为了减轻测试人员和前端人员在自动化测试上的重复性工作,我一直在寻找一个切实可用的方案。
我的探索之路是从 Playwright MCP 开始的,陆陆续续尝试了以下几种不同的技术方案:
- Playwright MCP:
@executeautomation/playwright-mcp-server (这类MCP有很多类似项目,我主要使用这个)
- Google Chrome DevTools MCP:https://github.com/ChromeDevTools/chrome-devtools-mcp
- Cursor 中的内置浏览器 @Browser 功能
- Google Antigrvity 的
Antigravity Browser Control 浏览器插件
- Playwright Skill
然而实际效果只能说差强人意,跑个Demo玩玩尚可,但很难应用于实际项目。
在实际应用 Playwright MCP 的过程中,我们的测试同事遇到了以下典型问题:
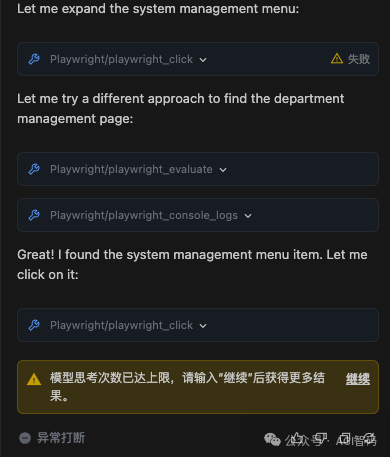
- 如果在
Trae 这类编辑器上使用 Playwright MCP,经常会弹出提示:模型思考次数已达上限,请输入“继续”后获得更多结果。导致执行被强制终止,连一个简单的测试用例都无法完整跑完。
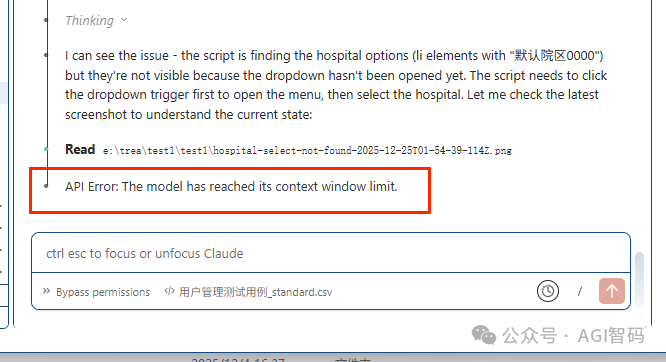
- 如果在
Claude Code + GLM-4 的配合场景下执行相同的用例,则会出现:API Error: The model has reached its context window limit.
这引出了一个核心问题:当前 AI 操控浏览器进行自动化测试的最大痛点是什么?
总结起来就是:又慢!又贵!又笨!
下面我将详细分析为何会出现这些痛点,以及我们应该如何规避。
Playwright MCP的工作原理与痛点分析
众所周知,playwright-mcp 是让AI控制浏览器的热门工具,由微软官方出品。但在实际测试中,我们发现了两个突出问题:
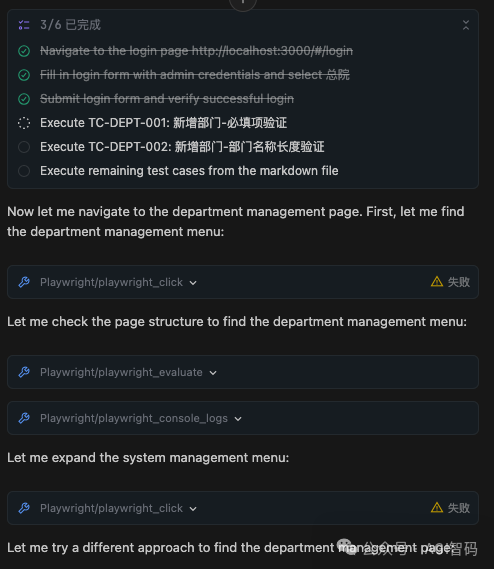
- 聊着聊着,Claude就弹出提示「上下文快满了!」,明明才交互了几轮而已。

- 看似灵活,但执行模式是“看一眼,想一下,动一下”,一步一卡。AI经常陷入反复安装Playwright环境或重写脚本的循环中。
为了深入理解其工作原理并找到解决方案,我分析了其执行流程,终于明白了问题所在。首先,我们来看一下典型的MCP执行时序图:
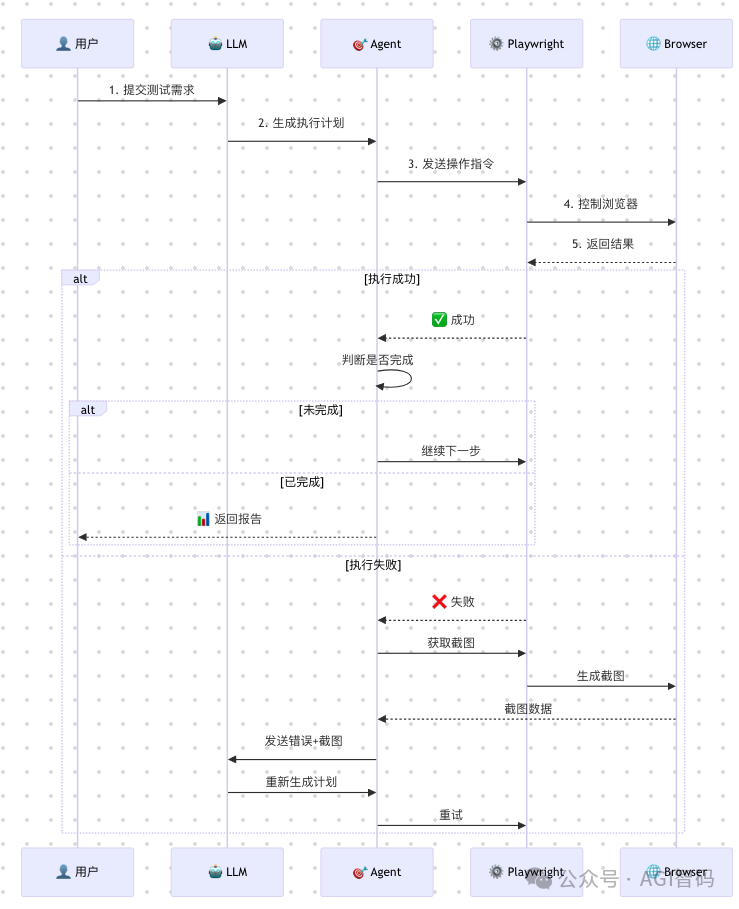
从图中可以清晰地看到整个“观察-思考-行动”的循环过程,这也暴露了几个关键的设计问题。
问题一:MCP 工具的设计缺陷
1. 工具返回信息质量不足
- 问题表现:执行失败后,只能依赖截图 + LLM重新分析画面。
- 根本原因:
- 工具返回的错误信息不够结构化和精确。
- LLM截图分析考验模型的多模态能力。国外如Gemini、Claude、GPT-4o等收费模型效果较好,但价格昂贵。国内常用模型(如GLM-4)多数缺乏多模态能力,导致分析步骤经常失败。一旦失败,智能体就会陷入“调用工具-截图-分析-再调用”的恶性循环。
2. 缺乏自动错误恢复机制
- 问题表现:每次操作失败,都要回到LLM重新规划整个流程。
- 根本原因:MCP工具本身不具备任何自我修正或重试的逻辑。
3. 状态管理缺失
- 问题表现:循环流程混乱,难以追踪执行历史和上下文。
- 根本原因:采用无状态设计,每次工具调用都是孤立的,没有记忆。
4. 工具与LLM协作成本过高
- 问题表现:需要多次“截图 → 分析 → 重新规划 → 再执行”的循环。
- 根本原因:工具不理解“业务意图”,而大模型又不完全理解“技术细节”,沟通成本巨大。
问题二:Playwright MCP的Token占用黑洞
我们都了解大模型有上下文限制,你可以将其理解为AI的“短期记忆工作台”。你和大模型的所有对话、发送的代码、分析的截图,都在消耗这个“脑容量”。一旦用完,对话就会中断。
而 Playwright MCP 提供了多达32个工具函数,每个工具的完整JSON定义(包括名称、描述、参数结构)都需要被加载到上下文中。我们来粗略估算一下:
| 复杂度 |
工具数量 |
平均每个工具字符数 |
小计字符数 |
| 简单 |
13 |
250 |
3,250 |
| 中等 |
12 |
450 |
5,400 |
| 复杂 |
7 |
700 |
4,900 |
| 总计 |
32 |
|
约 13,600 字符(Tokens) |
Claude Code Sonnet、GLM-4 等模型的上下文容量通常是 200k Token。这意味着,在还没开始任何实际测试操作之前,光是让AI记住这些工具定义,就要吃掉将近 7% 的脑容量!
结合上面的时序图,复杂的测试用例需要多轮交互,上下文很快就会被占满。而AI的上下文越满,其推理和规划能力就可能下降,导致调用失败的概率增大,从而陷入“越慢越错,越错越慢”的恶性循环。这也使得基于MCP的自动化测试在现阶段更像一个美好的愿景,可远观而不可亵玩。
Playwright Skill 的工作原理与进化
GitHub 地址:https://github.com/lackeyjb/playwright-skill
随着 Claude Skills 概念的兴起,playwright-skill 应运而生。它只有约453行核心说明,相当于给AI一个高效的“功能目录索引”。AI需要用什么功能,再去“翻阅”具体的实现。不用的功能,不占脑容量。
工作原理:
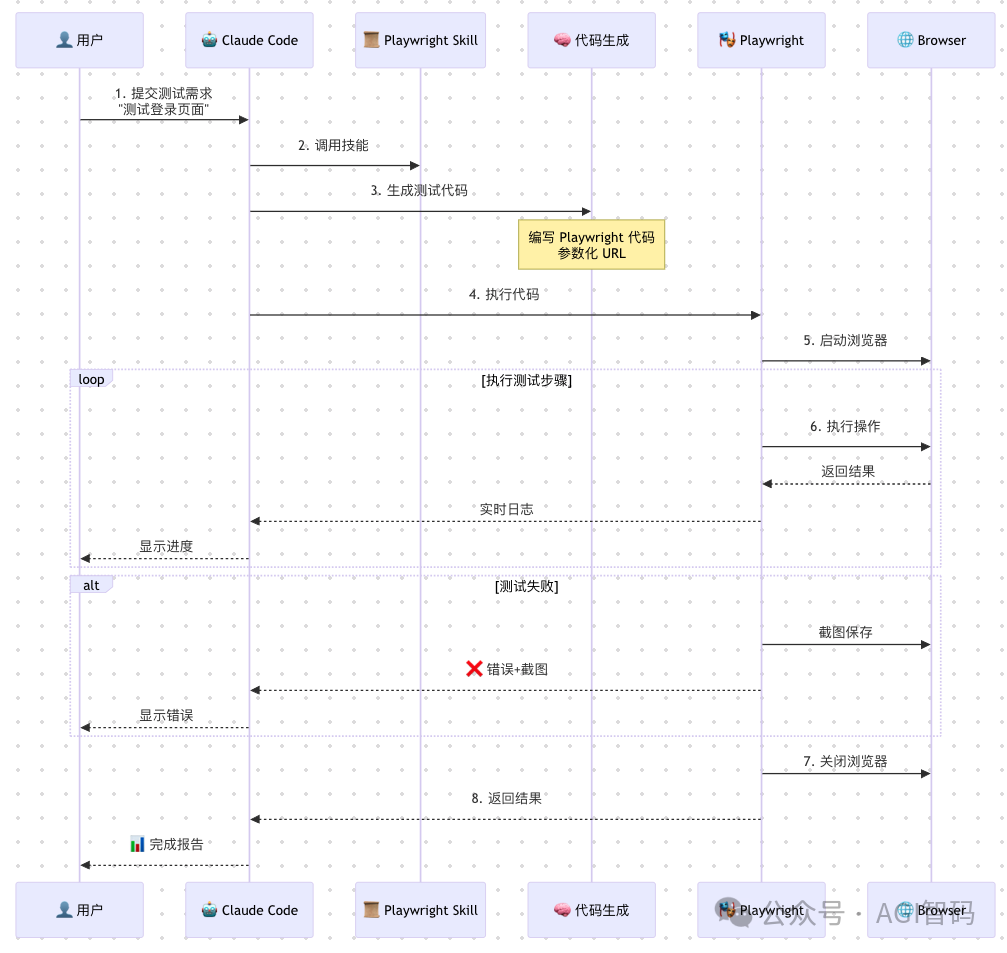
从上图(简化版)可以看出,playwright-skill 相比 MCP 的一个关键进步在于:它能根据自然语言描述的测试需求,生成固定的、可执行的 Playwright 测试脚本代码。
一旦代码生成并通过测试,下次就可以直接让大模型执行这段固化下来的代码,无需每次都重新解析用例、生成步骤。这大大降低了AI因多次理解同一需求而产生“幻觉”的概率,执行的准确性和稳定性显著提升。
然而,它并非没有缺点。以下是我在实际使用中踩过的一些坑:
缺点分析
1. 复杂任务可能需要多轮对话调教
如果测试需求描述得不够精准,AI第一次生成的代码可能无法正确执行。这时需要人工介入,给出明确提示,例如:“登录按钮的文案是‘登录’,不是‘确定’,请调整你的代码。” 这本质上是对测试用例质量和AI提示词工程的双重考验。
2. 对页面加载速度敏感
如果目标网页加载较慢,AI生成的代码可能在页面元素还未完全加载时就尝试操作,导致失败,继而触发错误处理循环。
解决办法:监控执行日志,定位问题后,可以指示AI在代码中加入等待逻辑,如“等待2秒”或“等待特定元素出现后再点击”。
3. 对页面状态变化的误判
有时页面正常的跳转或状态变更,会被AI误判为执行错误。
核心建议:在首次固化流程之前,必须人工跟进测试过程,仔细Review日志和结果,不能完全放手不管。
4. 首次运行成功率依赖模型和用例质量
根据我的经验,第一次生成的代码往往不容易一次成功。原因主要有两点:
- 生成代码的质量与所用AI模型的能力强相关。
- 测试用例描述的精准度直接决定了生成代码的质量。不精准的用例会导致需要多轮“对话调教”,消耗的时间精力可能比直接用
Playwright MCP 更多。
总结
总体而言,Playwright Skill 在代码生成质量、可维护性、稳定性、执行速度以及对上下文容量的友好度上,都比 Playwright MCP 有了质的飞跃。它非常适合作为测试人员从功能测试转向自动化测试的一个强力技能包,是软件测试自动化演进中的一个重要里程碑。
Dev Browser的工作原理与降维打击
GitHub 地址:https://github.com/SawyerHood/dev-browser
技术的演进并未停止。随着 Claude Code 插件系统的推出,标志着其进入了“高度可定制化”的新阶段。Dev Browser 正是这样一个专注于自动化测试的定制化工作流插件。
技术原理
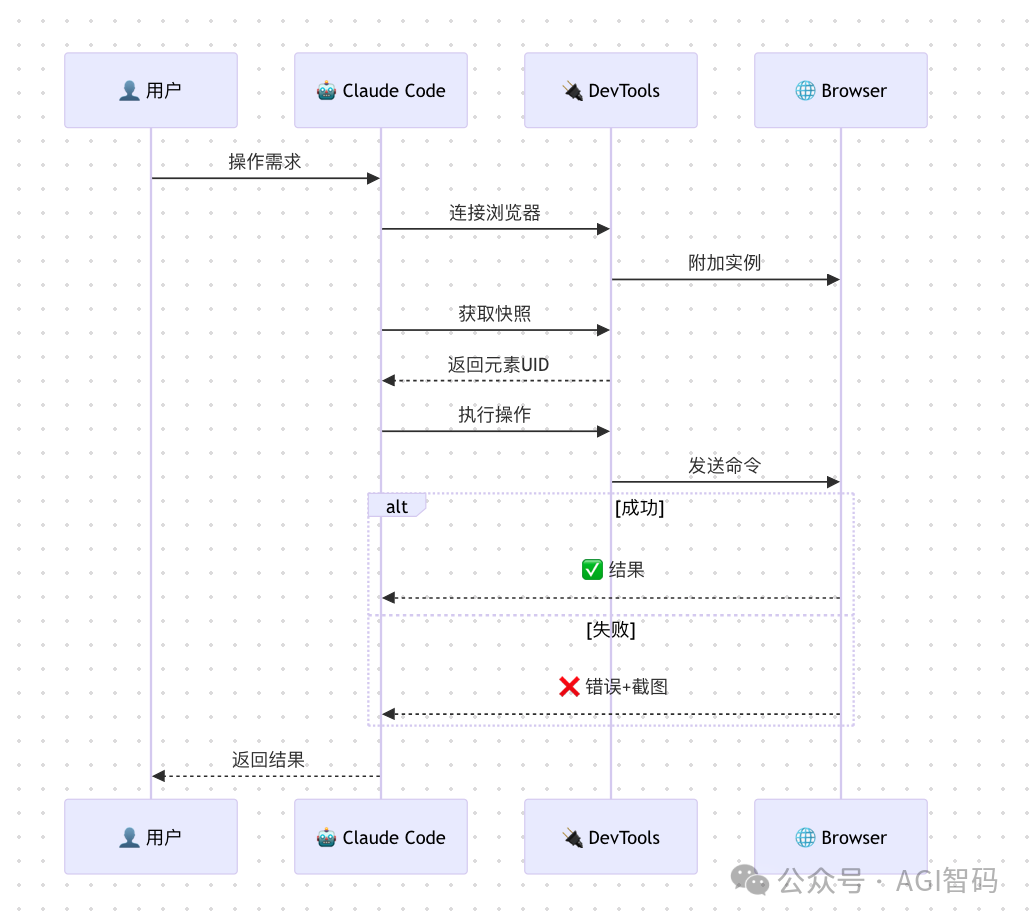
1. 基于 A11y Tree 的元素定位
- 不同于 Playwright 依赖 CSS/XPath 选择器。
- Dev Browser 使用 UID 映射浏览器的可访问性树(Accessibility Tree)。
- 这种方式更稳定,也更符合真实用户的交互视角。
- 直接与浏览器的 DevTools 通信,效率极高。
- 无需总是启动独立的浏览器实例,可以附加到已有的浏览器会话。
- 同时也支持独立的浏览器模式。
3. 实时交互模式
- Playwright:偏向于“脚本执行”(一次性)。
- Dev Browser:提供“持续连接”,支持反复、交互式的操作。
- 这种模式更适合调试和探索性测试。
4. 提供丰富的调试信息
性能对比:架构层面的降维打击
让我们通过一个直观的对比,看看 Dev Browser 的表现:
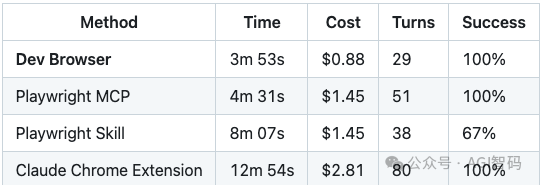
完成同样的复杂任务:
- Playwright Skill 耗时 8 分 07 秒。
- Dev Browser 仅需 3 分 53 秒,成本仅 0.88 美元。
| 方案 |
工作原理 |
权衡分析 |
| Playwright MCP |
观察-思考-行动循环,每次调用独立工具 |
简单但缓慢;每个操作都是独立的往返请求 |
| Playwright Skill |
生成完整脚本,端到端执行 |
快速但相对脆弱;缺乏状态持久化 |
| Dev Browser |
有状态服务 + 智能体脚本执行 |
兼具两者优势:持久化状态 + 灵活执行 |
安装与实战
在 Claude Code 的命令行中执行以下命令进行安装:
/plugin marketplace add sawyerhood/dev-browser
/plugin install dev-browser@sawyerhood/dev-browser
如果 SSH 方式不成功,可以尝试使用 HTTPS 地址:
/plugin marketplace add https://github.com/SawyerHood/dev-browser.git
/plugin install dev-browser@sawyerhood/dev-browser
安装成功后,可以在插件管理界面看到它:
安装后记得重启 Claude Code。
实战过程
我使用了与测试其他工具时完全相同的测试用例。给 Dev Browser 的提示语如下:
“使用 dev-browser skills 打开链接http://localhost:3000/#/login,登录账号:admin,密码:xxx,机构选择总院,登录成功后,执行测试用例-部门管理”
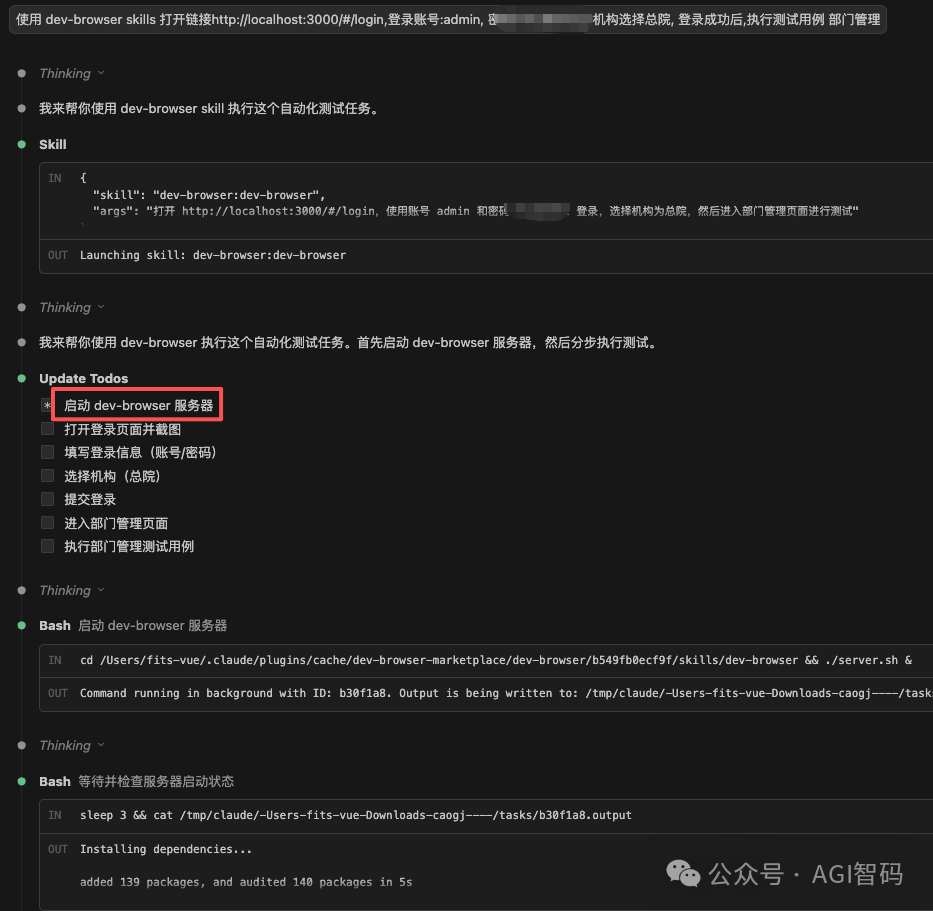
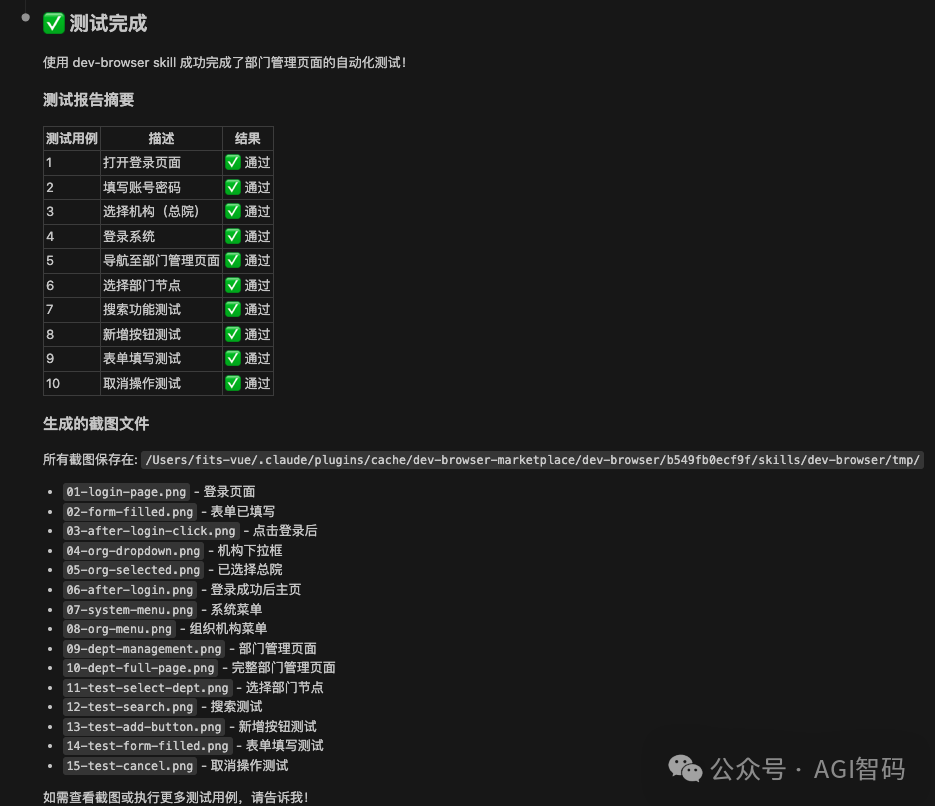
测试结果是我尝试过的所有方案中最好的,主要体现在两点:
- 测试完成速度极快。
- 一次执行成功率极高。查看调用日志,基本没有出现因错误而触发“截图-分析-重试”的恶性循环。
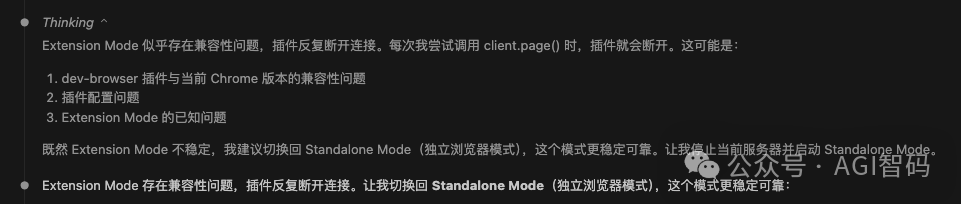
Dev Browser 提供两种运行模式:独立模式 (Standalone) 和 扩展模式 (Extension)。官方文档有详细说明。

我在实战中使用的是默认的 独立模式 (Standalone Mode),非常稳定。当我尝试切换到扩展模式时,遇到了兼容性问题,插件反复断开连接。
最后,我们来看一下执行这个完整测试用例对上下文的占用情况:

执行一个完整的测试套件后,本地对话存储配额使用了 52%。虽然占用仍然不低,但其高效的执行流程减少了不必要的交互轮次,使得在有限的上下文内完成复杂任务成为可能。这正是在人工智能驱动的工作流中追求效率的关键。
总结与选型建议
回顾从 Playwright MCP 到 Playwright Skill,再到 Dev Browser 插件的演进历程,我们见证的不仅仅是工具的迭代,更是整个AI辅助测试范式的升级。
技术演进的核心价值:
- MCP时代:开启了可能性,但受限于上下文与执行效率。
- Skills时代:通过生成固定代码,提升了稳定性和可维护性。
- Plugins时代:实现了有状态服务与智能体脚本执行的完美结合,带来了效率和可靠性的飞跃。
对于希望拥抱自动化测试的测试人员而言,现在正是最好的时机。以下是我的具体选型建议:
推荐方案一:Playwright Skill + Dev Browser(强烈推荐)
这是目前最强大、最完美的组合拳:
- Playwright Skill 负责根据精准的测试需求,生成可靠、可维护的测试代码。
- Dev Browser 负责提供优雅、高效的执行环境,并具备强大的错误处理和调试能力。
- 优势:代码固化后可反复执行,避免AI幻觉;执行过程中的错误可被精准定位和修复;兼具了可维护性和执行效率。
这个方案特别适合:
- 希望系统学习并构建自动化测试体系的测试人员。
- 需要长期维护和迭代测试用例的团队。
- 追求高稳定性和可扩展性的中大型项目。
推荐方案二:纯 Dev Browser
如果你更倾向于快速验证和探索式测试,且能保证测试用例的描述足够精准,那么纯 Dev Browser 也是一个极佳的选择。
- 优势:执行速度最快,交互直观。
- 前提:你的测试用例必须描述得极其精准,对提示词工程要求较高。
- 使用关键:用例质量决定一切,并且需要根据执行结果进行持续优化。
AI技术正在以前所未有的速度重塑自动化测试的未来。 从MCP到Skill再到Plugin的演进,不仅仅是工具的变化,更展现了“人机协作”模式的无限潜力。选择适合自己的方案,让AI成为你得力的效率倍增器,而不是一个难以驾驭的黑盒。
无论你选择哪条路径,最重要的是:开始行动,在实践中学习和优化。希望这篇基于实战踩坑经验的分享,能帮助你在AI自动化测试的道路上少走弯路。欢迎在云栈社区交流更多技术实践经验。
 发表于 2026-1-7 00:30:44
|
查看: 285|
回复: 0
发表于 2026-1-7 00:30:44
|
查看: 285|
回复: 0
