做数据前端开发,我们很快会形成一个共识:如何将枯燥的数字以恰当方式呈现,是我们的首要任务,但这仅仅是起点。
如果说规范的数字排版是中后台系统的"地基",确保了信息的准确传递;那么可视化图表就是地基之上的"建筑"。地基稳固,建筑才能充分发挥作用——让用户从微观数据阅读中解放出来,更快识别趋势、定位异常,真正从数据中获取价值。
本文重点讨论的并非那座"建筑",而是经常被忽视却决定系统专业度的"地基"——数字格式化。
观察得物各业务线的日常场景:
- 商品详情页:券后价、折扣、分期单价等;
- 智珠(得物社区运营平台)、得数(自助取数平台)、智能运营(得物交易运营平台)中的GMV、转化率、留存率、PVCTR等;
- 社区帖子阅读量、点赞数、粉丝数。
这些数字表面只是数值,一旦显示在屏幕上,就自动成为版面组成部分:对齐方式、位数长短、小数位数、是否使用"万/亿"、单位放置——都会影响页面节奏和专业感。
排版本质是在管理信息与秩序:层级、节奏、对齐、留白。数字不是排版的"附属品",恰恰是这些原则最密集的载体。
本文专注"数字格式化"主题:
- 什么是数字格式化?背后有哪些文化差异和技术细节?
- 缺乏统一方案时,失控数字会给产品决策、UI排版和工程维护带来什么问题?
- 得物数据前端如何在得数/智珠/智能运营中将此事从"工具函数"升级为"基础设施"?
- 基于Intl.NumberFormat和@dfx/number-format的方案架构如何,带来哪些实际收益?
什么是"数字格式化"?
不只是toFixed(2)
提到数字格式化,第一反应常是:toFixed(2)、拼接%、添加¥符号,或通过正则添加千分位。但在真实场景中,"同一数值如何呈现"远比想象复杂。
数字写法本身就是"文化差异"
据Florian Cajori 1928年著作《数学符号史》记载,小数分隔符演变经历了漫长标准化过程。
早期数学文献中,不同地区对小数的处理方式各异。以数值34.65为例,中世纪文献常在整数与小数间加横线或在个位数字上方加注标记。英国早期采用竖线"|"作为分隔,后在印刷中简化为逗号或点,这与当时阿拉伯数学家主要使用逗号的习惯相呼应。
"点"与"逗号"分流的历史成因
17世纪末至18世纪初是符号标准化的关键时期,也是英美体系与欧洲大陆体系产生分歧的起点:
- 欧洲大陆(莱布尼茨的影响):德国数学家莱布尼茨提议使用"点"作为乘法符号。经由克里斯蒂安·沃尔夫等学者推广,在欧洲大陆教科书中广泛普及。为避免符号冲突,欧洲大陆数学家普遍采用"逗号"作为小数分隔符。
- 英国(牛顿体系的延续):英国数学界未采纳莱布尼茨的乘法符号,而是沿用"X"表示乘法。因此"点"在英国未被乘法占用,得以继续作为小数分隔符使用。
标准的确立
尽管比利时和意大利等国曾长期坚持使用点作为小数分隔符,但最终均向欧洲大陆主流标准靠拢,改用逗号。至此,英美使用"小数点"、欧洲大陆使用"小数逗号"的格局基本定型。
- 英语系/中国常见写法:1,234,567.89
- 很多欧洲国家:1.234.567,89(点是千分位,逗号是小数)
- 瑞士习惯:1'234.56或1'234,56,用撇号'做分组。
这些规则已被整理进Unicode CLDR和ICU数据库,现代浏览器的Intl.NumberFormat建立在这套数据之上,能根据locale自适应这些写法。
因此,简单的1,000:
- 在美国人或中国人眼中是"one thousand/一千";
- 在某些欧洲语境下可能被读作"保留三位小数的一点零"。
从事电商、跨境、数据产品时,这种"写法"差异不再是小问题,而是直接影响决策和合规性的因素。
数字不只是"大小",还有语义和语气
在UI中,我们经常表达"数字的语气":
- +12.3%:不是纯数学"加号",而是"上涨"信号,排版上常配合红/绿颜色;
- 1.2M/120万:为节省空间和降低认知负担,用缩写表示量级;
- < 0.01:极小数值,让用户知道"接近0",而非盯着0.000032的数字尾部;
- —/N/A:告知用户"此处无数据/异常",而非"数值为0"。
这些属于"数字的表达"而非"运算结果"。仅使用toFixed和字符串拼接,很难在全系统内保持这些语气一致。
浏览器和Node已提供"引擎"
ECMAScript 402标准提供的Intl.NumberFormat,是专门处理本地化数字格式化的构造器。
它支持:
- 根据locale切换小数点、分组规则、数字符号;
- 货币格式:style: "currency" + currency: "CNY" | "JPY" | ...;
- 百分比:style: "percent",自动乘100并加%;
- 紧凑表示:notation: "compact",输出9.9M、9.9亿等缩写;
- formatToParts():将数字拆解为整数、小数点、小数、货币符号等片段,便于精细排版。
因此,数字格式化的"引擎问题"已解决——真正难点在于:
- 如何结合业务语义;
- 如何结合排版规范;
- 如何在多系统间保持一致;
- 如何治理"不乱写"的工程实践。
这就回到我们自己的故事。
如果没有统一方案:三个数据产品的日常
以下场景在得物或类似电商/数据平台中常见。
想象典型后台页面:
- 顶部是活动看板KPI卡片;
- 中间是按品类/渠道拆分的表格;
- 下方是创作者表现列表。
价格:同一张订单,不同系统"长得不同"

以前的做法如何?在没有统一规范的"蛮荒时代",面对数字的第一反应常是:"这还不简单?拼个字符串不就完事了?"
这种代码你一定写过,或在项目角落见过:
场景一:简单粗暴的字符串拼接
// "我管你什么场景,先拼上去再说"
function formatPrice(value: number) {
// 隐患埋雷:这里是全角¥还是半角¥?null会变成"¥null"吗?
return '¥' + value.toFixed(2);
}
场景二:为千分位手写正则
// "网上一搜一大把的正则,看着能跑就行"
export const formatNumberWithCommas = (number: number | string) => {
const parts = number.toString().split('.');
// 经典的正则替换,但这真的覆盖所有负数、极大值场景吗?
parts[0] = parts[0].replace(/\B(?=(\d{3})+(?!\d))/g, ',');
// 手动补零逻辑,不仅难维护,还容易在边界情况(如undefined)下报错
if (parts.length > 1 && parts[1]?.length === 1) {
parts[1] = `${parts[1]}0`;
}
return parts.join('.');
};
这看起来"能用",但当业务复杂度上升或需要国际化时,接手者只能感叹。
-
视觉上的"各自为政"
- 符号打架:商品卡片用半角¥,详情页用全角¥,甚至混用CNY。
- 精度随心:有的开发觉得toFixed(2)严谨,有的觉得.00多余直接砍掉,导致同一页面数字像锯齿般参差不齐。
-
排版上的"秩序崩塌"
- 试想表格列:1299、1,299.00、1299.0混在一起。
- 对齐基准线完全错乱,尤其在表格中如同"狗啃过",用户眼睛需在不同小数位间跳跃,阅读体验极差。
-
国际化上的"死胡同"
- 这种硬编码逻辑完全堵死国际化道路。
- 一旦业务需支持USD(美元)、JPY(日元,默认无小数)、EUR(欧元,部分国家用逗号做小数点)。
- 如1,234,567.89(英美)和1.234.567,89(德意),这不是改符号能解决的,而是数字书写逻辑的根本差异。
我们本想省事写的小函数,最终变成阻碍系统演进的技术债务。
看似智能的"万/亿"缩写,其实是硬编码的陷阱
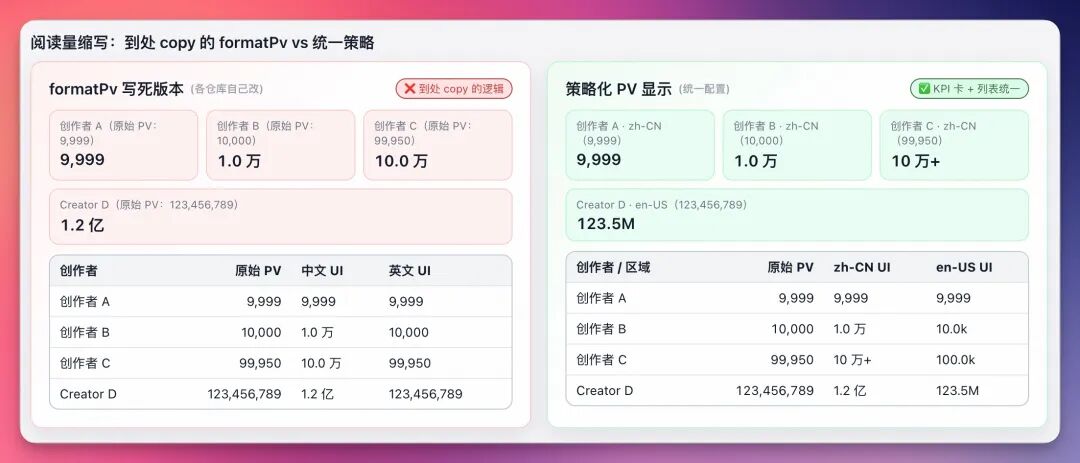
在创作者中心或内容社区,希望阅读量(PV)符合用户直觉认知:
- 小数值:< 10,000时,显示完整数字,精确到个位;
- 中量级:≥ 10,000时,缩写为X.X万;
- 海量级:≥ 100,000,000时,缩写为X.X亿。
海外版需求又变为:1.2k/3.4M/5.6B。
于是写出经典formatPv:
function formatPv(count: number) {
if (count < 10000) return String(count);
if (count < 100000000) return (count / 10000).toFixed(1) + '万';
return (count / 100000000).toFixed(1) + '亿';
}
这段代码逻辑清晰,看似解决问题。但在真实场景中,它是"Bug制造机":
1.临界点的"视觉突变"
- 9999下一秒变成1.0万?产品会立即质疑:"这个数展示是不是不对,能不能9999后显示1.0w而非1.0万?"
- 99950四舍五入变成10.0万,是否显示更直观的10万?这些细节需大量if-else修补。
2.维护上的"复制粘贴地狱"
- 中文版写一套,英文版formatPvEn再写一套,业务拓展至世界各地时需要多少formatPv(xx)?
- A项目拷一份,B项目拷一份。当产品要求"万"后不留小数,需去N个仓库找出代码修改。最终全站缩写策略处于"相似但不一致"状态。
3.文化适配上的"盲区"
- 这套逻辑是典型"简体中文中心主义"。
- 印度用户看到100k无感,他们习惯用Lakh(10万)和Crore(1000万);
- 阿拉伯语区可能需要用东阿拉伯数字。
这不仅是将"万"翻译成"Wan"的问题,而是数字分级逻辑在不同文化中完全不同。我们在UI硬塞"只能在简体中文自洽"的规则,这在国际化产品中行不通。
被"抹平"的语义—0、空值与极小值
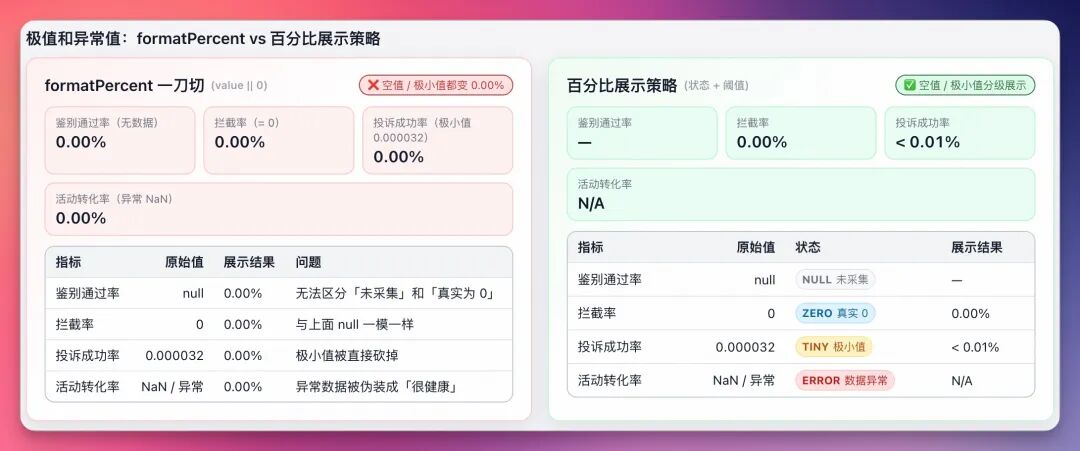
在得数(自助取数平台)、智珠(得物社区运营平台)、智能运营(得物交易运营平台)类重度数据看板中,充满各种比率型指标:
- 风控类:鉴别通过率、拦截率;
- 履约类:超时率、投诉成功率;
- 增长类:活动转化率、复购率。
面对这些指标,以前最常见处理是写通用formatPercent:
function formatPercent(value: number | null | undefined) {
// "没数据就当0算呗,省得报错"
return ((value || 0) * 100).toFixed(2) + '%';
}
这行代码虽只有一句,却在业务层面犯三个严重错误:
1.混淆"事实"与"缺失"
- null代表数据未产出或链路异常(即无数),而0代表业务结果确实为零。
- 代码粗暴将null转为0.00%,会让用户误以为"今天无人投诉"或"转化率为0",从而掩盖系统故障或数据延迟。
2."抹杀"长尾数据价值
- 对AB或算法模型,0.000032是具备统计意义的概率值。
- 被代码强行截断为0.00%后,业务同学困惑:"为什么P值还能是0?"这直接损害数据公信力,影响业务决策。
3.阻断精细化表达可能
当想将极小值优化为< 0.01%这种更科学表达时,通过vscode搜索代码,500+文件直接让人无从下手。
从排版设计角度,三者本应拥有完全不同视觉层级:
- 空值(No Data):使用—或灰色占位符,表示"此处无信息",降低视觉干扰;
- 异常值(Error):使用N/A或警示色,提示用户"数据有问题";
- 极小值(Tiny Value):使用< 0.01%或≈0,保留数据存在感,同时传达"接近于零"的准确语义。
得数DataHub治理展示层时发现,大量"同一指标在不同页面长得不一样",根源在于这些各自为政、缺乏语义区分的格式化规则。
从"写工具函数"到"定义展示语义"

回顾上述场景,透过混乱代码片段,可发现三个共性系统难题:
- 逻辑熵增:每个业务线、甚至每个页面都在重复造轮子。formatPrice、formatPercent遍地开花,前后端逻辑割裂,维护成本随业务扩张指数上升。
- 无法治理:想统一全站"万/亿"阈值?或将某种费率精度从两位改四位?这几乎不可能。
- 体验失控:设计规范虽写"空值用—",但落实到代码全看开发心情。结果用户在不同系统间切换时,看到"似是而非"的统一,严重影响产品专业感。
为解决这些问题,在数据域产品中,我们对"格式化"重新定义:
它不只是前端的UI渲染逻辑,而是指标定义的一部分。
我们不仅要定义"指标的计算口径",更要定义"指标的展示语义"。
在Galaxy(指标管理平台)定义好"数怎么算出来"后,得数DataHub承担起定义"数该怎么被看见"的职责。我们将这层逻辑抽象为"展示语义"(Visualization Semantics):
- 定类型(Type):它是金额(Currency)、比率(Ratio),还是计数(Integer)?
- 定单位(Unit):默认是元/万元,还是%、‰(千分比)或bp(基点)?
- 定精度(Precision):小数位固定保留两位,还是根据数值大小动态截断?
- 定状态(State):遇到Null(空值)、Error(异常)或Epsilon(极小值),展示层如何兜底?
- 定场景(Context):在空间局促的KPI卡片里(追求简洁),和需要财务核对的明细表格里(追求精确),是否应用不同渲染策略?
这是架构上的升维:
这些关于"长什么样"的逻辑,不再散落业务代码的if-else里,而是被统一收拢到元数据系统中管理。
从此刻起,数字格式化不再是前端模板里的小工具,而是成为得数体系的一项基础设施——一层独立、可配置、可治理的数据领域服务。
着手开发前,首先确立原则:底层能力不造轮子,拥抱Web标准。
ECMAScript 402标准中的Intl.NumberFormat已提供极其强大的本地化格式化引擎。它的能力远超大多数手写正则替换:
const n = 123456.789;
// 德国:点号分组、逗号小数
new Intl.NumberFormat('de-DE').format(n);
// "123.456,789"
// 印度:lakh/crore分组
new Intl.NumberFormat('en-IN').format(n);
// "1,23,456.789"
// 日元货币:默认0位小数
new Intl.NumberFormat('ja-JP', {
style: 'currency',
currency: 'JPY',
}).format(n);
// "¥123,457"
它完美解决那些最让前端头疼的国际化底层问题:
- 文化差异:全球各地的千分位、小数点、数字符号习惯;
- 货币规则:不同币种的标准小数位(如日元0位,美元2位)和符号位置;
- 多态支持:内置百分比、紧凑缩写(Compact Notation)、科学计数法等模式;
- 排版能力:通过formatToParts()将数字拆解为数组(整数部分、小数部分、符号等),为精细化排版提供可能,如在小数或百分比符号比整数小2个字号。
但是,它天然"不懂"业务:
- 它不懂中文习惯:无法直接实现"兆/京/垓"这种中文超大数缩写逻辑(标准最多支持到亿);
- 它不懂得数规范:不知道*_rate类型指标在空值时要显示"-",在极小值时要显示< 0.01%;
- 它不懂业务上下文:不知道GMV在KPI卡片里要按"万元"展示,而在财务报表里必须精确到"厘"。
因此,我们的最终架构策略是:
以Intl.NumberFormat为底层的"渲染引擎";在其之上搭建"数字领域层"(Domain Layer);专门用于转译得物的业务规则和排版语义。
在得物数据前端的大仓中,我们将这层能力实现为独立包:@dfx/number-format。专门服务得数、智珠、智能运营等内部系统。
可将其理解为三件事的组合:
- 一个统一封装Intl.NumberFormat的核心引擎(含缓存、解析);
- 一套可配置的业务规则/预设(preset)和插件系统;
- 一组面向React和Node环境的接口(组件+Hook+FP函数)。
声明式开发:把"数字长什么样"抽象成规则
在业务开发侧,最终期望目标是:让开发者只关心"这是什么指标",而不关心"它该怎么展示"。
场景一:基础格式化
可直接使用组件,以声明式方式调用:
import { NumberFormat } from '@dfx/number-format';
// 无论在哪个页面,价格都只需这样写
<NumberFormat
value={price}
options={{ style: 'currency', currency: 'CNY' }}
/>
场景二:基于语义的自动格式化
更进阶用法是,在系统层面定义"规则集",业务组件只需传入指标名称:
import { NumberFormatProvider, AutoMetricNumber } from '@dfx/number-format';
// 1. 定义规则:所有"price.cny"类型指标,都遵循人民币格式
const rules = [
{ name: 'price.cny', options: { style: 'currency', currency: 'CNY' } },
];
// 2. 注入上下文
<NumberFormatProvider options={{ rules }}>
{/* 3. 业务使用:完全解耦,只传语义 */}
<AutoMetricNumber name="price.cny" value={price} />
</NumberFormatProvider>
收益显而易见:
- 自动化:CNY自动带两位小数,切到JPY自动变0位小数,逻辑完全由底层接管。
- 一致性:全站所有price.cny的地方,千分位、符号位置严格统一,版面节奏自然对齐。
场景三:批量匹配比率指标
对于成百上千个转化率指标,我们不需要逐一定义,只需一条正则规则:
const rules = [
// 匹配所有以_rate结尾的指标,自动转为百分比,保留2位小数
{ pattern: /_rate$/i, options: { style: 'percent', maximumFractionDigits: 2 } },
];
// 页面代码极其干净
<AutoMetricNumber name="conversion_rate" value={conversionRate} />
空值与异常值如何展示、极小值是否显示< 0.01%、两位小数从哪里来,全部在规则+插件里处理。
插件系统:收口那些"奇怪但常见"的需求
得物业务场景中,存在大量Intl标准无法直接覆盖的边缘需求。我们将这些需求统一建模为插件(Format Plugin),介入格式化生命周期:
- 千分比/基点(bps):需在pre-process阶段将数值乘1000或10000;
- 中文大写金额:会计与合同场景的特殊转换;
- 极小值兜底:设定阈值,当数值小于0.0001时,post-process阶段输出< 0.01%;
- 会计格式:负数使用括号(1,234.56)而非负号;
- 动态精度策略:根据数值大小动态决定保留几位小数。
这套插件机制的意义在于"治理":
它让"在某个业务仓库里偷偷写一个特殊正则"成为过去式。任何新的格式化需求,都必须以插件形式接入,由数据前端统一评审、沉淀,最终复用到全站。
全链路打通:从Galaxy元数据到UI渲染
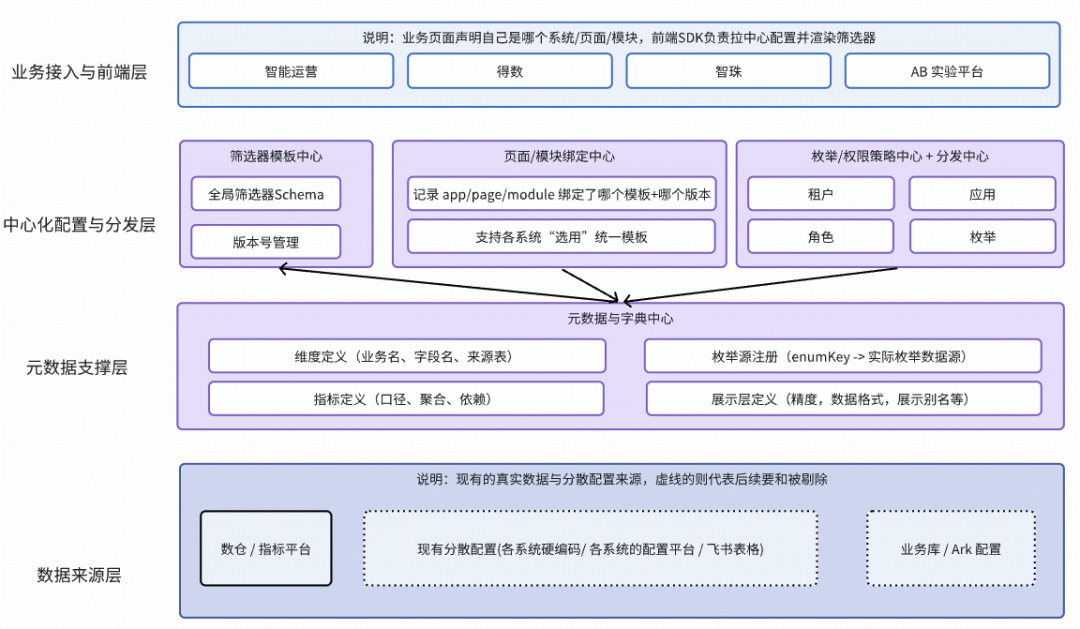
最后,将这套系统与得数的中台能力打通(也是我们正在做的),形成完整渲染链路。
在Galaxy和得数的元数据中,指标本身已有code、label、type等字段。我们只需再加一点约定:
{
"metricCode": "gmv",
"label": "GMV",
"format": "currency", // 基础类型
"meta": {
"formatConfig": {"style": "currency", "maximumFractionDigits": 2},
"category": ["交易指标"],
"displayConfig": { "table": "precise", "card": "compact" }
}
}
前端渲染时:
- 配置下发:页面加载时,获取指标的Code及元信息,转换为前端的MetricFormatRule[]。
- 上下文注入:在应用根节点通过NumberFormatProvider注入规则集。
- 傻瓜式使用:表格、卡片、图表组件只需消费指标ID:<AutoMetricNumber name={metricId} value={value} />
这样实现真正的『数据驱动UI』:
- "指标长什么样"只在得数元数据管理中定义一次。
- 修改展示规则(如调整精度),只需改配置,无需批量修改前端代码,更无需重新发版;
- 前台业务与中台报表看到的同一个指标,格式永远物理一致。
统一之后:重塑设计、工程与业务的价值
从我们的视角出发,这套统一数字格式方案落地,带来的收益远不止"代码整洁",它在三个层面产生深远影响。
对设计与排版:版面终于可控了
曾经,产品需在每个页面验收中反复纠结数字对齐和精度。现在,设计规范只需在文档中定义一次:
- 金额类:统一保留两位小数,强制右对齐,货币符号半角化;
- 比率类:空值兜底为—,异常值显示N/A,极小值转译为< 0.01%;
- 缩写策略:全站统一遵循"中文万/亿、英文k/M/B"的梯度逻辑。
开发同学不再『古法手搓』,而是直接接入统一的Preset和插件。
无论看板、详情页,还是导出的Excel报表,数字风格保持像素级一致。从视觉角度,我们相当于给数字建立了一套Design Token:精度、单位、占位符都有标准索引,让整个平台呈现高度统一的专业感和节奏感。
对工程质量与效率:从"搜索toFixed"到"改一处生效全站"
所有数字格式逻辑集中在一个领域层和配置中心。
一类指标的规则变更(精度、单位、空值策略)可以配置化调整。
规约可进入Lint(数字格式化限制)/Code Review:
- 禁止直接在业务代码中new Intl.NumberFormat、toFixed拼字符串;
- 鼓励所有数字展示全部走@dfx/number-format与DataHub规则。
这是工程治理层面的价值:它将"依赖开发者自觉"的软约束,变成"可配置、可维护、可迭代"的系统能力。
对业务和数据信任:从"怀疑这数有问题"到"愿意用来决策"
统一数字格式还有一个最隐性却最核心的价值:重构数据信任。
- 消除歧义:前台商品价格与中台报表金额完全一致,运营不再因"显示精度不同"质疑数据准确性;
- 精准语义:空值(Null)和零(Zero)被清晰区分,避免因格式问题导致的错误决策。
在得物,严谨是需要刻在基因里的关键词。
作为数据前端,我们深知:懂数据,并能用最专业方式呈现数据,是这一岗位的核心素养。当我们不仅能交付代码,还能通过精准数字展示消除歧义、传递信任时,技术与业务间就建立起深层默契。
这种对数字细节的极致追求,不仅是对用户体验的尊重,更是对得物"正品感"品牌心智在数字世界的延伸。
数字,是版面的『最后一公里』
回头看,得物数据前端在得数、智珠、智能运营这条线做的,其实有两件事:
我们不再将数字视为模板字符串里随时可替换的"黑洞",而是将其视作与字体、色彩、间距同等重要的排版元素,纳入统一的设计语言系统。
我们以Web标准Intl.NumberFormat为引擎,以@dfx/number-format为领域层,以得数Schema为配置中枢,将"数字如何展示"这一命题,从硬编码的泥潭中解放出来,转变为一种可配置、可治理、可演进的系统能力。
当你再回头看公司产品的各个页面——
- 前台商品详情页的价格和券后价;
- 社区里的阅读和点赞数字;
- 智珠的策略看板;
- 得数的自助分析报表。
你会发现它们拥有一个共同特征:
这些数字不再是各说各话的噪点,而是共同操着同一种精准、优雅的"排版语言"。
这就是我们做"数字格式化"的初衷:用技术的确定性,换取业务的专注力。
此时,作为前端开发,你可以坚定地说出:我这展示的没问题,是数出问题了~
走出数据域:从内部门户到全业务
前面的篇幅更多围绕得数、智珠、智能运营等中后台系统展开。在这些场景下,数字格式化的核心用户是运营、分析师和算法同学——帮助他们透过数据看清业务走势。
但这套能力并不应局限于"后台"。它完全具备走出数据域的潜力,成为得物全业务线共享的一层关键基础设施。
跨业务线:从"运营看板"走向"交易链路"
目前@dfx/number-format虽然生长于数据土壤,但其解决的问题是通用的。未来,它可以自然渗透到更广阔的业务场景:
- 交易域:统一商品详情页、结算页的价格、分期费率、税费展示逻辑;
- 社区域:标准化社区详情页中的风险分、阈值、命中率精度;
- 客服域:规范赔付金额、工单时长的展示口径。
这在工程上意味着一次"升维":
- 依赖升级:将@dfx/number-format从数据域私有包提升为公司级的基础依赖;
- 开发范式:新业务在处理数字展示时,默认动作不再是"手写一个format函数",而是查阅现有的Preset和插件;
最终带来的体验质变是:
用户无论在得物App的前台页面,还是内部的各类管理系统中,看到的数字都拥有同一套呼吸感和视觉习惯。这种跨端的一致性,是品牌专业感最直接的体现。
跨地区与汇率:构建独立的"全球化价格能力"
随着得物业务出海,多地区、多币种是绕不开的挑战。此时,数字领域层不仅要负责"长什么样",更要承担起"展示策略"的职责。
我们可以设想一个「全球化价格组件」:
<MultiRegionPrice
skuId="123456"
basePriceCny={price}
regions={[
{ locale: 'zh-CN', currency: 'CNY' },
{ locale: 'en-US', currency: 'USD' },
{ locale: 'ja-JP', currency: 'JPY' },
]}
/>
这个组件将负责两层逻辑的解耦:
- 计算层:负责实时汇率换算、多币种价格计算。
- 展示策略层:
- 对照展示:是否显示"原币种+本地参考价"(如JP¥20,000(≈$135.00));
- 文化适配:是否遵循当地的"心理价位"策略(如$199.99 vs$200);
- 格式渲染:最终调用@dfx/number-format,确保日元无小数、美元有小数、分节号正确。
从工程视角看,这避免"汇率算对了、数字排版全乱了"的尴尬;从产品视角看,这正是得物沉淀"出海技术套件"的重要一步(如国际智能运营)。
时间与日期:用同样的思路,去做第二条"格式化主线"
数字是一类挑战,"时间"则是另一类。跨时区转换、相对时间(此刻)、不同地区的日期写法(DD/MM vs MM/DD),其复杂度丝毫不亚于数字。
既然浏览器提供Intl.DateTimeFormat,我们完全可以复刻数字领域层的成功路径:
- 基础设施:构建@dfx/date-format,统一封装时间格式化与相对时间逻辑;
- 预设管理:定义标准Preset(如"运营报表用YYYY-MM-DD"、"C端动态用今天12:30");
- 组件化:提供<DateTimeFormat />和<AutoMetricDate />组件;
- 元数据打通:在得数的元数据中,针对时间型的维度也同样进行配置。
这样,数据前端的展示层就拥有两条清晰主线:
- 数值主线:Intl.NumberFormat → @dfx/number-format → 数字展示规范
- 时间主线:Intl.DateTimeFormat → @dfx/date-format → 时间展示规范
未来,我们甚至可以抽象出更上层的@dfx/data-format,让"任何字段该怎么展示",完全由Schema配置+领域层规则共同决定。
最后:把"展示"这件事做到极致
如果只看代码,我们做的事情似乎很简单:把Intl标准用到极致,封装了一层领域库,并接通了元数据配置,写了个工具库。
但如果从产品体验和工程演进的角度看,我们其实完成了一次基础设施的升级:
把前端开发中最琐碎、最容易被忽视的"数字与时间展示",从"到处粘贴的小工具",升级成了"有统一规范、有可观测性、有迭代空间的系统能力"。
现在,这套能力已让得数、智珠、智能运营的部分模块长出统一的"数字气质"。
未来,期望它能够走出数据平台,支撑得物更广泛的业务场景,让同一件商品,在不同地区、不同语言、不同终端上,既算得对,又看得顺。
 发表于 2025-11-27 03:43:37
|
查看: 208|
回复: 0
发表于 2025-11-27 03:43:37
|
查看: 208|
回复: 0
