在 Kubernetes 集群的日常运维中,工作节点的下线与新增是保障基础设施灵活性与稳定性的关键操作。本文将基于一个 3 Master + 2 Node 的测试集群,详细讲解如何在生产环境中执行一套不影响业务的标准流程,确保操作的安全与可控。
1. 工作节点下线流程
节点下线并非简单地删除服务器,其核心在于安全、平滑地迁移工作负载,避免服务中断。
1.1 标记节点为不可调度
首先,需要将目标节点标记为不可调度(Cordon),这是为了防止在后续操作期间有新的 Pod 被调度到该节点上。这里我们以 k8s-node02 节点为例。
[root@k8s-master01 ~]# kubectl cordon k8s-node02
node/k8s-node02 cordoned
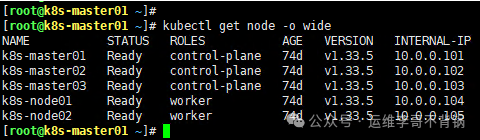
执行后,使用 kubectl get node 命令查看节点状态,确认 k8s-node02 的状态已变为 Ready,SchedulingDisabled。这意味着该节点上的现有 Pod 仍可运行,但 Kubernetes 调度器不会再将新的 Pod 分配给它。
[root@k8s-master01 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready control-plane 74d v1.33.5
k8s-master02 Ready control-plane 74d v1.33.5
k8s-master03 Ready control-plane 74d v1.33.5
k8s-node01 Ready worker 74d v1.33.5
k8s-node02 Ready,SchedulingDisabled worker 74d v1.33.5
1.2 安全驱逐 Pod
标记完成后,下一步是驱逐该节点上运行的所有 Pod。在操作前,强烈建议先查看该节点上运行了哪些 Pod:
[root@k8s-master01 ~]# kubectl get po -A -owide | grep k8s-node02
特别注意:需要重点关注是否有 StatefulSet 管理的 Pod、是否使用了 本地存储(Local Volume) 以及是否存在 单副本服务。这些情况需要额外处理,否则可能导致数据丢失或服务中断。
使用 kubectl drain 命令执行驱逐:
[root@k8s-master01 ~]# kubectl drain k8s-node02 --ignore-daemonsets --delete-emptydir-data
参数说明:
--ignore-daemonsets:忽略 DaemonSet 管理的 Pod(如网络插件、日志收集组件),这些 Pod 通常每个节点都需要运行,drain 命令默认会因它们而失败。--delete-emptydir-data:删除使用 emptyDir 卷的 Pod。emptyDir 的数据生命周期与 Pod 一致,存储在节点本地,驱逐时可以选择删除。
处理特殊 Pod 的注意事项:
- 有状态应用(StatefulSet):必须确保其副本数大于 1,并且存储使用的是 PVC(持久卷声明)而非本地盘。否则,
drain 过程会因无法安全迁移而卡住。
- 单副本业务:需要提前手动扩容副本,或与业务方协调,告知会有短暂的服务中断风险。
驱逐完成后,务必检查所有 Pod 是否已在其他节点上重建并正常运行:
[root@k8s-master01 ~]# kubectl get po -A | grep -Ev '1/1|2/2|3/3|NAMESPACE'
这条命令可以过滤出非“Running”状态(即非所有容器都已就绪)的 Pod,便于排查问题。
1.3 从集群中移除节点
当节点上的 Pod 全部被驱逐并迁移成功后,可以从控制平面永久删除该节点的记录:
[root@k8s-master01 ~]# kubectl delete node k8s-node02
node "k8s-node02" deleted
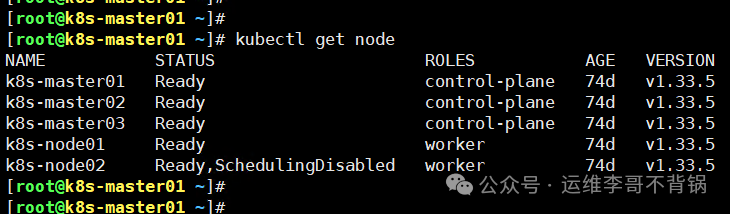
再次查看节点列表,确认 k8s-node02 已被移除。
[root@k8s-master01 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready control-plane 75d v1.33.5
k8s-master02 Ready control-plane 75d v1.33.5
k8s-master03 Ready control-plane 75d v1.33.5
k8s-node01 Ready worker 75d v1.33.5
1.4 清理被移除的节点
最后,需要在被下线的物理服务器或虚拟机上执行清理操作,以便未来可以重新初始化或用作他途。
- 停止 kubelet 服务:
[root@k8s-node02 ~]# systemctl stop kubelet
- 使用
kubeadm reset 重置节点,清理 Kubernetes 相关配置:
[root@k8s-node02 ~]# kubeadm reset -f
- 手动删除残余的配置和数据目录(请谨慎操作):
[root@k8s-node02 ~]# rm -rf /etc/cni/net.d /var/lib/kubelet /var/lib/etcd
2. 新增工作节点流程
扩容集群时,新增节点必须满足与现有集群一致的基础环境,以确保兼容性。
2.1 准备新节点
准备一台新的服务器作为工作节点,需满足以下条件:
- 操作系统及内核版本一致
- 时间同步(NTP)
- 主机名唯一且符合命名规范
- DNS 配置正确
- 容器运行时(如 containerd、Docker)版本与配置一致
- 已安装 kubeadm, kubelet, kubectl 且版本与集群一致
关键配置检查:
- Hosts 文件:确保所有节点(包括新节点)的
/etc/hosts 文件包含集群所有节点的主机名解析。
[root@k8s-master01 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.0.0.101 k8s-master01
10.0.0.102 k8s-master02
10.0.0.103 k8s-master03
10.0.0.104 k8s-node01
10.0.0.105 k8s-node02 # 新增节点
- SSH 免密登录(可选):为方便管理,可以从 Master 节点配置到新节点的 SSH 免密登录。
ssh-copy-id -i ~/.ssh/id_rsa.pub root@10.0.0.105
2.2 通过 kubeadm 将节点加入集群
Kubeadm 生成的加入令牌(token)默认有效期为 24 小时。如果令牌过期,需要重新生成。
- 在 Master 节点上生成加入命令:
[root@k8s-master01 ~]# kubeadm token create --print-join-command
kubeadm join 10.0.0.110:16443 --token n8zwbt.q8ro0nyqf4mob6lk --discovery-token-ca-cert-hash sha256:654440c125218765414892d8cbcfc48ecd29d7335679943bfd4c6cac0a3625f1
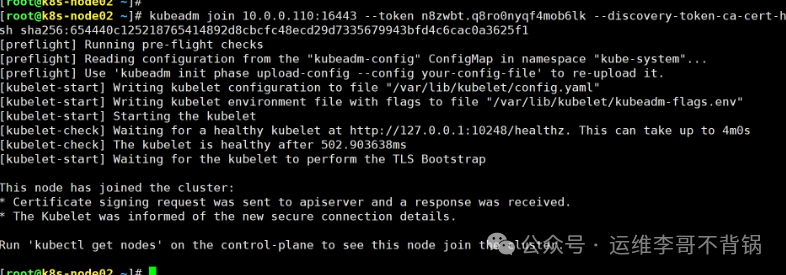
- 在新节点上执行上一步获得的加入命令:
[root@k8s-node02 ~]# kubeadm join 10.0.0.110:16443 --token n8zwbt.q8ro0nyqf4mob6lk --discovery-token-ca-cert-hash sha256:654440c125218765414892d8cbcfc48ecd29d7335679943bfd4c6cac0a3625f1
2.3 验证节点状态
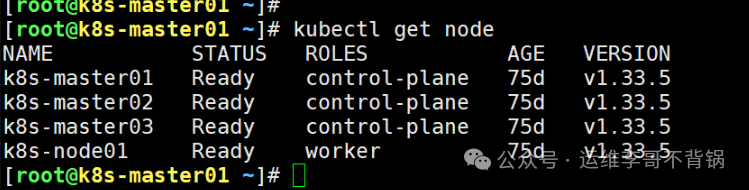
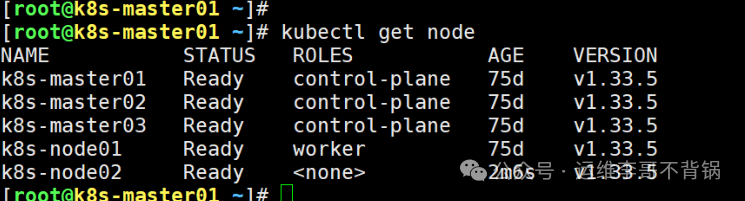
加入命令执行成功后,回到 Master 节点查看节点状态,确认新节点已成功加入并处于 Ready 状态。
[root@k8s-master01 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready control-plane 75d v1.33.5
k8s-master02 Ready control-plane 75d v1.33.5
k8s-master03 Ready control-plane 75d v1.33.5
k8s-node01 Ready worker 75d v1.33.5
k8s-node02 Ready <none> 2m6s v1.33.5
2.4 注意事项与最佳实践
- 网络连通性:确保新节点与所有 Master 节点之间网络通畅,特别是 API Server 的端口(默认 6443)以及云原生网络插件(如 Calico、Flannel)所需的端口。
- 负载均衡:节点加入后,Kubernetes 调度器会自动将新创建的 Pod 分配到新节点。你也可以使用
kubectl cordon/uncordon 或 kubectl drain 来手动调整现有工作负载的分布。
- 标签与污点:根据业务需要,可以为新节点打上标签(Labels)或污点(Taints),以实现更精细的 Pod 调度策略。
遵循上述流程,可以极大降低在 Kubernetes 生产环境中进行节点变更的风险。如果你想深入探讨更多集群管理技巧,欢迎在云栈社区与其他运维和开发者交流经验。
 发表于 2026-1-10 23:48:00
|
查看: 255|
回复: 0
发表于 2026-1-10 23:48:00
|
查看: 255|
回复: 0
