
随着人工智能技术的快速发展,如何让模型理解和推理超长文本已成为自然语言处理领域的核心挑战之一。传统模型在面对百万Token级别的文档时,常因上下文窗口限制和训练不稳定等问题而力不从心。阿里通义实验室推出的开源项目 Qwen-Doc,正是为了攻克这些难题而生。
项目概述
Qwen-Doc 是一个专注于文档理解、解析与智能体应用的开源实战项目集合。其核心模型基于 Qwen3-30B-A3B 架构,并通过一系列系统化的后训练方案,显著提升了模型的长文本推理能力。该项目的目标不仅是追赶顶尖模型,更旨在通过开源模型、数据和方法论,推动整个社区在复杂文档处理能力上的进步。
核心功能
(一)长文本推理
Qwen-Doc 能够高效处理超长文本,例如百万级 Token 的文档,并解决其中跨段落、跨文档的复杂问题。它通过创新的记忆增强框架,有效突破了传统模型对物理上下文窗口的依赖,实现了对海量信息的高效推理。
(二)多跳推理
模型支持复杂的多跳逻辑推理,能够通过多个步骤串联分散的信息,完成需要深度思考的任务。例如,在长篇幅的技术报告或法律文书中,它可以找出分散在各处的关联信息,并进行综合判断。
(三)信息整合
Qwen-Doc 具备强大的信息提取与整合能力,可以从冗长的文本中抓取关键事实,并将其融合起来,用于回答需要全局视野的问题。这背后依赖于其高质量的数据合成管线。
(四)记忆管理
面对超出单次处理窗口的超长文本,Qwen-Doc 引入了记忆管理框架。它将单次推理与迭代式的记忆处理相结合,通过多阶段训练,把全局信息“折叠”进紧凑的记忆表示中,从而突破硬件限制。
(五)通用能力提升
值得注意的是,Qwen-Doc 在专注于长文本能力的同时,其数学推理、智能体记忆和长对话等通用任务上的表现也有显著提升,展现了良好的技术泛化性。
技术揭秘
(一)高质量数据合成管线
如何获得用于训练的高质量长文本推理数据?Qwen-Doc 采用了“先拆解,后组合”的策略。首先将长文档解构成原子事实及其关系网络,然后利用知识图谱等工具,以程序化的方式合成那些需要多跳推理和全局整合的复杂问题,从而构建出高质量的训练数据集。
(二)稳定的强化学习方法
长文本多任务训练常面临数据分布偏移和奖励信号不稳定的挑战。为此,团队引入了任务均衡采样和任务专属优势估计策略。同时,提出的自适应熵控制策略优化(AEPO)算法,能动态调控训练过程中的负梯度,平衡模型的探索与利用,确保了在超长序列上训练的稳定性。
(三)突破物理窗口的记忆管理框架
这是 Qwen-Doc 的核心创新之一。该框架不依赖于扩展有限的上下文窗口,而是通过分块处理、迭代更新记忆的方式,让模型能够有效处理任意长度的文档。它将复杂的全局信息压缩存储,在需要时进行精确检索,实现了对超长文本的“无损”推理。
性能表现
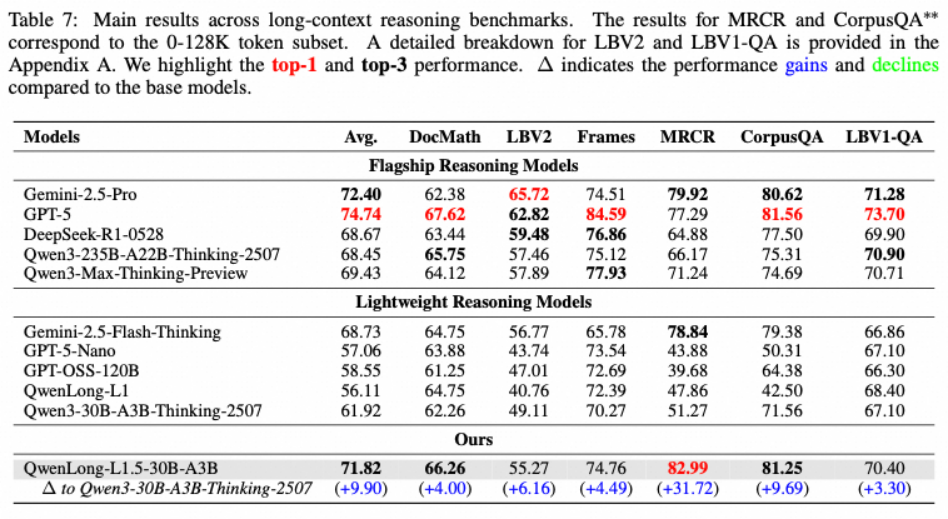
Qwen-Doc 在多项权威的长文本推理基准测试中表现卓越。例如,在 LongBench-V2 测试集上,其平均得分比基线模型 Qwen3-30B-A3B-Thinking 高出 9.9 分,达到了 71.82 分,与谷歌的 Gemini-2.5-Pro (72.40分) 成绩相当。在另一个复杂推理测试 MCRC 中,Qwen-Doc 更是取得了 82.99 的高分,凸显了其在解决复杂问题上的强大实力。
应用场景
(一)长文档分析
无论是百页的财务年报、复杂的法律合同还是深奥的学术论文,Qwen-Doc 都能快速消化,提取关键条款、财务指标或核心论点,并完成跨章节的归纳分析,极大提升专业人士的工作效率。
(二)代码理解和生成
对于大型开源项目或企业私有代码库,Qwen-Doc 能够理解其整体架构和逻辑脉络。它可以为开发者生成代码片段、提供补全建议,甚至解释复杂函数的作用,成为编程效率的“加速器”。
(三)复杂问答系统
在智能客服、知识库问答等场景中,用户的问题往往不是简单的一问一答。Qwen-Doc 的多跳推理能力使其能够处理“根据A文档的X条款和B报告的第Y部分,判断Z是否合规”这类复杂问题,提供深度、准确的答案。
(四)信息检索与整合
传统的搜索引擎返回的是网页列表,而 Qwen-Doc 可以从检索到的多篇长文档中直接整合出结构化的答案,或构建出针对某一主题的迷你知识图谱,让信息获取从“查找”升级为“洞察”。
(五)教育与学习
它可以充当个性化的智能辅导老师,引导学生一步步解开复杂的数学证明,或从长篇的教科书材料中总结出清晰的知识点框架,适配不同学生的学习节奏。
快速使用
Qwen-Doc 提供了便捷的部署方式,以下是通过 Hugging Face 快速上手的示例。
(一)安装依赖
首先,需要配置好Python环境并安装必要的依赖库。
# Create the conda environment
conda create -n qwenlongl1_5 python==3.10
conda activate qwenlongl1_5
# Install requirements
pip3 install -r requirements.txt
# Install verl, we use the 0.4 version of verl
git clone --branch v0.4 https://github.com/volcengine/verl.git
cd verl
pip3 install -e .
(二)模型推理
安装完成后,便可以使用 Transformers 库加载模型并进行推理。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Tongyi-Zhiwen/QwenLong-L1.5-30B-A3B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
template = """Please read the following text and answer the question below.
<text>
$DOC$
</text>
$Q$
Format your response as follows: "Therefore, the answer is (insert answer here)"."""
context = "<YOUR_CONTEXT_HERE>"
question = "<YOUR_QUESTION_HERE>"
prompt = template.replace('$DOC$', context.strip()).replace('$Q$', question.strip())
messages = [
# {"role": "system", "content": "You are QwenLong-L1, created by Alibaba Tongyi Lab. You are a helpful assistant."}, # Use system prompt to define identity when needed.
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=50000,
temperature=0.7,
top_p=0.95
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151649 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
结语
Qwen-Doc 通过高质量数据合成、稳定的强化学习训练以及革命性的记忆管理框架,在长文本理解与推理领域实现了显著的技术突破。它不仅在基准测试中媲美顶级商用模型,更在代码理解、文档分析、复杂问答等多个实用场景中展现出巨大潜力。对于开发者社区而言,其全面的开源策略无疑将加速长文本AI技术的普及与创新。欢迎在云栈社区交流更多关于AI模型实践的经验与想法。
项目地址
 发表于 2026-1-15 03:08:59
|
查看: 191|
回复: 0
发表于 2026-1-15 03:08:59
|
查看: 191|
回复: 0
