当前,大模型与强化学习的结合是AI领域的热门方向。然而,现有的强化学习方法通常将整个大语言模型视为一个单一、整体的策略来优化,焦点多集中于外部的奖励设计等表层改进,却忽视了模型内部复杂的层级结构与演化过程。
理解大模型这个“黑盒”的内部工作机制,尤其是其如何执行推理,对于从算法层面进行针对性设计至关重要。来自中国科学院自动化研究所与腾讯AI Lab的研究团队,从模型可解释性分析入手,发现了一个有趣的现象:大模型内部实际上“秘密”地包含了多个可采样的内部策略。他们还揭示了不同模型家族(如Llama与Qwen)在推理过程中展现出截然不同的内部熵模式。
基于这些发现,团队提出了一种新颖的、从可解释性出发的强化学习算法:自底向上的策略优化。该算法将训练过程与大模型自底向上的内部推理机制相耦合,通过在训练早期直接优化底层的内部策略,来重构模型的基础推理能力,从而在复杂的数学推理任务上取得了显著优于传统方法的效果。

什么是内部策略?
研究团队提出了一个核心洞察:我们所优化的大语言模型整体策略,实际上是由一系列更细粒度的“内部策略”组成的。
在强化学习场景中,我们常说的大模型策略,是指模型根据当前上下文环境生成下一个token的过程。这个过程本质上是对一个基于词表的概率分布进行采样。而这个最终的概率分布,来源于模型最后一层的隐藏状态经过解嵌入矩阵转换的结果。
受“logit lens”等工作的启发,并利用Transformer架构中残差流的加性分解特性,我们可以将任意中间层的隐藏状态,甚至是中间模块(如自注意力层或前馈网络层)的输出,与解嵌入矩阵结合,构建出独立的、可采样的概率分布。这就定义了“内部层策略”和“内部模块策略”。从这个视角出发,研究团队试图剖析:模型的推理能力是如何在层与层之间涌现的?我们能否通过直接优化这些内部过程来提升模型的整体性能?
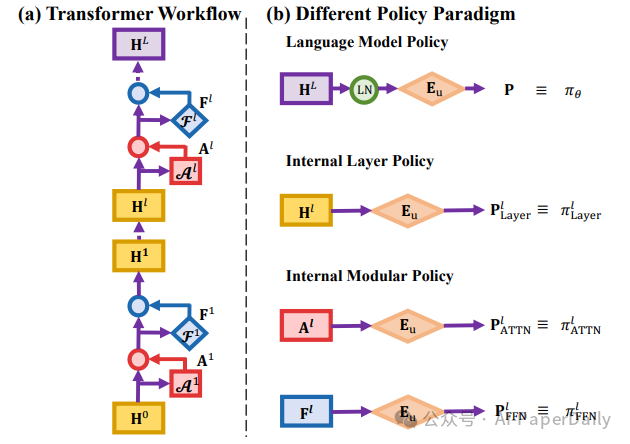
图1: (a) Transformer内部的残差流可分解为来自底层的累加,使得底层的隐状态可以被轻松剥离;(b) 语言模型策略的本质以及内部策略的组成。
内部策略研究发现
研究团队从策略的视角,提出了“内部策略熵”这一度量,对Qwen和Llama系列模型进行了深入的扫描分析,揭示了两种截然不同的内部推理模式。
通用的熵流向:所有模型都表现出一种普遍结构,即底层保持较高的熵值以探索广阔的解决方案空间,而随着层数升高,熵值迅速下降,在顶层趋近于零以进行最终的确定性预测。这符合“底层捕捉语义、高层进行决策”的普遍直觉。
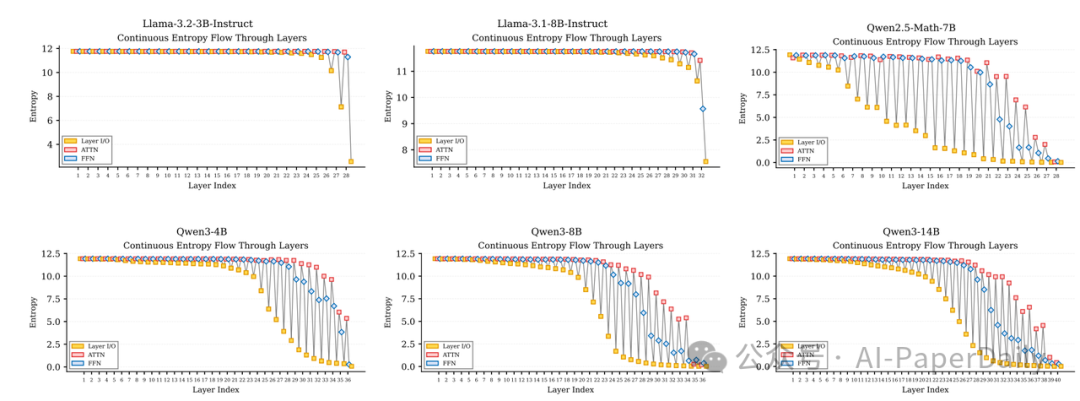
图2:不同架构模型内部策略熵的连续走向。所有模型在早期保留较高的熵而在最后收敛。
为了更精细地分析各个模块的作用,研究团队进一步提出了“内部策略熵变化”,通过计算模块输出的熵相对于输入熵的变化,来判断该模块是在引入不确定性(发散探索)还是在收敛推理空间。
Llama vs. Qwen:架构决定的思维差异:在细粒度的模块层面,差异变得非常显著。Llama系列模型的预测空间似乎只在最后几层才突然收敛。其中间层的前馈网络模块熵变化持续为微弱的正值,表明其在大部分层级中都在进行发散但浅显的探索,缺乏中间阶段的信息整合。
而Qwen系列则展示了一种更类似人类思考的渐进式、结构化推理模式。其前馈网络模块呈现出清晰的“探索—整合—收敛”三阶段:
- 底层:熵增加,积极扩大搜索空间。
- 中层:熵变化趋近于零,利用参数化知识进行信息整合与计算。
- 高层:熵减少,逐步收敛至最终答案。
这种结构化的推理模式可能解释了为何Qwen系列模型在后训练阶段能展现出更高效的知识吸收能力。
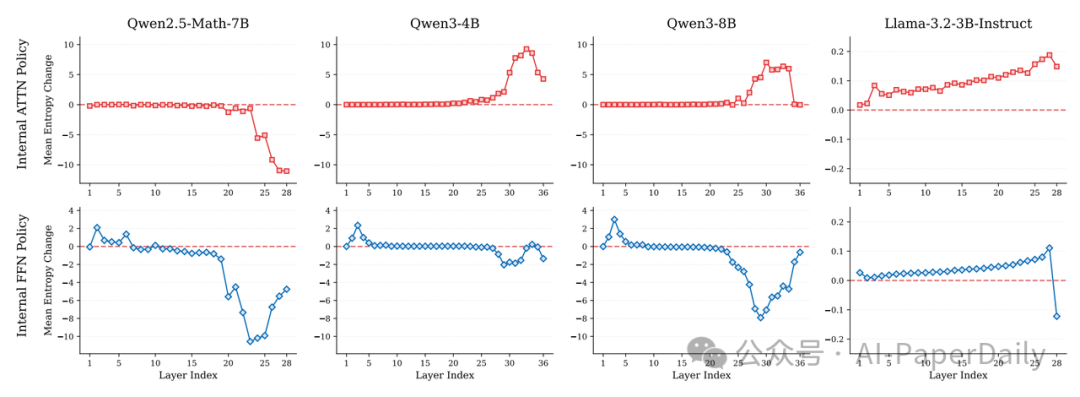
图3:Llama和Qwen系列不同模块的推理特征差异;其中Qwen3系列表现出了良好的结构化特征。
研究团队用生动的漫画描述了Qwen系列的这种结构化推理过程:
- 底层探索阶段:模型增加不确定性,广泛收集推理线索。
- 中部整合阶段:整合参数知识进行计算,但不改变不确定性。
- 高层收敛阶段:综合所有信息,收敛推理空间,得出最终答案。
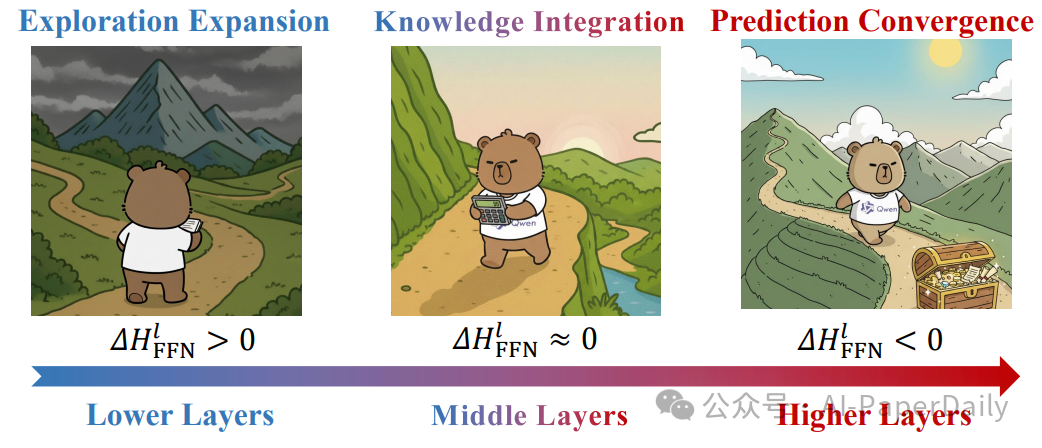
图4:Qwen系列的渐进式结构化推理漫画示例。
可采样内部策略优化
研究团队进一步将内部层策略直接视为可优化的策略对象进行强化学习训练。实验发现了几个有趣的现象:
- 特征早期对齐:优化后的内部策略能捕捉到更多上层推理的信息,实现了特征的早期对齐与精炼,为后续层级的推理打下了更好基础。
- 更强的不确定性压缩:内部策略对内部推理不确定性的压缩能力更强。
- 性能坍塌风险:但需要注意,对内部策略进行过多的训练会导致整体性能下降。
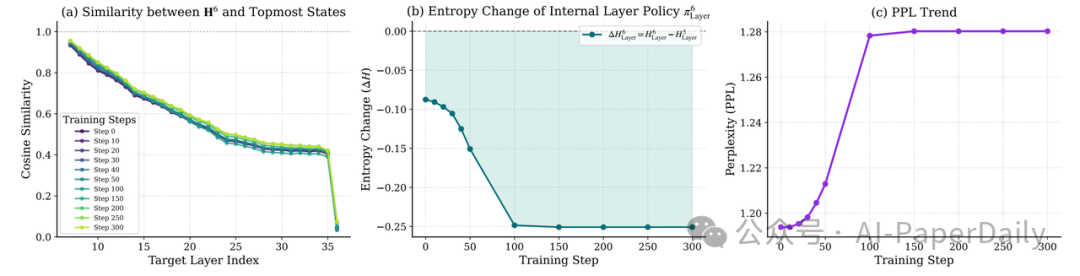
图5:直接优化内部策略的实验现象。(a)状态相似度变化,(b)内部层策略熵变化,(c)整体困惑度趋势。
自底向上的策略优化
基于以上发现,研究团队提出了一个核心观点:既然模型的推理能力是自底向上、逐层涌现的,那么优化过程也应顺应这一自然规律。由此,Bottom-up Policy Optimization 算法应运而生。这是一种新颖的两阶段训练范式:
- 早期阶段(底层对齐):优先优化选定的、具有正向探索信号的细粒度内部层策略(如前馈网络层),引导底层特征与最终的推理目标对齐。
- 后期阶段(全局优化):切换至标准的、针对整个语言模型输出层的策略优化,完成整体输出的最终对齐。

图6:Bottom-up Policy Optimization (BuPO) 算法流程。
实验结果
研究团队在MATH、AMC23、AIME24/25等复杂的数学推理基准上进行了广泛实验,结果证明了BuPO的有效性:
- 全面超越基线:在Qwen3-4B/8B和Llama-OctoThinker系列模型上,BuPO的表现一致优于GRPO、PPO、Reinforce++和RLOO等主流强化学习算法。
- 显著的性能提升:例如,在Qwen3-4B上,BuPO在AIME24数据集上的平均得分比GRPO提高了4.69%;在Llama-OctoThinker-8B上,MATH500的得分提升了5.16%。
- 更优的采样效率:在不同的采样数量设置下,BuPO均保持了最佳或接近最佳的性能,证明了其生成结果的鲁棒性与一致性。
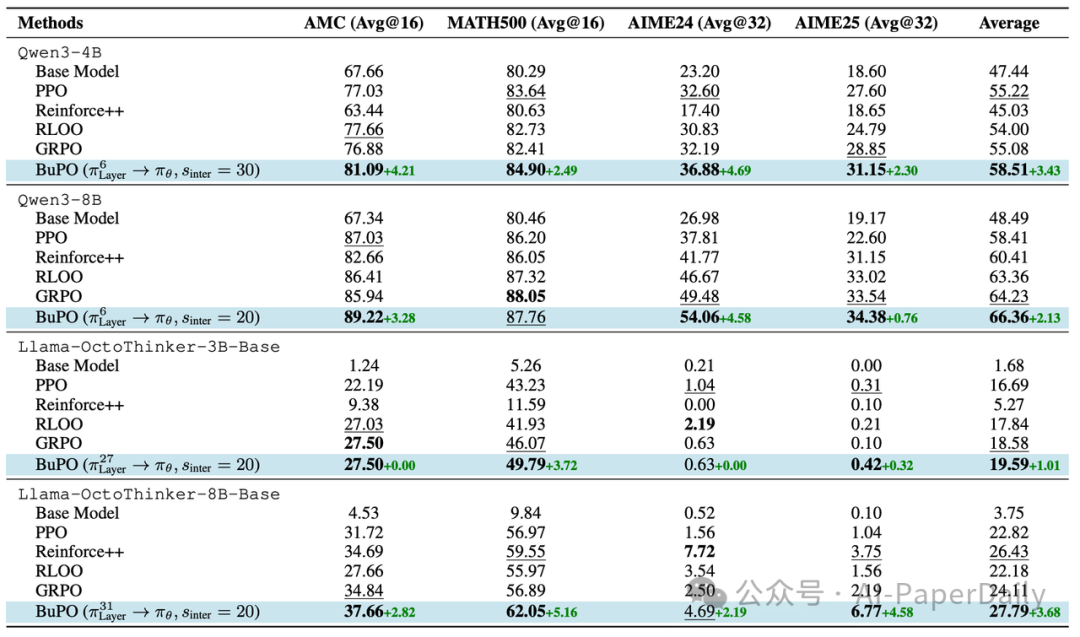
表1:不同模型与优化方法在多个测试集上的平均性能对比。
同时,BuPO训练过程中的熵动态曲线也表明,早期对齐内部策略能有效扩展模型在训练初期的探索空间,为后续的强化学习优化奠定了更好的基础,避免了过早收敛到次优解。
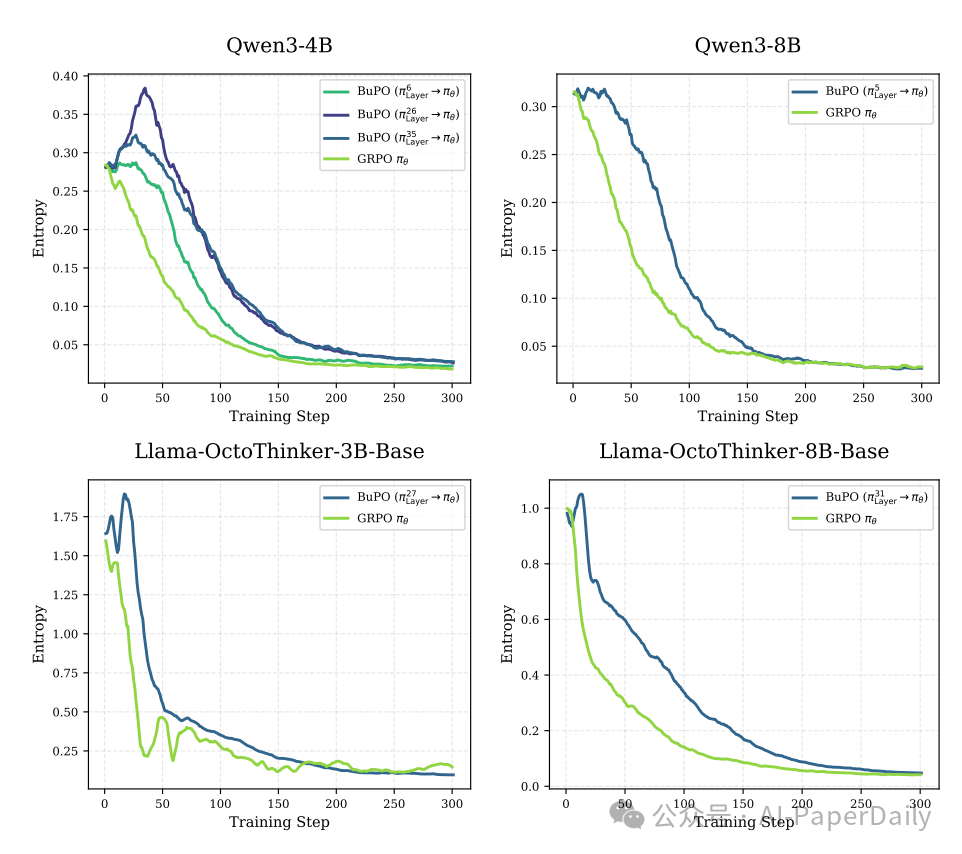
图7:BuPO与GRPO方法在训练过程中策略熵变化的动态对比图。
总结
Bottom-up Policy Optimization不仅是一项算法创新,更为我们理解大模型提供了新的视角。它揭示了大模型的策略并非一个不可分割的黑箱,而是由无数内部策略交织而成的精密系统。
通过自底向上地优化这些内部组件,我们能够从根源上重构和增强模型的基础推理能力,而非仅仅在表层调整其输出概率。这项工作通过解构大模型的内部策略,在模型可解释性研究与强化学习算法设计之间架起了一座新的桥梁。对这类前沿的AI研究与技术动态感兴趣的开发者,欢迎持续关注云栈社区的分享与讨论。
 发表于 2026-1-4 19:23:29
|
查看: 335|
回复: 0
发表于 2026-1-4 19:23:29
|
查看: 335|
回复: 0
