在设备上进行神经网络(NN)推理相比于基于云端的处理具有诸多优势,包括可预测的延迟、增强的隐私性、更高的可靠性以及为供应商降低运营成本。
这激发了微控制器级神经网络加速器(通常称为神经处理单元(μNPUs))的快速发展,这些加速器专门针对超低功耗应用而设计。
在本文中,我们首次对多种商用可用的 μNPUs 进行了比较评估,并为其中一些平台提供了独立的基准测试。我们开发并开源了一个模型编译框架,以实现跨不同 μNPU 硬件的量化模型一致性基准测试。我们的基准测试针对端到端性能,包括模型推理延迟、功耗和内存开销以及其他因素。
分析结果揭示了硬件规格与实际性能之间的预期趋势以及令人惊讶的差异,包括一些 μNPUs 在模型复杂度增加时表现出意外的扩展行为。我们的框架为进一步评估 μNPU 平台提供了基础,并为这一快速发展的领域的硬件设计人员和软件开发人员提供了宝贵的见解。

论文链接: https://arxiv.org/abs/2503.22567
本文目录
- 一、引言
- 二、背景与动机
- 2.1 受限环境中的神经计算
- 2.2 μNPU 硬件设计
- 2.3 基准测试 μNPU 平台
- 三、架构与方法论
- 3.1 硬件
- 3.2 模型
- 3.3 评估指标
- 3.4 性能分解
- 四、结果与讨论
- 4.1 功率和效率分析
- 4.2 延迟和内存 I/O 分析
- 4.3 特定任务的考量
- 4.4 结果总结
- 4.5 未来发展方向
- 4.6 实用建议
- 4.7 限制
- 五、相关工作
- 六、结论
- 参考文献

一、引言
在受限设备上执行神经网络(NN)推理在众多领域都有应用,包括可穿戴健康监测[1]、智能农业[2]、实时音频处理[3]和预测性维护[4]。
与基于云端的替代方案相比,设备端推理具有诸多优势:
- 对于时间敏感型应用,可以改善延迟;
- 增强隐私性,因为无需传输敏感数据;
- 通过消除对网络连接的依赖,提高了可靠性;
- 并且通过消除数据传输需求,降低了供应商的运营成本。
鉴于其独特的外形尺寸和低功耗特性,微控制器(MCUs)被广泛应用于资源受限的环境。然而,它们的性能通常受到内存容量、吞吐量和计算能力的限制。
现代神经网络(NNs)的计算需求推动了从高性能数据中心到超低功耗和嵌入式设备的整个计算范围内的专用硬件加速器的发展。在资源受限的低端,微控制器级神经处理单元(μNPUs)最近开始出现,它们设计用于在极其严格的功耗范围内运行(毫瓦或亚毫瓦级别),同时仍能为实时推理提供低延迟。这些设备代表了一类新的加速器,结合了微控制器的功耗效率和此前仅属于更强大计算平台的认知能力。
μNPUs 的核心优势在于它们能够利用神经网络的固有并行性,通过专用的乘累加(MAC)阵列以及用于权重存储的专用内存结构来实现。
这种架构上的专门化使得 μNPUs 能够在执行等效工作负载时,与通用微控制器相比,实现数量级的延迟改进。尽管 μNPU 平台的数量不断增加,但该领域缺乏标准化的评估或全面的基准测试套件。
现有的基准测试仅关注 Analog Devices 的 MAX78000[5–7],缺乏与其他平台的比较。硬件供应商基于专有的评估框架提供性能指标,通常使用不同的神经网络模型、量化策略以及其他各种优化。
这种评估方法的异构性以及缺乏对供应商提供的性能声明的独立验证,为硬件设计人员和嵌入式软件开发人员在选择最适合其应用约束的 μNPU 平台时带来了不确定性。缺乏标准化的基准测试也阻碍了研究,因为它掩盖了架构设计与实际性能之间的关系。
鉴于 μNPU 平台的快速发展和日益多样化,为该领域建立可靠的比较基准已成为当务之急。为此,我们做出了以下贡献:
- 基准测试 μNPU 平台:我们首次对商用可用的 μNPU 平台进行了比较评估,使得能够在一致的工作负载和测量条件下,直接比较不同硬件架构的性能。
- 独立基准测试:我们还为一些此前未经过第三方评估的 μNPU 平台提供了首次细致且独立的性能基准测试,提供对供应商性能声明的无偏验证。
- 开源模型编译框架:我们开发并开源了一个框架,能够简化跨不同 μNPU 平台移植神经网络模型的过程,降低跨平台评估的工程开销。
- 开发者建议:基于我们的基准测试结果,我们为开发者提供了关于平台选择、模型优化的关键关注点以及各种应用场景和约束下的权衡的可行建议。
通过开发统一的编译和基准测试框架,我们在各种 μNPU 平台上标准化了模型表示,使得可以直接比较延迟、内存和能耗性能。
我们的评估还包括对模型执行各个阶段的细致分析,从 NPU 初始化和内存输入/输出开销到 CPU 预处理/后处理——这些方面可能会显著影响端到端性能,但在技术评估中常常被忽视。
分析结果揭示了硬件规格与实际性能之间的预期趋势以及令人惊讶的差异,包括一些 μNPUs 在模型复杂度增加时表现出意外的扩展行为。
我们希望我们的发现能够为开发者和硬件架构师提供宝贵的见解。
二、背景与动机
2.1 受限环境中的神经计算
从云端计算转向设备端神经计算在实时数据处理方面具有诸多优势,尤其是在数据隐私和安全日益受到关注的情况下[8]。与基于云端的解决方案不同,本地推理通过在本地处理敏感数据来降低安全风险,这在医疗诊断和监控等领域尤为有利[9, 10]。
此外,本地处理还可以减少端到端的延迟,并降低模型供应商的运营成本。然而,传统的神经网络加速器(如 GPU 和 TPU)由于功耗较高且外形尺寸较大,不适合在资源受限的环境中使用[11, 12]。微控制器(MCUs)是一种紧凑型、低功耗的计算平台,通常依赖于单个 CPU 和共享内存总线[13]。尽管 MCUs 常被用于资源受限的物联网(IoT)应用[14–16],但它们通常缺乏高效的神经网络推理计算能力。
具体来说,典型 MCUs 的计算能力通常仅能达到每秒数百万次乘累加(MAC)操作,远低于实时神经网络推理所需的每秒数十亿次 MAC 操作。它们缺乏专用硬件加速,导致在处理神经网络时出现较大的延迟开销和较高的功耗。此外,有限的 SRAM 和闪存内存也常常给高效管理神经网络模型所需的大型权重矩阵带来挑战。
鉴于传统 MCUs 的诸多不足,微控制器级 μNPUs 应运而生。
这些专用的神经网络加速器提供了专用的神经处理硬件,为神经网络工作负载提供了更高的吞吐量,满足了实时神经网络推理的严格要求[17–19],同时保持了低功耗运行。
总的来说,μNPUs 成为了在资源受限环境中高效、实时处理神经网络的关键解决方案。
2.2 μNPU 硬件设计
μNPU 硬件设计通过专用的乘累加(MAC)单元和可并行化的内存层次结构来优化高效的张量操作[20, 21]。图 1 展示了典型 μNPU 的架构,由一个脉动阵列(systolic array)的处理单元(PEs)组成。
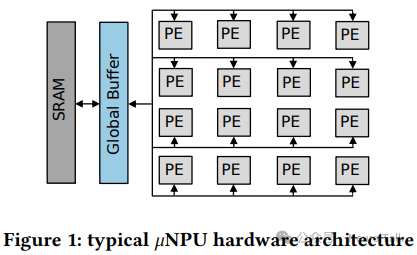
值得注意的是,每个 PE 都包含自己的 MAC 单元,更重要的是,它还有自己的权重内存空间,以避免内存争用并最大化并行化。PE 阵列通过 PE 间通信网格连接,该网格连接到一个大型全局缓冲区和通过片上网络连接的 SRAM/DRAM[22]。通过划分可用 RAM,并实现高带宽内存接口和数据预取机制,实现了高效的内存层次结构优化,解决了传统 MCUs 在处理大型神经网络模型权重时面临的内存瓶颈问题。
μNPUs 主要在 PE 的数量、PE 布局和聚类、内存层次结构布局以及每个 PE 中存储/ MAC 单元的可用性和数量上有所不同。这些架构优势,加上低功耗优化技术(如电源门控),使得 μNPU 平台能够为实时神经网络推理提供低功耗、高吞吐量的性能。
2.3 基准测试 μNPU 平台
采用 μNPU 平台的需求:对设备端神经计算的需求增加加速了 μNPUs 的开发和商业化。这一点从越来越多的供应商中得到了证明,例如 Arm[23],他们已经向市场推出了 μNPU 平台。
对全面基准测试的需求:现有的关于 μNPU 平台的工作主要关注实际应用和/或模型优化[24–26],缺乏从系统角度对性能进行细致分析。在评估 μNPU 平台的内存使用、延迟、功耗和吞吐量时,我们的目标是揭示关键的性能瓶颈,引导研究人员朝着更高效的软件和神经网络模型设计方向发展。
现有基准测试的局限性:现有的 μNPU 基准测试主要集中在单一平台上,缺乏对现在种类繁多的可用平台进行横向比较[6, 7, 27]。这种狭窄的视角限制了对不同 μNPUs 之间性能变化和基于任务的适用性的理解。现有的独立基准测试也存在显著的不足:大多数基准测试仅关注模型的前向推理过程,忽略了端到端模型推理或应用程序流程中的其他相关操作,例如 NPU 初始化、内存输入/输出(I/O)以及 CPU 预处理/后处理。尽管这些因素经常被忽视,但它们可能会显著影响整体性能和效率。
三、架构与方法论
我们首先详细介绍我们的基准测试硬件和模型,然后提供一个关于我们基准测试框架和模型推理流程的全面概述。
3.1 硬件
为了提供一个全面的基准测试,我们评估了一系列广泛使用的、商用的 μNPU 平台,从超低功耗的 μNPUs 到高性能的 NPU 集成系统级芯片(SoC)架构。这些平台与没有专用神经硬件的微控制器(MCUs)一起进行评估,以便进行比较。
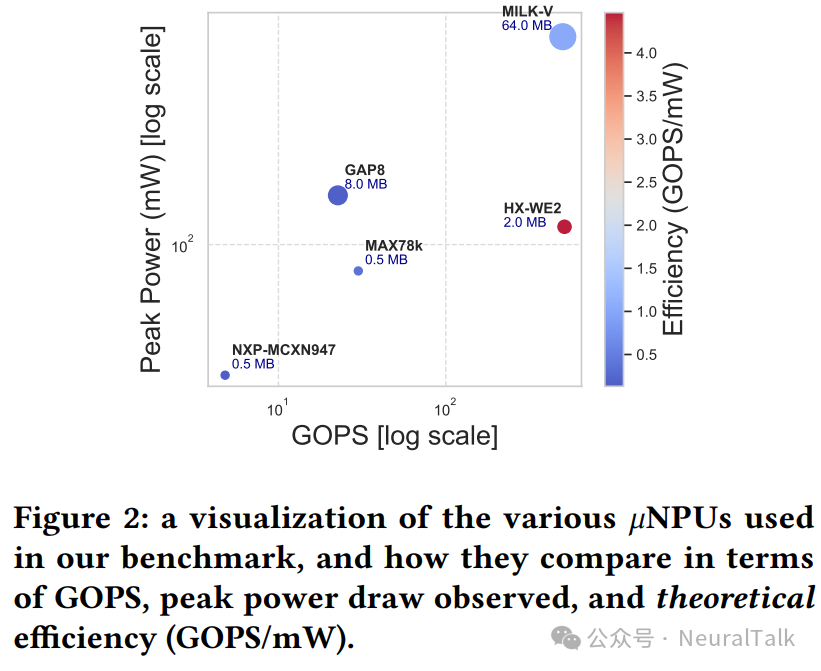
我们的选择涵盖了广泛的计算能力(小于 5 到大于 500 GOPs,即每秒十亿次操作)、内存配置(128 KB 到 2 MB RAM)以及位宽支持(从 1 位量化到 32 位浮点运算)。图 2 提供了我们基准测试中包含的各种 μNPU 平台的峰值 GOPS 与峰值功耗的可视化(以对数刻度表示)。
表 3 细列出了我们的基准测试 μNPUs,我们将在下面对每个平台进行更详细的介绍。
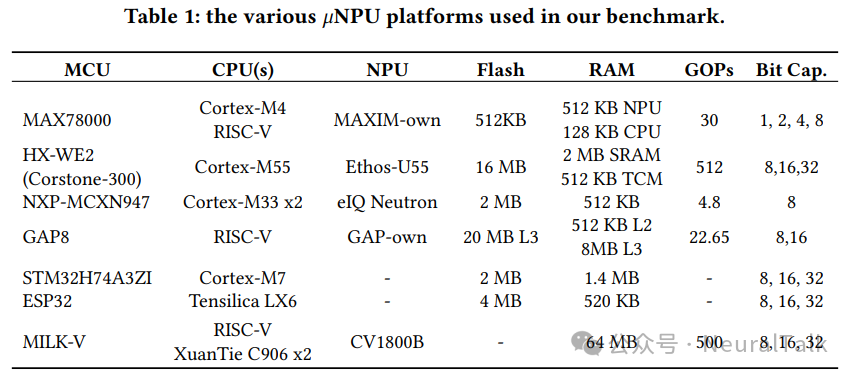
- MAX78000(或 MAX78K)[5]:Analog Devices 平台,包含 Cortex-M4F 和一个 RISC-V 协处理器(两者均可作为主处理器),以及专有的 30-GOPS CNN 加速器。加速器拥有专门的 512 KB SRAM 用于输入数据、442 KB 用于权重、2 KB 用于偏置,并支持 1/2/4/8 位量化。该细粒度位宽量化在其他 μNPU 平台或常见库中并不普遍(例如 TFLite/LiteRT [28]仅支持 8 位整数和 16 位浮点权重量化)。MAX78000 还拥有 512 KB 闪存和 128 KB CPU 专用 SRAM。该平台也是商用 μNPUs 中记录最完善的平台之一;既有研究对其 CNN 加速器进行了多种配置的基准测试[6, 7, 27],并探索了针对其 2D 内存布局的最佳模型与数据加载策略[29]。
- GAP8[30]:GreenWaves Technologies 平台,包含一个 8 核 RISC-V 集群和一个 22.65-GOPS 硬件卷积引擎,支持 8 位或 16 位精度加速。具备 512 KB L2 RAM、最多 8 MB L3 SRAM、以及 20 MB 闪存,适合更大/更复杂模型或混合专家(MoE)架构。已有研究多聚焦模型优化[26, 31, 32],但仍缺少平台级基准测试。
- Himax HX6538 WE2(HX-WE2)[33]:采用 Corstone-300(Cortex-M55 + Ethos-U55),峰值可达 512 GOPS。配备 512KB TCM、2MB SRAM、16MB 闪存,适合大型模型,但功耗也更高。
- NXP MCXN947[34]:MCX N94x 系列,包含双 Cortex-M33 与 NXP eiQ Neutron NPU,8 位加速能力为 4.8 GOPS;512 KB RAM、2 MB 闪存,面向低功耗。
- 无神经硬件 MCU 对照组:
- STM32H7A3ZI[35]:Cortex-M7,高性能 MCU,2 MB 闪存与 1.4 MB SRAM,常用于板载神经网络[16, 36]。
- ESP32s3[37]:双 Tensilica LX6,512 KB SRAM、2MB PSRAM、8MB 闪存;宣称通过扩展指令集(128 位矢量等)为神经网络计算提供加速。
- MILK-V Duo[38]:基于 CVITEK CV1800B 的 RISC-V SoC,运行 Linux,工作负载更灵活,但功耗预算更高。
3.1.1 关于 CPU 频率的说明
我们将各种 μNPU 平台配置为以统一的 CPU 频率运行。这样可以直接比较架构效率,但需要注意:许多平台能以更高频率运行,某些情况下接近 GHz。我们的方法有意隔离“架构效率”,后续实验可以探索频率变化对端到端延迟与功耗的影响。其他硬件参数大多也以默认方式标准化;不同 μNPU 平台的活动 PE 数量、内存布局配置以及其他硬件特定优化均可配置,且会影响整体效率。
3.2 模型
表 2 列出了基准测试使用的 CNN 模型,覆盖图像分类、目标识别和信号重建等应用。
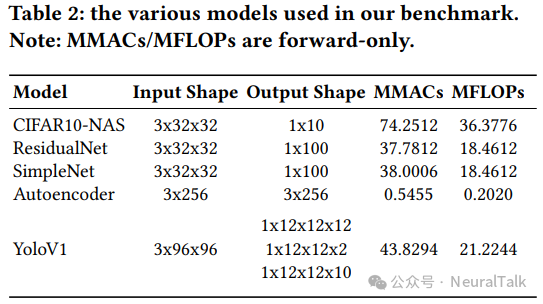
- CIFAR10-NAS:使用 Once-for-All(OFA)NAS 框架生成的 CIFAR-10 最优 CNN。是本文最大的模型:7430 万次 MAC、3640 万次 FLOPs;输入 3×32×32,输出 10 类[39]。
- ResidualNet:残差结构 CNN,3770 万次 MAC、1850 万次 FLOPs;训练于 CIFAR100,输入 3×32×32,输出 100 类。
- SimpleNet:基础卷积+池化堆叠的简化 CNN;3800 万次 MAC、1850 万次 FLOPs;训练于 CIFAR-100,输入 3×32×32,输出 100 类[40]。
- Autoencoder:对称编码器-解码器;仅 5455 次 MAC、2020 次 FLOPs;用于机器故障检测数据集(SpectraQuest 模拟器)[41];输入/输出 3×256。
- YoloV1:单阶段目标检测 CNN;4383 万次 MAC、2120 万次 FLOPs;训练于 COCO[42],仅检测“人”,输入 3×96×96;为跨平台一致性裁剪了最终层;NMS 后处理在 CPU 上执行。
3.2.1 确保模型一致性
我们在基准测试平台上遇到了算子支持的巨大差异,例如:
- NXP-MCXN947 的 eiQ Neutron NPU 缺乏 softmax 原生支持,需要作为 CPU 后处理实现。
- YoloV1 的 NMS 在不同平台上支持不一致,需要将 NMS 移到 CPU 后处理。
这也解释了 YoloV1 的多组件输出形状。基准测试平台还体现了不同的算子兼容性。例如 MAX78000 仅支持部分卷积:1D 卷积核大小 1~9,2D 卷积核为 1×1 或 3×3。不支持的操作会回退到 CPU 执行,并带来延迟惩罚。
通过识别并构建使用所有 μNPUs 普遍支持的核心操作子集的模型,我们旨在确保任何测量到的性能差异源于基本架构差异,而不是模型编译和优化的变化。
3.2.2 量化
我们将所有基准模型量化到 INT8 精度,因为所有评估的 NPUs 都支持它。
需要强调:这便于公平对比,但未必代表各平台“精度-性能”最优点。部分平台(如 MAX78000)支持更低位宽(1/2/4 位),而另一些(如 HX-WE2)支持浮点加速(FLOAT16/FLOAT32)。我们对所有模型/平台执行后训练量化(PTQ)。尽管部分平台支持 QAT 和融合算子,但这会产生平台特定模型,难以跨 NPU 兼容。
PTQ 使我们能保持模型结构一致性。并且我们关注的核心指标是延迟和功耗,而不是精度;因此 PTQ 对性能评估足够具有代表性。PTQ 使用领域代表性的校准数据集完成;不采用每通道量化,而采用每张量量化以确保跨平台兼容。
3.2.3 编译
各种 μNPUs 支持的模型格式差异很大,从常见格式(如 TFLite)到平台特定格式(如 CVITEK 的 CVIMODEL)。为便于跨平台部署,我们开发了自定义模型编译工作流,将基础模型转换为目标 NPU 的优化格式。
工作流输入 Torch(或 ONNX/TFLM)基础模型与编译器标志(目标 NPU、输入维度、位精度、PTQ 校准数据等),输出面向目标平台的优化模型与推理代码。编译过程依平台而异:例如针对 ARM Ethos-U55(HX-WE2)的模型使用 ARM Vela 编译器,接收 TFLiteMicro(TFLM)模型并生成 Ethos-U 优化二进制文件,同时应用平台特定优化(含内存减少策略)。
我们评估了两类 Size/Performance 策略:
- HX-WE2(S):最小化 SRAM 使用;
- HX-WE2(P):优先执行速度(若指定可用 arena 缓存则使用);
- 其他平台使用各自工具链(如 MAX78k SDK、NXP eIQ 门户工具等)。
在每种情况下,我们配置工具以保持模型结构等价性,同时应用平台适当的优化。需要注意:编译工作流通常会生成模板推理代码与编译后的模型,但不包含模型特定的预处理/后处理步骤;这些步骤应由开发人员结合应用自行实现并更新模板代码。
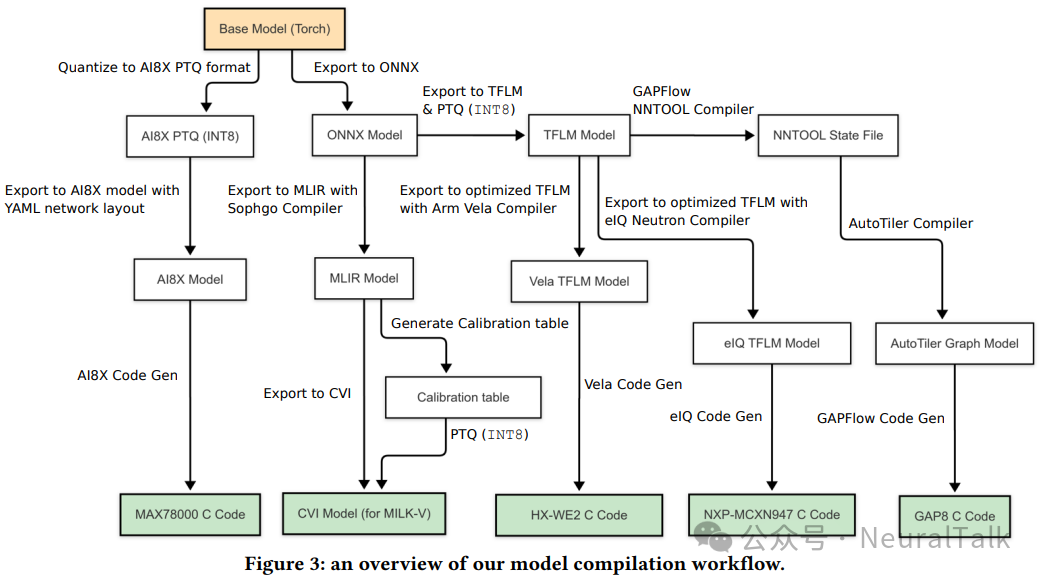
上图 3 详细介绍了我们的模型编译框架,用于将基础(Torch/ONNX/TFLM)模型转换为各种平台特定的格式。我们将开源我们的框架,希望它的使用可以简化跨平台模型编译和基准测试的过程。
3.3 评估指标
我们在每个基准平台和模型上测量延迟、功耗、能效(以每毫焦耳的推理操作次数表示)以及内存使用情况。各个平台上特定模型优化或编译工作流对模型精度的影响不在我们研究范围内。
3.3.1 延迟
使用每个平台的内部计时器测量延迟。除 MILK-V 外,所有 MCUs 配置为 100 MHz。MILK-V 不支持手动频率缩放,仅支持 DVFS。由于延迟与 CPU 频率成反比(延迟、周期数与频率之间关系可由常规比例关系表达),我们将 MILK-V 的延迟标准化,使其与统一频率条件下的性能相当。每个模型运行 10 次连续推理,报告平均延迟与标准差。
3.3.2 功耗和能量
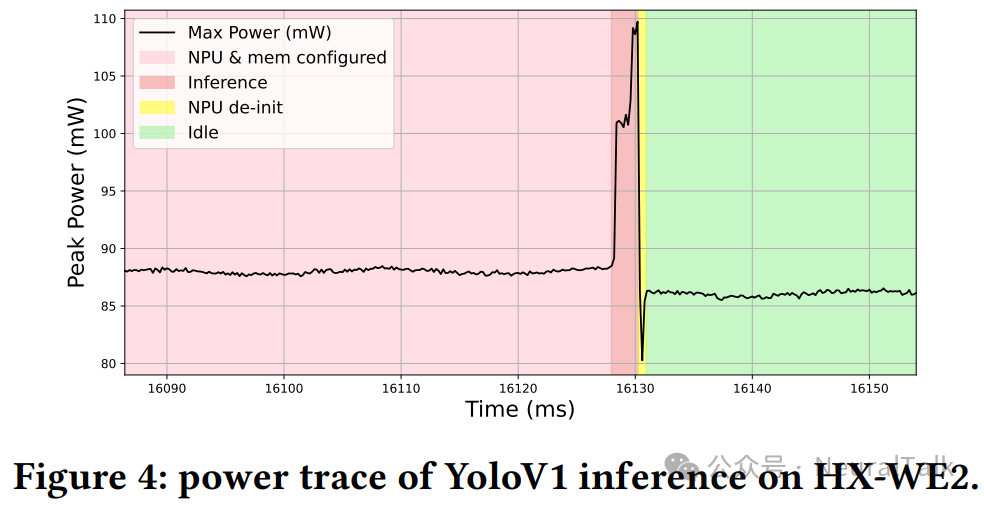
使用 Monsoon High Voltage Power Monitor [43] 以 50 Hz 采样率计算功耗和能量。输入电压设置为 3.3 V,捕获推理持续时间与平均功耗,从而得到平均能量消耗。为确保测量稳定,仅分析运行 1 分钟后记录的数据。对 10 次重复推理测量功耗,报告平均值和标准差。图 4 展示了 HX-WE2 的 Ethos-U55μNPU 上进行 YOLOv1 推理的功率曲线。
3.3.3 推理次数/毫焦耳
为了量化能效,我们引入“推理次数/毫焦耳”,表示每消耗 1 毫焦耳能量所执行的端到端推理次数(包括内存传输、CPU 预处理/后处理,以及可选的 NPU 初始化)。
3.3.4 内存使用
通过分析编译工具链生成的链接器文件来评估内存使用情况:该文件给出代码、初始化数据与未初始化数据段的分解。闪存使用量为代码与初始化数据总和,RAM 使用量包括初始化与未初始化数据段。对 MAX78000,由于其专用 NPU-only 内存,RAM 使用量分别按 CPU 与 NPU 计算。
3.4 性能分解
我们将模型执行的每个阶段进行分解,并测量每个阶段的延迟和功耗。这种细致分析有助于识别推理流程中的特定瓶颈,同时测量整体端到端性能。
我们还测量了平台空闲功耗(无活动计算时的基本功耗)。对无神经硬件的 MCUs(如 STM32H7A3ZI、ESP32),初始化与内存 I/O 合并计算。
分解阶段包括:
- NPU 初始化:NPU 设置开销,包括内存缓冲分配与内核配置。
- 内存 I/O:模型与输入数据加载成本,包括输入张量与模型权重在闪存、SRAM/DRAM 与 NPU 侧内存之间的搬运。
- 推理:NPU 上执行模型前向传递。
- 后处理:CPU 上执行的额外操作(例如 softmax、YoloV1 的 NMS 与输出 softmax)。Autoencoder 不需要后处理。
- 空闲:无活动计算时的基本功耗。
四、结果与讨论
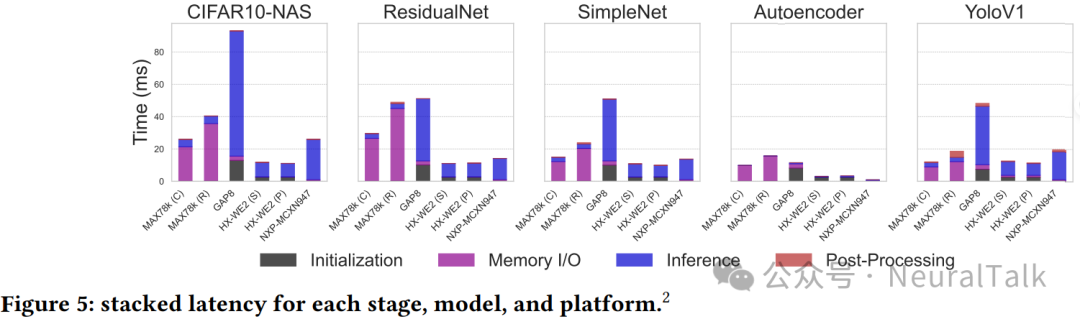
下图来自补充材料的表 6,列出了各阶段、模型与平台的完整延迟和功耗数据。
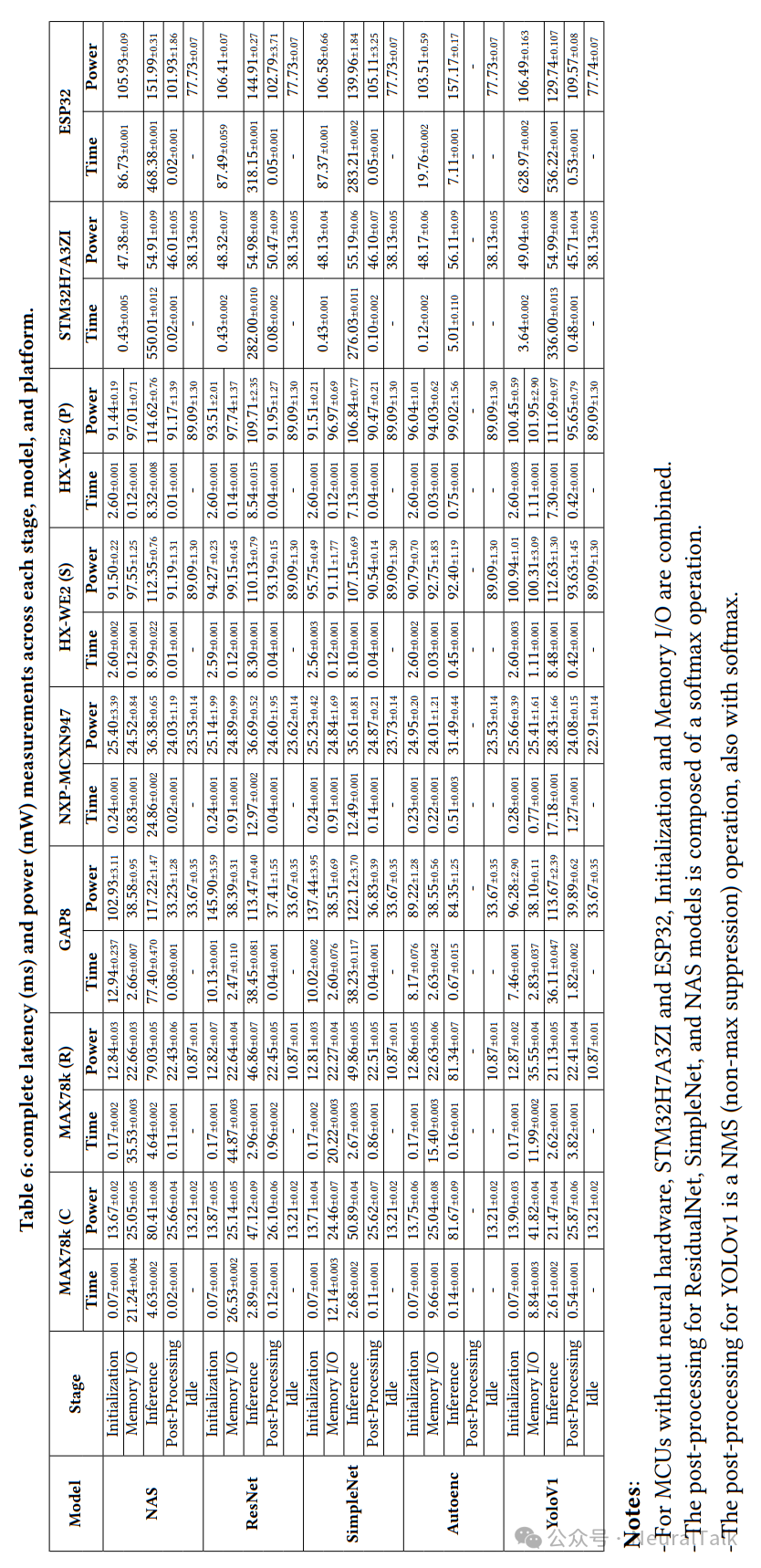
4.1 功率和效率分析
结果显示不同平台效率差异显著(见表 3、表 4)。
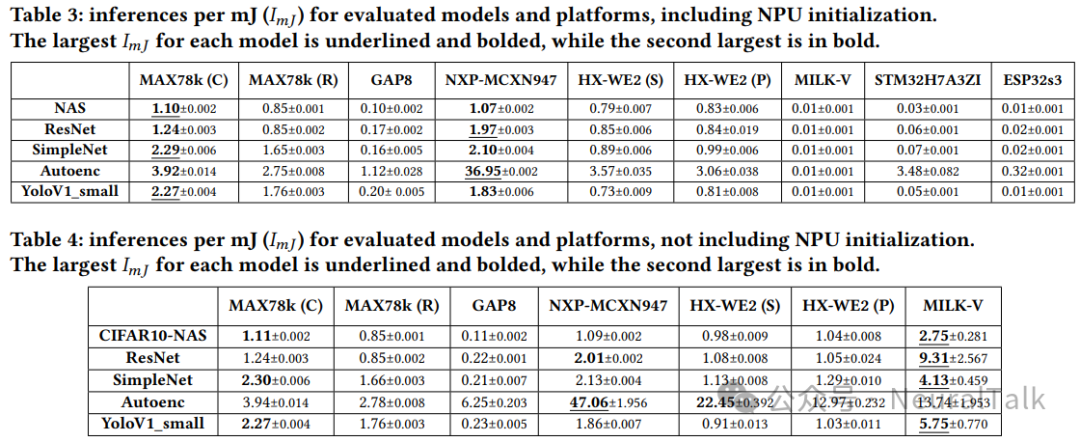
当考虑 NPU 初始化开销时,使用 Cortex-M4 CPU 的 MAX78000(C)在所有模型中展现出最佳整体效率,端到端延迟持续低于 30 ms。使用 RISC-V CPU 的 MAX78000(R)略逊一筹,与既有独立基准测试一致[6]。NXP-MCXN947 同样实现持续低于 30 ms 的延迟:其快速初始化与内存 I/O 抵消了(相对)较慢的推理延迟影响,即便吞吐量更低,在部分场景也能达到与 MAX78000 相当甚至更优的效率。
值得注意的是,功耗较高但延迟较低的 HX-WE2(Cortex-M55 + Ethos-U55)在端到端延迟上始终优于 MAX78000(C/R),原因在于后者内存 I/O 开销更大。相较 MAX78000(C/R),HX-WE2(S)与(P)平均端到端加速约 1.93× 与 3.07×,但平均功耗也分别增加约 3.13× 与 3.33×。此外,在 HX-WE2 上,Vela 的性能优化版本通常比尺寸优化版本延迟略低;但随着模型复杂度增加,效率提升减弱——例如在性能优化的 YoloV1 上,其效率反而低于尺寸优化变体。
无专用神经硬件的通用 MCUs(STM32H7A3ZI、ESP32s3)整体效率显著更低,从实证角度证明了在资源受限环境中进行端侧推理时专用神经硬件的价值:某些情况下端到端延迟可提升两个数量级。与此同时,STM32H7A3ZI 在推理功耗(54.91–56.11 mW)上与部分模型的 MAX78000(C/R)相当甚至更低,在 Autoencoder 上尤为明显:实现 3.483 次/毫焦耳,与测试套件中最优平台接近。这可能与 Cortex-M7 在处理 Autoencoder 的简单计算结构(0.5455 百万 MAC)时的效率有关。相较之下,ESP32 推理时功耗(129.74–157.17 mW)与延迟(7.11–536.22 ms)均偏高,即便其声称支持张量相关的 CPU 指令扩展。
总体而言,通用 MCU 对简单模型可能还算“够用”,但面对更复杂神经网络会很快变得不现实。RISC-V SoC(MILK-V)在考虑初始化开销时效率偏低;但若忽略初始化(例如连续运行场景),MILK-V 在几乎所有模型上的效率排名最高。尽管其空闲功耗更高,但推理时间极快(0.17–0.61 ms)。因此,对功耗不是第一约束、且不需频繁初始化/去初始化,但追求低延迟与紧凑外形的场景,MILK-V 可能是有效选择。
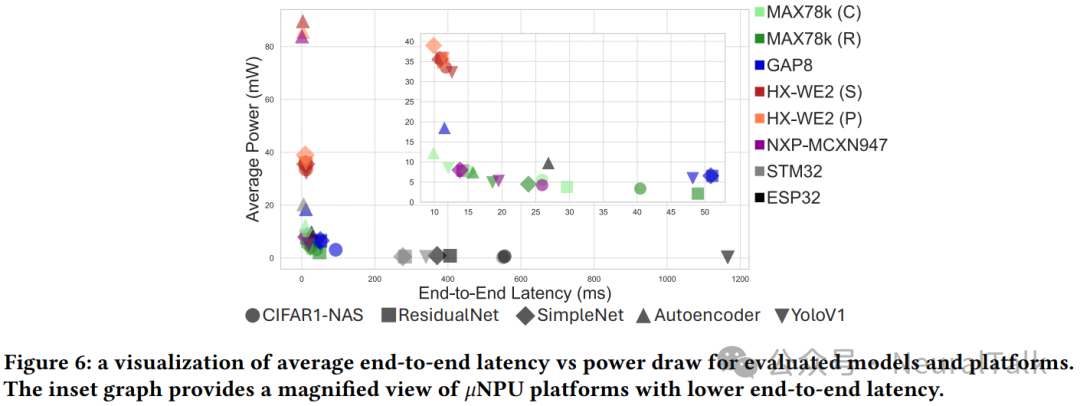
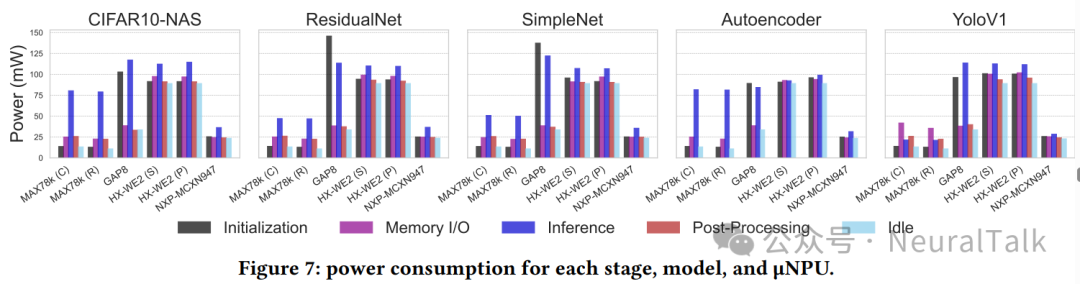
图 7 展示了功耗分布:MAX78000(10.87–80.41 mW)与 NXP-MCXN947(22.91–36.69 mW)在所有模型上功耗最低,且 NXP 在执行阶段的峰值功耗波动最小,使能量预算更可预测。
除了峰值功耗,空闲功耗对低功耗部署同样关键,尤其在低占空比场景。MAX78000 的空闲功耗最低(RISC-V:10.87 mW;Cortex-M4:13.21 mW)。HX-WE2 的空闲功耗最高(89.09 mW),这会引发其在极度功耗受限场景下的适用性担忧——当空闲时间占主导时,空闲功耗将主导总能耗。
4.2 延迟和内存 I/O 分析
4.2.1 NPU 初始化
不同平台初始化时间差异显著:MAX78000 低至 0.07 ms,GAP8 高达 12.94 ms。除 GAP8(7.46–12.92 ms)外,大多数 μNPU 的初始化开销相对端到端延迟几乎可忽略。但对需要频繁加载/卸载模型的占空比应用,这一开销可能成为问题。
4.2.2 内存 I/O
表 5 列出了各平台与模型的闪存和 RAM 使用情况。

MAX78000 的内存 I/O 延迟非常突出,成为主要瓶颈:平均内存 I/O 时间是推理时间的 6.10×(Cortex-M4)与 9.80×(RISC-V)。例如 ResidualNet 在 MAX78k(R)上,内存 I/O 为 44.89 ms,推理仅 2.96 ms,意味着超过 90% 的端到端时间花在内存操作而非计算。这表明 MAX78000 性能很大程度受内存限制,与既有独立基准一致[6]。
同一平台上,Cortex-M4 在内存 I/O 操作上比 RISC-V 更高效。
相比之下,其他共享 SRAM 的平台内存 I/O 开销几乎可忽略。与传统 CPU/GPU 一维连续内存不同,μNPU 采用二维内存布局:一个轴映射到并行计算核心,另一个轴组织逻辑地址空间;每个 PE 也配备独立权重内存空间,以避免争用并最大化并行。近期研究[29]针对该二维布局提出了减少 I/O 延迟的策略,包括:
- 在加速器内虚拟化权重内存以减少碎片;
- 优化动态权重分配以最小化加载/卸载;
- 权重预加载:由空闲 CPU 提前加载下一模型权重。
进一步研究可包括自动化内存管理,并结合即时预取、动态量化或输入自适应剪枝等技术,减少单模型执行的 I/O 延迟。相关主题也可在 人工智能 场景下延伸讨论,例如算子支持、端到端 profiling 与编译链优化如何协同。
4.2.3 推理
一个意外发现是:尽管 MAX78000 理论计算能力(30 GOPs)远低于 HX-WE2(512 GOPs),MAX78000 在推理延迟上仍更优。例如 MAX78000(C)平均比 HX-WE2(P)快约 2.48×。这可能与其更适合 CNN 的权重静止数据流模式有关。尽管 HX-WE2 显著降低了内存 I/O 延迟,但端到端延迟仍以 HX-WE2 更占优。HX-WE2 在不同模型上的推理时间相对一致,也暗示其架构可能更适合比本测试套件更大的模型。
MAX78000 在模型复杂度变化时推理延迟波动更大(0.14–4.63 ms),显示其可扩展性更强。GAP8 在所有模型上端到端延迟最高,平均比 MAX78000 慢 17×,尽管两者计算能力接近(22.65 vs 30 GOPs)。但 GAP8 更大的闪存与 RAM 使其更适合大型模型或 MoE。
4.2.4 CPU 后处理
后处理在许多基准测试中常被忽视,但它可能显著影响端到端延迟与效率。例如 YoloV1 的 NMS 在 MAX78000 的 RISC-V CPU 上后处理耗时 3.82 ms,而推理仅 2.62 ms。该现象提示:应尽量减少依赖 CPU 的后处理,并在设计基准测试时避免因算子不支持而回退到 CPU 导致的额外惩罚。我们通过确保模型在各平台上尽可能兼容 NPU,来实现端到端延迟的公平比较。
实际应用中,开发者往往会针对目标平台优化模型,因此仍需综合考虑:平台支持的算子范围(部分 NPU 支持很有限)、更强模型未修改部署时可能出现的精度与性能权衡,以及平台工具链所能提供的优化能力。
4.3 特定任务的考量
内存限制和模型复杂度
内存容量直接限制可部署的模型复杂度。例如 GAP8 的大内存(8MB RAM、20MB 闪存)可部署远大于 MAX78000(512KB NPU 内存、128KB CPU 内存)的模型。这对多类别检测或大词表音频分类等场景尤为关键。
内存 I/O 时序也揭示了平台适用性差异:MAX78000 较长的内存 I/O(8.84–26.53 ms)更适合持续模型部署;HX-WE2 具备更大闪存与更低内存 I/O(0.03–1.11 ms),但初始化更长(2.56–2.60 ms),因此更适合连续推理或动态模型切换。
操作模式和功耗特性
不同操作模式能力会影响平台适用性。例如 MAX78000 空闲(10.87–13.21 mW)与推理(21.13–81.67 mW)功耗变化大,利于占空比应用利用功耗门控机制。还需进一步研究低功耗模式、唤醒时间、功耗门控与 DVFS 等参数。
此外,具备非对称协处理能力的双 CPU 平台能改善任务分配,甚至实现核心分层唤醒,从而进一步节能。例如 MAX78000 结合低功耗 RISC-V 与更强 Cortex-M4,在动态低功耗推理策略下可能进一步优化能量使用。
精度要求和量化支持
位宽支持是部署关键因素之一。MAX78000 支持 1/2/4/8 位操作,适合可接受更低精度或可激进量化的应用;需要更高数值精度时,HX-WE2 的 FLOAT16/FLOAT32 支持可能更有优势。
4.4 结果总结
我们在多种商用 μNPU 平台上测量了多种模型架构的功耗与延迟。
我们发现,仅凭 GOPS 无法可靠预测端到端延迟,而内存带宽对性能影响巨大。
结论要点如下:
- 使用 Cortex-M4 的 MAX78000 在考虑初始化的情况下整体效率最佳,所有模型端到端延迟持续低于 30 ms;但高达 90% 时间用于内存 I/O,内存成为主瓶颈。
- HX-WE2 平均端到端延迟比 MAX78000 快约 1.93×,但功耗约增加 3.13×。
- NXP-MCXN947 端到端延迟也可低于 30 ms,初始化与内存 I/O 快;在低复杂度、内存轻量模型上效率突出。
- 通用 MCUs 效率显著更低,验证专用神经硬件优势。
- 排除初始化后(连续运行应用),MILK-V 效率总体排名最高:更高空闲功耗被极快推理时间抵消。
- NXP-MCXN947 在 Autoencoder 上排名最高,无论是否考虑初始化,都比最近竞争对手实现超过 2× 的效率提升。
关键差异化因素包括:内存容量(决定模型复杂度)、功耗特性(如 MAX78000 空闲与推理差异大,利于占空比)、以及精度支持(MAX78000 支持 1–8 位,HX-WE2 支持至 32 位浮点)。
4.5 未来发展方向
推进硬件架构
开发具有更大片上缓存和改进内存吞吐量的下一代 μNPU 架构是显而易见的优先事项,这将:
- 减少某些平台上的显著内存 I/O 开销(例如 MAX78000);
- 支持部署更大、更强模型或 MoE,用于上下文感知推理。
优化模型权重加载
与硬件联合优化,改进模型架构与加载策略以最大化数据重用至关重要。显著内存 I/O 瓶颈提示需要针对 μNPU 的权重虚拟化、动态分配优化与预取策略。
扩展算子支持
目前多数 μNPU 平台算子支持极为有限,主要集中在 CNN 基础算子。未来设计应纳入更广算子集,以支持更多样化架构,例如 Transformer。
改进量化和模型压缩
细粒度位宽量化与其他非标准优化在 μNPU 平台上支持不足。硬件与软件生态需要加强;现有资源受限设备软件库也缺乏灵活性,例如 TFLite/LiteRT 仅支持 8 位整数和 16 位浮点权重量化。
启用设备端训练
当前 μNPU 平台仅支持推理,不支持设备端训练。设备端训练可实现个性化、持续学习并适应分布漂移,且无需云端依赖,尤其有利于隐私与远程部署。未来设计应支持量化设备端训练,需要高效训练算法与硬件对反向传播的支持。
标准化模型格式
模型格式异构增加跨平台编译与部署开销。硬件供应商应推动统一模型格式,降低移植成本。
开发准确的模拟器
对 μNPUs(及 MCUs)而言,可靠软件模拟器与延迟/功耗/内存预测模型仍明显缺失。此类工具可让开发者在无实体硬件情况下完成优化,加速端到端开发周期。
4.6 实用建议
面向嵌入式开发人员和硬件设计人员,建议如下:
对于能效
MAX78000 在考虑初始化的情况下能效显著领先,适合电池供电应用。若目标是延长电池寿命,可考虑利用其在空闲期间动态关闭系统部分区域的能力。
对于延迟敏感型应用
- HX-WE2 具备快速初始化、内存 I/O 与推理本身,适合需要响应式模型切换、实时适应变化条件或间歇性/占空比操作的场景。
- NXP-MCXN947 也实现低端到端延迟,同时功耗预算更低,适合功耗受限工作负载。
同时,对延迟敏感且空间受限的应用,如果功耗不是主要限制因素、且不需频繁初始化/去初始化,更强 SoC(如 MILK-V)也可能合适。未来可探索其他 SoC 平台[44, 45]表现。
对于大型模型
GAP8 的大内存适合部署更大、更复杂模型,或实施基于条件的多专家网络切换,尽管其初始化时间更长、推理延迟更高。若功耗不是主要问题,MILK-V 的低推理延迟与大内存(支持 SD 卡)也可能是强选择。
对于安全与效率
作为基于 Arm 的平台,NXP-MCXN947 支持 TrustZone[46],可在安全与非安全区域间硬件隔离。结合其有竞争力的端到端延迟(0.96–25.95 ms)与较低功耗(22.91–36.69 mW),适合对安全有较高要求但不极端受限的应用。后续可探索将安全执行环境扩展到集成 μNPU 加速(例如通过 I/O 直通),实现受保护但高效的推理。
对于简单模型
模型足够简单时,像 STM32H7 这样的通用 MCU 即使没有专用加速,也能实现有竞争力的效能,从而免去专用硬件需求。
4.7 限制
解读基准测试结果时,需要考虑以下限制:
频率标准化
统一 CPU 频率便于比较架构效率,但不展示峰值性能;许多平台可在更高频率运行。
固定量化位宽
标准化 INT8 便于公平比较,但未利用支持更低位宽(MAX78000 的 1/2/4 位)或更高精度(HX-WE2 的 FLOAT16/FLOAT32)的平台能力;本文也只将量化视作缩小模型大小的手段,未覆盖其他优化维度。
CPU 配置
实验中统一 CPU 分频器设置;而多平台支持可变分频器,这会影响效率曲线。
模型适应性限制
为保持跨平台结构一致性,模型优化需要妥协;针对特定平台的优化可能得到不同效率曲线。
算子支持
通过确保模型兼容 NPU,我们排除了不支持算子回退影响。未来应研究在不同算子集平台上使用更复杂或未修改模型、以及针对精度优化模型时的性能扩展与平台特定优化影响。
开发工具链成熟度
本文聚焦性能指标;但平台选择时常被忽略的关键因素还包括:工具链成熟度与模型优化工具的完善程度,值得后续研究。
五、相关工作
端到端基准测试
在资源受限与移动计算平台上对 NN 模型进行基准测试的研究逐渐增多:
- MLPerf mobile inference 基准测试提供行业标准开源框架,用于评估移动设备上多样化加速器与软件栈的 NN 性能[47]。
- Laskaridis 等研究了大型语言模型在 Android、iOS 与 Nvidia Jetson 等移动平台的效率[48]。
- Reuther 等探索了从蜂窝 GPU、FPGA 到数据中心硬件等广泛 NN 加速器的性能与功耗特性[49]。
然而,以往关于 μNPU 的研究多局限于应用层评估[18, 19]或单一平台独立基准[6, 27],且常忽略端到端流程中的部分操作[7]。据我们所知,本文是首个对多个商用 μNPU 平台进行并排、细致的端到端基准测试研究。
针对 MCUs 的 NN 加速器
除商用加速器(如 Arm Ethos-U55)外,近期研究提出了更高效的定制设计:
- RaPiD:面向超低功耗 INT4 推理与训练,实现 3–13.5 TOPS/W(平均 7 TOPS/W)能效[50]。
- XNOR 神经引擎:面向二值网络的可配置硬件加速 IP,集成到带自主 I/O 子系统与混合存储器的 MCU 中[51]。
高效的设备端推理
在 MCUs 部署 NNs 受制于内存容量、吞吐量与功耗[52, 53]。相关研究包括模型压缩[12, 54, 55]、更高效算子/架构设计[56–58]、基于输入复杂度的自适应推理[59–61],以及硬件侧并行数据流优化[21]。本文工作旨在识别现有最佳实践与瓶颈,推动 μNPU 上更高效的部署。
六、结论
我们对多种商用可用 μNPUs 上的多种 NN 模型进行了全面评估,揭示了预期趋势以及意外发现,为嵌入式神经计算领域提供了系统性证据。专用神经加速的性能优势清晰可见:与通用 MCUs 相比,专用平台在某些情况下实现了高达两个数量级的能效提升。
此外,我们发现仅凭理论计算能力(GOPs)无法准确预测实际性能。通过按阶段分解推理流程,我们识别了关键瓶颈(尤其是内存 I/O),并为未来硬件与模型设计提供了重要参考。实际部署时,开发者需要在延迟、能效、模型复杂度与算子灵活性之间做权衡:你的应用是低占空比、长待机?还是连续推理、强实时?不同答案会导向不同平台选择。
我们开源了基准测试框架,希望其使用能够简化跨平台模型编译与评估。更多端侧推理与硬件选型讨论,可在云栈社区 https://yunpan.plus 获取相关资源与交流。
参考文献
[1] Pietro Mercati and Ganapati Bhat. Self-Sustainable Wearable and Internet of Things (IoT) Devices for Health Monitoring: Opportunities and Challenges. IEEE Design and Test, 42(2):35–60, 2025.
[2] Sarah Condran, Michael Bewong, Md Zahidul Islam, Lancelot Maphosa, and Lihong Zheng. Machine Learning in Precision Agriculture: A Survey on Trends, Applications and Evaluations Over Two Decades. IEEE Access, 10:73786–73803, 2022.
[3] Chanwoo Kim, Dhananjaya Gowda, Dongsoo Lee, Jiyeon Kim, Ankur Kumar, Sungsoo Kim, Abhinav Garg, and Changwoo Han. A Review of On-Device Fully Neural End-to-End Automatic Speech Recognition Algorithms. 2020.
[4] Emil Njor, Mohammad Amin Hasanpour, Jan Madsen, and Xenofon Fafoutis. A Holistic Review of the TinyML Stack for Predictive Maintenance. IEEE Access, 12:184861–184882, 2024.
[5] Maxim Integrated. MAX78000. 2025. https://www.analog.com/en .
[6] Arthur Moss, Hyunjong Lee, Lei Xun, Chulhong Min, Fahim Kawsar, and Alessandro Montanari. Ultra-Low-Power DNN Accelerators for IOT: Resource Characterization of the MAX78000. ACM SenSys, 2022.
[7] Mitchell Clay, Christos Grecos, Mukul Shirvaikar, and Blake Richey. Benchmarking the MAX78000 artificial intelligence microcontroller for deep learning applications. SPIE, 2022.
[8] Linghe Kong et al. Edge-computing-driven Internet of Things: A survey. ACM Computing Surveys, 55(8), 2022.
[9] Ruijin Wang et al. Privacy-preserving Federated Learning for Internet of Medical Things under Edge Computing. IEEE J-BHI, 27(2), 2022.
[10] Cheng Wang et al. The security and privacy of mobile-edge computing: An artificial intelligence perspective. IEEE IoT Journal, 10(24), 2023.
[11] Jinhyuk Kim and Shiho Kim. Hardware accelerators in embedded systems. Springer, 2023.
[12] Ji Lin et al. MCUNet: Tiny deep learning on iot devices. NeurIPS, 2020.
[13] Swapnil Sayan Saha et al. Machine learning for microcontroller-class hardware: A review. IEEE Sensors Journal, 22(22), 2022.
[14] Ji Lin et al. On-device training under 256kb memory. NeurIPS, 2022.
[15] Young D Kwon et al. TinyTrain: resource-aware task-adaptive sparse training of DNNs at the data-scarce edge. arXiv:2307.09988, 2023.
[16] Yushan Huang et al. Low-Energy On-Device Personalization for MCUs. IEEE/ACM SEC, 2024.
[17] Erez Manor and Shlomo Greenberg. Custom Hardware Inference Accelerator for Tensorflow Lite for Microcontrollers. IEEE Access, 10, 2022.
[18] Guanchu Wang et al. Bed: A Real-Time Object Detection System for Edge Devices. ACM CIKM, 2022.
[19] Weining Song et al. TaDA: Task Decoupling Architecture for the Battery-less Internet of Things. ACM SenSys, 2024.
[20] Luca Caronti et al. Fine-grained hardware acceleration for efficient batteryless intermittent inference on the edge. ACM TECS, 22(5), 2023.
[21] Taesik Gong et al. DEX: Data Channel Extension for Efficient CNN Inference on Tiny AI Accelerators. NeurIPS, 2025.
[22] Vivienne Sze et al. How to Evaluate Deep Neural Network Processors: TOPS/W (Alone) Considered Harmful. IEEE Solid-State Circuits Magazine, 12(3), 2020.
[23] ARM. ARM Ethos-U Processor Series Brief, 2022. Accessed: 2025-03-12.
[24] Marco Giordano and Michele Magno. A Battery-Free Long-Range Wireless Smart Camera for Face Recognition. ACM SenSys, 2021.
[25] Abu Bakar et al. Protean: An energy-efficient and heterogeneous platform for adaptive and hardware-accelerated battery-free computing. ACM SenSys, 2022.
[26] Edward Humes, Mozhgan Navardi, and Tinoosh Mohsenin. Squeezed Edge YOLO: Onboard Object Detection on Edge Devices, 2023.
[27] Yushan Huang et al. Energy Characterization of Tiny AI Accelerator-Equipped Microcontrollers. 2024.
[28] TensorFlow.org. TensorFlow Lite for Microcontrollers. https://www.tensorflow.org/lite/microcontrollers . Accessed: 2025-03-13.
[29] Changmin Jeon et al. TinyMem: Boosting Multi-DNN Inference on Tiny AI Accelerators with Weight Memory Virtualization. HotMobile ’25, 2025.
[30] GreenWaves Technologies. GAP8 Product Brief, 2021. Accessed: 2025-03-12.
[31] Cristian Ramírez et al. Communication-Avoiding Fusion of GEMM-Based Convolutions for Deep Learning in the RISC-V GAP8 MCU. IEEE IoT Journal, 11(21), 2024.
[32] Julian Moosmann et al. Flexible and Fully Quantized Lightweight TinyissimoYOLO for Ultra-Low-Power Edge Systems. IEEE Access, 12, 2024.
[33] Himax Technologies. WiseEye2 AI Processor, 2025. Accessed: 2025-03-12.
[34] NXP Semiconductors. FRDM-MCXN947 Development Board, 2025. Accessed: 2025-03-12.
[35] STMicroelectronics. STM32H7A3ZI Microcontroller, 2025. Accessed: 2025-03-12.
[36] Tommaso Addabbo et al. Gravimetric system for enhanced security... IEEE TIM, 71, 2022.
[37] Espressif Systems. ESP32-S3 Datasheet, 2025. Accessed: 2025-03-12.
[38] Milk-V. Milk-V Duo, 2025. Accessed: 2025-03-12.
[39] Han Cai et al. Once-for-All: Train One Network and Specialize it for Efficient Deployment, 2020.
[40] Seyyed Hossein Hasanpour et al. Lets keep it simple: Using simple architectures..., 2023.
[41] Analog Devices Inc. Motor Fault Sample Dataset. https://github.com/analogdevicesinc/CbM-Datasets/tree/main . Accessed: 2024-04-01.
[42] Tsung-Yi Lin et al. Microsoft COCO: Common Objects in Context, 2014. Accessed: 2025-03-12.
[43] Monsoon Solutions Inc. Monsoon High voltage power monitor. 2024. https://www.msoon.com/ .
[44] Luckfox. Luckfox Pico. https://www.luckfox.com/Luckfox-Pico . Accessed: 2025-03-17.
[45] Canaan. K230. https://developer.canaan-creative.com/k230/zh/dev/00_hardware/K230_datasheet.html . Accessed: 2025-03-17.
[46] ARM. ARM TrustZone, 2025. Accessed: 2025-03-17.
[47] Vijay Janapa Reddi et al. MLPerf mobile inference benchmark. PMLR Systems, 4, 2022.
[48] Stefanos Laskaridis et al. Melting point: Mobile evaluation of language transformers. MobiCom, 2024.
[49] Albert Reuther et al. Survey and benchmarking of machine learning accelerators. IEEE HPEC, 2019.
[50] Swagath Venkataramani et al. RaPiD: AI accelerator for ultra-low precision training and inference. ISCA, 2021.
[51] Francesco Conti et al. Xnor neural engine... IEEE TCAD, 37(11), 2018.
[52] Sayed Saad Afzal et al. Battery-free wireless imaging of underwater environments. Nature Communications, 13(1), 2022.
[53] Yuchen Zhao et al. Towards batteryfree machine learning and inference in underwater environments. HotMobile, 2022.
[54] Tejalal Choudhary et al. A comprehensive survey on model compression and acceleration. Artificial Intelligence Review, 53, 2020.
[55] Muhammad Zawish et al. Complexity-driven model compression for resource-constrained deep learning on edge. IEEE TAI, 5(8), 2024.
[56] Yu Pan et al. Reusing pretrained models by multi-linear operators for efficient training. NeurIPS, 2023.
[57] Jakub M Tarnawski et al. Efficient algorithms for device placement of dnn graph operators. NeurIPS, 2020.
[58] Lingda Li et al. A simple yet effective balanced edge partition model for parallel computing. 2017.
[59] Stefanos Laskaridis et al. Adaptive Inference through Early-Exit Networks. EMDL’21, 2021.
[60] Bita Darvish Rouhani et al. Delight: Adding energy dimension to deep neural networks. ISLPED ’16, 2016.
[61] Noam Shazeer et al. HydraNets: Specialized Dynamic Architectures for Efficient Inference. CVPR, 2018.
 发表于 2026-1-20 16:27:41
|
查看: 345|
回复: 0
发表于 2026-1-20 16:27:41
|
查看: 345|
回复: 0
