一、Python后端与Neo4j接口开发:全文索引应用
在基于知识图谱的应用开发中,高效的数据检索是核心需求。当数据量增大时,直接使用 CONTAINS 进行模糊查询会面临性能瓶颈。为此,为特定属性创建全文索引是提升搜索效率的关键。
1. 创建与使用全文索引
步骤一:在Neo4j中管理索引
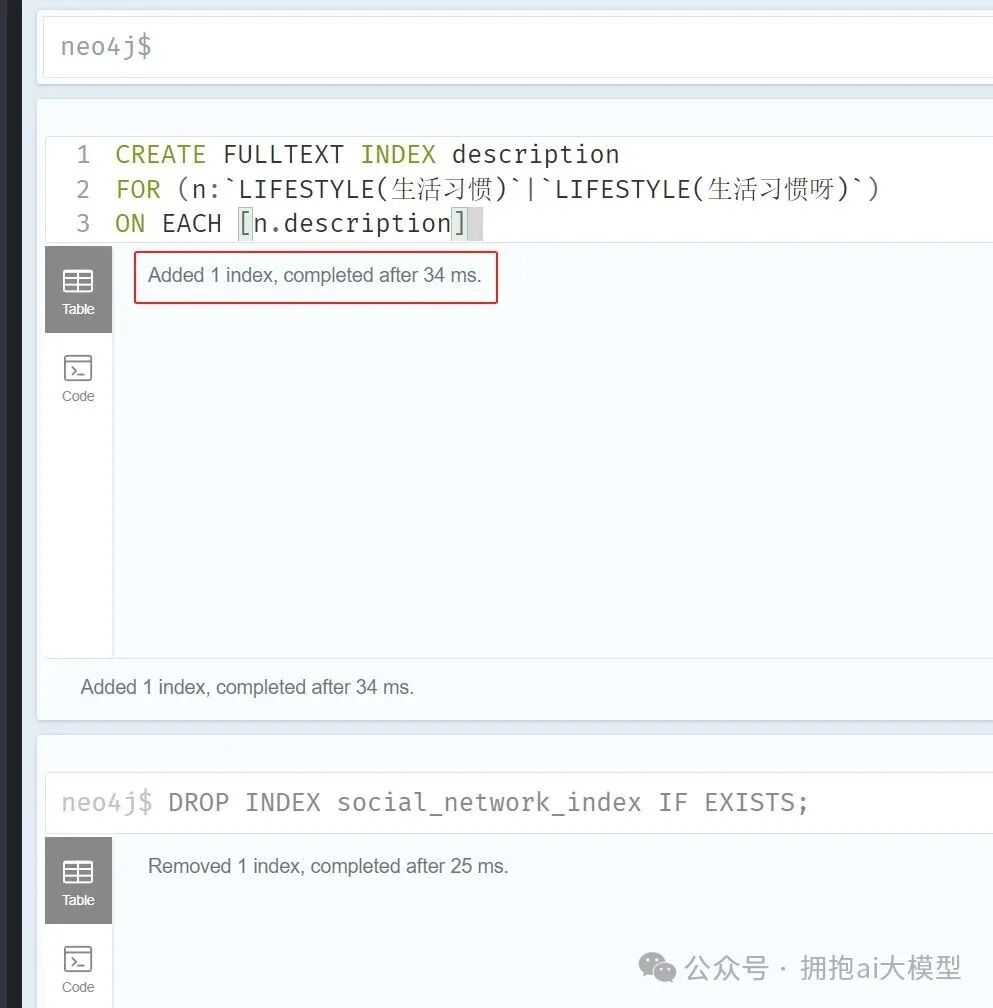
首先,如果线上已存在同名的旧索引,需要先将其删除。删除索引的命令如下:
DROP INDEX social_network_index IF EXISTS;
接着,创建针对节点 description 属性的全文索引。以下命令为标签为 LIFESTYLE(生活习惯) 的节点创建索引:
CREATE FULLTEXT INDEX description
FOR (n:`LIFESTYLE(生活习惯)`)
ON EACH [n.description]
索引创建与删除的操作示例如下图所示:
步骤二:在Python程序中调用全文索引
创建索引后,在Python程序中,我们就需要将原有的 MATCH...WHERE...CONTAINS 查询替换为专用的全文索引查询函数。Neo4j提供的调用方式如下:
CALL db.index.fulltext.queryNodes('description', ‘搜索关键词’)
YIELD node, score
RETURN node, score
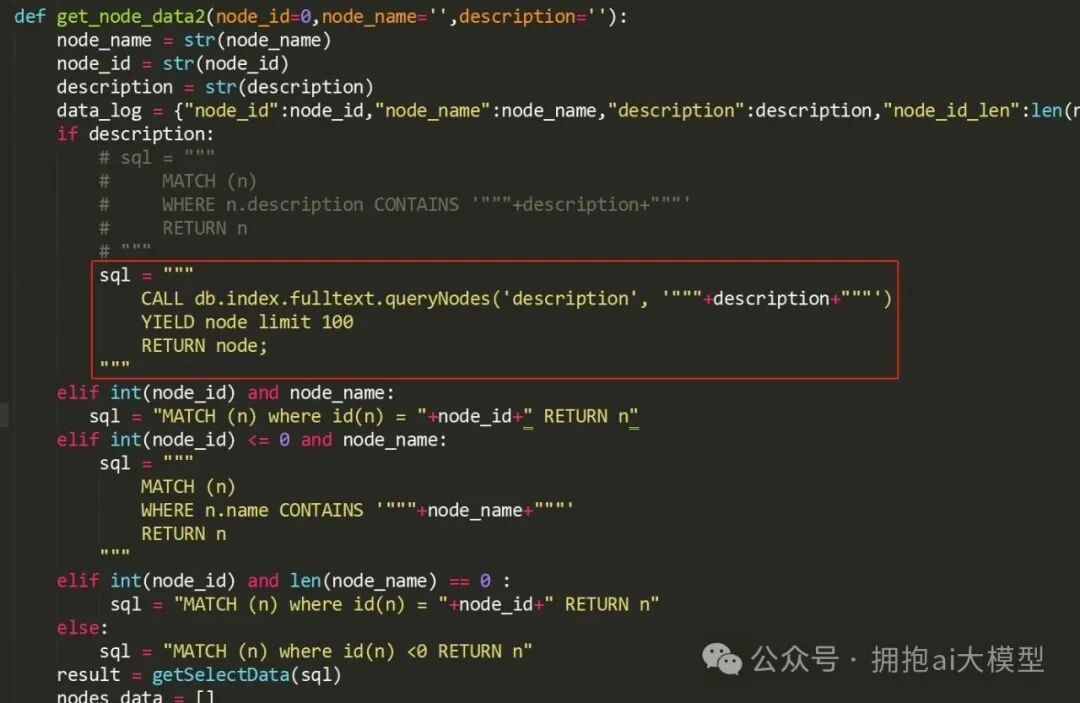
在代码中,我们根据传入的参数动态构建查询。初始版本的函数设计如下:
def get_node_data2(node_id=0, node_name='', description=''):
node_name = str(node_name)
node_id = str(node_id)
description = str(description)
data_log = {"node_id":node_id, "node_name":node_name, "description":description, "node_id_len":len(node_id)}
if description:
sql = """
CALL db.index.fulltext.queryNodes('description', '""" + description + """')
YIELD node limit 100
RETURN node;
"""
elif int(node_id) and node_name:
sql = "MATCH (n) where id(n) = " + node_id + " RETURN n"
elif int(node_id) <= 0 and node_name:
sql = """
MATCH (n)
WHERE n.name CONTAINS '""" + node_name + """'
RETURN n
"""
elif int(node_id) and len(node_name) == 0 :
sql = "MATCH (n) where id(n) = " + node_id + " RETURN n"
else:
sql = "MATCH (n) where id(n) < 0 RETURN n"
result = getSelectData(sql)
nodes_data = []
然而,直接运行上述代码会报错。错误信息提示在访问返回结果时发生了 KeyError: 'n'。
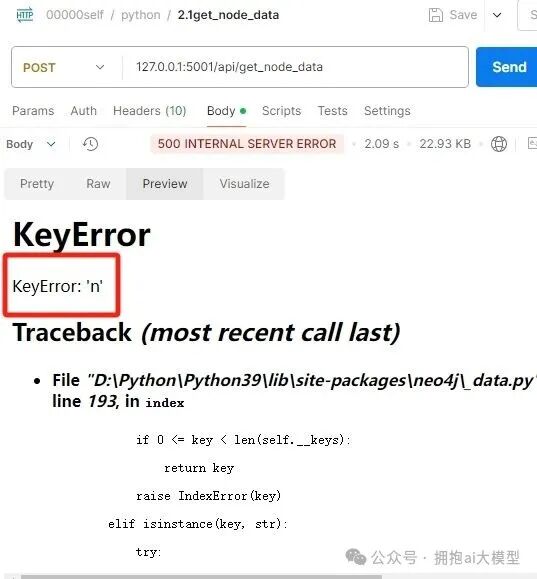
问题排查与解决
问题根源在于Cypher查询的返回结果别名。在使用 CALL db.index.fulltext.queryNodes() 时,我们通过 YIELD node 获取节点,但在 RETURN 语句中直接返回了 node,这使得在后续Python代码中尝试以 record[“n”] 访问时失败,因为返回的键是 node 而非 n。
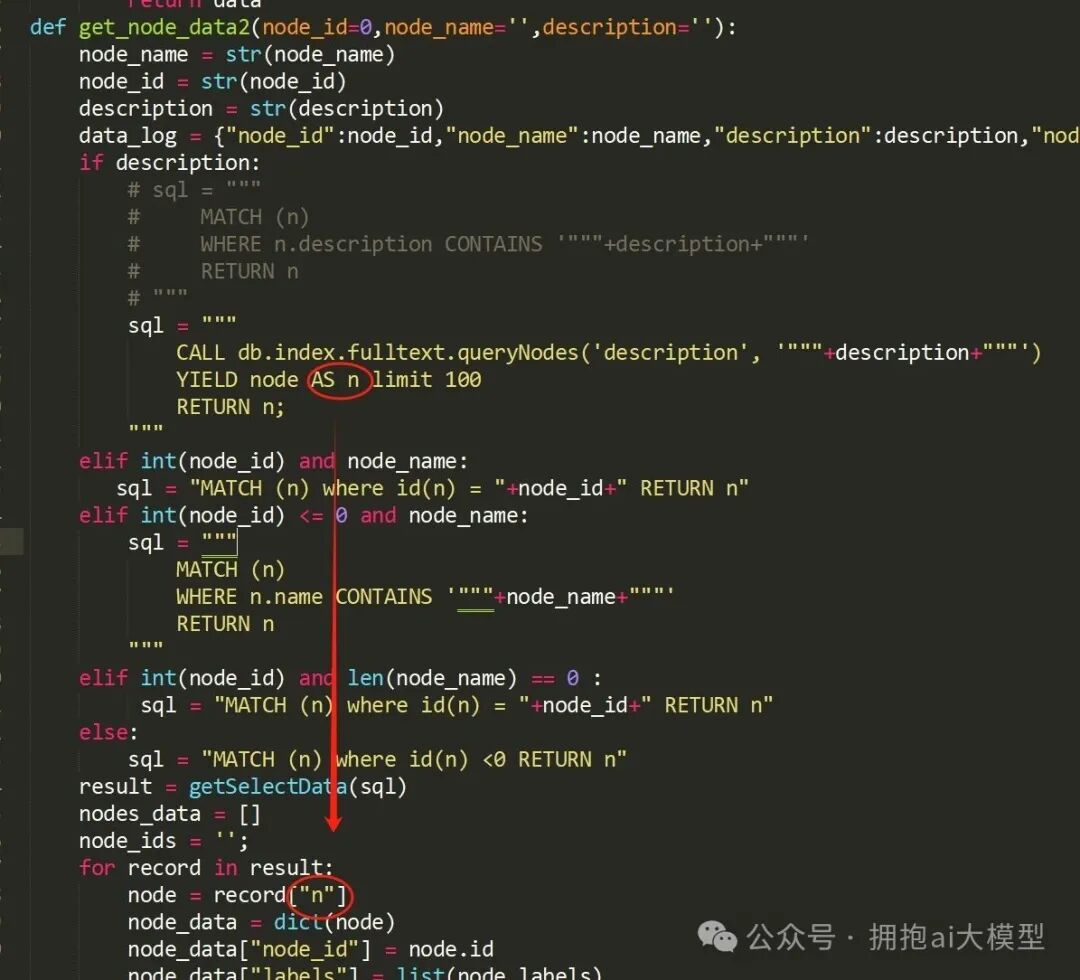
解决方案是为返回的节点设置一个明确的别名。将查询语句修改如下:
sql = """
CALL db.index.fulltext.queryNodes('description', '""" + description + """')
YIELD node AS n limit 100 # 关键修改:为node设置别名n
RETURN n;
"""
相应地,处理结果的循环部分就能正确通过 record[“n”] 获取节点对象了。修正后的完整函数逻辑如下:
步骤三:验证上线效果
修改完成后,通过API传入描述关键词进行测试,成功返回了包含该关键词的节点列表,证明全文索引集成成功。
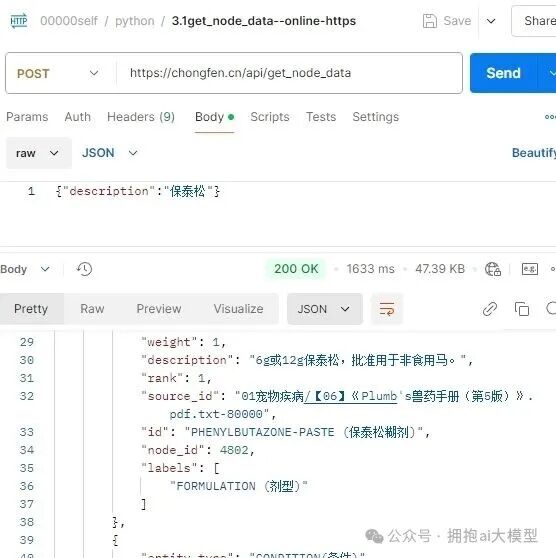
2. 基于节点ID的关系扩展搜索
在实际应用中,除了全文检索,另一种常见场景是通过一个已知节点ID,查找与其相关联的所有节点(例如邻居节点)。
例如,在知识图谱中,节点ID 112 可能通过“孩子”或“父亲”等关系与其他节点相连。
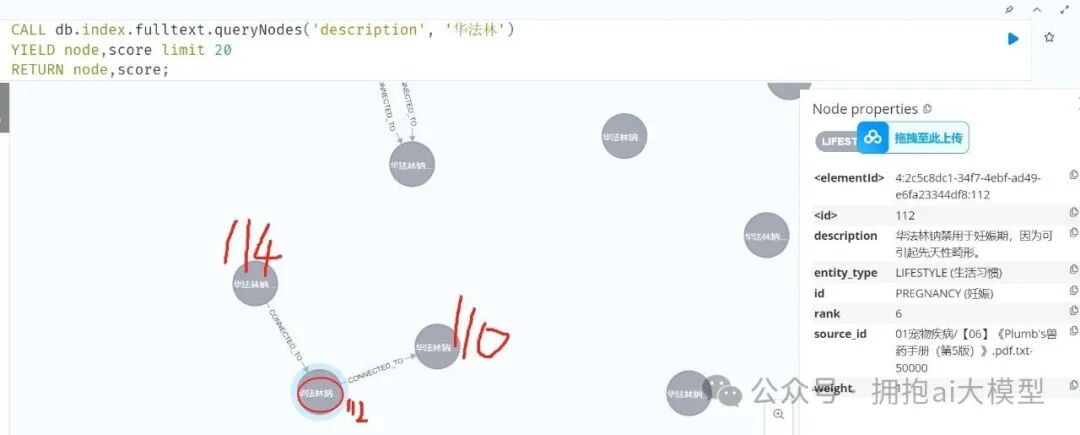
为了获取这些关系,我们需要编写不同的Cypher查询。这通常涉及使用 MATCH 路径模式来匹配从起始节点出发的特定或所有关系,并将关联节点返回。这部分逻辑可以根据业务需求,补充到上述 get_node_data2 函数的分支判断中,实现根据 node_id 查询关系网络的功能。
总结
通过在Neo4j中建立全文索引,并在Python后端程序中正确调用,可以显著提升基于文本属性的搜索性能。开发过程中需要注意Cypher查询返回结果的别名映射问题。同时,结合节点ID进行图关系遍历,能够满足更复杂的数据关联查询需求,为构建功能丰富的知识图谱应用打下基础。希望这篇实践笔记能对你在开发中有所启发,也欢迎在云栈社区分享你的技术心得。
 发表于 2026-1-15 00:32:05
|
查看: 269|
回复: 0
发表于 2026-1-15 00:32:05
|
查看: 269|
回复: 0
