在项目开发中,我们经常遇到需要将数据同步到其他数据库的场景,例如不同的业务系统需要数据共享,或者将本平台的数据同步到第三方平台。传统的定时任务+接口调用的方式,往往面临实时性差、协调成本高和可靠性低等问题。
传统同步方案的痛点
- 实时性差:通常只能做到分钟级或小时级同步,数据延迟高。
- 协调成本高:需要各部门系统配合开发数据上报接口,沟通协调工作量大。
- 开发工作量大:每个对接部门都需要定制化开发接口,维护成本高。
- 可靠性问题:接口调用失败时数据容易丢失,需要复杂的重试和补偿机制。
为什么选择Flink CDC?
经过实际项目应用,总结出Flink CDC在数据同步方面的核心优势:
1. 同步模式灵活
- 全量同步:支持历史数据一次性迁移,适合初始化场景。
- 增量同步:实时捕获数据变更,保持数据同步状态。
- 混合模式:先全量后增量,无缝切换,业务无感知。
2. 实时性能卓越
- 毫秒级延迟:源表数据的增删改操作,几乎实时同步到目标表。
- 高吞吐量:单任务可处理万级TPS,满足大部分业务场景。
- 资源可控:支持背压机制,自动调节同步速度。
3. 使用门槛低
- 配置驱动:通过SQL配置即可完成同步任务,无需编程。
- 可视化管理:Web界面监控任务状态,运维友好。
需要注意的是,使用Flink CDC的前提条件是确保Flink服务器与源数据库(Oracle)和目标数据库(MySQL)之间具备稳定的网络连通性。
1. Flink环境搭建
1.1 部署模式选择
Flink支持多种部署模式,根据业务场景选择合适的部署方案:
- Standalone模式:适合开发测试和小规模生产环境。
- Yarn模式:适合大数据集群环境,资源管理更灵活。
- Kubernetes模式:适合容器化部署,弹性伸缩能力强。
本次实践采用Standalone独立部署模式,具有部署简单、维护方便的特点。
1.2 安装步骤
- 下载Flink安装包(本文使用
flink-1.19.3-bin-scala_2.12.tgz),下载地址:https://flink.apache.org/downloads/
- 解压并设置环境变量。
- 启动集群。
tar -xzf flink-*.tgz
export FLINK_HOME=/path/flink-*
# 启动集群
cd /path/flink-*
./bin/start-cluster.sh
# 关闭集群
./bin/stop-cluster.sh
如果需要在Web界面查看状态,需要修改安装路径下 /conf/flink-conf.yaml 中的相关配置,然后重启集群。
rest:
# The address to which the REST client will connect to
address: 172.29.236.202
bind-address: 0.0.0.0
# 默认是8081,由于被占用,改成了8082
port: 8082
如果是单机部署且计划运行的任务并发数大于1,需要调整TaskManager的slot数量。slot可以理解为Flink中的执行单元,一个slot可以执行一个任务子任务。配置时可以根据服务器CPU核心数来设定。
同样修改 /conf/flink-conf.yaml:
taskmanager:
# 默认是1
numberOfTaskSlots: 16
memory:
process:
size: 8192m # 默认1728m,建议调大内存,不然数据量过大时容易OOM
启动后,可以通过Web界面(地址:http://Flink服务器IP:8082)查看集群状态。
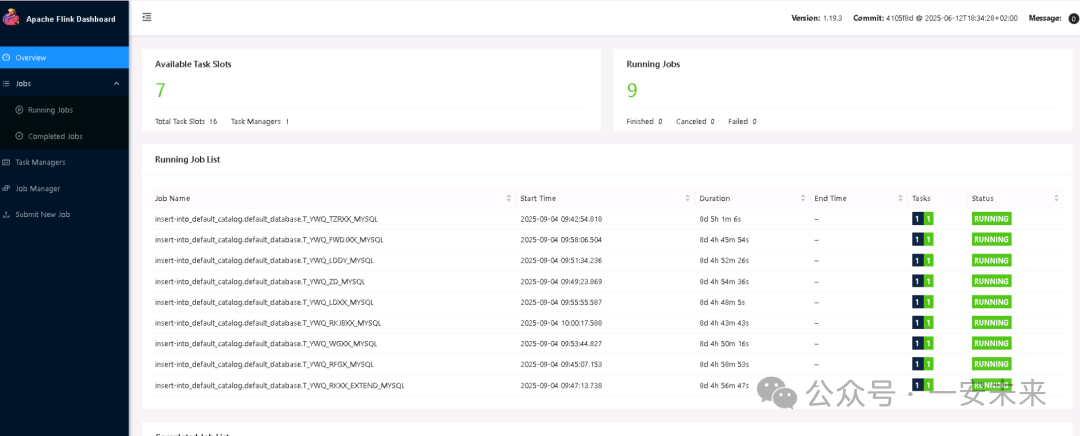
2. 依赖驱动准备
使用Flink CDC之前,需要将必要的连接器JAR包放入Flink安装目录的 /lib/ 文件夹下。根据同步任务所需的源端和目标端数据库不同,所需的驱动包也不同。
本次任务需要将Oracle的数据同步到MySQL,需要准备Oracle CDC连接器和JDBC连接器等相关JAR包。具体依赖信息可在Flink CDC官方文档中查看。
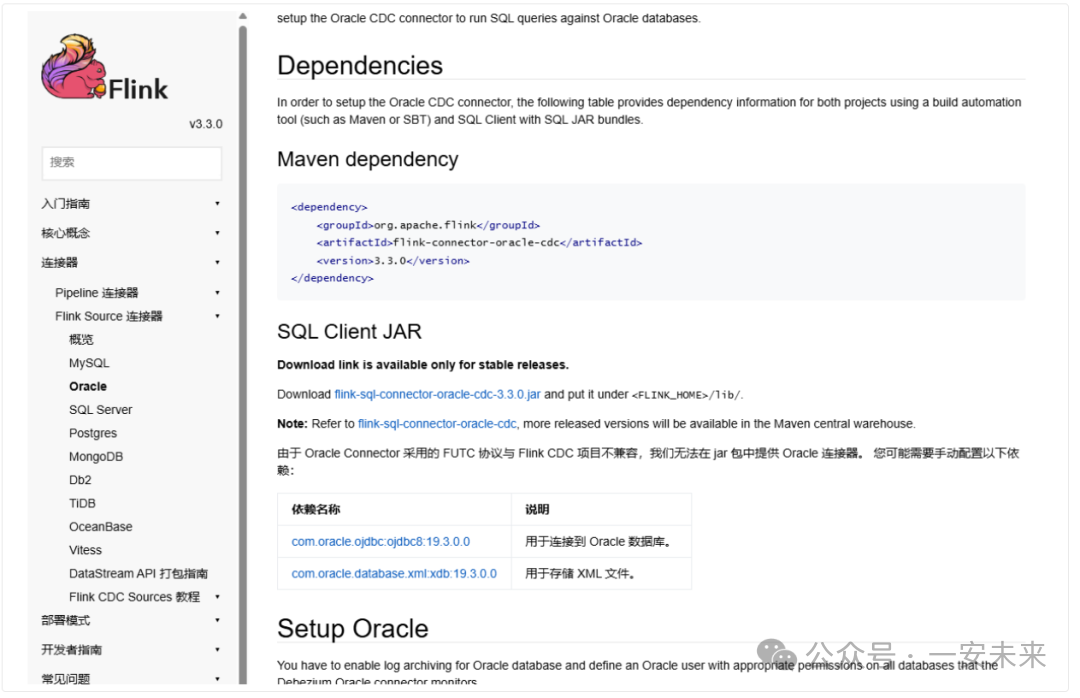
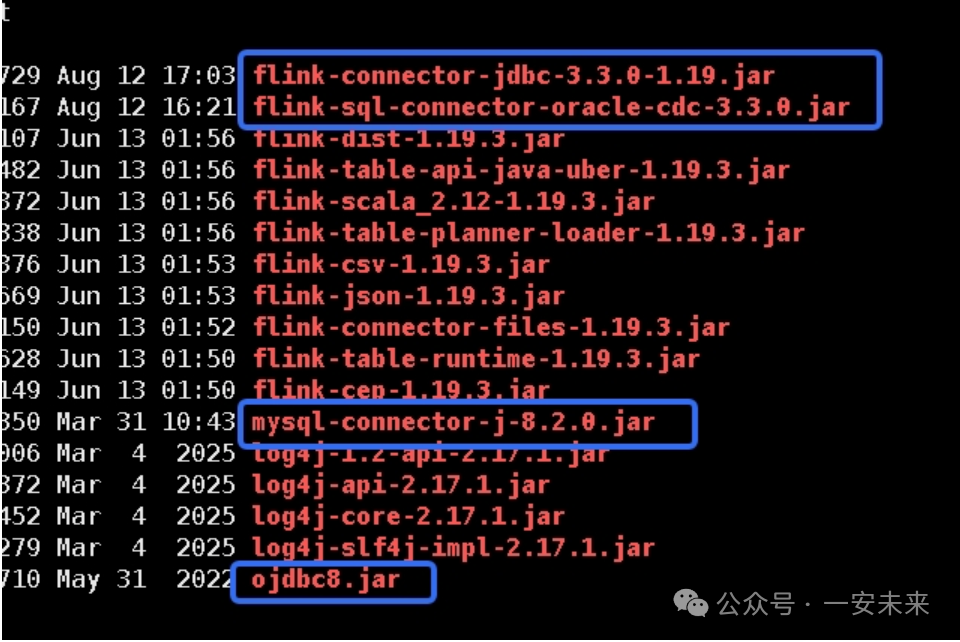
下图列出了本次任务下载并放置到 /lib/ 目录的部分核心JAR包。
3. 数据库环境配置
3.1 数据接收端(MySQL)配置
3.1.1 用户权限配置
出于安全考虑,建议为Flink同步任务创建一个专用的数据库账户,并授予最小必要权限。
-- 创建专用账号(仅限来自 Flink 主机的访问),假设安装flink的机器ip:172.29.236.202
CREATE USER 'flink'@'172.29.236.202' IDENTIFIED BY 'YourPassword';
-- 赋权(按需最小权限,JDBC upsert 需要 SELECT/INSERT/UPDATE/DELETE),假设mysql模式名为flow
GRANT SELECT, INSERT, UPDATE, DELETE ON flow.* TO 'flink'@'172.29.236.202';
FLUSH PRIVILEGES;
-- 验证用户创建结果:
SELECT host, user, plugin FROM mysql.user WHERE user IN ('flink','root');
3.1.2 连接器配置
在Flink SQL中,通过以下语句定义指向MySQL目标表的连接器。
CREATE TABLE TEST_FLINK_OBJECT_MYSQL (
ID STRING NOT NULL,
BANK_DEPOSIT STRING,
NUM int,
NAME STRING,
PRIMARY KEY (ID) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://172.29.230.54:3306/flow?useSSL=false&characterEncoding=utf8',
'driver' = 'com.mysql.cj.jdbc.Driver',
'username' = 'flink',
'password' = 'YourPassword',
'table-name' = 'test_flink_object',
'scan.fetch-size' = ‘500’
);
3.2 数据发送端(Oracle)配置
3.2.1 系统环境准备
以root用户创建必要的目录并设置权限,确保Oracle归档日志可正常写入。
# 创建Oracle用户和组(如果不存在)
sudo adduser oracle
# 创建归档日志目录,确保磁盘空间充足
mkdir -p ‘/u03/oracle/oradata/recovery_area’
chown -R oracle:oinstall ‘/u03/oracle’
chmod 750 ‘/u03/oracle/oradata/recovery_area’
3.2.2 数据库归档配置
使用具有DBA权限的账户登录Oracle,开启归档模式并配置补充日志,这是CDC能够捕获变更的前提。
-- 设置归档路径和大小
alter system set db_recovery_file_dest_size = 10G;
alter system set db_recovery_file_dest = ‘/u03/oracle/oradata/recovery_area’ scope=spfile;
-- 重启数据库并开启归档模式
shutdown immediate;
startup mount;
alter database archivelog;
alter database open;
--查看数据归档模式,应该输出 “Database log mode: Archive Mode”
archive log list;
-- 开启数据库级最小补充日志(必须)
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
-- 开启指定表所有列的补充日志(推荐,确保能捕获所有列变更)
ALTER TABLE 模式名.表名 ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
3.2.3 补充日志说明
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA 是CDC功能的核心配置,其作用是让Oracle在Redo Log中记录更完整的数据变更信息,包括变更前值、变更后值以及主键信息,以便Flink CDC准确解析。
3.2.4 CDC用户创建
创建一个专用于CDC同步的Oracle用户,并授予必要的权限。
CREATE USER flinkuser IDENTIFIED BY flinkpw DEFAULT TABLESPACE USERS QUOTA UNLIMITED ON USERS;
GRANT CREATE SESSION TO flinkuser;
GRANT SET CONTAINER TO flinkuser;
GRANT SELECT ON V_$DATABASE to flinkuser;
GRANT FLASHBACK ANY TABLE TO flinkuser;
GRANT SELECT ANY TABLE TO flinkuser;
GRANT SELECT_CATALOG_ROLE TO flinkuser;
GRANT EXECUTE_CATALOG_ROLE TO flinkuser;
GRANT SELECT ANY TRANSACTION TO flinkuser;
-- 下面这个执行可能报错 不影响(Oracle 版本不支持 LOGMINING 系统权限(11g/12c 没有该权限))
GRANT LOGMINING TO flinkuser;
-- 更多权限...
注意:需要被同步的源表必须定义主键,这是Flink CDC进行增量快照和分片读取的关键依据。
4. 同步任务实现
首先,我们在Oracle中准备一张测试表 TEST_FLINK_OBJECT。
数据同步的Flink SQL脚本主要分为三个部分:定义源表连接器、定义目标表连接器、编写插入语句。
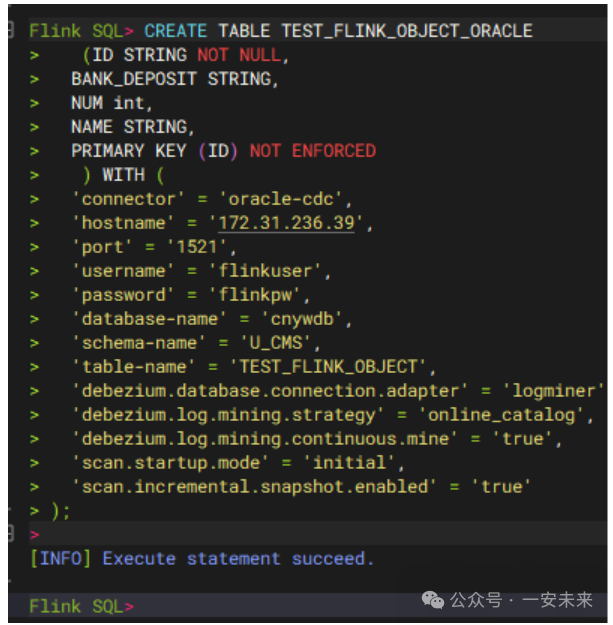
4.1 源表连接器配置 (Oracle CDC)
CREATE TABLE TEST_FLINK_OBJECT_ORACLE
(ID STRING NOT NULL,
BANK_DEPOSIT STRING,
NUM int,
NAME STRING,
PRIMARY KEY (ID) NOT ENFORCED
) WITH (
‘connector’ = ‘oracle-cdc’,
‘hostname’ = ‘172.31.236.39’,
‘port’ = ‘1521’,
‘username’ = ‘flinkuser’,
‘password’ = ‘flinkpw’,
‘database-name’ = ‘cnywdb’,
‘schema-name’ = ‘U_CMS’,
‘table-name’ = ‘TEST_FLINK_OBJECT’, --映射的真实数据库中的表名
‘scan.startup.mode’ = ‘initial’,
‘scan.incremental.snapshot.enabled’ = ‘true’,
-- 这个配置很重要,实践中如果没有显式配置分片键,大数据量时可能OOM
‘scan.incremental.snapshot.chunk.key-column’ = ‘ID’,
‘debezium.database.connection.adapter’ = ‘logminer’,
‘debezium.log.mining.strategy’ = ‘online_catalog’,
‘debezium.log.mining.continuous.mine’ = ‘true’
);
4.2 目标表连接器配置 (MySQL JDBC)
CREATE TABLE TEST_FLINK_OBJECT_MYSQL (
ID STRING NOT NULL,
BANK_DEPOSIT STRING,
NUM int,
NAME STRING,
PRIMARY KEY (ID) NOT ENFORCED
) WITH (
‘connector’ = ‘jdbc’,
‘url’ = ‘jdbc:mysql://172.29.230.54:3306/flow?useSSL=false&characterEncoding=utf8’,
‘driver’ = ‘com.mysql.cj.jdbc.Driver’,
‘username’ = ‘flink’,
‘password’ = ‘Syzxzs@2024’,
‘table-name’ = ‘test_flink_object’,
‘scan.fetch-size’ = ‘500’
);
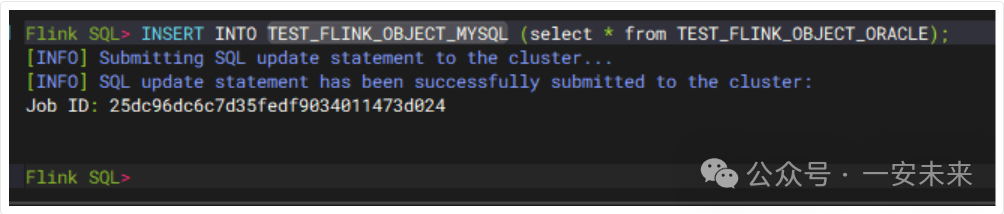
4.3 数据同步任务
INSERT INTO TEST_FLINK_OBJECT_MYSQL (select * from TEST_FLINK_OBJECT_ORACLE);
4.4 任务提交与执行
启动Flink SQL Client,提交上面编写的任务。切换到Flink安装目录的 /bin/ 下,执行 ./sql-client.sh。

在SQL Client中分别执行创建源表和目标表的SQL语句。
最后执行数据插入语句,提交同步任务。
也可以将上述所有SQL语句写在一个文件中(例如 oracle-to-mysql-object.sql),通过命令 ./sql-client.sh -f oracle-to-mysql-object.sql 一次性执行。
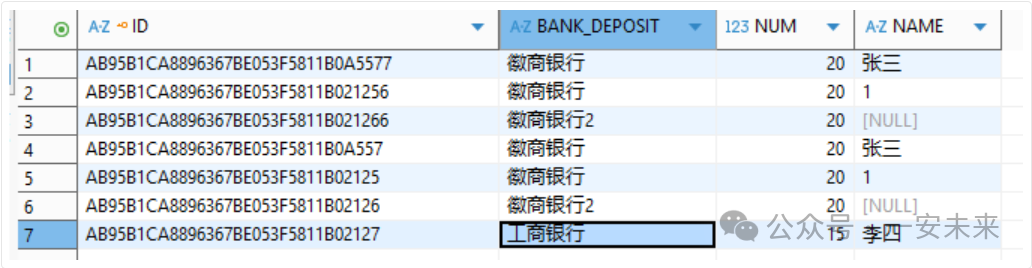
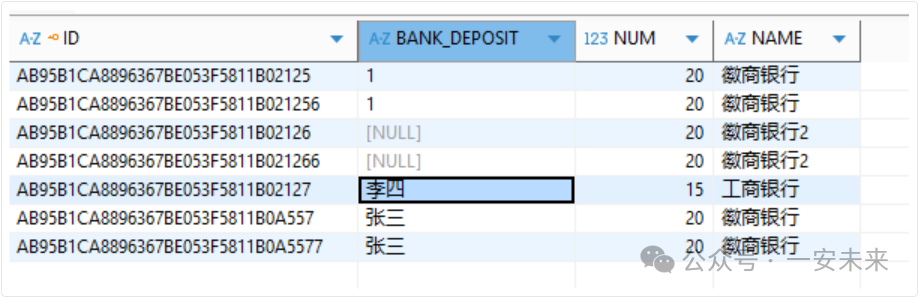
执行成功后,可以在MySQL中查询到同步过来的数据。下图展示了在同步时对字段进行了别名映射(将 BANK_DEPOSIT 和 NAME 字段互换)后的结果。
5. 生产实践经验与踩坑记录
5.1 关键配置优化
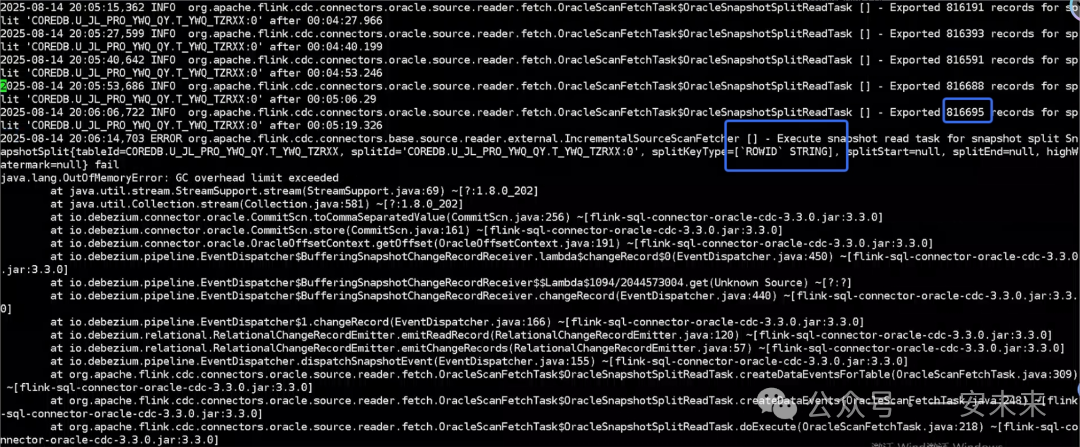
scan.incremental.snapshot.chunk.key-column = ‘ID’:这个配置至关重要。尽管源表有主键,但在实践中发现,必须显式指定此配置来告知Flink CDC使用哪个列进行分片。否则,在大数据量全量同步阶段,Flink可能会使用ROWID等非主键列进行低效分片,导致任务持续读取数据直至内存溢出(OOM)。下图就是未配置该参数时发生OOM的日志截图。
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA:必须开启数据库级别的补充日志。最初我们只开启了表级补充日志,但在配置了主键分片后任务报错,提示需要数据库级日志归档。官方文档也建议同时开启数据库级和表级。
5.2 数据一致性保障
在实践中,我们同步了9张表,总数据量近4千万。发现在初始全量同步及后续增量同步中,偶有极少数据丢失。排查发现丢失的数据本身并无特殊之处,怀疑可能与Oracle 11g版本缺少LOGMINING权限或日志挖掘机制有关。其他数据库(如MySQL、PostgreSQL)的CDC同步则未发现此问题。
建议:在核心数据同步场景中,可以优先采用Flink CDC实现准实时同步。同时,为应对可能存在的极低概率数据不一致问题,应准备一个兜底方案。例如,可以借助AI工具快速生成一个定时对比和补数的脚本,两者结合既能保证实时性,又能确保最终一致性。
参考文档
通过本文的实践指南,你应该能够搭建起一个从Oracle到MySQL的实时数据同步通道。Flink CDC极大地简化了异构数据源同步的复杂度,但在生产部署时,务必关注分片配置、归档日志、内存调优等细节。如果你在实践过程中遇到其他问题,欢迎在云栈社区的大数据板块与大家交流讨论。
 发表于 2026-1-22 09:14:22
|
查看: 300|
回复: 0
发表于 2026-1-22 09:14:22
|
查看: 300|
回复: 0
