过去一年,我的工作习惯被彻底颠覆。这不是简单的效率提升,而是“写代码”这件事的本质发生了变化。
以前我写功能,80%的时间花在修改旧代码上。现在我发现,真正的价值不在于“写”,而在于“如何改”。Cursor让我第一次深刻意识到,AI Coding 的终点不是生成,而是修改。这一点,很多人可能还没完全反应过来。
想象一个熟悉的场景:需求评审后,产品经理说:“这里的逻辑需要微调一下。”你打开代码,开始寻找入口、追踪调用链、修改函数签名、调整测试用例。半小时过去,可能才改了一半。这并非因为你不熟悉代码,而是修改本身就是一个高认知负担的任务。而 Cursor 所做的,本质上就是将“修改代码”提升为一种一等公民的能力。
起初,我也以为是背后的模型变得更强大。但后来越用越觉得不对劲。Cursor 在代码生成能力上,并没有比 Claude 或 GPT 强出太多,但它修改代码的体验就是异常顺畅。顺畅到什么程度?顺畅到你会下意识地相信它“理解”你的项目。后来我深入研究了它的设计,才发现真正的秘诀在于 “search-replace + 投机解码(Speculative Decoding)apply”,而非单纯的代码生成能力。
我们先把 search-replace 这个概念说清楚。传统的 LLM 修改代码,基本流程是:读取一段代码 → 生成新代码 → 开发者手动粘贴替换。Cursor 则不同。它会先在完整的代码仓库中进行结构级搜索,定位所有相关的代码块,然后在原始上下文中进行局部替换。这不是整段代码重写,而是像一位经验丰富的工程师,只精确地改动需要修改的行。
举一个简单的例子。假设你有一个 Python 服务,之前使用的是同步的 requests 库,现在想统一改为 httpx 异步客户端。你在 Cursor 中只需要输入一条指令:
把项目中所有 requests 调用替换为 httpx.AsyncClient,并保持函数签名不变。
Cursor 所做的不是生成一个示例让你参考,而是直接在项目文件中进行修改。效果大致如下:
原代码:
import requests
def fetch_user(uid):
resp = requests.get(f"https://api.example.com/users/{uid}")
return resp.json()
Cursor apply 后:
import httpx
async def fetch_user(uid):
async with httpx.AsyncClient() as client:
resp = await client.get(f"https://api.example.com/users/{uid}")
return resp.json()
关键点不在于修改了这一段代码,而在于:它会将所有相关的调用一次性全部修改,并且不会触及不相关的逻辑。这正是 search-replace 技术成熟后,带来的质变体验。
真正让这个过程变得“顺畅”的,是 Cursor 的 投机解码(Speculative Decoding)apply 机制。简单来说,它不是先生成完整的修改结果再一次性覆盖原文件,而是边预测、边对齐、边应用。每一步操作都会校验是否与当前代码上下文匹配,如果不匹配则回滚重试。因此,你看到的不是一场“推倒重来”的大手术,而是一系列连续、小步、可控的编辑操作。
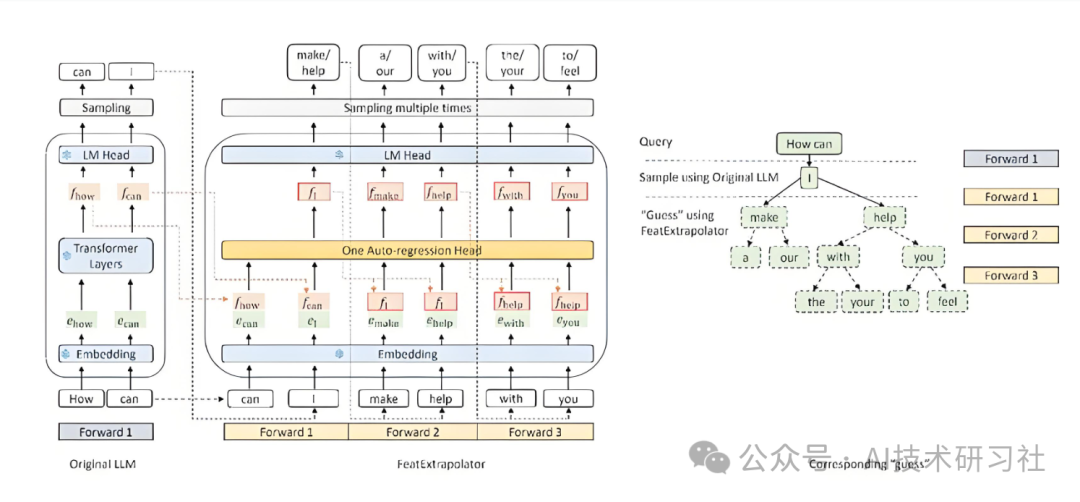
说一句主观的感受:Cursor 更像一个“会写 git diff 的 AI”,而不是一个“只会输出代码块的 AI”。这也是为什么它特别适合处理代码重构、技术栈迁移、统一代码风格这类任务。
说到这里,不得不提一个近期的热点。DeepSeek 最近在 GitHub 上更新了 FlashMLA 内核,在114个文件中,有28处提到了 MODEL1。
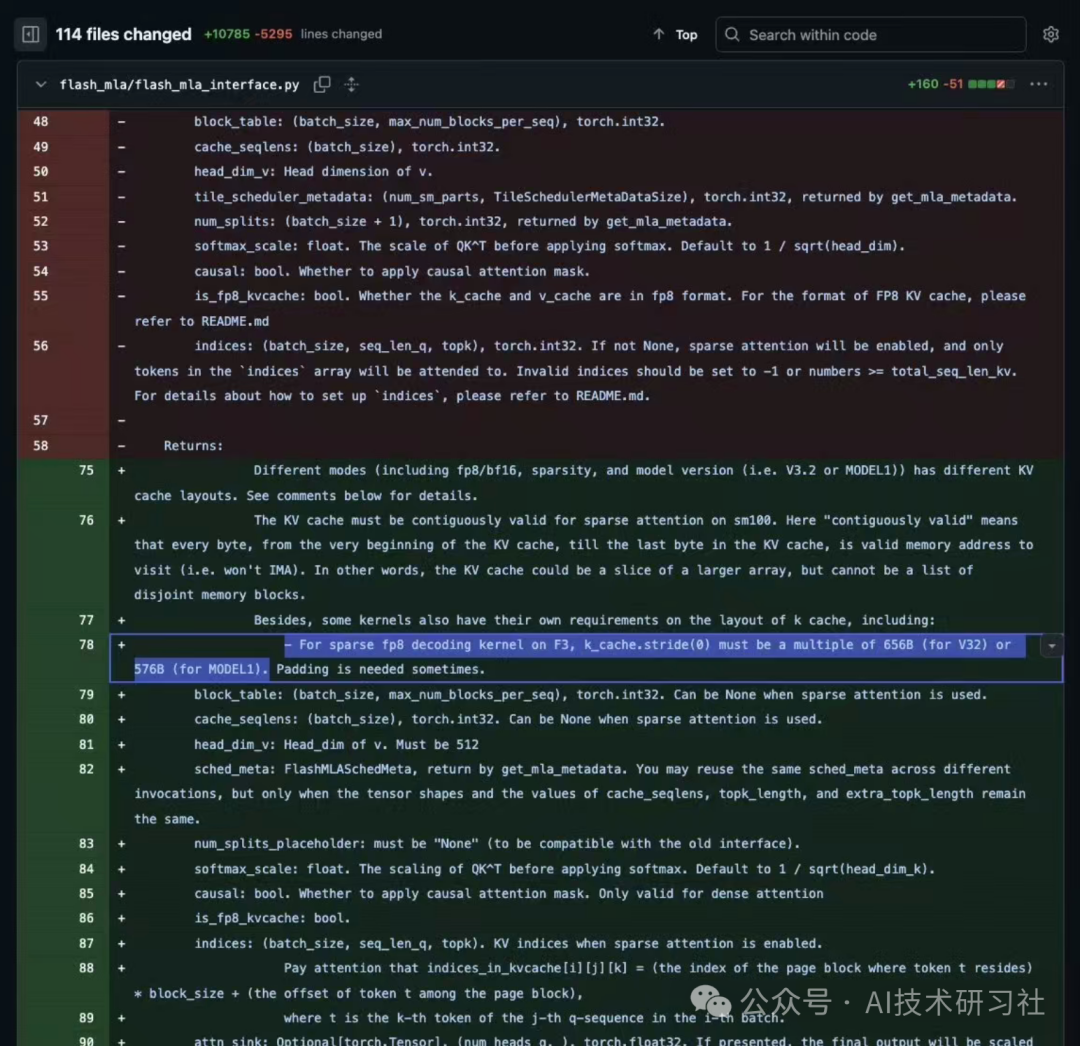
如果你关注过 DeepSeek-R1 的架构,就会明白这很不寻常。这看起来不像是在 V3 架构上打补丁,更像是一个全新架构的前奏。很多人猜测,这可能就是内部代号为 V4 的模型。
为什么在讨论 Cursor 时要提到 DeepSeek?因为我越来越确信一点:下一代大模型的价值,将被 search-replace 这类编辑型工具无限放大。模型能力再强,如果不能“安全、精准地修改现有代码”,其商业价值就会被严重限制。
目前,我在使用 Cursor 时已经形成了一套固定的开发模式,这套模式几乎是为 search-replace 量身定制的:
- 快速学习与建模:通过短问答形式,让 AI 帮我快速学习一个新领域(例如 Web3)。重点不是写代码,而是构建脑内的知识结构和模型。
- 结构化仓库:建立一个 GitHub monorepo,将前端、后端、定时任务、基础设施即代码(如 Terraform)、文档全部放在一起。根目录通常只分为
code 和 docs,并保持结构同构。
- 口述架构:直接在仓库中“口述”我对系统架构的想法,让 Cursor 整理成第一版的架构文档。
- 按业务拆解模块:按业务功能划分模块,而非技术架构。例如,后端不是传统的
controller/service 分层,而是划分为“订单”、“结算”、“风控”等业务模块。
- 文档驱动开发:在
docs 目录中,针对每个模块与 AI 详细讨论其目标、接口设计和数据模式。
每完成一个模块的文档,我就让 Cursor 根据文档生成 code 目录下的实现,并运行最基础的测试。这一步,search-replace 的威力尤为明显,因为文档的任何修改,都可以快速、小步地同步到代码实现中,而非推倒重来。
善于使用 AI 的开发者,其工作往往不是从 0 到 1,而是从 0.9 到 1。
这里必须分享一个我踩过的大坑。我曾经在没有设置任何“安全围栏”的情况下,让 Cursor 直接大规模修改业务逻辑代码。结果很糟糕——虽然主逻辑没错,但许多边界条件被忽略了。当时我甚至想放弃 Agent 模式。后来才想明白,问题不在工具本身,而在于我没有为它设置“刹车系统”。
现在,我所有的项目都会设置三道安全围栏:
- 第一道:Git Hook + 代码格式化工具,确保代码风格一致,避免低级语法错误。
- 第二道:单元测试,覆盖核心业务路径。
- 第三道:代码复杂度检查,限制函数的圈复杂度。
设置好这些围栏后,我才敢让 Cursor 自主地提交代码。只要安全机制健全,AI Agent 就会运行得越来越稳定。
说到并行 Agent,不得不提 Cursor 团队一个“疯狂”的实验。他们利用 GPT-5.2,在 Cursor 环境中编写了一个完整的浏览器,而且是用 Rust 语言实现的,从渲染引擎到 JavaScript 虚拟机全部自研。更夸张的是,这个项目连续运行了一周没有崩溃,数百个 Worker 并发工作,最终产出了上百万行代码。
这件事最重要的启示不是浏览器本身,而是他们采用的模式:由 Planner Agent 拆分任务,Worker Agent 只负责执行,评审 Agent 决定继续推进还是回滚。每一轮迭代结束后,直接清空长期记忆,从一个干净的 master 分支重新开始。这种“流水线式的 AI 工厂”模式,我相信很快会成为行业标配。
单个 Agent 能写出 Demo,多个 Agent 协作才能构建出复杂的系统。
在此,我想提出一个观点:未来淘汰部分工程师的,可能不是 AI 本身,而是“比你更擅长使用 AI 工具的工程师”。
编程这件事,正在从一种体力劳动,转变为一种判断劳动。你的核心价值在于判断“是否需要修改”、“应该修改哪里”以及“修改的结果是否可行”。Cursor 等工具则接手了“具体如何修改”的执行部分。
现在的我,很少再纠结“这段代码是不是我亲手写的”。我更关心的是:系统结构是否合理,演进路径是否顺畅,三个月后是否还能轻松地进行修改。这种心态的转变,起初很难适应,但一旦适应,你会发现自己的视角被提升到了一个新的高度。
文章接近尾声,我想说得更直白一些。DeepSeek 的新模型、Cursor 的 apply 机制、多 Agent 并行协作,这些技术趋势叠加在一起,共同指向一个方向:软件开发的核心,正在从“编写新代码”向“编辑和管理代码的持续演化”转变。
最后,留一个问题供大家思考:
你第一次将核心业务代码交给 AI 进行修改时,内心是充满兴奋,还是感到一丝恐惧?
 发表于 2026-1-22 06:24:36
|
查看: 165|
回复: 0
发表于 2026-1-22 06:24:36
|
查看: 165|
回复: 0
