
在面向亿级用户访问的超大规模系统中,构建一个健壮、高效的多级分布式架构是保障服务高并发与低延迟响应的基石。这套体系通常遵循“本地缓存 -> 分布式缓存 -> 持久化存储”的层级设计,每一层都扮演着不可替代的角色。
多级缓存架构全景
一个典型的多级缓存架构链路可以概括为以下流程:
请求入口
↓ 【L1 本地缓存】(JVM / Caffeine)
↓ 【L2 分布式缓存】(Redis Cluster)
↓ 【L3 远端缓存 / 二级存储】(Redis + SSD / KV)
↓ 数据库 / 搜索 / 文件存储
L1 本地缓存:速度的极致追求
本地缓存部署在应用进程的内存中,是距离业务代码最近的一层。当缓存命中时,数据读取的延迟可以低至亚毫秒级别,对于读操作极为频繁的热点数据场景意义重大。
但它也有明显短板:容量有限,且数据分散在各个实例上,形成了“数据孤岛”。因此,本地缓存通常用来存放生命周期短、极度热门的少量数据,并通过设置过期时间或采用LRU(最近最少使用)等淘汰策略来严格控制内存占用。常见的技术实现包括直接使用JVM堆内存,或者集成Caffeine、Guava Cache这类高性能本地缓存库。

核心特点与挑战:
- 优点:访问速度极快(无网络开销),能显著优化系统P99延迟(即99%的请求所能达到的最快响应时间)。
- 挑战:容量小,数据在多实例间不一致,需要设计合理的更新与失效机制来避免脏数据。
L2/L3 分布式缓存:容量与可用的保障
当数据的热度范围和体积超出单机内存能力时,就需要引入分布式缓存,例如 Redis、Memcached等。这一层解决了数据在多个应用实例间共享的问题,并提供了容错能力,是承接前端流量、保护后端数据库的“防洪坝”。
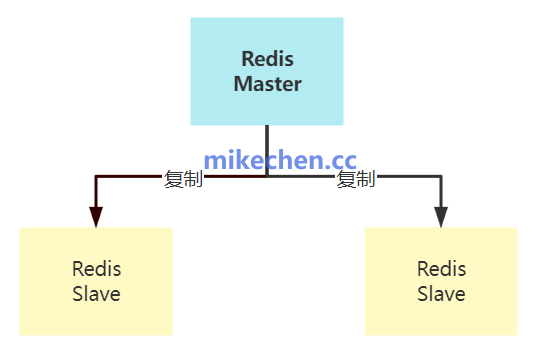
通过主从复制、集群分片等机制,分布式缓存可以实现水平扩展,大幅提升整体缓存容量和服务的可用性。在多级架构中,L2通常被设计为存放“热数据”的核心集群,而L3则可能用于存储“温数据”或“冷数据”,也可能作为跨地域部署的次级缓存层,进一步降低远程访问的延迟。
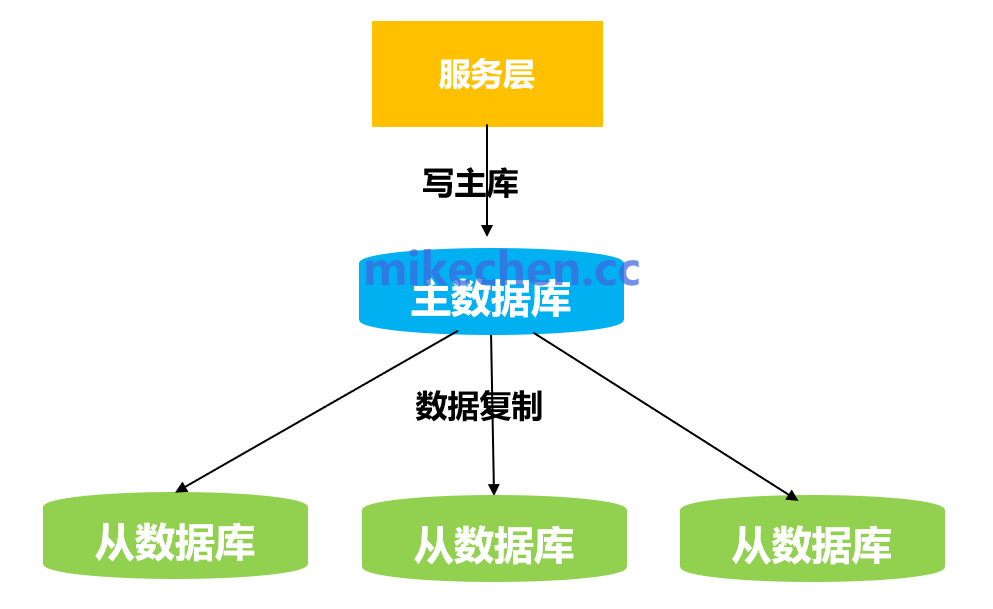
持久层:数据的最终归宿
持久层,包括关系型数据库(如MySQL)、NoSQL数据库、搜索引擎(如Elasticsearch)等,是所有数据的权威来源和最终落地点。它负责处理复杂的查询、事务操作,并保证数据的强一致性与持久化。
缓存的作用是加速访问,但不能替代持久层的数据可靠性与一致性保障。当请求在缓存的所有层级都未命中时,系统必须“回源”查询持久层。因此,在架构设计上,要力求通过高缓存命中率来减少对持久层的直接冲击,尤其在流量洪峰期间,避免其成为整个系统的性能瓶颈。常见的组合是采用分库分表的MySQL集群处理核心交易,结合Elasticsearch满足复杂搜索需求。
总结
构建亿级流量的系统,本质上是在速度、容量、一致性、成本之间寻找最佳平衡点。本地缓存、分布式缓存与持久化存储组成的三级架构,是经过大规模互联网业务验证的有效模式。理解每一层的特性与局限,并设计好层与层之间的降级、更新、失效策略,是每一位架构师的必修课。如果你想深入探讨更多关于高并发与系统设计的实践,欢迎在云栈社区与其他开发者交流学习。 |  发表于 2026-1-10 18:57:14
|
查看: 219|
回复: 0
发表于 2026-1-10 18:57:14
|
查看: 219|
回复: 0
