新年伊始,我收到了金仓社区寄来的一本新书——《金仓数据库 KingbaseES 性能优化》。利用假期时间通读全书后,我得出的结论是:这本书超出了我的预期。

整本书共分九章,开篇第一章便直指核心,探讨性能优化的方法论。书中有一句话令人印象深刻:
在处理性能问题之前首先确认这是不是一个真正的性能问题。
这句话看似简单,在实践中却常被忽视。许多工程师或DBA一听到“数据库慢了”,便急于动手调整参数、改写SQL甚至重启服务,却很少冷静思考:这究竟是不是一个可量化的问题?问题的根源到底在业务侧还是系统侧? 性能优化的终极目标,从来不是让数据库“看起来很忙”,而是让业务能够稳定、可预期地运行。从这点来看,本书从一开始就摆正了方向。
第二章介绍了性能优化基础,其中提到 KingbaseES 实现了 Global plan cache(目前仅支持 Simple Protocol)。我认为这是一个非常务实的改进。在OLTP场景下,并发高、SQL模式稳定,执行计划生成的开销不容忽视。如果执行计划能够跨会话复用,对于大量结构相同的SQL,响应时间将有显著改善。相比之下,社区版PostgreSQL的计划缓存基本停留在会话级别,共享计划缓存一直是个难题,仅有一个维护状态不明的插件方案。
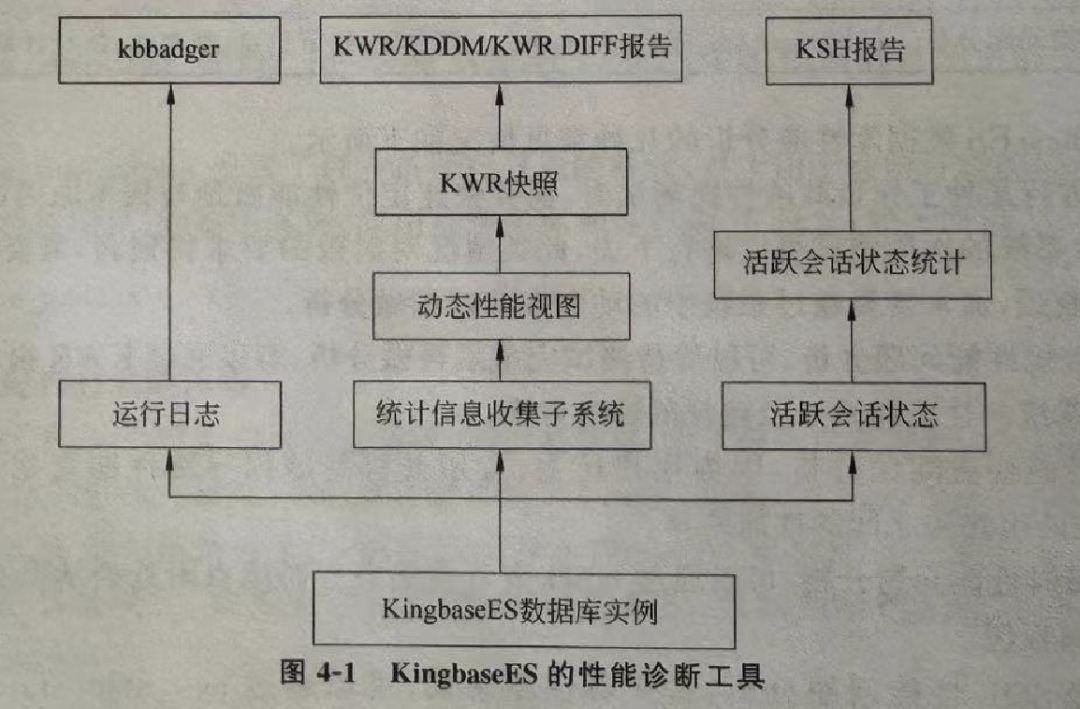
第四章我认为是工程含量非常高的一章,系统介绍了数据库的性能诊断能力。KingbaseES 构建了一套完善的可观测体系:
- KWR:历史快照报告
- KDDM:基于KWR的优化建议报告
- KDR DIFF:用于回溯与分析因变更导致的性能问题
- KSH:活跃会话历史追溯
许多从Oracle转向PostgreSQL的用户常抱怨后者在可观测性上“工具零散、需要拼凑插件、缺乏历史数据”。KingbaseES 至少在工程化落地层面,向前迈出了一大步。掌握这些工具,在面对性能问题时能更加得心应手。
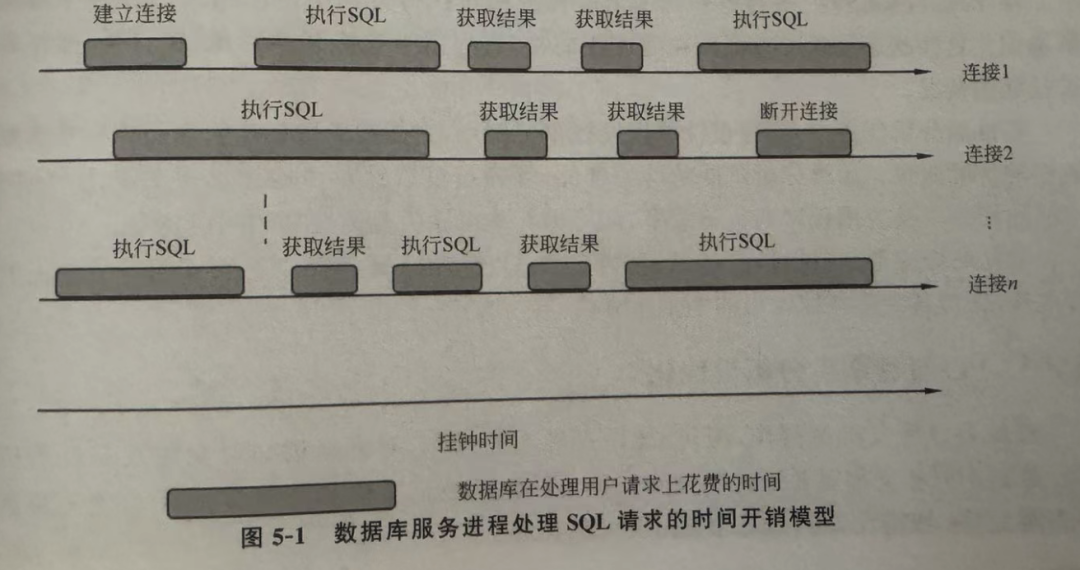
第五章提出了一个极具借鉴价值的概念——时间模型。其目的是明确各子系统对性能的影响,并基于此构建多维分析框架,从而定位性能问题的根本原因。通过拆解一次SQL请求在各个阶段的耗时,可以将性能问题自上而下地分解:
- 建立连接是否慢(涉及进程模型、是否需要连接池)
- SQL本身执行是否慢(是等待资源,还是真正计算耗时高)
- 返回数据量是否过大(涉及网络吞吐、结果集控制)
- 等待事件与系统瓶颈定位
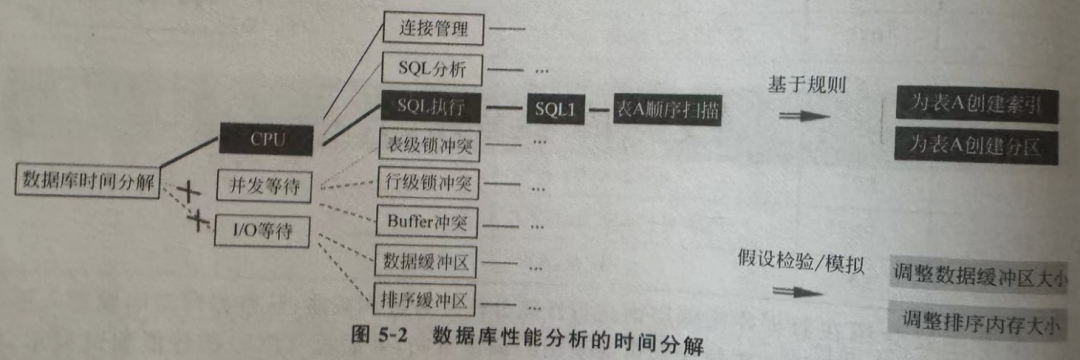
此外,本章还介绍了一些典型的等待事件,例如在高并发、大共享缓冲池场景下的公认热点 buffer_content 等待,以及 lock_manager 等待等。针对经常被提及的 wal_insert 等待事件(在V18版本中已通过无锁优化大幅改善),KingbaseES 提供了 enable_xlog_insert_lock_free 参数来消除此等待以提升性能,不过对系统有一定要求。
第六章介绍了SQL语句优化基础。书中提及的KingbaseES版本似乎还未引入向量化执行引擎,主要基于传统的火山模型,这可能与其更侧重于TP场景有关。
第七章详细讲解了SQL查询执行计划,此处内容较为常规,略过不表。
第八章聚焦于优化SQL执行计划。KingbaseES 提供了 SQL优化建议器 sys_sqltune,不过据描述,其支持的自动改写场景目前还比较有限,例如将UNION转为UNION ALL、DELETE转TRUNCATE,以及促使隐式类型转换使用索引等。在查询优化器的逻辑优化阶段,KingbaseES 通过 kdb_rbo 插件对一些特殊场景进行了增强,原文概括如下:
- 合并多个存在包含关系的(NOT) EXISTS子查询,减少对相同表的重复扫描、连接操作。
- 将SQL中重复的子查询或表达式,或多个UNION ALL分支中的公共表访问,转换为CTE,减少访问或连接次数。
- 将连接条件下推到带有UNION操作的子查询中,利用Nestloop参数化路径提升性能。
- 对
SELECT count(distinct XX) 进行优化,当数据重复度极高(通过参数 kdb_rbo.attribute_distinct_value_threshold 控制,默认0.1即90%以上重复)时,自动引入分组操作来提升性能。相当于自动改写为 select count(o_clerk) from (select o_clerk from orders group by o_clerk);。
此外,KingbaseES 还实现了位图索引,这对于索引属性基数较低的场景尤为合适。本章末尾还介绍了一个“黑科技”——查询映射。该功能允许将一个查询映射为另一个查询执行。对于那些因历史遗留原因无法直接修改的“陈年”SQL,此功能可谓雪中送炭。DBA可以在数据库内部定义映射规则,实现遇到A语句自动改写为B语句,从而在不改动应用代码的情况下优化性能。
第九章讲述了如何编写高效的SQL语句,涵盖了诸如OR子句改写、避免标量子查询成为性能杀手、IN和EXISTS的选择等常见优化技巧。书中也指出:
目前,PostgreSQL优化器对SQL中OR子句过滤条件的优化能力较为有限。如果OR子句中的过滤条件仅涉及一张表,且所有条件上均有合适索引,优化器会生成BitmapOr的索引路径。
最后一章则介绍了一些数据建模方面的最佳实践,例如分区表设计、数据类型选择等。
小结
作为一名长期活跃在PostgreSQL/Greenplum生态中,对国产数据库保持理性审视但也愿意深入了解的技术从业者,我的总体看法是:这本书虽然围绕KingbaseES展开,但其中蕴含的大量性能分析方法、排障思路和工程实践,其价值并不仅限于某一个数据库产品。不必带着“站队”的心态去阅读,将其视为一本 “性能优化方法论+工程实践”的合集,或许能收获更多洞见。对于希望系统提升数据库问题分析与解决能力的朋友来说,这是一本颇具参考价值的读物。如果你想深入探讨更多数据库性能优化相关的实践,也欢迎在技术社区交流分享。
 发表于 2026-1-5 22:23:54
|
查看: 191|
回复: 0
发表于 2026-1-5 22:23:54
|
查看: 191|
回复: 0
