一、背景
随着得物App各业务功能的丰富和升级,App内可供用户体验的内容和活动日益增多。在用户使用时长不断增长的背景下,App的体验问题变得愈发重要。然而,在传统的功能研发流程中,App端的测试时间相对有限,难以对所有场景的体验问题实现全覆盖。
传统的UI自动化回归测试已无法全面满足应用质量保障的需求。尤其是在涉及页面交互和用户体验等主观性较强的问题时,往往只能依赖测试人员手动进行场景体验,整体测试效率较低。
此前,我们结合内部的前端页面巡检平台,实现了对App核心场景的日常巡检能力,对基础的页面展示、交互事件和图片相似度等问题已具备初步检测能力。针对传统自动化在应用体验类问题检测上的难题,我们结合内部应用AI模型的经验,开始尝试利用大型模型的分析能力在App上进行智能巡检,并最终实现了得物App智能巡检的应用落地。相较于传统方式,智能巡检在帮助业务排查应用体验类问题上展现出显著优势。
二、架构总览

在App智能巡检的整个架构流程中,涉及了内部多个平台和服务的交互,各自发挥着不同作用:
-
巡检平台
作为整个流程的管理中心,是用户直接交互的平台。用户可在平台上完成问题检测配置、个性化规则制定和目标场景设定等操作。任务执行结束后,平台会汇总各服务的执行结果,进行分析过滤,并对确定的异常问题自动告警通知。
-
自动化服务
主要提供App各端自动化任务执行的基本能力,是具体的执行者。根据任务配置,自动化服务会依次进行可用真机设备调度、执行环境初始化、进入目标页面、现场AI送检、自定义操作执行、通用异常查询分析等流程,最终将结果上报给巡检平台归档。
-
前端/客户端SDK
为丰富巡检过程中可获取的异常信息,我们与前端及客户端平台合作打通了相关检测能力。除了执行过程本身识别的错误外,一些系统级错误(如JS错误、白屏错误、网络错误等)可通过对应平台提供的SDK获取,检测结果会与执行步骤关联绑定,便于快速定位异常来源。
-
模型服务
视觉类任务的检测主要由模型服务完成。模型基于用户配置的AI校验规则及基础通用规则,对执行现场的实时截图进行快速识别分析,对图中可疑的UI问题、交互问题及不符合规则的内容进行深入探索,并产出最终检测结果给到巡检平台。
-
真机服务
用于提供云端真机设备。任务执行过程中,可根据用户的执行系统、品牌、数量等需求调度空闲设备,以满足多设备并行巡检的需要。对于巡检中发现的问题,用户可远程登录对应真机快速复现场景,研发修复后也可通过真机快速验证。
三、主要功能设计
1. 页面结构布局问题检测
在App使用过程中,最常见的UI问题包括页面展示错位、组件重合或排版布局错乱等。这类问题直观影响用户体验,我们将其归类为页面结构布局问题。
针对此类问题,传统的自动化手段通常缺乏统一的判断标准,难以在不同页面场景下通用,且维护成本较高。考虑到页面现场截图包含了大部分有效信息,我们尝试将完整的页面信息提供给AI模型,让模型基于特定规则自动理解图片内容并进行问题校验。其基本检测流程如下:

在整体操作流程中,我们将基础任务使用场景分为两大类,AI检测的侧重点和结果判断标准有所不同:
2. 通用视觉体验问题检测
除了页面布局问题,App体验和视觉类问题的表现形式多样。为了覆盖更多场景,我们设计了一个通用的视觉检测功能,其校验规则可由用户自由指定,平台也会提供一些默认的通用规则,用户可根据实际场景组合检测目标和方式。该功能的基本流程如下:
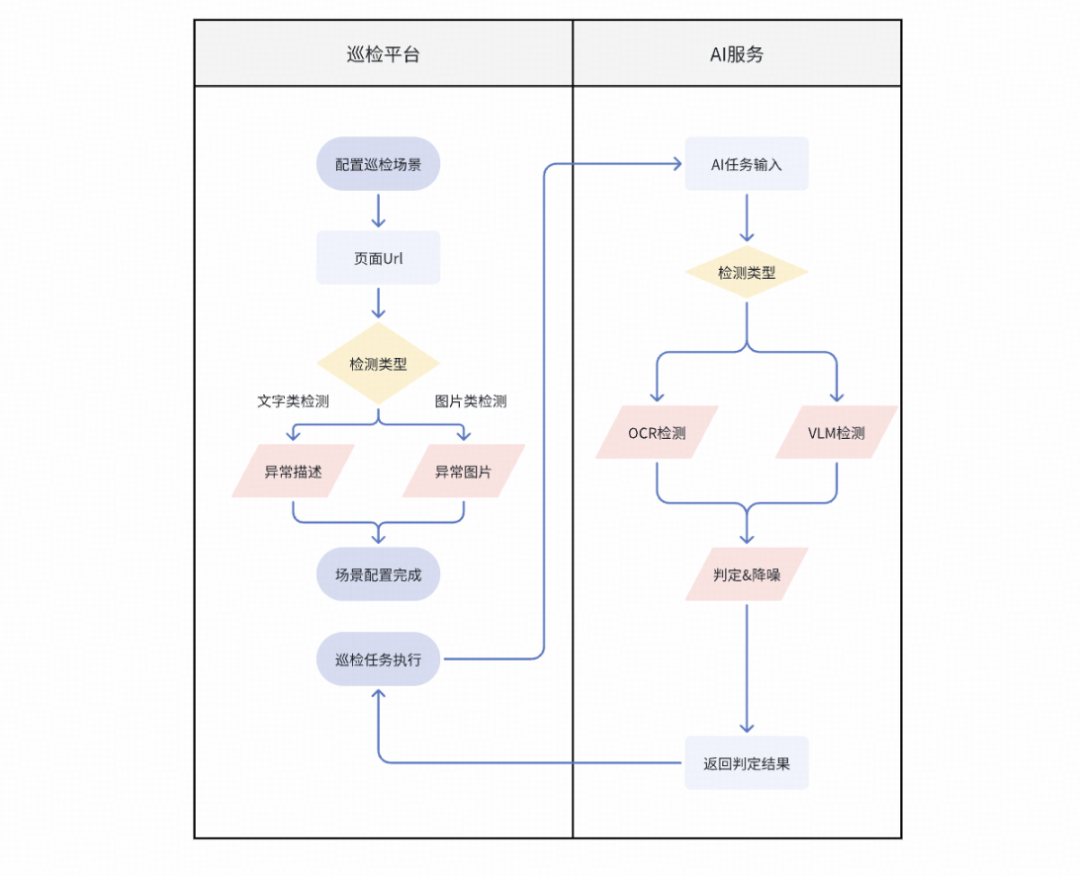
在该功能的检测流程中,我们将检验侧重点区分为针对文字和针对图片两类:
3. 页面展示一致性检测
前述两个检测能力主要针对单页面异常。然而,得物App业务页面复杂,用户常需在不同页面间跳转,这就产生了跨页面UI信息展示是否符合预期的问题。此类UI问题涉及多个页面,且出现规律不固定,传统上主要依赖测试人员手工执行时随机发现,难以保障场景覆盖。
针对这种跨页面的UI问题,我们分析发现,解决的关键在于理解目标商品或展示内容之间的对应关系,并在后续测试流程中保留此关联信息,最终结合不同页面的现场信息和关联关系进行分析。基于此,我们设计了一套页面展示一致性检测功能,其整体流程如下:

相较于单页面检测,跨页面UI问题检测有几个关键差异点:
-
检验层级和目标发现
由于涉及多级页面,检测过程中需要判断最终检测层级,防止对比页面不全。同时,针对需要对比的商品内容,需实时维护多级页面的对应展示关系,避免对比对象出现差异。
-
多级操作定位
在自动化执行过程中,后续层级的页面缺乏可靠的定位对比信息。我们采用模型识图定位,即用上级页面的目标图片来定位当前页面是否存在相同目标,此过程需对相似目标图片进行过滤和识别。
-
多级页面对比分析
最终的分析结果依赖于多级页面的现场截图信息和规则进行校验对比,从而得到整个多级页面场景下的一致性分析结果。
4. AI操作与异常(无响应)检测
前置操作
有些目标入口无法直接到达,例如位于需要滑动多屏才能展示的板块。针对此类场景,我们引入了AI自动化操作能力。用户可用简短的语言描述前置操作步骤,在实际任务执行时,AI会识别这些描述并完成相应操作指令,在所有操作执行完毕后,再进行其他视觉体验功能的智能巡检。该功能的执行流程如下:
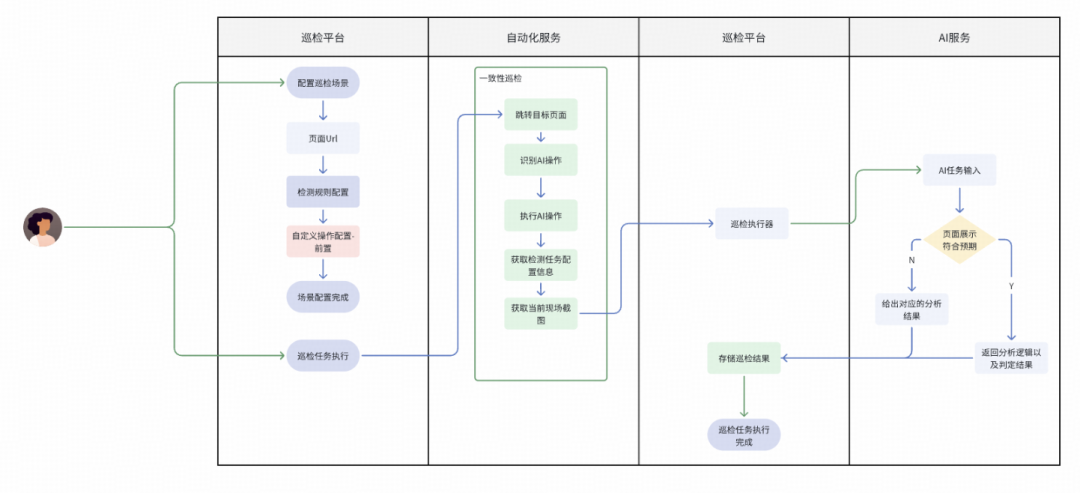
基于AI实现自然语言到实际操作,我们参考了业界实践和开源方案,最终采用AI模型完成操作分析、UI自动化框架完成操作执行的方式。在接入大模型(尤其是开源模型)后,由于其本身具备多模态能力(NLP、图像识别、目标定位等),通过持续优化Prompt,即可实现智能的UI自动化执行。大致架构如下:
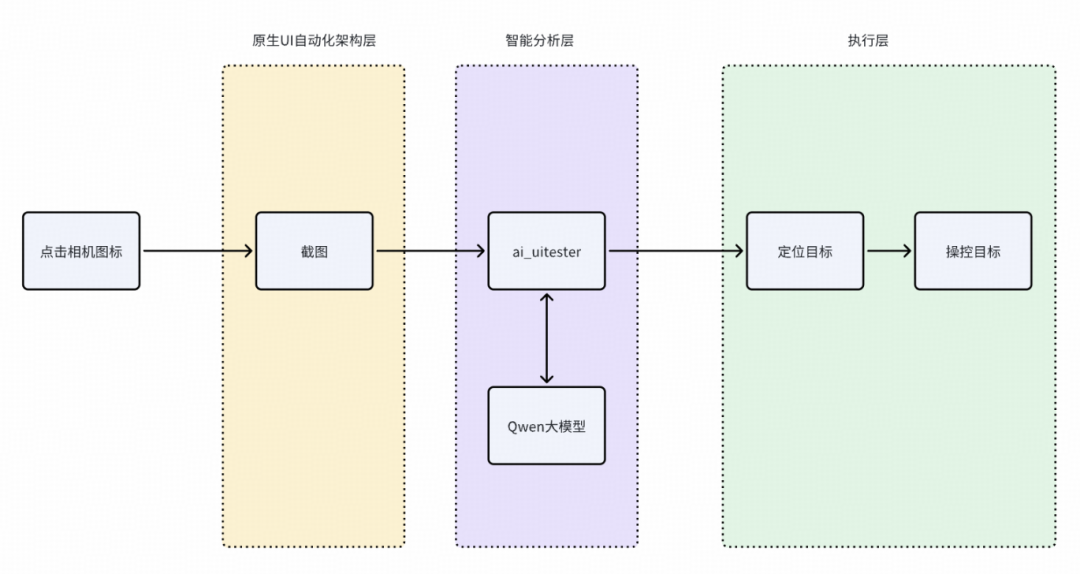
具体实现原理不在此详述,我们通过一个核心能力简单分析实现流程:
1.模型相关实现
import json
from openai import OpenAI
from ..config.llm_config import LLMConfig
from ..utils import get_logger
class ChatClient:
#模型初始化
def __init__(self, config_path=None, model_log_path=None):
self.logger = get_logger(log_file=model_log_path)
self.config = LLMConfig(config_path)
self.openai = OpenAI(
api_key=self.config.openai_api_key,
base_url=self.config.openai_api_base,
)
def chat(self, prompt_data):
#模型交互,提交截图和任务描述
chat_response = self.openai.chat.completions.create(
model=self.config.model,
messages=prompt_data,
max_tokens=self.config.max_tokens,
temperature=self.config.temperature,
extra_body={
"vl_high_resolution_images": True,
}
)
result = chat_response.choices[0].message.content
json_str_result = result.replace("```json", "").replace("```", "")
try:
res_obj = json.loads(json_str_result)
return res_obj
except Exception as err:
self.logger.info(f"LLM response err: {err}")
#异常数据修复
try:
import json_repair
res_obj = json_repair.repair_json(json_str_result, return_objects=True)
return res_obj
except Exception as err:
self.logger.info(f"LLM response json_repair err: {err}")
try:
import re
#返回的bbox处理
if "bbox" in json_str_result:
while re.search(r"\d+\s+\d+", json_str_result):
json_str_result = re.sub(r"(\d+)\s+(\d+)", r"\1,\2", json_str_result)
res_obj = json.loads(json_str_result)
return res_obj
except Exception as err:
self.logger.info(f"LLM response re.search err: {err}")
2.点击操作实现
def ai_tap(self, description):
screenshot_base64 = self.get_resized_screenshot_as_base64()
ret = {
"screenshot": screenshot_base64,
}
prompt = Tap(description).get_prompt(screenshot_base64)
res_obj = self.chat_client.chat(prompt)
if "errors" in res_obj and res_obj["errors"]:
ret["result"] = False
ret["message"] = res_obj["errors"]
else:
#返回的bbox处理为实际坐标
x, y = self.get_center_point(res_obj["bbox"])
#进行具体的自动化操作
self._click(x, y)
ret["location"] = {"x": x, "y": y}
ret["result"] = True
ret["message"] = ""
return ret
独立路径校验操作
AI操作配置也可作为独立的功能校验逻辑,置于视觉任务检测之后执行。此时操作执行逻辑相对独立,若操作过程中出现错误同样会上报。
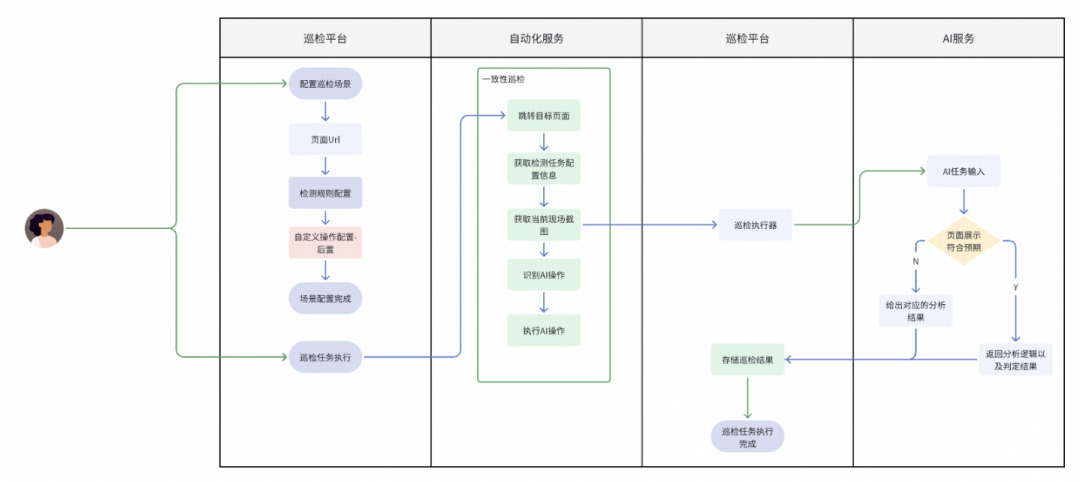
操作无响应检测
在自动化操作过程中,还需关注操作本身是否生效,否则无法保证整个执行链路的完整性。App内的点击操作可能出现无响应的情况,这可能是设计、网络或响应问题,也属于一种用户体验问题。因此,我们在原有执行流程中引入了差异分析模块,以保障操作的有效完成。

在操作有效性保障方案上,我们对比了图像像素处理和模型分析对比两种方式。两者的分析结果均能满足实际场景需要。考虑到成本,大部分场景会优先采用基于图像像素对比的方式;在判断结果不满足要求的场景中,再使用模型进行分析。
def check_operation_valid(screen_path_before, screen_path_after, cur_ops, screen_oss_path_before,
screen_oss_path_after):
try:
import cv2
import numpy as np
img_before = cv2.imread(screen_path_before)
img_after = cv2.imread(screen_path_after)
if img_before is None or img_after is None:
raise RuntimeError(f"操作响应校验读取图片异常")
# 确保两张图片大小相同
if img_before.shape != img_after.shape:
img_after = cv2.resize(img_after, (img_before.shape[1], img_before.shape[0]))
# 转换为灰度图
gray_before = cv2.cvtColor(img_before, cv2.COLOR_BGR2GRAY)
gray_after = cv2.cvtColor(img_after, cv2.COLOR_BGR2GRAY)
# 计算直方图
hist_before = cv2.calcHist([gray_before], [0], None, [256], [0, 256])
hist_after = cv2.calcHist([gray_after], [0], None, [256], [0, 256])
# 归一化直方图
hist_before = cv2.normalize(hist_before, hist_before).flatten()
hist_after = cv2.normalize(hist_after, hist_after).flatten()
# 计算相关系数 (范围[-1, 1],1表示完全相同)
correlation = cv2.compareHist(hist_before, hist_after, cv2.HISTCMP_CORREL)
# 计算卡方距离 (范围[0, ∞],0表示完全相同)
chi_square = cv2.compareHist(hist_before, hist_after, cv2.HISTCMP_CHISQR)
# 计算交集 (范围[0, 1],1表示完全相同)
intersection = cv2.compareHist(hist_before, hist_after, cv2.HISTCMP_INTERSECT)
# 设置相关系数阈值,超过此阈值视为两张图一致
threshold = Thres
threshold_chi_square = Thres_chi
if correlation > threshold and chi_square < threshold_chi_square and intersection > threshold:
raise RuntimeError(f"当前操作:{cur_ops} 疑似无效")
except Exception as e:
raise e
四、平台建设与使用
1. 平台配置
基础规则配置
针对上述不同的检测类型和功能,用户可在巡检平台上创建和管理目标检测规则,所有巡检场景和任务均可共用这些规则。
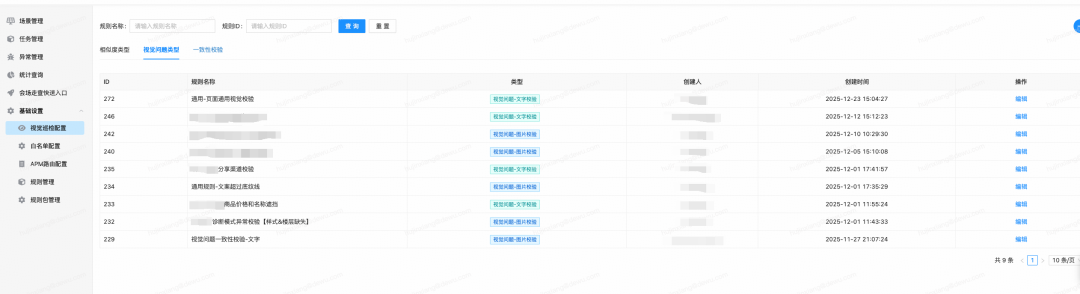
配置项
不同功能的具体检测规则和配置内容有所差异,但基本上只需描述大致的检测范围,无需过度细化。例如,下图是平台上的通用检测规则,用于检查所有常见的排版、报错等异常问题:

2. 巡检结果反馈
常规任务
对于执行完成的检测任务,在对应的详情页可以查看模型的逻辑和分析过程。例如,下图是得物App内某IP品牌页的检测结果:

在测试记录的执行详情中,通常会展示以下关键信息:
- 当前规则的对比图和现场实时截图。
- 基于配置的检测规则,模型的具体分析过程和结论。
通过现场截图和模型分析描述,测试人员可以准确定位和分析问题。如果当前结果是模型误报,相关人员可进行反馈,我们将根据检测结果持续优化模型的检测能力。这种结合自动化与智能分析的质量保障模式,是现代化运维与测试体系中追求效率与准确性的重要实践。
页面展示一致性检测
对于多级页面展示一致性检测任务,返回的结果信息中会有日志说明比较过程和结果。若发现异常,会额外提供不同页面的对比截图:

AI操作
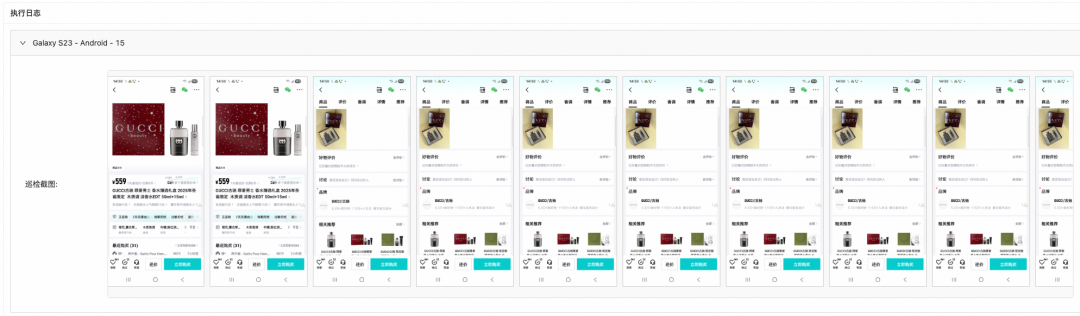
在配置了AI操作的任务中,其结果详情页面会展示整个流程的执行截图,以帮助测试人员定位问题和还原现场:
五、总结
在移动应用自动化测试领域,传统的元素和图像驱动方法正逐渐向智能化驱动转型。这一转变不仅提升了自动化的使用效率和维护便利性,也使基于模型的图像理解能力得以发挥,从而释放出深度探索应用程序的潜力。
我们通过整合现有技术平台,基于视觉语言模型(VLM),开展了场景化的智能巡检探索与实践。该方法在多种任务场景下均能有效识别应用中的问题。相较于之前的方案,智能巡检整体的问题识别准确率从50%提升到80%,图片相似度匹配准确率从50%提升到80%以上。在首次会场AI走查过程中(纯技术侧),共发现17个配置问题,AI问题发现率达95%。
后续,我们将继续结合AI大模型能力,在App的更多相关场景中进行探索和应用,帮助测试人员更高效地保障App质量,持续提升得物App的用户使用体验。我们也欢迎广大开发者前往云栈社区交流更多关于智能测试与自动化运维的技术实践。
 发表于 2026-1-13 05:02:05
|
查看: 284|
回复: 0
发表于 2026-1-13 05:02:05
|
查看: 284|
回复: 0
