整理一份关于Kubernetes应用标准化部署,以及使用Victorialogs搭建轻量日志系统的实操指南。其核心是PVG架构(Promtail + Victorialogs + Grafana),相比传统的EFK栈更为轻量,尤其适合中小型集群。经过实际测试效果良好,特此记录方便后续复用,也避免遗忘细节再次踩坑。
一、方案选型思路
1. 应用部署核心原则
在K8s中部署应用,需要把握三个核心要点:容器化要标准、资源要设限制、健康状态要能监测。无状态应用使用Deployment,有状态应用则考虑StatefulSet,服务通过Service暴露,配置和敏感信息分别用ConfigMap和Secret管理。这样做的好处是,后续修改配置无需重新构建镜像,同时也更安全。
2. 日志架构选PVG的原因
之前尝试过EFK(Elasticsearch, Fluentd, Kibana)方案,但其资源占用过高,小型集群难以承受。切换到Victorialogs后,整个系统变得清爽许多——它非常轻量(单节点内存通常小于200MB)、部署简单,并且能够直接对接Promtail和Grafana,无需安装额外插件。三者分工明确:Promtail负责采集日志,Victorialogs负责存储和查询,Grafana负责可视化展示,完全可以满足日常的运维需求。
补充一下适用场景:对于中小型集群、资源紧张的环境,或者希望快速落地一套日志方案而不想过多折腾的团队,选择PVG架构准没错。对于大型集群,可以给Victorialogs配置多副本,后续再补充相关的高可用配置。
这里有一个小提醒:Victorialogs能够同时存储日志和指标数据,与Grafana的兼容性极佳。通过K8s命名空间、Pod名称等标签过滤日志非常方便,比单独搭建两套系统要省心得多。
二、Step1:K8s应用标准化部署(实操步骤)
1. 前置准备
首先将应用程序容器化并推送到镜像仓库(如Docker Hub、阿里云ACR等)。关键点:应用程序的日志务必输出为JSON格式的结构化日志,这将为后续的日志解析和过滤提供极大便利。准备好以下四个核心的YAML配置文件:
- Deployment.yaml:定义应用的部署方式、副本数、资源限制等。
- Service.yaml:为应用提供访问入口,集群内访问使用ClusterIP即可。
- ConfigMap.yaml:存储非敏感配置,例如端口号、日志格式等,方便修改。
- Secret.yaml(可选):存储数据库密码等敏感信息,比明文更安全。
2. 动手部署
(1)先建命名空间
为应用单独划分一个命名空间,便于后续管理和资源隔离,避免与日志、监控等系统组件混杂。
apiVersion: v1
kind: Namespace
metadata:
name: app-namespace
执行命令:kubectl apply -f namespace.yaml,之后用 kubectl get ns 确认是否创建成功。
(2)部署应用Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo-app
namespace: app-namespace
labels:
app: demo-app
spec:
replicas: 2 # 日常2个副本够用,业务高峰再上调
selector:
matchLabels:
app: demo-app
template:
metadata:
labels:
app: demo-app
log-type: application # 加个标签,方便后续Promtail精准采集
spec:
containers:
- name: demo-app
image: your-registry/demo-app:v1.0 # 替换成自己的镜像地址
ports:
- containerPort: 8080
resources: # 必须设限制,防止应用占满集群资源
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 500m
memory: 512Mi
volumeMounts:
- name: app-config
mountPath: /app/config # 挂载配置文件
livenessProbe: # 存活探针,检测应用是否挂了
httpGet:
path: /health
port: 8080
initialDelaySeconds: 30 # 启动30秒后再检测,避免刚启动就误判
periodSeconds: 10
readinessProbe: # 就绪探针,检测应用是否能提供服务
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
volumes:
- name: app-config
configMap:
name: demo-app-config
(3)创建Service暴露服务
apiVersion: v1
kind: Service
metadata:
name: demo-app-svc
namespace: app-namespace
spec:
selector:
app: demo-app
ports:
- port: 80
targetPort: 8080
type: ClusterIP # 集群内访问用这个,外部要访问就改成NodePort或LoadBalancer
(4)部署后验证
执行部署命令后,一定要检查资源状态,避免部署失败未被发现。
kubectl apply -f deployment.yaml -f service.yaml -f configmap.yaml
# 查看Pod状态,确保都是Running
kubectl get pods -n app-namespace
# 临时看10行日志,验证应用是否正常输出日志
kubectl logs -l app=demo-app -n app-namespace --tail=10
三、Step2:PVG日志系统部署(核心是Victorialogs)
整体部署顺序是:先安装Victorialogs(存储核心)→ 再安装Promtail(采集器)→ 最后配置Grafana(可视化)。所有操作都在独立的 logging 命名空间进行,与应用环境隔离。
1. 先建日志专用命名空间
apiVersion: v1
kind: Namespace
metadata:
name: logging # 所有日志组件都放这里
执行命令:kubectl apply -f logging-namespace.yaml
2. 部署Victorialogs(日志存储核心)
Victorialogs必须配置持久化存储,否则Pod重启后日志数据将会丢失。这里使用NFS进行临时测试,生产环境强烈建议更换为分布式存储(如GlusterFS、Ceph),单点存储风险较高。
(1)创建PV/PVC(持久化存储)
# pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: victorialogs-pv
spec:
capacity:
storage: 10Gi # 测试用10G,生产按日志量调整,建议至少50G
volumeMode: Filesystem
accessModes:
- ReadWriteOnce # 单节点用这个,多副本要改成ReadWriteMany
nfs:
path: /data/nfs/victorialogs # 自己NFS服务器的共享路径
server: 192.168.1.100 # 替换成实际NFS地址
# pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: victorialogs-pvc
namespace: logging
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
执行命令:kubectl apply -f pv.yaml -f pvc.yaml,之后确认PVC是否绑定成功(STATUS 显示为 Bound)。
(2)部署Victorialogs和Service
apiVersion: apps/v1
kind: Deployment
metadata:
name: victorialogs
namespace: logging
labels:
app: victorialogs
spec:
replicas: 1 # 测试单副本,生产开多副本要配集群模式
selector:
matchLabels:
app: victorialogs
template:
metadata:
labels:
app: victorialogs
spec:
containers:
- name: victorialogs
image: victoriametrics/victorialogs:v0.45.0 # 用稳定版,别用最新版怕有bug
ports:
- containerPort: 8428 # 核心端口,接收日志和查询请求
name: http
volumeMounts:
- name: victorialogs-data
mountPath: /victorialogs-data # 日志存储目录
env:
- name: VL_STORAGE_DATA_PATH
value: /victorialogs-data
- name: VL_HTTP_LISTEN_PORT
value: "8428"
resources: # 资源按集群规模调,小集群200m cpu、256m内存足够
requests:
cpu: 200m
memory: 256Mi
limits:
cpu: 1000m
memory: 1Gi
volumes:
- name: victorialogs-data
persistentVolumeClaim:
claimName: victorialogs-pvc
# service.yaml(无头服务,方便后续扩展多副本)
apiVersion: v1
kind: Service
metadata:
name: victorialogs-svc
namespace: logging
spec:
selector:
app: victorialogs
ports:
- port: 8428
targetPort: 8428
clusterIP: None
执行命令:kubectl apply -f victorialogs-deployment.yaml -f victorialogs-service.yaml
验证:kubectl get pods -n logging -l app=victorialogs,确保Pod是Running状态,如有问题使用 kubectl logs 命令排查。
3. 部署Promtail(日志采集器)
使用DaemonSet方式进行部署,确保每个K8s节点上都有一个采集器实例,从而采集到所有节点的容器日志。配置文件的准确性是关键,否则日志无法正确推送到Victorialogs。
(1)创建Promtail配置ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: promtail-config
namespace: logging
data:
promtail.yaml: |
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml # 记录采集位置,避免重启后重复采日志
clients:
- url: http://victorialogs-svc:8428/insert/logs # 推到Victorialogs的地址,别写错
batchwait: 1s
batchsize: 102400 # 批量推送大小,默认就行
scrape_configs:
- job_name: kubernetes-pods
kubernetes_sd_configs:
- role: pod
relabel_configs:
# 只采运行中的Pod日志,减少无效采集
- source_labels: [__meta_kubernetes_pod_phase]
regex: Running
action: keep
# 提取K8s标签,方便后续过滤日志
- source_labels: [__meta_kubernetes_pod_name]
target_label: kubernetes_pod_name
- source_labels: [__meta_kubernetes_namespace]
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_container_name]
target_label: kubernetes_container_name
# 日志路径别错,不然采不到日志
- source_labels: [__meta_kubernetes_pod_uid, __meta_kubernetes_pod_container_name]
regex: (.+);(.+)
replacement: /var/log/containers/$1_$2.log
target_label: __path__
(2)部署Promtail DaemonSet
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: promtail
namespace: logging
labels:
app: promtail
spec:
selector:
matchLabels:
app: promtail
template:
metadata:
labels:
app: promtail
spec:
serviceAccountName: promtail # 要提前授权,不然没权限访问K8s资源
containers:
- name: promtail
image: grafana/promtail:2.9.6 # 和Grafana版本适配就行
args:
- -config.file=/etc/promtail/promtail.yaml
volumeMounts:
- name: config
mountPath: /etc/promtail
- name: varlog
mountPath: /var/log/containers # 容器日志目录,必须挂载
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers # 元数据目录,只读就行
readOnly: true
- name: tmp
mountPath: /tmp # 存采集位置文件
volumes:
- name: config
configMap:
name: promtail-config
- name: varlog
hostPath:
path: /var/log/containers
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: tmp
emptyDir: {}
(3)创建RBAC权限(必做)
Promtail需要相应的权限来获取Pod元数据,否则标签提取会失败,导致日志无法按Pod、命名空间进行过滤。这是一个常见的踩坑点,必须配置。
apiVersion: v1
kind: ServiceAccount
metadata:
name: promtail
namespace: logging
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: promtail-clusterrole
rules:
- apiGroups: [""]
resources: ["pods", "nodes"]
verbs: ["get", "watch", "list"] # 只给必要权限,遵循最小权限原则
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: promtail-clusterrolebinding
subjects:
- kind: ServiceAccount
name: promtail
namespace: logging
roleRef:
kind: ClusterRole
name: promtail-clusterrole
apiGroup: rbac.authorization.k8s.io
执行命令:kubectl apply -f promtail-config.yaml -f promtail-daemonset.yaml -f promtail-rbac.yaml
4. 部署Grafana(日志可视化)
如果您的K8s集群中已经部署了Grafana,直接添加数据源即可,无需重复部署。以下是全新部署的步骤记录。
(1)部署Grafana和Service
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
namespace: logging
labels:
app: grafana
spec:
replicas: 1
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
containers:
- name: grafana
image: grafana/grafana:10.2.3 # 稳定版,界面好用
ports:
- containerPort: 3000
volumeMounts:
- name: grafana-data
mountPath: /var/lib/grafana # 持久化配置,避免重启丢面板
env:
- name: GF_SECURITY_ADMIN_PASSWORD
valueFrom:
secretKeyRef:
name: grafana-admin-secret
key: password # 密码存在Secret里,别明文写
volumes:
- name: grafana-data
persistentVolumeClaim:
claimName: grafana-pvc # 自己创建PVC,步骤和Victorialogs类似
# 管理员密码Secret(提前创建)
apiVersion: v1
kind: Secret
metadata:
name: grafana-admin-secret
namespace: logging
type: Opaque
data:
password: YWRtaW4xMjM= # Base64编码,原密码是admin123,生产一定要改!
# Service.yaml(外部访问用NodePort)
apiVersion: v1
kind: Service
metadata:
name: grafana-svc
namespace: logging
spec:
selector:
app: grafana
ports:
- port: 3000
targetPort: 3000
type: NodePort
(2)Grafana对接Victorialogs数据源
- 访问Grafana:通过
节点IP + NodePort 访问(使用 kubectl get svc -n logging 查询端口),用户名 admin,密码为上面配置的密码。
- 添加数据源:左侧导航栏进入
Configuration → Data Sources → Add data source,搜索并选择 VictoriaLogs。
- 配置数据源:URL填写
http://victorialogs-svc:8428,其他选项保持默认,点击 Save & Test 验证连接,显示成功即可。
- 查询日志:进入
Explore 界面,选择刚才添加的Victorialogs数据源。可以利用从Promtail中提取的标签进行过滤(例如 kubernetes_namespace="app-namespace"),即可看到对应的应用日志,支持按时间范围、关键词进行筛选。
Grafana插件列表中已安装的VictoriaLogs插件。
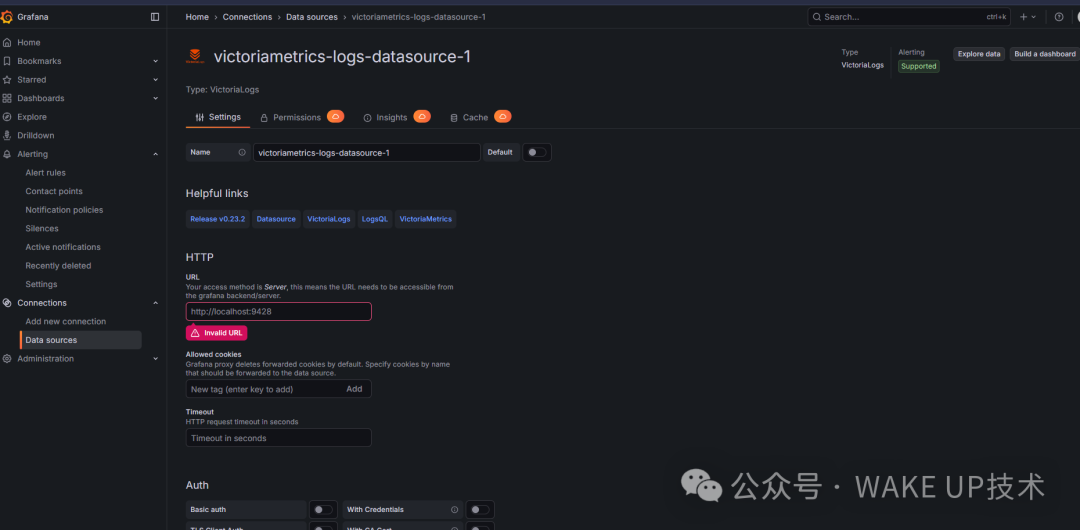
在Grafana中配置VictoriaLogs数据源,填写正确的Service地址。
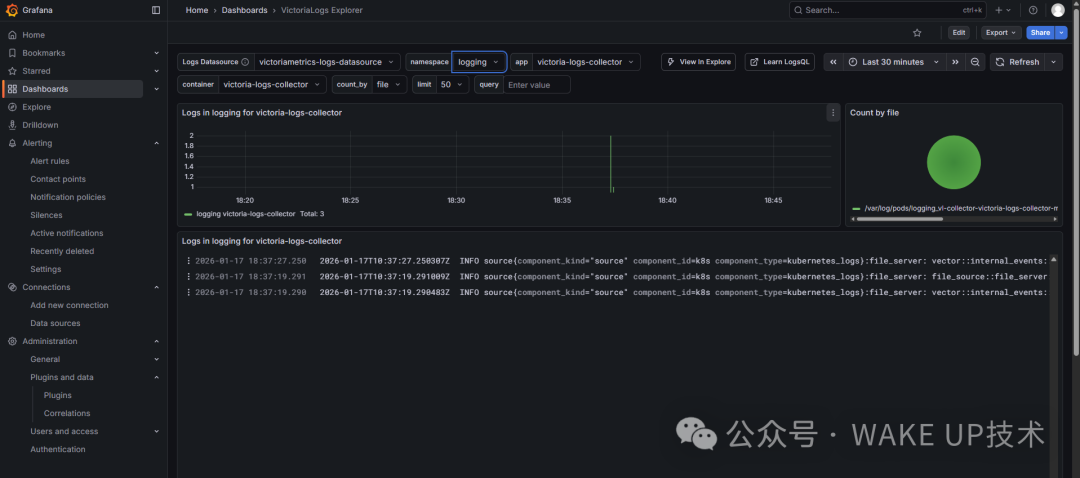
在Grafana Explore界面成功查询到由Promtail收集并存入VictoriaLogs的应用日志。
四、实操踩坑&注意事项
- Victorialogs性能优化:生产环境建议开启gzip压缩,添加环境变量
VL_COMPRESSION_TYPE=gzip,可以节省不少存储空间;多副本部署需要配置集群模式,否则日志数据在不同副本间不互通。
- 日志采集范围控制:
kube-system、logging 这类系统命名空间的日志通常无需采集,可以在Promtail配置中添加过滤规则,以减少不必要的存储压力。
- 持久化存储选择:无论是Victorialogs还是Grafana,都不要使用单点存储。生产环境务必使用分布式存储,防止因存储故障导致数据丢失。
- 安全加固:为Victorialogs添加API密钥认证,为Grafana开启HTTPS。日志中可能包含敏感信息,不应毫无保护地暴露在外网。
五、总结
整体流程并不复杂:应用按照标准化方式进行部署,日志系统采用轻量的PVG架构,足以应对中小型集群的需求。核心关键在于Victorialogs的配置、Promtail的RBAC权限与日志路径匹配、以及Grafana数据源的正确对接。只要这三步配置无误,整套日志系统就能稳定运行。这份云原生技术栈的实战笔记,旨在为后续的部署提供可直接参考的模板,避免再次从头查阅文档和踩坑。希望这份构建现代化运维体系的指南能对你有所帮助,也欢迎到云栈社区与其他开发者交流更多实战经验。
 发表于 2026-1-18 15:06:41
|
查看: 212|
回复: 0
发表于 2026-1-18 15:06:41
|
查看: 212|
回复: 0
