在日常学习和工作中,你是否遇到过这些令人头疼的场景:看到技术文章里的代码截图想复制下来测试,却只能对着图片一个字母一个字母地敲;遇到扫描版的PDF文档,其中的文字无法选中,想引用时只能手动重打;或者在看教学视频时,屏幕上出现的错误提示或关键信息无法复制,想搜索解决方案都变得异常困难。
之前,为了解决这些问题,我尝试过不少OCR(光学字符识别)软件。它们要么需要联网调用第三方API,存在隐私泄露的顾虑;要么需要作为后台服务常驻运行,占用宝贵的系统内存;还有一些功能完善的,价格却令人望而却步。直到我发现了 Text Grab,一个基于 Windows 系统原生 OCR 引擎构建的免费开源工具,它让我彻底告别了那些付费或联网的 OCR 软件。
Text Grab 是什么?
简单来说,Text Grab 是一个轻量级的 Windows 应用程序。它的核心价值在于,直接调用并封装了 Windows 10/11 系统自带的 OCR 引擎,将微软内置的强大识别能力以一种极其便捷的方式呈现给用户。这意味着它具有以下突出优势:
- ✅ 完全离线运行:所有识别过程均在本地计算机上完成,无需连接互联网,不调用任何云端 API。
- ✅ 零后台占用:随用随开,用完即关。不需要像某些工具那样常驻后台,彻底解放系统资源。
- ✅ 免费且开源:软件在 GitHub 上完全开源,所有功能免费使用,无任何订阅或付费陷阱。
- ✅ 轻量且快速:安装包体积仅数 MB,识别速度几乎在瞬间完成,体验流畅。
本质上,Text Grab 扮演了一个“桥梁”的角色,它把 Windows 系统中已经存在但隐藏较深的 OCR 功能,通过一个简洁直观的界面暴露出来,让我们普通用户能够轻松调用。
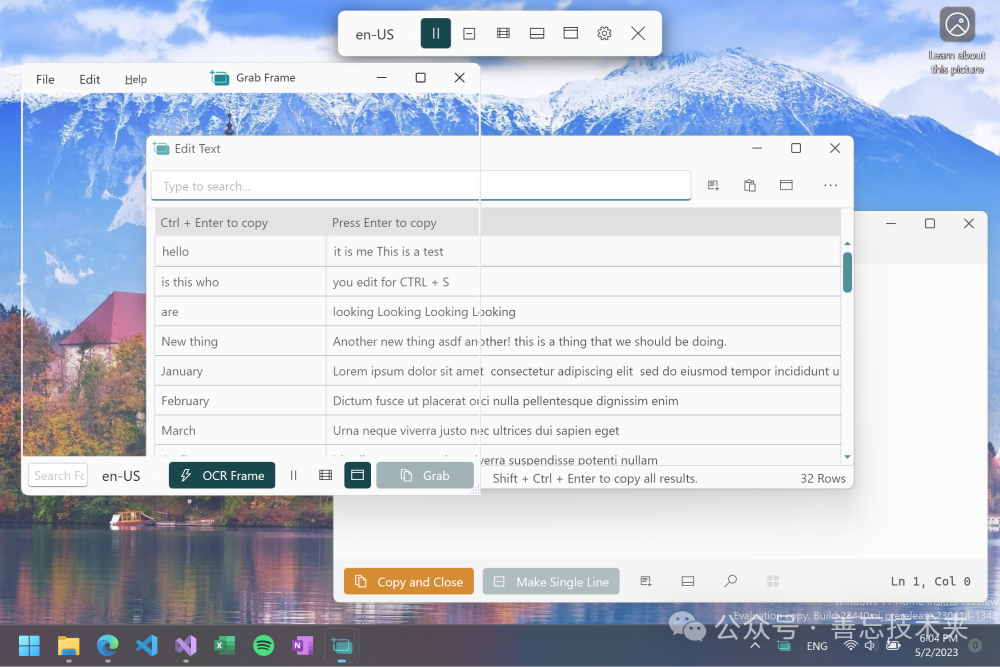
Text Grab 主界面,支持快速查找、编辑文本、抓取窗口等多种模式。
如何安装与使用?
安装方式
Text Grab 提供了三种灵活的安装途径,你可以根据使用习惯选择:
- Microsoft Store(推荐):直接在 Windows 应用商店中搜索 “Text Grab” 并安装。这是最省心的方式,支持自动更新。
- GitHub Releases:前往项目的 GitHub Releases 页面下载最新的安装包进行手动安装。
- Winget 命令行:如果你喜欢命令行,可以通过管理员权限打开终端,输入命令
winget install TextGrab 一键安装。
对于大多数用户而言,通过 Microsoft Store 安装是最便捷的选择。
核心使用模式
安装完成后,Text Grab 主要通过三种模式来应对不同的识别需求:
1. 全屏模式
这是最高效的常用模式。按下默认快捷键 Win + Shift + T,整个屏幕会变暗,此时用鼠标拖拽框选你想要识别的任意区域。松开鼠标后,框选区域内的文字会立即被识别并自动复制到系统剪贴板,你可以直接粘贴到任何地方。
2. 抓取窗口模式
此模式会打开一个可调整大小和位置的透明窗口。你可以将这个窗口拖放到需要持续监控或反复识别的位置(例如视频播放器的字幕区域),软件会实时识别窗口覆盖区域的文字,并显示在编辑框中,方便你随时复制。
3. 编辑文本模式
这是一个功能更全面的编辑器窗口。你不仅可以打开图片文件(如 PNG、JPG)进行直接识别,还能对识别后的文本进行查找、替换、朗读等编辑操作,并最终将结果保存为 .txt 文本文件。
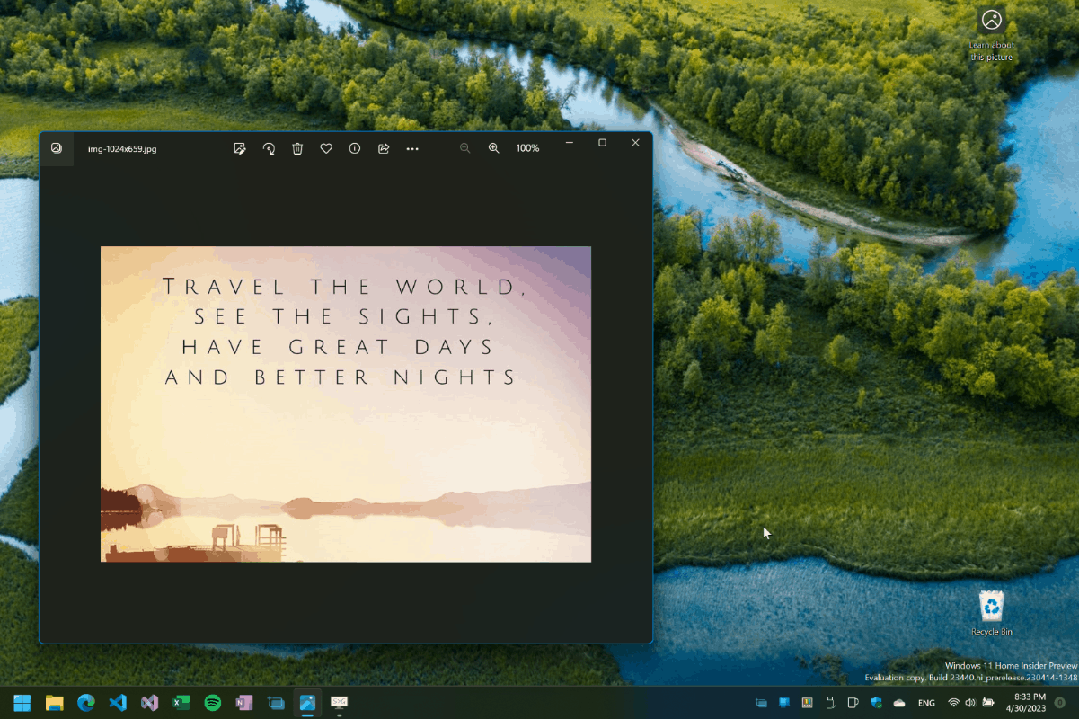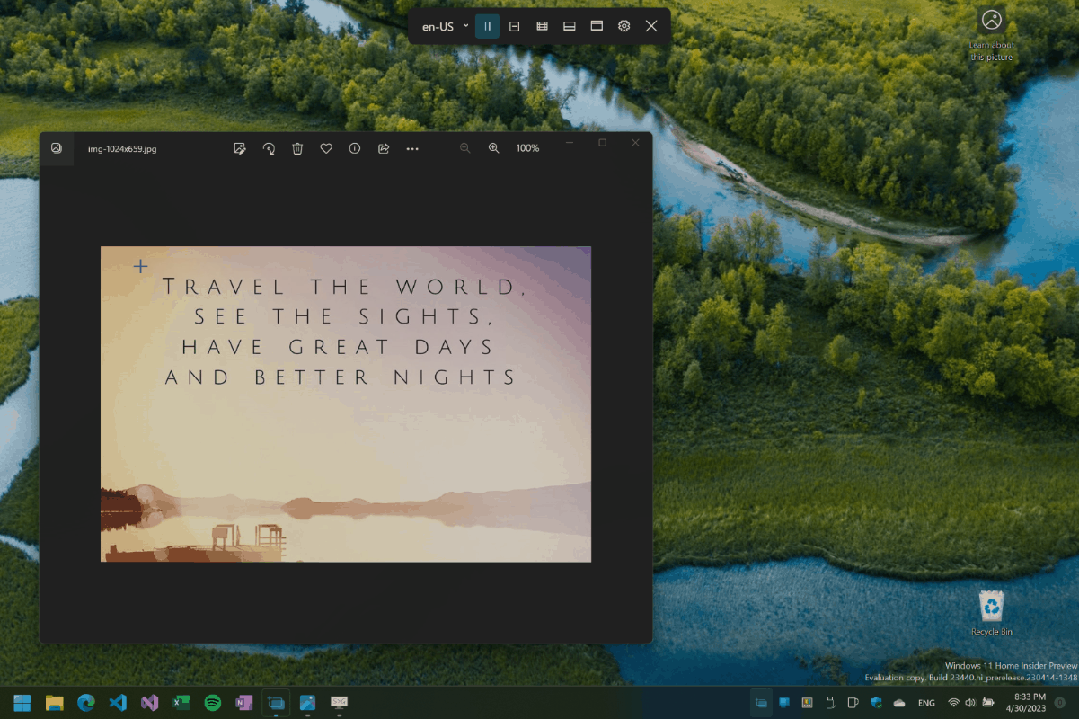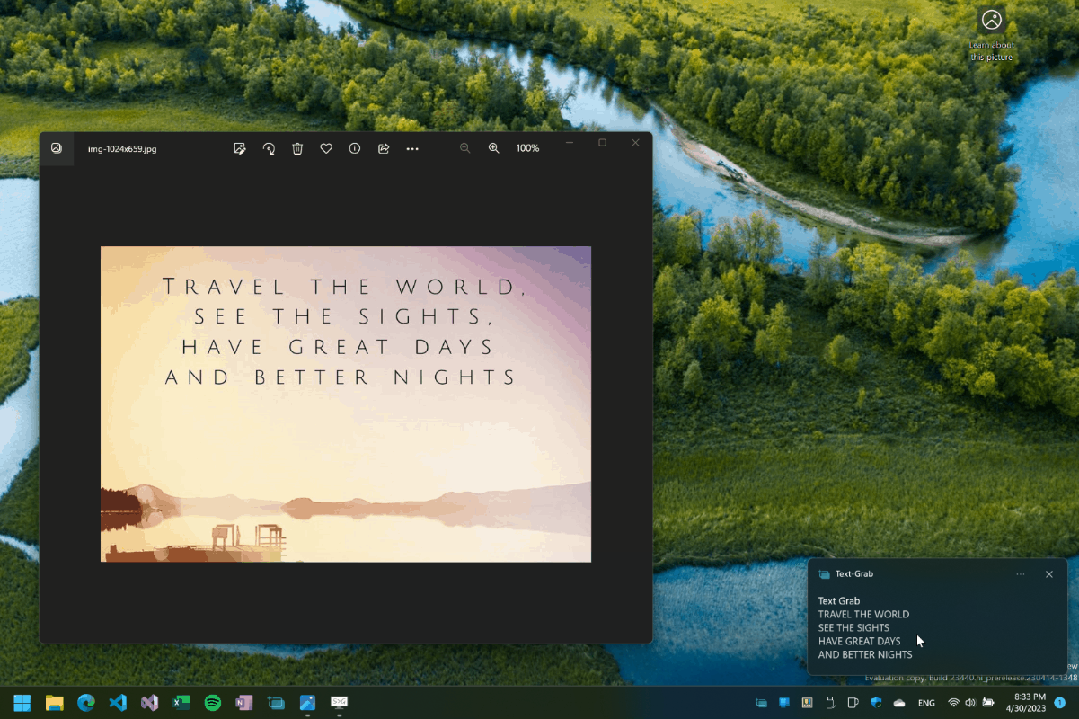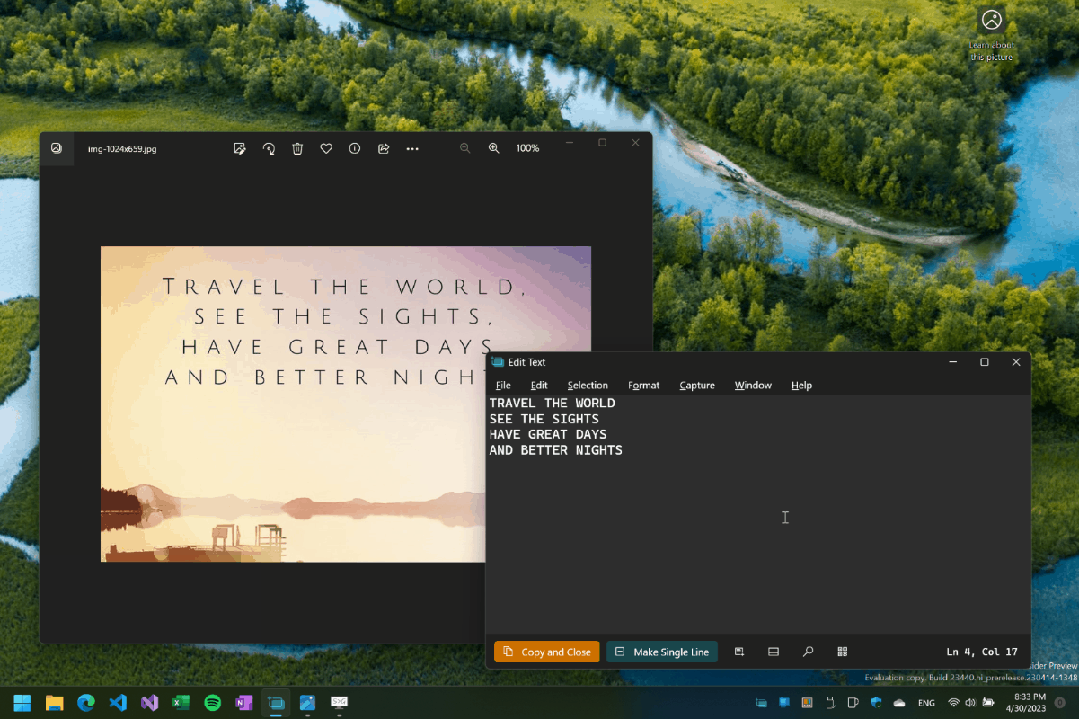
全屏模式演示:按下快捷键后框选区域,文字即被识别并复制。
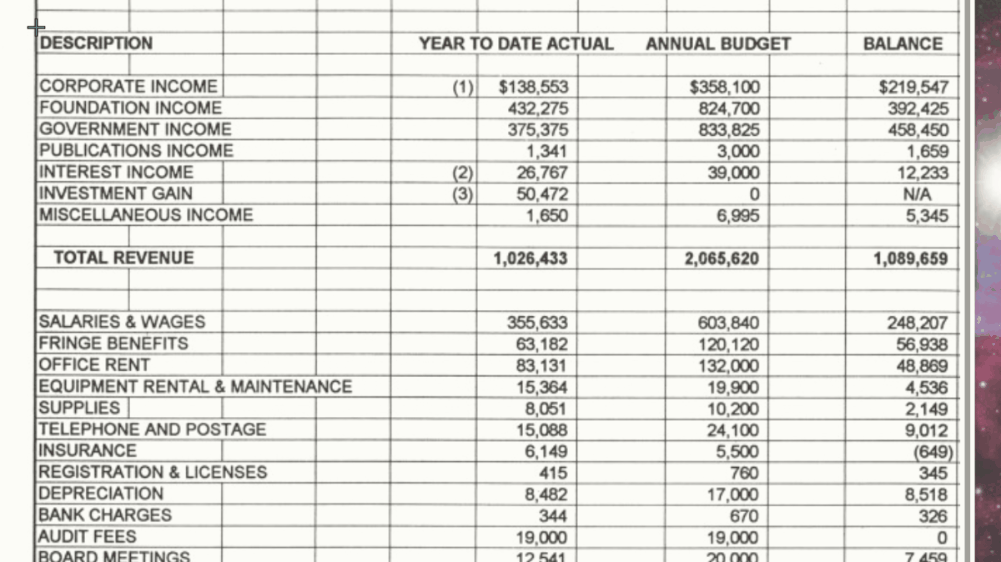
抓取窗口模式示例:将透明窗口置于表格上方,持续识别其中的数据。
快速查找模式:即时识别桌面上的文本信息并进行搜索。
实际体验与评价
经过一段时间的深度使用,Text Grab 在大多数场景下的表现令人满意:
优点:
- 识别速度极快:得益于本地引擎,识别过程几乎是即时的,远超需要网络请求的在线工具。
- 中英文混合识别准确率高:对于技术文档、代码截图、网页文字等印刷体,识别准确率很高。
- 支持多语言:除了中英文,还支持日语、韩语、法语、德语等多种语言识别。
- 隐私安全保障:所有处理均在本地完成,彻底杜绝了敏感信息上传至云端的风险。
- 快捷键提升效率:熟练使用
Win + Shift + T 快捷键后,整个提取文字的流程行云流水。
缺点与局限:
- 系统版本依赖:需要 Windows 10 版本 1903 或更高,以及 Windows 11。
- 手写体识别能力一般:对于较潦草的手写文字,识别率较低。
- 复杂排版可能出错:面对多栏排版、图文混排复杂的文档,识别出的文字顺序偶尔会出现混乱。
- 不擅长特殊内容:对于数学公式、化学方程式等特殊符号的识别效果不理想。
主流OCR工具横向对比
为了更清晰地定位 Text Grab,我们将其与市面上其他几款常见 OCR 工具进行简要对比:
| 特性 |
Text Grab |
天若OCR |
QQ/微信截图OCR |
ABBYY FineReader |
| 价格 |
免费开源 |
免费 |
免费 |
付费(昂贵) |
| 是否需要联网 |
否 |
是 |
是 |
否 |
| 后台占用 |
无 |
需常驻 |
需常驻 |
需常驻 |
| 识别速度 |
极快 |
快 |
快 |
较快 |
| 中文识别率 |
90%+ |
95%+ |
90%+ |
95%+ |
| 英文识别率 |
95%+ |
90%+ |
90%+ |
98%+ |
| 支持语言 |
多语言 |
中英为主 |
中英为主 |
超100种语言 |
| 批量处理 |
支持 |
不支持 |
不支持 |
支持 |
| 隐私性 |
极好 |
一般 |
一般 |
好 |
通过对比可以看出,Text Grab 的核心竞争力在于其 “完全离线、零后台驻留、免费开源” 的铁三角组合。如果你追求极致的识别精度和专业文档处理,ABBYY 仍是行业标杆;如果需要便捷的联网快速识别,天若OCR和社交软件内置功能也不错。但如果你优先考虑轻量化、隐私安全和即开即用的体验,那么 Text Grab 无疑是 Windows 平台上的最佳选择之一。
四个典型实用场景
1. 提取程序错误日志
开发调试时,命令行终端或错误弹窗中的报错信息常常无法直接复制。使用 Text Grab 全屏模式框选错误信息,瞬间复制后粘贴到搜索引擎或 技术论坛 求助,极大提升排错效率。
2. 复制教程中的代码截图
技术博客、视频教程里展示的代码片段通常是图片格式。用 Text Grab 识别后,稍作格式调整即可投入运行或保存,省去大量重复手敲的时间。
3. 提取视频字幕或旁白
观看没有提供字幕文件的外语教学视频时,可以暂停画面,使用抓取窗口模式覆盖字幕区域,轻松提取关键句子用于记录或翻译。
4. 转换扫描版PDF内容
对于无法选中文字的扫描版PDF文档,可以截图后使用 Text Grab 的编辑文本模式打开图片进行识别,将图像内容转化为可编辑的文本。
总结与适用建议
推荐指数:⭐⭐⭐⭐⭐
适合人群:
- 需要频繁进行OCR操作,但不喜欢安装重型软件或后台服务的用户。
- 对数据隐私敏感,不希望文字内容上传至任何第三方服务器的用户。
- Windows 10/11 的开发者、学生、文案工作者等各类办公人群。
不适合人群:
- 主要需求是识别大量手写笔迹的用户。
- 需要处理具有复杂版面布局(如杂志、报纸)的专业出版场景。
- 对印刷体文字识别准确率有近乎100%苛求的用户。
总而言之,Text Grab 凭借其调用系统原生能力的独特优势,在免费、轻量、隐私和便捷性之间找到了一个完美的平衡点。它让我意识到,我们手边的 Windows 系统其实蕴藏着不少未被充分利用的宝藏功能。如果你也经常与图片中的文字打交道,不妨现在就试试这款 开源工具。
项目信息:
希望这个工具能像提升我的效率一样,帮助到你。探索和分享好用的工具,也是 云栈社区 所倡导的极客精神之一。
 发表于 2026-1-10 01:17:58
|
查看: 338|
回复: 0
发表于 2026-1-10 01:17:58
|
查看: 338|
回复: 0
