
Agent Lightning 是由 微软亚洲研究院 (MSRA) 开源的一套 AI Agent训练框架。
但它的目标并非“再造一个Agent框架”,而是做了一件更聪明的事:
让你现在已经在用的Agent,在几乎不改代码的情况下,自己变得更聪明。
你可以把它理解为:
- 不是新Agent
- 不是新模型
- 而是一个 专门给Agent做“后天训练”的加速器
一个现实问题:为什么现在的Agent都“越用越僵”?
大多数Agent项目都会遇到相同的瓶颈:
- Prompt一旦写好,能力就固定了
- 任务失败,只能靠人工手动调整Prompt
- 面对多步复杂任务(如SQL生成、代码编写、逻辑推理),一步错往往导致步步错
- 缺乏系统性的方法来自动诊断:“Agent到底是在哪一步犯了错?”
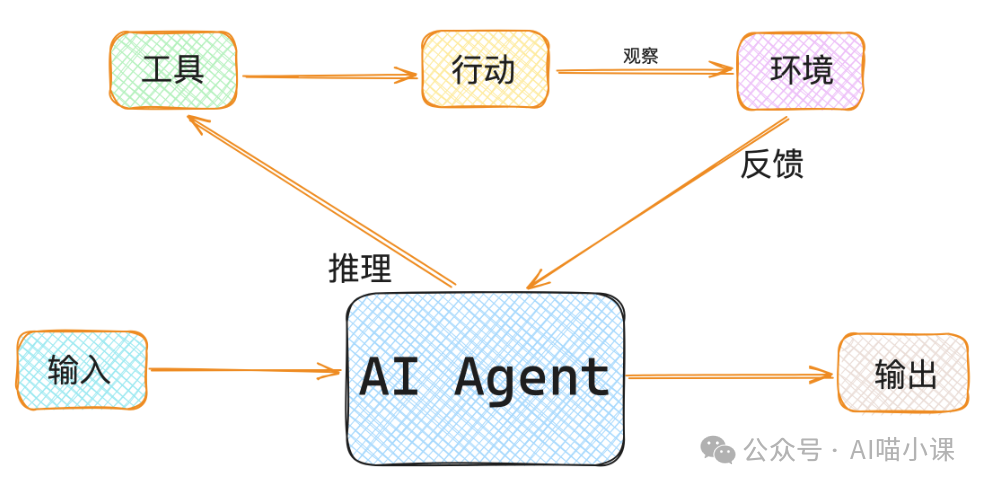
简而言之,目前许多Agent本质上仍是 静态策略执行器,而非具备学习进化能力的智能系统。Agent Lightning 正是瞄准了这一核心痛点。
核心思想:不改Agent,让Agent学会进化
Agent Lightning的核心设计理念非常明确:
训练逻辑,不能和Agent的业务逻辑绑在一起。
零侵入式优化(最大亮点)
它做出了一个非常“工程师友好”的设计决策:
- Agent怎么写,你照旧
- 训练这件事,完全交给Agent Lightning
具体体现在三个方面:
- 代码解耦 (Decoupling)
Agent的执行逻辑与训练逻辑彻底分离。你无需为了引入训练能力而重构现有的Agent代码。
- 框架通用性极强
它已支持或可以轻松接入主流Agent开发框架,如 LangChain、AutoGen、OpenAI Agent SDK、CrewAI,甚至是纯Python编写的自定义Agent。
- 越用越聪明
框架会持续收集Agent在真实场景中的执行轨迹,通过强化学习或Prompt优化等技术,反向改进其决策策略,实现持续进化。
Agent Lightning 到底是怎么工作的?
Agent Lightning 采用了一个非常清晰和“干净”的架构设计,官方称之为:
Training–Agent Disaggregation (训练–智能体分离)
你可以将其理解为由两个核心角色协同工作。
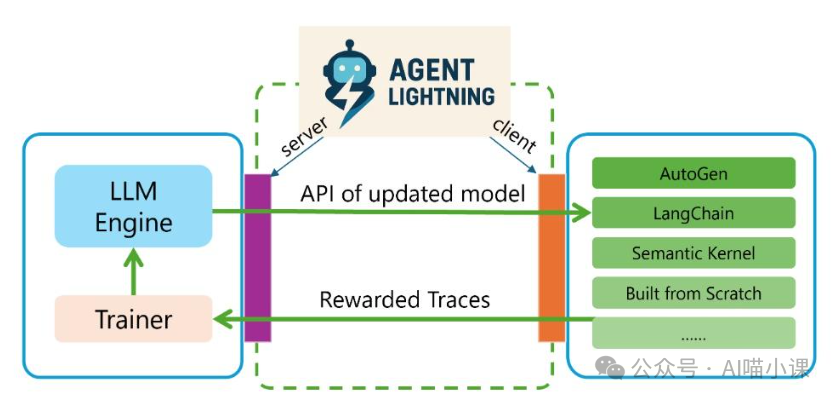
Lightning Client:贴在Agent身上的“黑匣子”
这是一个非常轻量的运行时组件。它不控制Agent的行为,只专注于三件事:
- 观察 Agent每一步的执行动作。
- 抽象 将这些行为建模为:状态 (State) → 动作 (Action) → 奖励 (Reward) 的序列。
- 发送 将完整的执行轨迹发送给Server端。
在理论上,这一步将Agent的执行过程转化为了一个 MDP(马尔可夫决策过程)。但对工程师而言,只需记住一句话:
Client只负责“记录”,不负责“思考”。
Lightning Server:真正负责“让Agent变聪明”的中枢
Server端是训练的核心大脑,负责:
- 托管强化学习等训练算法(如内置的LightningRL)。
- 接收来自多个Client Agent的执行轨迹数据。
- 分析哪些行为是好的决策,哪些导致了错误。
- 更新模型权重或优化Prompt策略。
一句话总结:
Agent在业务线干活,Lightning在后台教它怎么干得更好。
它解决的不仅是“效果差”,更是一个老大难问题
关键能力1:信用分配 (Credit Assignment)
这是多步骤Agent任务中最具挑战性的问题之一。例如一个SQL生成Agent:
- 第2步:选错了数据表Schema。
- 第5步:JOIN逻辑写错。
- 最终结果:查询失败。
传统做法需要人工猜测是Prompt的哪部分出了问题。而Agent Lightning能够自动分析并判断,究竟是哪一步的具体动作导致了最终的失败。这对于调试和优化复杂、长链路的任务至关重要。
关键能力2:复杂Agent场景的适配
它并非只优化简单的单轮问答,而是明确针对以下复杂场景进行了设计:
- 工具调用 (Tool-use)
- 多轮对话
- 多Agent协作
- 长链路推理
这也是它与普通Prompt调参工具的本质区别。
适合用在哪些地方?
Agent Lightning 不是万能药,但在以下几个方向,其价值非常明确:
1. Text-to-SQL
- 训练Agent更好地理解数据库结构和查询意图。
- 减少“语法正确但逻辑错误”的SQL生成。
- 非常适合企业内部BI工具或数据查询助手场景。
2. 数学与代码生成Agent
- 提升多步数学推理或代码生成的稳定性。
- 降低任务执行过程中的“思维跑偏”概率。
- 对需要调用计算器、组合多个函数的任务尤其有效。
3. RAG Agent
- 让Agent学会判断 “什么时候需要进行检索”。
- 优化检索策略,学会 “检索什么内容更有价值”。
- 显著减少基于错误检索信息产生的“幻觉”回答。
如何将Agent Lightning集成到现有项目中?
将Agent Lightning集成到现有项目,核心理念是“插件化”。你无需重构业务逻辑,只需像安装“行车记录仪”和“自动驾驶升级包”一样,通过几个步骤完成对接。
以下是集成的标准流程:
1. 环境准备与架构对齐
在开始前,需明确其双端架构:
- Lightning Server:通常部署在高性能服务器上,负责模型训练、参数更新和算法管理。
- Lightning Client:一个轻量级库,嵌入在你的Agent业务代码中,负责数据采集。
2. 集成核心步骤
第1步:环境部署
首先部署Lightning Server。通常可通过Docker或从源码安装:
git clone https://github.com/microsoft/Agent-Lightning.git
cd Agent-Lightning
pip install -e .
第2步:初始化Lightning Client
在你的Agent项目入口文件中,初始化客户端,将你的Agent包装成一个可观测实体。
- 配置连接:指定Server的地址和端口。
- 定义动作空间:告知框架你的Agent有哪些可用的“动作”(如:查询、生成代码、调用API)。
第3步:数据轨迹记录
这是集成中唯一需要轻微改动代码的地方。你需要通过Client API记录Agent的决策过程:
- State (状态):如用户输入、当前对话历史或环境变量。
- Action (动作):Agent生成的回复或调用的具体工具。
- Reward (奖励):这是关键。你需要提供一个反馈信号(例如,任务成功为1,失败为0),Lightning将依据此信号进行优化。
第4步:启动异步训练
一旦Client开始收集数据并回传,即可在Server端启动训练算法(如LightningRL)。Server会:
- 自动构建训练样本。
- 利用强化学习算法微调Agent底层的LLM。
- 支持热更新:将训练好的模型权重推送到生产环境,实现Agent的实时进化。
3. 集成示例 (以LangChain为例)
from agent_lightning.client import LightningClient
# 1. 初始化客户端
client = LightningClient(server_url="http://localhost:8080")
# 2. 包装你的原有 Agent 逻辑
def run_my_agent(user_query):
# 记录初始状态
session = client.start_session(state=user_query)
# 原有的 Agent 执行逻辑(例如基于LangChain)
response = my_langchain_agent.invoke(user_query)
# 3. 记录动作并提供反馈(可通过自动化测试或人工评估生成reward)
reward = evaluate_response(response) # 自定义评估函数
session.record_step(action=response, reward=reward)
session.end()
return response
4. 为什么这种集成方式是高效的?
- 解耦性:业务逻辑(Agent如何执行)与学习逻辑(Agent如何进化)完全分离,互不干扰。这种清晰的系统架构设计提升了维护性。
- 灵活性:如果你需要从LangChain迁移到AutoGen等其他框架,通常只需迁移Client端的几行包装代码,Server端的训练逻辑无需任何更改。
注意事项
- 奖励函数的质量:优化效果高度依赖于你提供的
Reward信号。建议从简单的二元(成功/失败)反馈开始,逐步细化。
- 计算资源:由于涉及模型微调,建议为Server端配置充足的GPU资源(如NVIDIA A100或H100)。
希望本文能帮助你理解并落地Agent Lightning这一强大的Agent训练加速器。如果你在实践过程中有更多心得或疑问,欢迎在云栈社区与广大开发者交流探讨。
 发表于 2026-1-10 09:07:01
|
查看: 191|
回复: 0
发表于 2026-1-10 09:07:01
|
查看: 191|
回复: 0
