在Web开发中,文件下载是一个常见但有时又颇为繁琐的需求。面对多样的数据源和复杂的处理流程,开发者往往需要编写大量样板代码。有没有一种方法,能让我们只关注核心数据,而将下载的复杂性隐藏起来呢?
本文介绍一种基于 @Download 注解的解决方案,它能极大简化在 Spring Boot 应用中实现文件下载的流程。想象一下,只需一个注解,即可处理本地文件、网络资源甚至自定义对象的下载与压缩,是不是非常便捷?
从痛点出发:一个复杂的下载场景
假设我们有一个设备管理平台,每个设备信息中都存有一个二维码图片的HTTP地址。现在需要批量导出所有设备的二维码,并打包成一个ZIP压缩包,且每个图片的文件名需使用设备名称。
传统的实现步骤可能包括:
- 查询设备列表。
- 遍历列表,根据URL下载图片到本地缓存(需判断缓存是否存在)。
- 为提升性能,可能还需引入并发下载。
- 所有图片下载完成后,将其压缩成ZIP文件。
- 最后操作输入输出流,将ZIP文件写入HTTP响应。
整个流程实现下来,代码可能长达数百行,维护起来并不轻松。
注解驱动的极简下载
而使用本文介绍的 @Download 注解方案,实现同样的功能可能只需这样:
@Download(filename = "二维码.zip")
@GetMapping("/download")
public List<Device> download() {
return deviceService.all();
}
public class Device {
// 设备名称
private String name;
// 设备二维码地址,@SourceObject注解标记此字段为需要下载的数据源
@SourceObject
private String qrCodeUrl;
// @SourceName注解标记此方法返回值为下载后的文件名
@SourceName
public String getQrCodeName() {
return name + ".png";
}
// 省略其他属性和方法
}
在上述代码中,控制器方法仅需返回业务数据(设备列表),并通过 @Download 注解指定下载文件名。在 Device 对象中,通过 @SourceObject 和 @SourceName 注解来声明下载源(二维码URL)和对应的文件名规则。所有的下载、压缩、写入响应等复杂操作,都由框架在幕后自动完成。
设计思路与核心架构
这个下载库的核心设计目标是灵活性与可扩展性,同时兼容 Spring WebMVC 和 WebFlux。其整体架构采用了处理器链模式,流程清晰,支持自定义扩展。
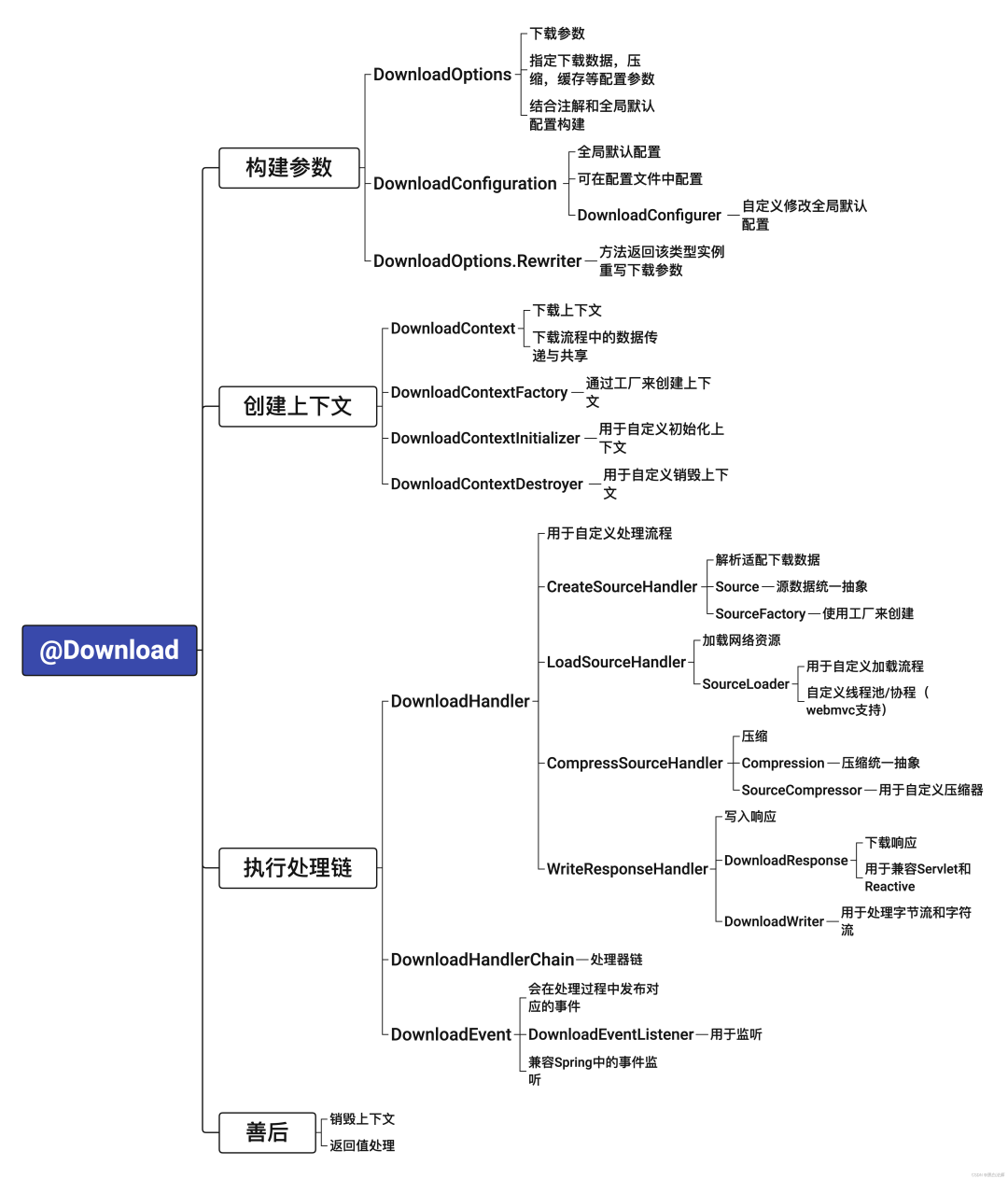
如图所示,一个下载请求的处理被分解为构建参数、创建上下文、执行处理链和善后清理四个主要阶段。其中,“执行处理链”是核心,它包含了一系列可插拔的处理器(DownloadHandler)。
核心组件解析
-
处理器链 (DownloadHandlerChain)
参考了 Spring Cloud Gateway 的设计,将下载流程中的各个步骤(如解析数据源、加载资源、压缩、写入响应)抽象为独立的 DownloadHandler,并通过 DownloadHandlerChain 组织执行顺序。这种设计使得添加或替换处理步骤变得非常容易,极大地提升了 系统架构 的灵活性。
-
统一的下载源抽象 (Source)
为了支持多种类型的数据下载(如 File、HTTP URL、自定义对象等),框架将所有的下载对象抽象为 Source 接口。针对不同类型,有相应的 SourceFactory 来负责识别和创建 Source 实例。例如,FileSourceFactory 处理 File 对象,HttpSourceFactory 处理以 http:// 开头的字符串。
对于自定义对象(如上文的 Device),框架通过反射解析类上的注解(如 @SourceModel, @SourceObject, @SourceName),动态地创建对应的 Source,实现了高度的灵活性。
-
响应式兼容与并发加载
为了同时支持 WebMVC 和 WebFlux,框架在底层做了大量兼容工作。例如,将响应对象抽象为 DownloadResponse,并为两种编程模型提供了不同的实现。对于需要从网络加载的资源(如HTTP图片),框架提供了 SourceLoader 接口,允许开发者自定义并发加载策略,例如使用特定的线程池或协程。
-
可扩展的压缩与写入
压缩功能通过 SourceCompressor 接口抽象,默认支持ZIP格式,也允许用户实现自己的压缩算法。响应写入则通过 DownloadWriter 接口处理,它负责操作底层的 InputStream 和 OutputStream,并可以处理如断点续传(Range 头)、字符编码等细节。
-
事件监听与日志
整个处理链在执行过程中会发布多种事件(DownloadEvent),并支持通过 DownloadEventListener 进行监听。基于此事件机制,框架内置了详细的日志功能,可以记录每个处理步骤、进度更新以及时间消耗,这对于监控流程和调试问题非常有帮助。
实践中的挑战与解决方案
在实现过程中,兼容 WebFlux 的响应式编程模型是一个挑战。在 WebMVC 中,可以通过 RequestContextHolder 获取请求响应对象,但在 WebFlux 中不行。一种方案是通过方法参数注入,但这不够优雅。最终,通过实现一个 WebFilter,将请求响应对象存入 Reactor Context,从而在后续流程中无需显式传递即可获取。
另一个挑战是响应写入后的清理工作。在处理器链中,响应写入后通常意味着流程结束,其后的处理器(如上下文销毁)可能不会被调用。解决办法是将上下文初始化和销毁逻辑独立于处理器链,并在响应式流的 doAfterTerminate 回调中执行销毁操作。
总结
通过 @Download 注解及其配套的框架设计,我们可以将复杂的文件下载逻辑简化为简单的声明式编程。开发者只需关注“下载什么”和“如何命名”,而“怎么下载”的细节则由框架妥善处理。这种模式不仅提高了开发效率,减少了重复代码,也通过清晰的模块化设计,为应对未来更复杂的需求变化提供了良好的 开源项目 扩展基础。无论是简单的单文件下载,还是需要并发抓取、动态压缩的批量文件导出,都可以通过这一套方案优雅地实现。 |  发表于 2026-1-6 19:23:34
|
查看: 235|
回复: 0
发表于 2026-1-6 19:23:34
|
查看: 235|
回复: 0
