现在,大模型可以独立写完整个浏览器了?
Cursor CEO Michael Truell 近期分享了一场引人注目的实验:他们利用 GPT-5.2,让系统连续不间断运行一周,目标是“从零构建”一个可用的 Web 浏览器。据其描述,最终的产出规模惊人:超过 300 万行代码,横跨数千个文件,全部由这套 AI 驱动的编程平台生成。
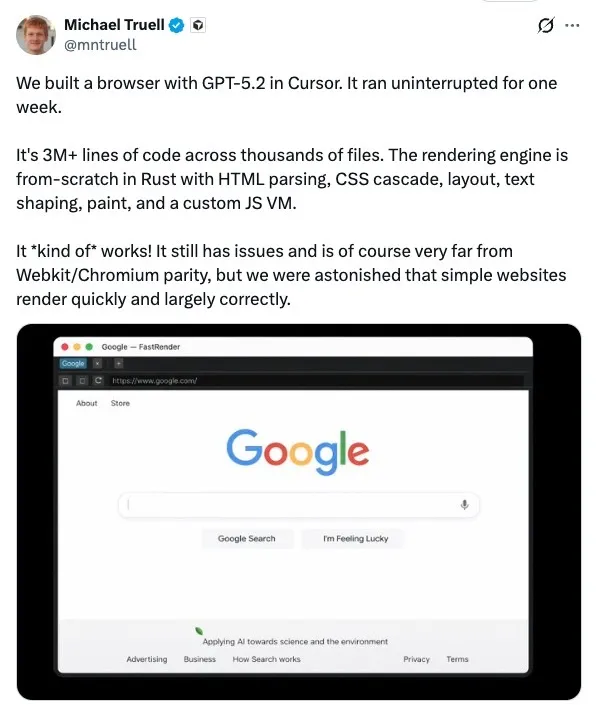
按照他的说法,这个项目并未依赖现成的渲染引擎,而是用 Rust “从零”实现了一整套渲染引擎,其中包括 HTML 解析、CSS 级联、布局计算、文本排版(text shaping)、绘制(paint)流程,甚至还包含一个自定义的 JavaScript 虚拟机。
Truell 也坦言,这个浏览器目前只是“勉强能工作”,距离 WebKit 或 Chromium 等成熟引擎还有巨大差距。但他同时表示团队“感到震惊”,因为一些简单网站在其上渲染得很快,且整体效果大致正确。
数百个Agent如何协同“造轮子”?
与此同时,Cursor 发布了一篇题为《Scaling long-running autonomous coding》的博客文章。文章回顾了让“编程 Agent 连续自主运行数周”的实验,旨在探索在那些通常需要人类团队耗时数月完成的项目中,AI编程能力的边界。
文章重点阐述了多 Agent 协同的挑战:如何在单个项目上同时运行数百个并发 Agent、协调它们的工作,并观察其产出超百万行代码和数万亿 Token 的过程。
Cursor 首先承认了单个 Agent 的局限:任务规模一大、依赖关系一复杂,推进速度就会显著下降。并行化看似是顺理成章的解决方案,但他们很快发现,难点不在于并发,而在于协同。
“学习如何协同:我们最初的方法是让所有 agent 具有同等地位,并通过一个共享文件自行协同。每个 agent 会检查其他 agent 在做什么、认领一个任务并更新自己的状态。为防止两个 agent 抢占同一项任务,我们使用了锁机制。
这一方案在一些有趣的方面失败了:agent 会持有锁太久,或者干脆忘记释放锁。即使锁机制正常工作,它也会成为瓶颈。二十个 agent 的速度会下降到相当于两三个 agent 的有效吞吐量,大部分时间都花在等待上。
系统非常脆弱:agent 可能在持有锁的情况下失败、尝试获取自己已经持有的锁,或者在完全没有获取锁的情况下更新协调文件。
我们尝试用乐观并发控制来替代锁。agent 可以自由读取状态,但如果自上次读取后状态已经发生变化,则写入会失败。这种方式更简单、也更健壮,但更深层的问题依然存在。
在没有层级结构的情况下,agent 变得非常规避风险。它们会回避困难任务,转而做一些小而安全的修改。没有任何一个 agent 承担起解决难题或端到端实现的责任。结果就是工作长时间在空转,却没有实质性进展。”
为了解决这一问题,Cursor 最终引入了更明确的角色分工,搭建了一条职责清晰的流水线:将 Agent 分为规划者(Planners)和执行者(Workers)。
“规划者持续探索代码库并创建任务。他们可以针对特定区域派生子规划者,使规划过程本身也可以并行且递归地展开。
执行者领取任务并专注于把任务完成到底。他们不会与其他执行者协调,也不关心整体大局,只是全力处理自己被分配的任务,完成后再提交变更。
在每个周期结束时,会有一个评审 Agent 判断是否继续,然后下一轮迭代会从干净的初始状态重新开始。这样基本解决了我们的协同问题,并且让我们可以扩展到非常大的项目,而不会让任何单个 Agent 陷入视野过于狭窄的状态。”
在此基础上,Cursor 将这套系统指向了一个更具挑战性的目标:从零构建一个浏览器。他们表示,Agent 持续运行了将近一周,在 1,000 个文件中写出了超过 100 万行代码(与 Michael Truell 所说的300万行有出入),并将源码发布在 GitHub 上供外界检视。
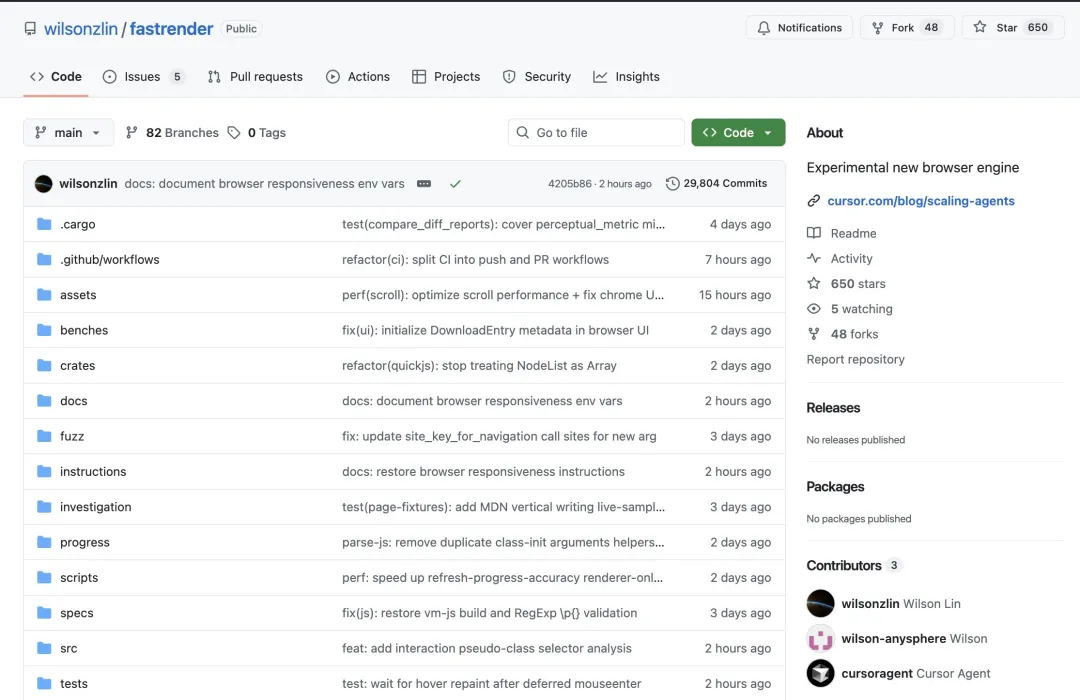
Cursor 进一步宣称:即便代码库规模已经很大,新启动的 agent 仍然能够理解它并取得实质性进展;同时,成百上千个 worker 并发运行,向同一个分支推送代码,而且几乎没有冲突。
一场“全民打假”的开始?
这次实验之所以引发强烈反响,很大程度上是因为:Web 浏览器本身就是软件工程领域公认的“地狱级”项目。

它难的不仅是“写代码”,更是其庞大的工作量、模块间的高耦合度,以及 Web 兼容性这条几乎看不到尽头的长尾。
在相关技术社区的讨论中,有人将开发浏览器类比为开发操作系统。现代浏览器是一个千万级代码量的复杂系统,包含网络栈、多种解析器、渲染流水线、UI框架等众多高复杂度模块,且必须在高性能、高安全性的前提下,跨多个平台运行,并同时兼容数十年前的旧内容和最前沿的现代 Web 应用。
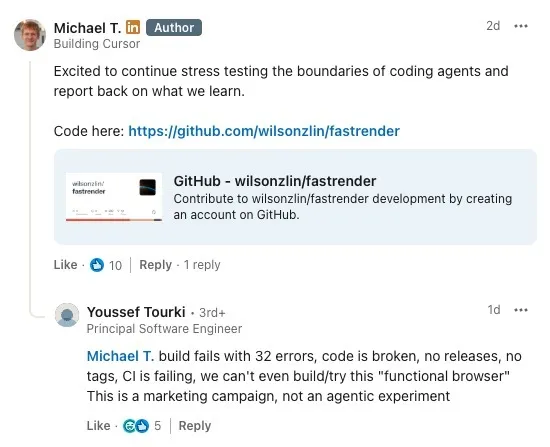
然而,当外界尝试亲自编译这个名为“FastRender”的 开源项目 时,很快意识到:它距离“功能齐全的浏览器”还差得很远,甚至在公开状态下,连最基本的稳定构建都难以通过。
从仓库的公开信息来看,近期主分支的多次 CI(持续集成)运行都以失败告终。不少开发者的独立构建尝试也报告了数十个编译错误。
“构建直接失败,报了 32 个错误,代码本身就是坏的;没有任何 release、没有 tag,CI 也在持续失败,我们甚至连这个所谓‘可用的浏览器’都没法编译、没法试跑。这更像是一场营销活动,而不是一次真正的 agentic 实验。”
有人在 Michael Truell 的社交动态下直接抛出了上述质疑,但未获回复。
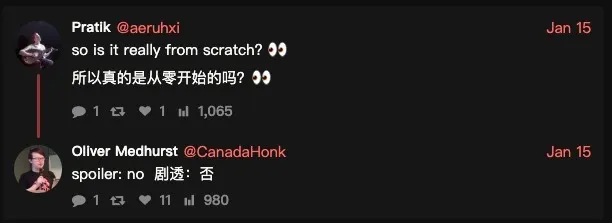
目前,唯一一位在社交平台上明确分享“复现成功”的是前浏览器开发者 Oliver Medhurst。他表示自己花了大约两小时修复编译错误和漏洞,才让项目运行起来。至于性能,他的评价很直接:有些页面加载需要整整一分钟,“不算好”。
一个更核心的追问也随之出现:“所以这真的是从零开始写的吗?”对此,他的回应更像一句反转预告:“剧透:不是。”
更多开发者通过查看仓库的依赖文件(Cargo.toml)发现,这个项目直接引入了 Servo(一个最初由 Mozilla 开发、现由 Igalia 维护的基于 Rust 的浏览器引擎)项目的 HTML 与 CSS 解析器,以及 QuickJS 的 Rust 绑定,并非所有关键组件都是“从零”自行实现。
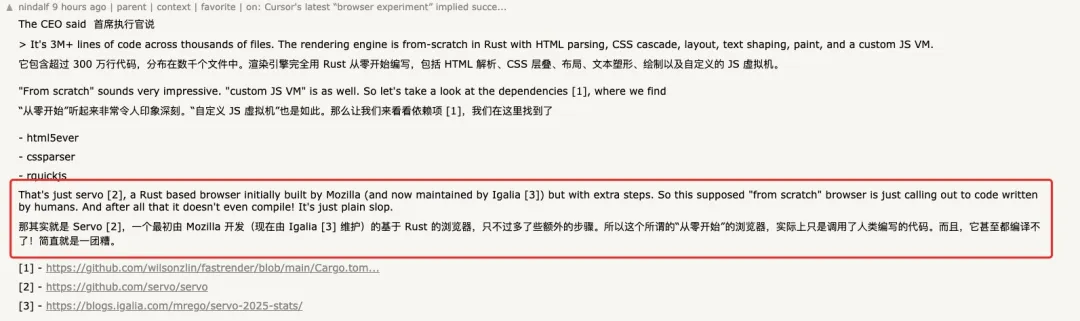
再加上用于 CSS 选择器匹配、SVG 渲染、图形绘制的多个成熟开源库,这个“浏览器实验”更像是巧妙地集成和调用了大量现有的人类编写的代码,而非完全从零开始构建的一整套新引擎。

更引人深思的是,项目中使用的某些依赖版本非常老旧。例如,它使用了发布于 2023 年 6 月的 wgpu 0.17,而当前最新版本已是 0.28。有开发者分析指出,这可能是因为 AI 在编写代码时倾向于直接修改版本管理文件,而不是通过 cargo add 等构建工具来添加依赖,因此容易“幻觉”出训练集中存在的随机旧版本。

这也引发了不少尖锐的批评:
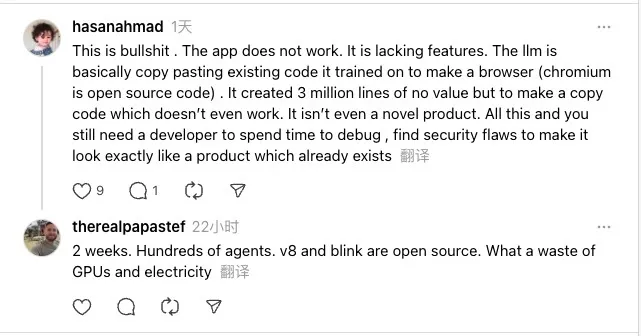
“这简直是胡扯。应用根本跑不起来,功能也缺得厉害。LLM 更像是在把它训练过的现成代码拼起来做个浏览器——毕竟 Chromium 本来就是开源的。最后堆出了 300 万行‘看起来很多’但没有价值的代码,结果还不能用,更谈不上什么新产品。”
“两周时间、数百个 agent,V8 和 Blink 又都是开源的。说到底,这就是在浪费 GPU 和电力。”
最后,这个实验还暴露出一个不容忽视的现实问题:成本。有人指出,Cursor 团队进行的另一个类似实验项目,其 GitHub Actions 累计触发了超过 16 万次工作流运行,但仅成功 247 次——失败的主要原因并非代码错误,而是超出了计算资源的支出上限。
当然,AI Agent 本身并不在乎预算。但在真实的软件工程世界里,可复现的构建、可持续的成本控制、以及可验证的产出质量,才是决定一个系统能否被信任、被维护并最终取得成功的关键。
这场实验无疑展示了AI辅助编程在规模化和自动化上的野心,但同时也揭示了当前技术在处理极端复杂系统、确保工程严谨性以及进行真正创新时所面临的深刻挑战。对于开发者社区而言,它更像是一面镜子,映照出狂热宣传与工程现实之间的差距。想了解更多此类技术前沿的动态与深度讨论,欢迎关注云栈社区。
参考链接:
 发表于 2026-1-24 05:52:59
|
查看: 198|
回复: 0
发表于 2026-1-24 05:52:59
|
查看: 198|
回复: 0
