分布式系统的世界,就像一座没有路标的“黑暗森林”。
当你刚从单体应用的舒适区走出来,踏入这片森林时,很容易感到迷茫:
- 满眼都是 CAP、BASE、Paxos、Raft 这些晦涩的术语;
- 到处都是 Redis、Kafka、etcd、TiDB 这些复杂的组件;
- 你知道要“高可用”,也知道要“高性能”,但当两者冲突时,你不知道该往左走还是往右走。
市面上的资料汗牛充栋,但往往两极分化:要么是晦涩难懂的学院派论文,读完就是“从入门到放弃”;要么是碎片化的工具教程,教你配置了一百个参数,却没告诉你 为什么要这么配。
我们缺的不是知识点,而是一条清晰的、能够串联起所有知识的“路径”。
接下来这份内容,会用“系统从小到大”的演进方式,把关键概念串成一条可走的路线:从世界观、到生存技能、再到理论高峰,最后眺望未来。你会更关注 “Why” 和 “Trade-off(权衡)”,而不是只背 “How”。
这张“路线图”长什么样?
这不是知识点堆砌,而是一场目标明确的探险:回到原点,模拟一个系统从小到大的演进过程,让你亲历那些 “不得不做” 的架构决策。
下面是路线图示意:
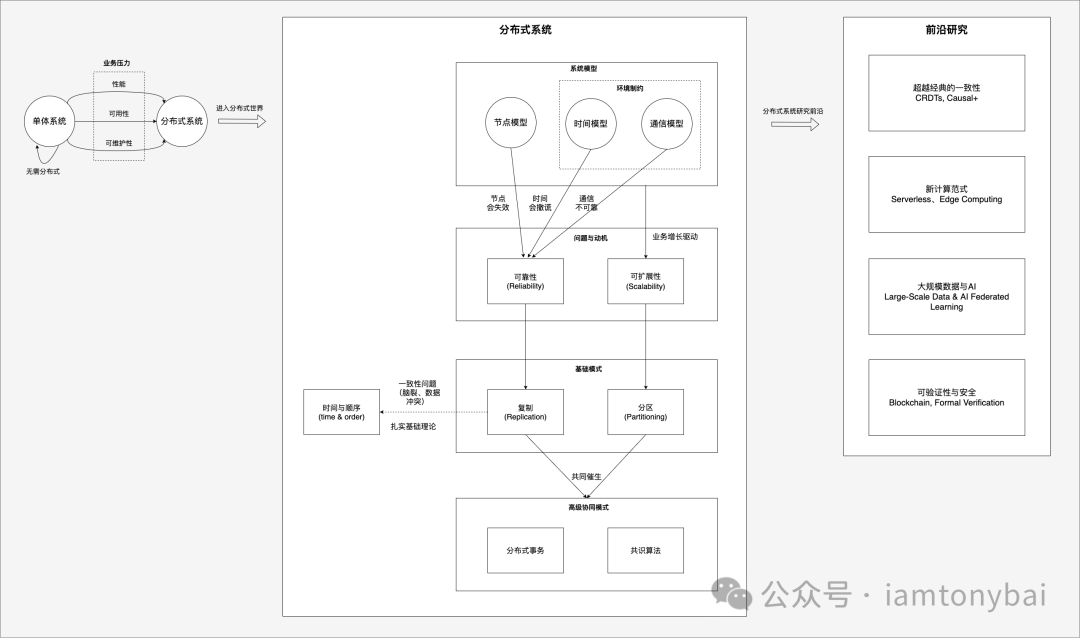
沿着这条路线,我们将经历四个关键里程碑。
第一站:重塑世界观(从单体思维走出来)
第一步是打破“单体思维”的幻想。在这个阶段,你需要学会 “拥抱失败”,并承认分布式的底层现实。
你会反复遇到这些问题:
- 为什么说 “物理时钟是不可靠的幻象”?
- 为什么在分布式世界里,“不确定性” 才是唯一的确定?
- 如何建立一套全新的 系统模型,用来解释延迟、丢包、重试、乱序、分区等现象?
当你开始用“系统模型”而不是“理想网络”思考问题时,很多争论(比如一致性与可用性)会变得更具体,也更可落地。
第二站:掌握生存技能(复制与分区)
为了让系统活下去并壮大,你需要两把武器:复制 与 分区。
这部分会把你从“会用组件”带到“懂它为什么这样设计”。
复制:主从 vs 无主
- 主从 vs 无主: 是选择“权威中心”的效率,还是“民主联邦”的韧性?
- 当网络抖动、节点故障、延迟飙升时,你的复制策略如何影响:写入路径、读一致性、故障恢复、以及运维复杂度?
分区:一致性哈希与扩容的“数据风暴”
- 分区的陷阱: 一致性哈希是如何优雅地解决扩容时的“数据风暴”的?
- 分区键怎么选?热点怎么处理?扩缩容会带来什么副作用?
如果你正在系统性梳理 分布式系统 的知识结构,这一站的关键是:把“复制/分区”当作设计的基础积木,而不是某个中间件的“配置项”。
逻辑时间:当物理时间失效时怎么办?
当物理时间不足以表达因果关系时,需要引入逻辑时间:
它们解决的不是“时间更准”,而是“因果更清晰”。当你需要解释“谁先发生、谁后发生、是否并发发生”时,这套工具会非常关键。
第三站:攀登理论高峰(分布式事务与共识)
这是旅途中最艰难、但也最精彩的一段:正面挑战 分布式事务 与 共识。
分布式事务:从理想到实用
- 从理想 到 实用: 看清 2PC 的脆弱性(阻塞、单点、故障恢复复杂等),再转向更工程化的方案:
更重要的是:你会开始用“业务语义”来讨论事务,而不是只讨论“协议名字”。例如:一个环节失败时,是 重试 更合理,还是 补偿 更安全?补偿是否幂等?如何防止重复执行?
共识:拆解 Paxos,深入 Raft
- 共识的皇冠: 拆解晦涩的 Paxos,并深入 Raft 的内核。
- 最硬核的训练方式是什么?用 Go 语言 亲手实现一个迷你版 Raft 共识引擎——因为代码细节会逼你回答所有“看似懂了、其实没懂”的问题。
举个很现实的对比:
- AI 可以帮你写一个 Raft 的
AppendEntries 函数;
- 但它不会替你判断:在你的业务场景下,到底该选 Raft 还是选 Gossip?该偏向一致性还是可用性?如何定义“可接受的失败窗口”?
如果你希望围绕 Go 的并发模型、工程实现与生态组件建立体系化认知,可以把相关话题放到 Go 语言 这个方向持续深入。
第四站:眺望未来(去中心化与实时协作)
当你站在山顶,视野将不再局限于数据中心:
- 剖析 Bluesky 背后的去中心化协议 ATProto:它如何构建下一代去中心化社交网络?
- 探索 CRDTs:看“乐观”的数学魔法如何解决实时协作难题。
这一站的意义在于:你会发现很多“新系统”的本质,仍然离不开前面三站的基本矛盾与基本权衡,只是场景变了、约束变了、目标函数也变了。
为什么在 “Vibe Coding” 时代还要学这些?
既然 AI 已经能帮我们写代码了,为什么还要啃这些硬骨头?
因为 AI 擅长“实现”,但只有你懂“权衡”。
- AI 可以帮你生成 SAGA 的代码模板,但它无法决定:在这个环节失败时,是应该重试还是应该补偿?
- AI 可以给你一套“看起来很对”的中间件组合,但它不会替你承担:一致性下降、链路延迟上升、故障恢复困难、运维成本暴涨的后果。
这些关于 “Why” 和 “Trade-off(权衡)” 的思考,才是系统的 设计哲学。
如果你经常在“高可用/一致性/性能/成本/复杂度”之间纠结,也可以在 技术文档 里补齐系统化的设计笔记与避坑清单,再回到自己的业务里做取舍。
适合谁?
- Go 语言开发者: 想把分布式核心概念和工程实现(尤其是共识)真正吃透。
- 后端工程师: 想跳出 CRUD 的惯性,建立完整的分布式知识体系。
- 架构师预备役: 需要在复杂业务场景下做技术选型,渴望提升架构思维与决策质量。
从哪里开始补齐“组件层”的理解?
当你看到 Redis、Kafka、etcd、TiDB 这类组件时,建议你不要只停留在“会用”。更高效的方式是带着问题去学:
- 它解决的核心矛盾是什么?
- 它为了达成目标牺牲了什么?
- 它最怕的故障模式是什么?恢复路径是什么?
- 在你的业务里,是否会引入新的系统性风险?
围绕常见中间件与数据系统的选型、原理与实战,可以延伸到 数据库/中间件/技术栈 做更全面的对照学习。
以上内容希望能把“分布式系统学习”从散点,变成一条能走通的路线。你也可以在 云栈社区 继续围绕相关主题做体系化沉淀与交流。
 发表于 2026-1-20 19:42:00
|
查看: 192|
回复: 0
发表于 2026-1-20 19:42:00
|
查看: 192|
回复: 0
