分布式架构是构建大型系统与处理海量数据的基石,其核心可归纳为三大支柱:分布式存储、分布式计算与分布式协调。本文将深入解析这三大组件的架构模式、核心原理及典型技术栈。
分布式存储:系统的基石
分布式存储系统旨在解决单机磁盘的容量限制与IO性能瓶颈,为上层应用提供可靠、可扩展的数据持久化能力。
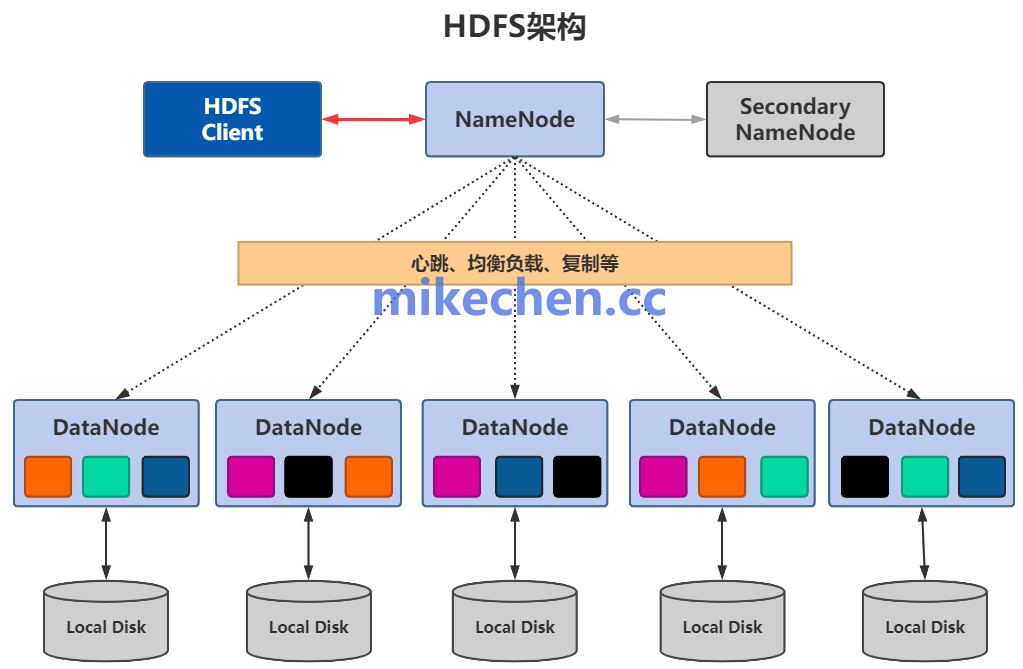
其主流架构模式为主从(Master-Slave)结构。通常由一个Master节点负责管理元数据(例如文件的位置信息),而多个DataNode节点则负责存储实际的数据块。
其核心原理包含以下几点:
- 数据分片:将大文件分割成固定大小的数据块,分散存储在不同的物理节点上。
- 多副本机制:每个数据块会在不同的物理机上存储多个副本(通常为3份),以此确保数据的可靠性与高可用性,即使单机损坏也不会导致数据丢失。
- 一致性保证:通过分布式协议来保证多个副本之间的数据同步,根据场景不同可提供强一致性或最终一致性模型。
典型的分布式存储系统包括支撑PB级离线数据存储的 HDFS,以及提供块、对象、文件存储统一方案的Ceph。
分布式计算:数据处理的大脑
分布式计算框架的核心思想是“移动计算而非移动数据”,通过将计算任务分发到数据所在的节点,以高效处理海量数据集。
其执行模型通常基于有向无环图,将复杂的计算任务分解为多个可并行执行的阶段,调度到集群中的多个工作节点上同时运行。
其核心原理主要体现在以下方面:
- MapReduce范式:经典的“分而治之”思想。Map阶段负责数据的拆分与初步处理,Reduce阶段则负责对中间结果进行汇总与聚合。
- 数据本地性:调度器会优先将计算任务分配到存储有所需数据块的节点上执行,极大减少了网络传输的开销。
- 内存计算:以 Spark 为代表的框架,将中间计算结果缓存在内存中,避免了多次磁盘IO,使得迭代计算和交互式查询的性能比基于磁盘的MapReduce提升数个数量级。
当前主流的分布式计算引擎包括广泛应用于数据分析与机器学习的Apache Spark,以及实现真正低延迟流处理的顶尖引擎Apache Flink。
分布式协调与调度:集群的指挥家
在由成百上千个节点组成的集群中,需要一套机制来解决诸如主节点选举、服务状态监控、任务调度与配置同步等全局一致性问题。这正是分布式协调服务的职责所在。
这类系统通常基于Paxos或Raft等一致性协议构建,形成一个高可用的集群来提供稳定的协调服务。
其提供的核心能力包括:
- 领导者选举:当主节点发生故障时,集群能通过共识算法在极短时间内自动选举出新的主节点,保证服务不间断。
- 分布式锁:在分布式环境下,确保对共享资源或关键代码段的访问是互斥的,防止并发冲突。
- 配置管理与服务发现:集中存储和管理集群的配置信息,并实时监控各个服务节点的存活状态,实现动态的服务注册与发现。
该领域的经典代表是作为Kafka、HBase等系统核心组件的 ZooKeeper。而基于Raft算法实现的Etcd,则是容器编排平台Kubernetes(K8s)的核心状态存储组件,堪称整个集群的“大脑”。
理解存储、计算与协调这三大支柱,是掌握 分布式架构 设计与演进的钥匙。希望本文的梳理能为您构建高可用、可扩展的系统提供清晰脉络。更多关于系统设计、高并发及微服务的深度讨论,欢迎访问云栈社区进行交流与探索。 |  发表于 2026-1-13 05:54:34
|
查看: 247|
回复: 0
发表于 2026-1-13 05:54:34
|
查看: 247|
回复: 0
