随着人工智能技术的快速发展,深度学习模型的规模和复杂度呈现爆炸式增长,对计算硬件提出了前所未有的挑战。与此同时,计算机图形学领域的实时光线追踪技术也在寻求突破传统渲染方法的性能瓶颈。在这一背景下,NVIDIA于2018年推出的RT Core技术,成为了连接AI计算与图形渲染的重要桥梁。
RT Core是GPU上专门用于处理性能密集型光线追踪工作负载的专用处理核心,通过革命性的硬件设计实现了实时光线追踪的突破。然而,RT Core的价值远不止于图形渲染领域。随着技术的演进,它在AI训练、3D感知、生成式AI等前沿应用中展现出越来越重要的作用。特别是在当前大模型时代,RT Core与Tensor Core、CUDA Core的协同工作机制,为复杂的AI训练任务提供了强大的硬件支撑。
一、基础知识
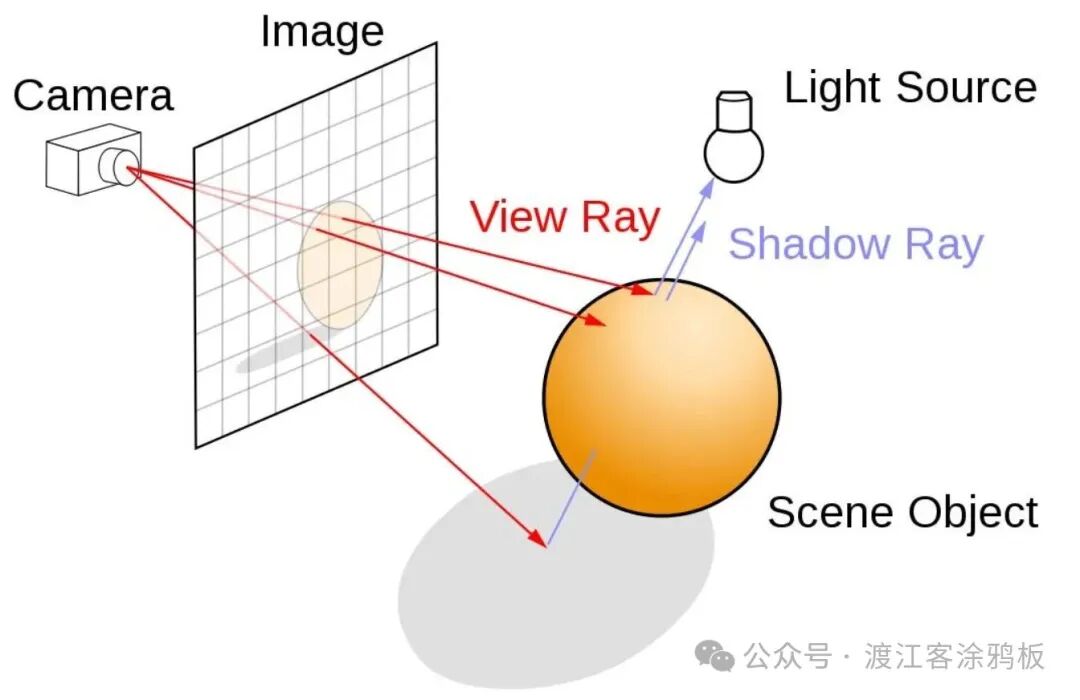
1、光线追踪基础知识
光线投射 是光线追踪算法中的一个过程,它从摄像机(眼睛位置)向图像平面中的每个像素发射一条或多条光线,然后检测这些光线是否与场景中的任何图元(三角形)相交。如果穿过像素并射向三维场景的光线击中了某个图元,则确定从原点(摄像机或眼睛位置)到该图元的距离,并将该图元的颜色数据用于确定像素的最终颜色。光线也可能反射并击中其他物体,并从中获取颜色和光照信息。
路径追踪 是一种更密集的射线追踪形式,它追踪数百或数千条光线穿过每个像素,并跟踪光线在到达光源之前多次从物体上反射或穿过物体的情况,以便收集颜色和光照信息。
包围体层次结构 (BVH) 是一种常用的光线追踪加速技术,它使用基于树状结构的“加速结构”,其中包含多个按层级排列的包围盒(包围体),这些包围盒或包围体包含或环绕不同数量的场景几何体或图元。逐条光线与场景中的每个图元相交进行测试效率低下且计算量巨大,而 BVH 是众多可用于加速此过程的技术和优化方法之一。BVH 可以组织成不同类型的树状结构,并且每条光线只需使用深度优先的树遍历过程与 BVH 进行测试,而无需与场景中的每个图元进行测试。在首次渲染场景之前,必须从源几何体创建 BVH 结构(称为 BVH 构建)。下一帧将需要根据场景变化执行新的 BVH 构建操作或 BVH 重新拟合操作。
去噪滤波 是一种高级滤波技术,无需额外投射光线即可提升性能和图像质量。去噪可以显著改善噪声图像的视觉质量,这些图像可能由稀疏数据构成,存在随机伪影、可见量化噪声或其他类型的噪声。去噪滤波尤其能够有效缩短光线追踪图像的渲染时间,并能从光线追踪器生成视觉上无噪声的高保真图像。去噪的应用包括实时光线追踪和交互式渲染。交互式渲染允许用户动态地与场景属性交互,并立即在渲染图像中看到更改后的更新结果。
2、渲染基础知识
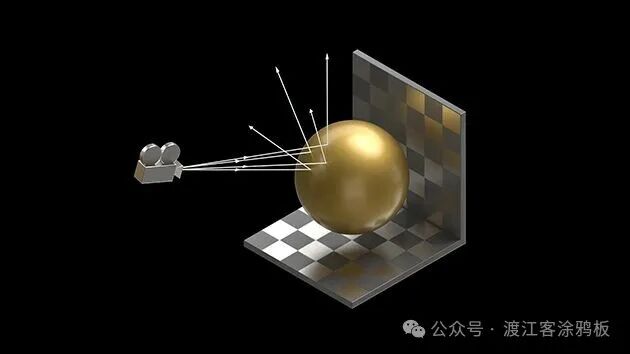
光栅化 是一种将三维物体显示在二维屏幕上的技术。光栅化技术利用不同形状和大小的虚拟三角形(或多边形)网格来创建屏幕上的物体。三角形的顶点(也称为角点)包含大量信息,包括其空间位置、颜色、纹理以及用于确定物体表面朝向的“法线”。计算机将三维模型的三角形转换为二维屏幕上的像素(或点)。每个像素都可以根据存储在三角形顶点中的数据分配一个初始颜色值。进一步的像素处理或“着色”,包括根据场景中光照情况改变颜色以及应用一个或多个纹理,最终生成应用于像素的最终颜色。光栅化技术应用于实时计算机图形学,虽然计算量仍然很大,但与光线追踪相比要小得多。
混合光栅化和光线追踪 是一种同时使用光栅化和光线追踪来渲染游戏或其他应用程序中场景的技术。光栅化可以识别可见物体并高效地渲染场景中的许多区域。光线追踪最适合渲染物理上精确的反射、折射和阴影。两者结合使用,可以有效地在保证良好帧率的同时实现高质量渲染。
摘自:https://developer.nvidia.com/discover/ray-tracing
二、Turing架构:RT Core的诞生
2018年,NVIDIA推出了具有里程碑意义的图灵(Turing)架构,首次引入了专门用于光线追踪的RT Core技术。图灵架构承载了RT Core以及全新Tensor Core,其中RT核心是专门用于实时光线追踪的处理器,能对光线和声音在3D环境中的传播进行加速计算,据称它的实时光线追踪能力提升到了Pascal架构的25倍。

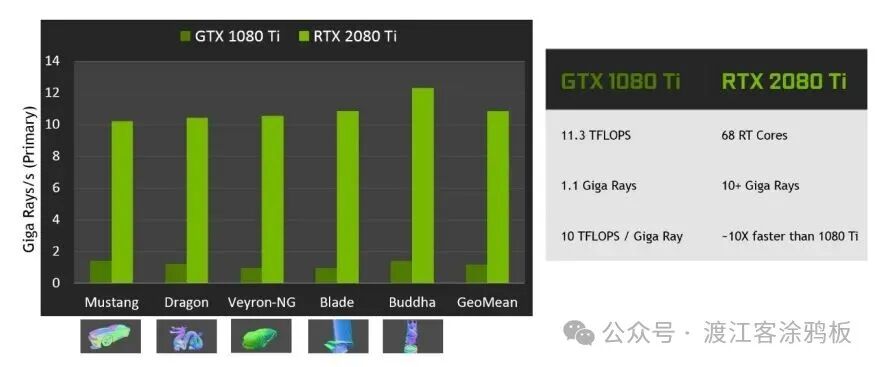
在硬件规格方面,图灵架构的高端TU102 GPU集成了186亿个晶体管,采用台积电12nm FFN工艺制造。以GeForce RTX 2080 Ti为例,该GPU包含6个图形处理集群(GPC)、36个纹理处理集群(TPC)、72个流式多处理器(SM),共计4,608个CUDA核心、72个RT Core、576个Tensor Core。每个SM单元配备1个RT Core,RTX 2080 Ti集成68个RT Core,可以实现每秒100亿条光线的实时计算,是GTX 1080 Ti的10倍。
三、Ampere架构:第二代RT Core(2020年)
2020年发布的Ampere架构带来了第二代RT Core,在多个维度实现了显著的性能提升。第二代RT Core的计算吞吐量是上一代的2倍,并能同时运行光线追踪和着色或降噪功能,从而大幅加快工作负载的运行速度,例如电影内容的逼真渲染和产品设计的虚拟原型创建。
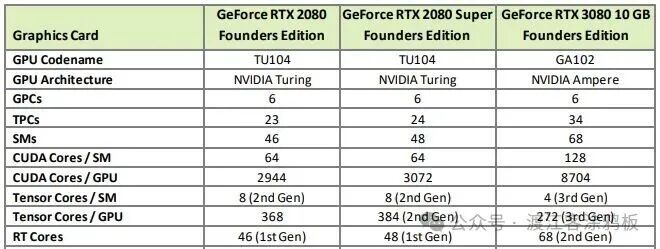
Ampere架构的技术创新不仅体现在RT Core的性能提升上,还包括全新的SM结构设计。与图灵架构相比,安培架构的CUDA核心能够以两倍的速度处理单精度浮点(FP32)运算,时钟频率下的性能提升达到2倍。在光线追踪性能方面,安培架构相比图灵架构实现了高达2倍的性能提升。
四、Hopper架构:数据中心的专业级RT Core(2022年)
2022年3月发布的Hopper架构主要面向数据中心和高性能计算场景,代表产品为H100 GPU。Hopper架构集成了800 亿个晶体管,采用台积电4N定制工艺制造。
Hopper架构的主要创新集中在第四代Tensor Core和Transformer Engine上。在RT Core方面,H100 GPU的配置相对保守,主要专注于为大规模AI训练提供强大的张量计算能力。
五、Ada架构:第三代RT Core的革命性升级(2022-2023年)
Ada Lovelace架构于2022-2023年推出,带来了第三代RT Core的重大技术突破。第三代RT Core在光线-三角形相交处理能力上实现了2倍的提升,使RT-TFLOPS性能提升超过2倍。
Ada架构的第三代RT Core包含了两个全新的专用硬件单元,标志着RT Core技术的重大演进:
1. 不透明微图引擎(Opacity Micromap Engine):
专门用于加速alpha测试纹理的光线追踪。该引擎能够直接对几何图形进行alpha测试,显著减少基于着色器的alpha计算,使开发者能够非常紧凑地描述不规则形状或半透明对象,如蕨类植物或栅栏,并使用Ada RT Core更高效地直接光线追踪它们。
2. 位移微网格引擎(Displaced Micro-Mesh Engine):
用于生成微三角形网格,称为位移微网格。该引擎支持10倍更快的BVH构建速度和20倍更少的BVH存储空间,使Ada RT Core能够以显著更少的BVH构建时间和存储成本光线追踪几何复杂的对象和环境。
在硬件规格方面,GeForce RTX 4090集成了128个第三代RT Core,性能达到191 RT TFLOPS。这一性能提升不仅体现在绝对数值上,更重要的是在处理复杂场景时的效率和质量提升。
六、Blackwell架构:面向AI渲染时代的RT Core(2024年)
2024年发布的Blackwell架构代表了RT Core技术的最新演进,标志着GPU从传统渲染向AI渲染时代的重要转变。第四代RT Core在多个方面实现了革命性升级,专门为支持Mega Geometry技术而设计。
第四代RT Core相比第三代进行了显著的架构创新:
1. 三角形集群交汇引擎(Triangle Cluster Intersection Engine):将原有的三角形相交引擎扩展为集群化处理,能够以簇集方式进行光线检测,大幅提升了处理大规模几何场景的效率。
2. 三角形集群解压缩引擎(Triangle Cluster Decompression Engine):专门用于处理压缩的几何数据,在保持高精度的同时显著减少内存占用。
3. 线性扫描球体单元(Linear Swept Spheres):专用于加速毛发渲染,能够使用球体代替三角形获得更准确的毛发形状拟合,具有更好的性能和较小的显存占用。
在性能方面,第四代RT Core的光线-三角形相交率相比第一代提升了7倍,相比第三代也有一倍的提升。RTX 5090集成的第四代RT Core性能达到360 RT TFLOPS,为全新的Mega Geometry技术提供了强大的性能支撑。
此外,Blackwell架构引入了全新的AI管理处理器(AMP),这是一个完全可编程的硬件处理器,能够精确控制和平衡帧生成与AI计算的所有需求。在混合了大语言模型、DLSS、帧生成等功能的游戏中,AMP能够优先保证基于LLM的数字人AI队友第一时间响应命令,同时确保帧渲染与刷新率接近或同步。这标志着RT Core与人工智能计算的融合达到了前所未有的深度。
七、技术演进总结与趋势分析
通过对RT Core五代技术演进的系统梳理,可以看出以下几个重要趋势:
(1)性能的指数级增长:从TURING架构的42.9RT TFLOPS到Blackwell架构的360 RT TFLOPS,RT Core的性能提升了超过8倍。特别是在光线-三角形相交处理能力上,第四代相比第一代提升了7倍。
(2)功能的多元化扩展:从最初单纯的光线追踪加速,RT Core逐渐发展为支持AI计算、3D感知、生成式AI等多元化应用的通用计算单元。特别是不透明微图引擎和位移微网格引擎的引入,大大扩展了RT Core的应用范围。
(3)与AI计算的深度融合:随着Tensor Core技术的同步演进,RT Core与Tensor Core、CUDA Core形成了越来越紧密的协同工作机制。在Blackwell架构中,这种融合达到了新的高度,通过AMP实现了AI计算与图形渲染的智能调度。
(4)面向未来的架构创新:Mega Geometry技术的引入标志着RT Core技术正在向处理超大规模几何场景的方向发展。支持的三角形数量可达5亿个,这为未来的元宇宙、数字孪生等应用提供了硬件基础。理解这些底层硬件的演进,对于从事计算机基础架构和高性能计算领域的开发者至关重要。
想要深入了解GPU、AI及更多前沿技术动态,欢迎访问云栈社区,与广大开发者一同交流学习。
免责声明:作者尊重知识产权、数据隐私,部分图片和内容来源于公开网络,版权归原撰写发布机构所有,如涉及侵权,请及时联系我们删除。
 发表于 2026-1-19 08:37:15
|
查看: 334|
回复: 0
发表于 2026-1-19 08:37:15
|
查看: 334|
回复: 0
