向量匹配原理本质上是:
把“对象 / 文本 / 图片 / 行为”等转成向量(一串数字),再用数学方法衡量向量之间的相似度,从而判断它们“有多像”。
下面我们将从直觉 → 数学 → 工程实现 → 应用场景等多层次,系统地讲解其底层原理。
一、直觉层理解
1️⃣ 向量是什么?
向量 = 对一个对象的“特征编码”
比如一句话:
“LangChain可以构建智能体”
它会被编码成类似这样的数字串:
[0.12, -0.33, 0.89, …, 0.07](维度可能是768、1536或3072维)
这串数字代表了这句话的语义,可以看作高维空间中的一个点。
2️⃣ 向量匹配在做什么?
比较两个向量在空间中是否“靠得近”
打个比方:就像地图上的两个地点,距离越近,它们就越相似(例如同在一个商圈)。
二、数学层原理(核心公式)
1️⃣ 最常用:余弦相似度(Cosine Similarity)
这种方法判断两个向量方向是否一致,而不关心它们的长度。
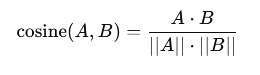
- 结果范围:
[-1, 1]
- 值越接近
1 → 两个向量越相似
- 直觉理解:判断两句话是否“在说同一件事”。这是向量搜索中最常见的指标 ⭐
2️⃣ 欧氏距离(Euclidean Distance)
计算两个点在空间中的直线距离。
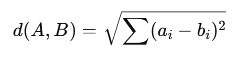
- 距离越小 → 两个点/向量越相似
- 更关心“数值上的绝对差距”
- 常用于图像匹配、物理空间距离计算等场景
3️⃣ 点积(Dot Product)
直接计算两个向量对应维度的乘积之和。
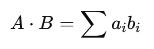
- 不做归一化处理,向量的长度会直接影响计算结果
- 某些近似最近邻(ANN) 检索引擎(如 Faiss)内部优化时会使用点积
三、工程实现流程
🔁 向量匹配完整链路
文本
↓
Embedding模型
↓
向量(高维)
↓
存入向量数据库
↓
相似度计算
↓
Top-K 结果
语义搜索示例:
步骤 1:向量化
query_vec = embed(“如何使用 DeepAgents”)
doc_vec = embed(“LangChain DeepAgents 使用指南”)
步骤 2:计算相似度
cos_sim(query_vec, doc_vec) = 0.91
→ 判定为高度相关
四、为什么“向量能表示语义”?
1️⃣ Embedding模型的训练方式
Embedding模型通过在海量数据上进行训练来学习一个核心规律:
- 语义相似的文本 → 对应的向量在空间中的位置更接近
- 语义不同的文本 → 对应的向量在空间中的位置更远离
例如,模型会学会:
- “猫”的向量 接近 “小猫”的向量
- “数据库”的向量 接近 “SQL”的向量
- “吃饭”的向量 远离 “微积分”的向量
2️⃣ 高维空间的优势
- 高维空间中的每一维都代表一个“隐含的语义特征”
- 维度越高,模型能够表达和区分的语义就越精细、越丰富
- 当前大型语言模型(LLM)生成的Embedding通常为 768、1536 或 3072 维
五、向量匹配的典型应用场景
1️⃣ 语义搜索(Semantic Search)
解决什么问题:
- 传统关键词搜索搜不到相关内容
- 用户使用了同义词或不同的表达方式
向量匹配怎么用:
- 将查询语句和所有文档都转化为向量
- 计算查询向量与所有文档向量的相似度
- 返回相似度最高的 Top-K 个文档
典型场景:
- 企业内部的文档搜索系统
- 技术文档、API文档的智能检索
- 知识库搜索
核心思想:“不是找词一样的,而是找意思一样的”。
2️⃣ 问答系统 / 知识库问答
本质:将用户的问题向量与知识库中的知识片段向量进行匹配。
常见形态:
工程形态:
Question → Embedding → Vector Search → LLM 生成答案
3️⃣ 内容推荐系统
匹配对象:
- 用户兴趣向量(根据历史行为生成)
- 内容向量(文章、视频、商品等)
典型应用:
机制:“你看过的内容,决定你下一条看到什么”。
4️⃣ 用户画像 & 相似用户发现
- 将用户的行为数据(点击、浏览、购买)转化为用户向量
- 通过向量匹配寻找行为模式相似的用户群体
- 应用于精准营销、社群划分、A/B测试分组等
5️⃣ RAG(检索增强生成)
为什么必须用向量匹配?
- LLM自身无法存储私有的、实时的或特定领域的数据
- 需要从外部知识源中实时检索相关信息来支撑LLM生成准确回答
典型RAG流程:
用户问题
→ 向量化
→ 向量数据库检索
→ Top-K 文档
→ LLM 生成回答
应用:
- 企业级AI助手
- 内部知识专家系统
- 行业智能问答平台
⭐ 这是目前向量匹配最重要的应用之一。
六、向量匹配的典型误区
❌ 误区:向量匹配等于精准判断。
✅ 现实:向量匹配本质上是衡量概率相关性。
因此,在工程实践中务必注意:
- 采用 Top-K + Rerank 策略:先通过向量匹配粗筛出候选集(Top-K),再用更精细的模型对候选结果进行重排序(Rerank)。
- 设置相似度阈值:过滤掉低相关度的结果,控制输出质量。
- 与规则引擎或LLM推理结合:向量匹配的结果可以作为输入,交由规则或大模型进行最终判断和加工。
七、一句话总结
向量匹配 = 把对内容的“理解”问题,转化为在高维空间中计算“几何距离”的问题。
或者说:
Embedding模型负责将语义映射到高维空间,而相似度函数则负责在这个空间里“寻找最近邻”。
希望这篇关于向量匹配原理的解析能对你有所帮助。如果你想深入探讨人工智能相关技术,或寻找实用的向量数据库等工具,欢迎访问云栈社区与更多开发者交流。
 发表于 2026-1-10 18:10:10
|
查看: 363|
回复: 0
发表于 2026-1-10 18:10:10
|
查看: 363|
回复: 0
