云原生已成为构建大型分布式架构的核心,而容器化技术则是其重要基石。要真正理解并高效运用Docker,深入探究其底层工作原理至关重要。本文将系统性地解析Docker依赖的三大内核级核心技术:Namespaces(命名空间)、Cgroups(控制组)和UnionFS(联合文件系统),它们共同构筑了容器的隔离性与轻量化特性。
Docker核心技术基石
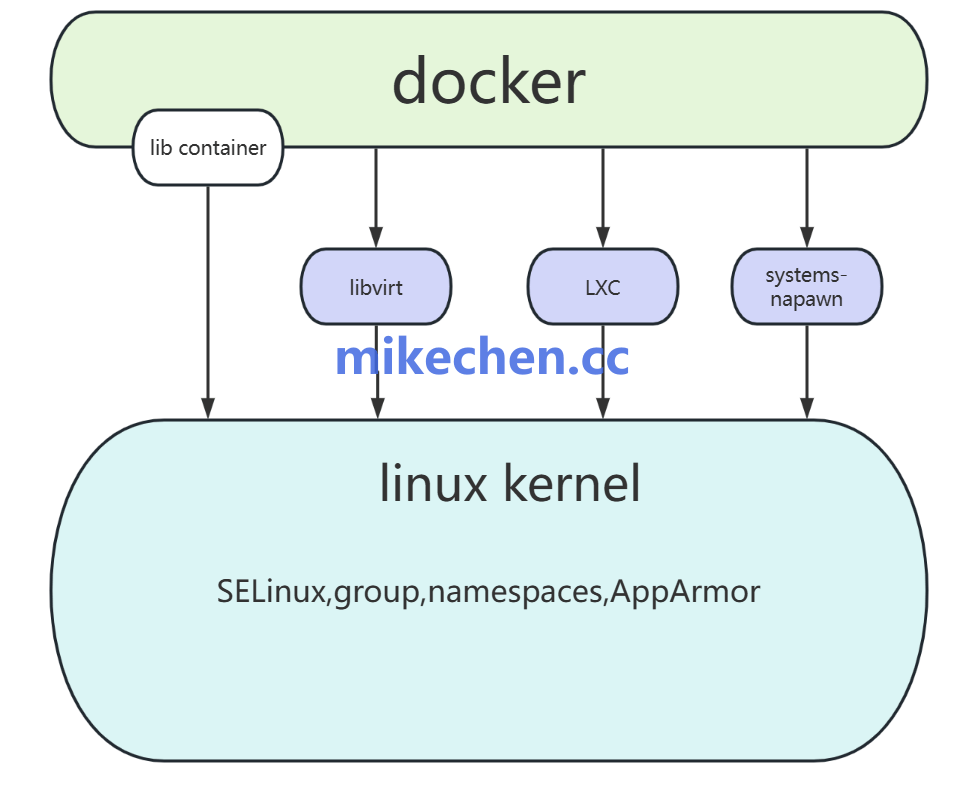
Docker之所以能实现轻量、高效的容器化,其根本在于对操作系统底层能力的精巧运用。它的核心特性并非凭空产生,而是深度依赖于Linux内核提供的Namespaces、Cgroups和UnionFS这三大机制。
Namespaces(命名空间)
命名空间是Linux内核提供的一种资源隔离机制,它能够将全局性的系统资源划分为多个相互独立的“视图”,从而为进程营造出一个个隔离的环境。
Linux内核主要提供了以下几种类型的命名空间:
- PID Namespace: 隔离进程ID。容器内的进程拥有独立的进程号体系,其init进程PID为1,且无法看到宿主机或其他容器内的进程。
- NET Namespace: 隔离网络设备、IP地址、端口、路由表等。每个容器可以拥有自己独立的虚拟网络接口和完整的网络栈。
- MNT Namespace: 隔离文件系统挂载点。容器内对文件系统的挂载/卸载操作不会影响到宿主机。
- UTS Namespace: 隔离主机名和域名。允许容器拥有独立的主机名。
- IPC Namespace: 隔离进程间通信资源,如信号量、消息队列和共享内存。
- User Namespace: 隔离用户和用户组ID。允许在容器内以root身份运行进程,而在宿主机上映射为普通用户,提升了安全性。
通过为每个容器创建一套独立的命名空间组合,Docker实现了进程、网络、文件系统及主机标识等多维度的环境隔离,这正是容器看起来像“独立小服务器”的根本原因。
Cgroups(控制组)
如果说Namespaces解决了“看得见什么”的隔离问题,那么Cgroups则解决了“能用多少”的资源管控问题。它是Linux内核的又一特性,用于对进程组的资源使用进行限制、统计和优先级管理。
Cgroups将一系列进程及其子进程组织成层次化的控制单元,并针对不同类型的资源(子系统)进行配额分配,例如:
- cpu子系统: 限制CPU使用时间或分配CPU核心。
- memory子系统: 限制内存使用量(包括RAM和Swap)。
- blkio子系统: 限制块设备(如磁盘)的I/O带宽。
- devices子系统: 控制对设备的访问权限。
在云原生场景下,当多个容器共享同一宿主机资源时,Docker利用Cgroups确保单个容器不会消耗超出预设配额的资源。这有效防止了某个容器因内存泄漏或CPU死循环而“拖垮”整个宿主机,实现了资源层面的隔离与公平调度,保障了服务的整体稳定性。这对于构建可靠的运维体系至关重要。
UnionFS(联合文件系统)
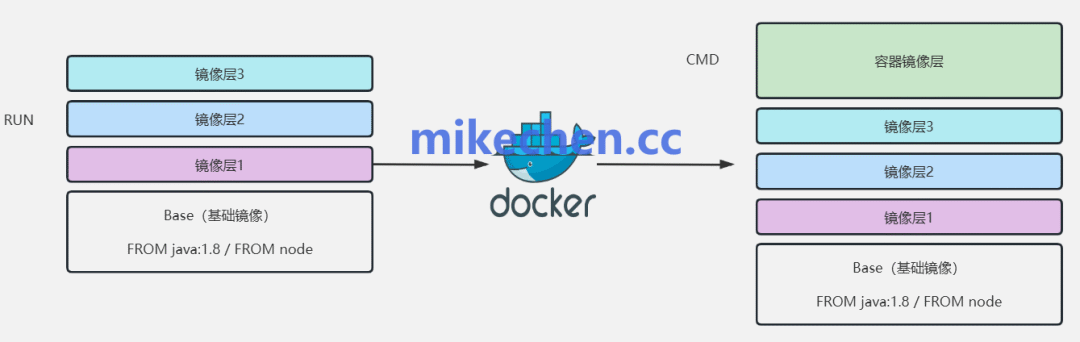
UnionFS是一种支持将多个不同的文件系统层(Layer)以“联合挂载”的方式,透明地叠加合并为一个单一视图的文件系统。Docker镜像和容器的高效性,很大程度上得益于对UnionFS(及其实现如Overlay2、AUFS)的应用。
Docker镜像采用分层的结构:
- 只读层(Read-only Layers): 一个Docker镜像由多个只读层叠加而成。每一层代表Dockerfile中的一条指令(如
FROM, RUN, COPY等)。这些层是共享和不可变的。
- 可写层(Container Layer): 当基于镜像启动一个容器时,Docker会在所有只读层之上添加一个薄薄的可写层(也称为容器层)。

这种架构带来了巨大优势:
- 镜像复用与高效分发: 所有容器可以共享相同的基础镜像层,只需拉取或存储不同的层,极大地节省了磁盘空间和网络带宽。
- Copy-on-Write(写时复制): 这是UnionFS的核心策略。当容器需要修改某个只读层中的文件时,该文件会被复制到可写层中进行修改,而原始的只读层保持不变。这既保证了镜像的不可变性,又使得容器的写操作变得轻量和快速。
总结
Namespaces实现了环境隔离,让容器拥有独立的运行视图;Cgroups实现了资源隔离,为容器设定了资源使用的边界;UnionFS则实现了文件系统隔离与高效的存储管理,通过分层和写时复制支持了镜像的轻量与快速部署。这三者协同工作,共同赋予了Docker容器轻量、快速、资源可控的核心特性。
理解这些底层原理,不仅能帮助我们在生产环境中更好地进行问题排查、性能调优和安全加固,也是深入学习和应用更复杂的云原生编排系统(如Kubernetes)的坚实基础。如果你想了解更多关于系统底层、虚拟化或云原生技术的深度讨论,欢迎访问云栈社区与其他开发者交流分享。 |  发表于 2026-1-15 05:45:01
|
查看: 211|
回复: 0
发表于 2026-1-15 05:45:01
|
查看: 211|
回复: 0
