最近发现一个功能相当全面的开源项目 Voice-Pro 。虽然作者(ABUS团队)为了启动新项目已经停止了更新,但其最后一个版本(v3.2.0)的功能已经非常完善,基本整合了市面上好用的开源语音模型。
简单来说,这是一个基于 Gradio 构建的本地化工作站,主要目标是替代 ElevenLabs、Kapwing 这类昂贵的 SaaS 服务。
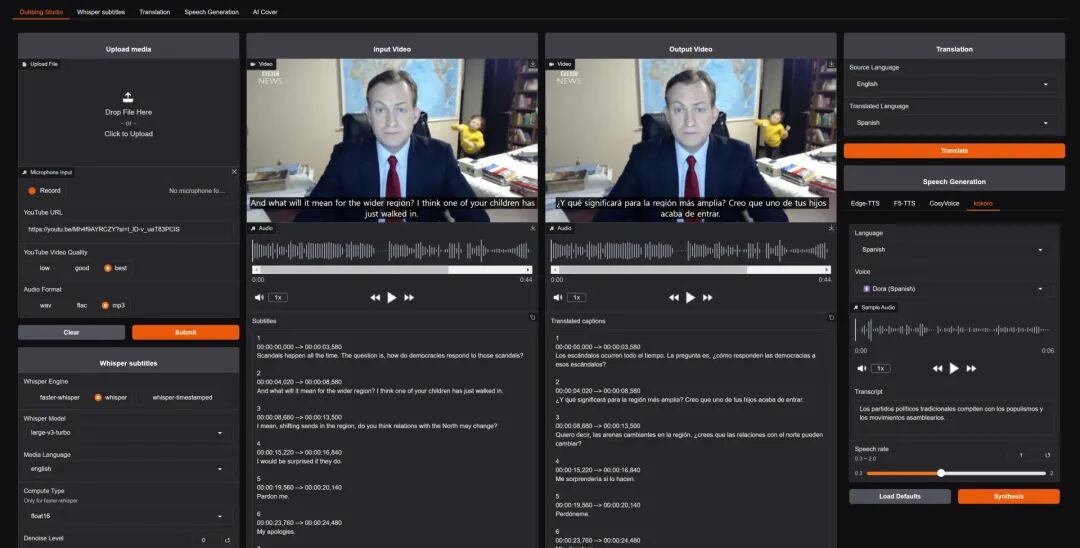
1. 核心功能(集成式解决方案)
该项目最大的价值在于将众多分散的工具整合到一个统一的 WebUI 中,省去了用户自行编写脚本调用多个组件的麻烦。
- 语音识别 (STT):
- 底层支持 Whisper, Faster-Whisper, Whisper-Timestamped 和 WhisperX。
- 支持 90+ 种语言,能够生成带单词级高亮标记的字幕文件。
- TTS & 语音克隆:
- Edge-TTS:微软的免费服务,支持 100+ 种语言和 400+ 种声音。
- Kokoro:在 HuggingFace TTS Arena 排行榜上表现优异的模型。
- 零样本语音克隆 (Zero-shot Voice Cloning):集成了 F5-TTS, E2-TTS 以及阿里开源的 CosyVoice。无需训练,直接提供一段参考音频即可克隆声音。项目内甚至预置了 Elon Musk、Joe Rogan 及 BTS 成员等人的参考音源。
- 多媒体处理 (Dubbing Studio):
- 内置 yt-dlp:可直接下载 YouTube 视频进行处理。
- 人声分离:调用 Demucs 模型,将背景音乐与人声分离。
- 字幕处理:支持字幕去噪,并可导出多种音频 (WAV, FLAC, MP3) 和字幕格式 (SRT, ASS 等)。
- 翻译:
- 支持超过 100 种语言的即时翻译,免费版本使用 Deep-Translator,也支持接入 Azure Translator API。
- 利用 spaCy 进行自然语言分句,使逐句翻译的结果更加自然。
2. 技术栈与硬件要求
项目代码主要由 Python (93.9%) 编写,UI 框架为 Gradio。
- 系统:Windows 10/11 (64-bit) 体验最佳。Mac 和 Linux 仅有脚本支持,官方未进行完整验证。
- GPU:强烈建议使用 NVIDIA 显卡。
- 需要 CUDA 12.4 版本。
- 显存:最低 4GB 可运行基础功能。但如果开启 Demucs 降噪或运行大型模型,推荐 8GB+。若显存不足,记得在设置中将计算精度调整为
int8,虽然 float 模式质量更好。
- 存储:建议预留 20GB 以上的空间,主要用于下载各类模型。
3. 部署与常见问题
虽然项目已停止更新,但代码完全开源且免费,用于本地运行没有问题。
- 安装:
- Windows 用户直接运行
configure.bat,脚本会自动配置 Git、ffmpeg、CUDA 等环境。
- 环境配置完成后,运行
start.bat 启动服务。
- 故障排除:
- 如果环境错乱或安装失败,最直接的方法是删除
installer_files 文件夹,然后重新运行配置脚本。
- 现状:目前版本停留在 v3.2.0 (发布日期 2025-12-05)。虽然有些遗憾,但作为一个离线工具,现有功能已经相当强大且实用。
总结
Voice-Pro 主要适合两类用户:一是自媒体从业者,需要大量处理字幕和配音,又不愿为 SaaS 平台支付月费;二是希望体验 F5-TTS 或 CosyVoice 等先进模型,但不愿一个个单独部署环境的开发者。
无论是用于视频内容搬运、本地字幕生成,还是进行简单的变声处理,这都是一个非常趁手的工具。对于对 Python 和 AI 音视频处理感兴趣的开发者,可以在 云栈社区 进一步交流相关技术。
项目地址: https://github.com/abus-aikorea/voice-pro?tab=readme-ov-file |  发表于 2026-1-19 17:09:34
|
查看: 303|
回复: 0
发表于 2026-1-19 17:09:34
|
查看: 303|
回复: 0
