1. 实时 AI 语音助手整体架构与 Opus 裸流需求
核心结论:在整个实时语音流链路中,Opus 应以「裸流」(raw Opus packets)形式存在,不使用 Ogg 等文件容器封装。
典型的实时 AI 语音助手数据流如下:
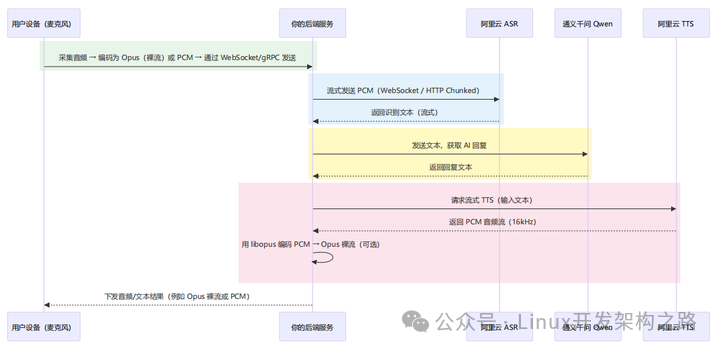
围绕 Opus 的关键约束可以总结为:
Opus 裸流,不要 Ogg 封装
- 编码端(用户设备或 TTS 后端)直接拿编码器输出的
Opus packets,打包进 RTP 或自定义二进制帧。
- 不加 Ogg page header,否则 RTC/自定义协议无法按实时帧语义解析。
ASR 侧只接受 PCM
- 以阿里云实时 ASR 为例:要求输入
PCM(LINEAR16)、16kHz、mono。
- 因此后端必须: Opus 裸流 → 解码 → 需要时重采样到 16kHz → PCM 片段 → WebSocket 发送给 ASR 。
TTS 侧输出 PCM,需要实时编码为 Opus
- 流式 TTS 返回同样是
PCM 片段(通常 16kHz mono)。
- 后端: PCM → Opus 编码(裸包)→ 注入 RTC / WebRTC 音频通道 ,再由 RTC 下发到用户端。
帧长与延迟控制
- 语音助手场景推荐
20ms 帧长:48kHz:每帧 960 samples;16kHz:每帧 320 samples。
- 20ms 帧通常在
延迟 / 压缩效率 / 鲁棒性 之间取得较好平衡,是 ASR/TTS/RTC 的常用配置。
本仓库的 Opus 使用策略(包括 alsa_opus_ws_stub.cpp )正是围绕上述约束来设计的:内部统一采用 48kHz 的 20ms 帧,必要时再通过重采样适配到 ASR/TTS 的 16kHz 要求。
2. “实时 AI 语音助手”的开发框架与分层建议
为了让 Opus 裸流链路在实际项目中易于维护与扩展,推荐按如下分层来设计整体系统:
2.1 端侧 / 客户端层
典型职责:
- 采集麦克风音频(浏览器 / App / SDK)。
- 使用 WebRTC/RTC SDK 编码为 Opus 裸流,通过 RTP 或专有协议推送到云端。
- 播放来自云端的 Opus 流(由 SDK 内部解码)。
与本仓库的关系:
- PC/Linux native 端可以参考 alsa_capture.cpp + Opus 编码逻辑,在推流前完成本地前处理(降噪/AGC/VAD 等)。
2.2 后端接入与音频网关层
典型职责:
- 与阿里云 RTC / WebRTC 网关对接,拉取或接收 Opus 裸流。
- 对接业务侧
WebSocket/gRPC 接口(例如 /asr 、 /assistant )。
- 做基础的鉴权、路由、会话管理。
与本仓库的关系:
- 可在这一层加载“音频处理 SDK”(例如由本仓库编译出的静态库/动态库),将拉取到的 Opus 裸流交给 SDK 解码成 PCM,再送入下游 ASR。
2.3 音频处理与 AI 编排服务层
典型职责:
- Opus 解码 / 编码。
- 重采样、格式转换,统一为 ASR 需要的 16kHz / mono / S16_LE 。
- VAD / AGC / 去回声等音频前处理(可选)。
- 与
ASR / LLM / TTS 做流式交互与编排。
与本仓库的关系:
alsa_opus_ws_stub.cpp 及相关代码可以直接演化为这一层的 “Opus 裸流 → PCM → Opus 裸流” 中间件:
- 上游:来自 RTC/网关的 Opus 包。
- 中游:PCM 形式对接 ASR 和 TTS。
- 下游:再次编码为 Opus,推送回 RTC。
2.4 观测与调试层
建议从一开始就纳入
- 对每一路音频链路记录关键指标:帧 seq、pts、包大小、解码失败率、ASR/LLM/TTS 各段延迟。
- 提供本地 PCM dump(如本示例的 ws_loopback.pcm )便于离线复盘与耳听。
与本仓库的关系:
WebSocketSenderStub::SendAudioFrame() 中打印的 seq/pts/bytes 以及环回写 PCM 的逻辑,就是最小可用的“观测与调试”能力。
在上述整体框架下,alsa_opus_ws_stub.cpp 更像是“音频处理与编解码 SDK 的本地验证样例”:它不关心 RTC/ASR/LLM/TTS 的业务细节,只专注于 ALSA ↔ Opus 裸流 ↔ PCM 这一核心能力链路。
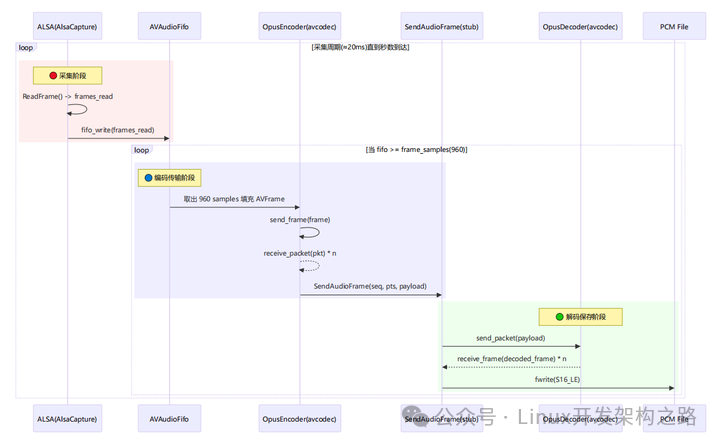
3. alsa_opus_ws_stub.cpp 示例:这个示例解决什么问题?
- 输入:ALSA 采集的 PCM(默认 48kHz / 单声道 / S16_LE、交错 packed)
- 处理:必要时重采样/格式转换 → 以固定帧长喂给 Opus 编码器
- 输出 A(模拟网络发送):每个 AVPacket 的 data/size 作为
Opus payload,在 SendAudioFrame() 打印发送信息
- 输出 B(环回验证):
SendAudioFrame() 内部把 Opus payload 立即解码回音频帧,转为 S16_LE PCM,写入 ws_loopback.pcm
关键特征:
- 不使用 AVFormatContext:不做 Ogg/Matroska 等容器封装,避免把“文件/容器语义”混入“实时传输”示例
- 使用
FFmpeg 的 avcodec 进行 Opus 编码/解码,便于与项目其它 FFmpeg 代码保持一致。
4. 图:整体模块与数据流
4.1 数据流图(Pipeline)

4.2 时序图(谁先做什么)
5. 核心参数与“20ms 帧”策略
5.1 采集侧固定参数(示例里写死)
cap_rate = 48000cap_channels = 1cap_format = SND_PCM_FORMAT_S16_LE
选择 48k 的原因:
- Opus 的内部处理以 48k 为基准(工程上统一到 48k 通常最省事)
5.2 编码帧大小(frame_samples)
程序采用:
frame_samples = enc_ctx->frame_size (若可得)- 否则 fallback:
960
解释:
- 48kHz 下,20ms 对应的采样点数为:$48000 \times 0.02 = 960$
- 20ms 是语音场景最常用的帧长:延迟、压缩效率、鲁棒性折中最好
6. 为什么需要 FIFO(AVAudioFifo)?
ALSA ReadFrame() 返回的帧数( frames_read )通常与 Opus 每帧固定的 frame_samples=960 不一定对齐:
- ALSA 的 period size 可能是 1200 frames(示例日志常见)
- 编码需要 960 frames 才能凑成一帧
所以需要 FIFO 来完成:
- 积累:把 ALSA 读到的不规则大小样本缓存起来
- 切帧:每次从 FIFO 恰好取出 960 samples 组一个编码帧
7. 是否需要重采样/格式转换(SwrContext)?
7.1 编码侧(采集 → 编码器输入)
程序会判断:
- 采集格式是否已满足 encoder 的 sample_fmt / sample_rate / channels
如果不满足,就用 SwrContext 做转换,把采集到的 PCM 变成 encoder 需要的格式后写入 FIFO。
虽然示例优先选择 AV_SAMPLE_FMT_S16 ,但不同 FFmpeg/Opus 编码器配置下仍可能出现格式不一致,因此保留转换逻辑更稳。
7.2 解码侧(解码帧 → 写入 PCM 文件)
解码器输出的 AVFrame 可能是:
- 不同采样率(尽管通常是 48k)
- 不同采样格式(float/planar 等)
为了让落盘 PCM 稳定可播放,示例强制输出:
因此 SendAudioFrame() 内部:
- 用 Opus 解码器得到
decoded_frame
- 初始化/复用
createSwrFromFrameToS16()
swr_convert() 转换后 fwrite() 写入 .pcm
8. 时间戳(PTS)与序号(SEQ)
8.1 PTS 的单位
示例里 pts 采用 “采样点(samples)” 作为单位:
frame->pts = pts; pts += frame->nb_samples;
打印时会换算为毫秒:
pts_ms = pts_samples * 1000 / sample_rate
这符合很多实时语音协议的思路:时间戳以采样点计数最精确,换算方便。
8.2 SEQ 的意义
seq 在每个 Opus payload 发送时递增(每个 packet 一个序号)
真正上 WebSocket 时,通常会把 seq/pts/payload 打包成自定义二进制帧:
- seq:用于乱序检测/丢包统计
- pts:用于播放侧时间线/抖动缓冲对齐
9. “WebSocketSenderStub” 为什么要在 SendAudioFrame() 解码?
这是为了 验证链路,而不是最终产品架构:
- 真实场景:
SendAudioFrame() 应该把 payload 发送到网络;解码发生在对端(云端或客户端)
- 示例场景:为了确认“编码出的 Opus payload 是可解码的”,我们把解码放在发送接口内部做“环回”
优点:
- 不依赖网络/云端
- 出问题时定位更快(编码器参数、帧边界、pts、数据拷贝等)
10. 如何验证结果(推荐步骤)
- 运行示例生成 PCM:
./build/alsa_opus_ws_stub hw:0 ws://127.0.0.1:9000/asr 5 ws_loopback.pcm
- 播放 PCM:
aplay -f S16_LE -r 48000 -c 1 ws_loopback.pcm
如果听到的声音与麦克风输入一致(允许有编码损失),说明:
ALSA 采集正常- 编码器输出 payload 正常
- payload 帧边界正确(每包可独立解码或可顺序解码)
- 解码器参数/重采样/写文件链路正确
11. 扩展:把 Stub 替换为真实 WebSocket(建议的接口形态)
当前 SendAudioFrame() 参数已经接近真实协议需求:
seq :包序号pts_samples :采样点时间戳sample_rate :采样率(用于换算/调试)payload/payload_size :Opus payload
落地真实 WebSocket 时,建议把发送帧结构定义成:
Header(固定长度):
- magic/version
- seq
- pts_samples
- payload_size
- flags(可选:DTX、end-of-stream 等)
Payload: Opus bytes
这样可以非常自然地把本示例替换成真实网络发送端。
12. Opus编解码异常分析参考
对 Opus 来说,最“不能错”的不是那些花里胡哨的调优参数,而是:时钟和格式要严丝合缝。一旦这些错了,轻则听起来怪,重则完全解不出来 / 跟下游对不上时间。
下面按优先级说,前 4 点是 绝对不能错的:
1. 采样率 + time_base + pts 一致
编码器 sample_rate
- Opus 内部“自然采样率”是
48kHz,几乎所有实时语音场景都用 48k。
- 你采集是 48k,就一定要把
enc_ctx->sample_rate 也设成 48k。
time_base 设置 典型写法(你代码里就是):
enc_ctx->time_base = {1, sample_rate};- 这样
pts 的单位就是 “采样点数”。
pts 的计算
- 每编码一帧就加 nb_samples : 第一帧 pts=0 ,第二帧 pts=960 ,第三帧 pts=1920 ……(20ms@48k)。
- 如果你采样率写错、time_base 写错或 pts 递增错了,下游按你给的 sample_rate 去算时间,就会: 音画不同步 / 播放速度不对 / ASR 时间戳对不上。
总结: sample_rate、 time_base、 pts 三个必须是同一套逻辑,错一个就全错。
2. 声道数 / 声道布局(mono/stereo)匹配实际数据
编码器侧:
- 你采集的是单声道,就要:
ff_compat_set_ctx_default_ch_layout(enc_ctx, 1);
- 不能把双声道当单声道 / 单声道当双声道去喂: 会导致左右声道互相串音、音量骤降、甚至解码器认为包有问题。
解码 + 播放 / 写 PCM:
- 下游(比如 ALSA)也要按照你真正输出的声道数来配置: 解码得到 1ch,却用 2ch 设备格式去写,会导致数据量不符或声道内容错位。
总结: channels 写几,就实际喂几;ALSA 播放 / 写 PCM 也要严格对齐。
3. sample_fmt(采样格式)要和你喂进去的 buffer 真正一致
在你的项目里:
- 采集输出是 S16 :
in_fmt = AV_SAMPLE_FMT_S16;
- 编码器能接受的格式可能是:S16 (整型)或 FLTP (浮点 planar)。
- 关键是:
enc_ctx->sample_fmt 要么直接是 AV_SAMPLE_FMT_S16 , 要么先用 swr_convert 把 S16 转成编码器要求的格式再喂。
典型致命错误:
enc_ctx->sample_fmt 写成 FLTP ,但你直接把 S16 buffer 塞给编码器;- 或者
channels > 1 却当成单通道连续 buffer 来填 planar 格式。
- 结果就是:声音完全失真 / 解码失败 / 崩溃。
总结: enc_ctx->sample_fmt + 你填入 AVFrame->data 的实际布局,必须一一对应;不一致就会“花音”甚至崩。
4. 每帧 nb_samples(帧长)要合理,和采样率对应
典型 Opus 帧长(以 48k 为例):
- 2.5ms / 5ms / 10ms / 20ms / 40ms / 60ms
- 你示例里用的是:
frame_size = 960 (20ms@48k)。
必须保证:
- nb_samples 和 sample_rate 配套(例如 20ms → 960@48k / 320@16k);
- pts 递增是“每帧加 nb_samples”。
设错会怎样?
- 设得太奇怪(比如非常小 / 非标准),部分实现会拒绝;
- pts 按错误的 nb_samples 递增,会导致时间线不准。
实战里:固定用 20ms 一帧(960@48k)最安全,低延迟时可以改 10ms,其他尽量别乱搞。
5. 比特率 / application / DTX 这些是“可调优”的,不是绝对不能错
bit_rate
- 典型语音场景:16k~32k mono,你现在用的 32k 很常见。
- 写错只会影响音质/带宽,一般不会“解不出来”。
application(voip / audio / lowdelay)
- 用 voip 做通话/ASR 是合理默认;
- 写成 audio 也不会崩,只是算法调优方向不太一样。
DTX / FEC / VBR/CBR
- 静音不发包(DTX)、前向纠错(FEC)、是否变码率,这些更多影响: 带宽 / 抗丢包 / 编码效率。
- 配错通常不会导致完全失败,只是达不到预期效果。
这些参数是“好坏之分”,前面 1–4 点则是“对错之分”。
6. 解码器侧:保持“诚实”和“一致”
- 多数时候,解码器会从 Opus 流里自己知道声道数 / 内部采样率;
- 你给
dec_ctx->sample_rate / ch_layout 的作用,相当于是“期望输出”, 然后再用 swr 统一成下游(ALSA / PCM 文件)需要的格式。
- 关键不要做的事是: 明明解码输出是 48k,你却告诉下游(播放 / 上层协议)是 16k; 或者把多声道误当单声道来写入/播放。
实际项目里可以怎么自查?
你可以用下面这几个“检查点”扫一遍当前代码和后续改动:
1. 采集参数 vs 编码器参数:
- cap_rate == enc_ctx->sample_rate ?
- cap_channels == 编码器声道数?
- 如不等,中间是否有 swr 做合法转换?
2. time_base / pts :
- time_base={1, sample_rate} ?
- pts 是否按 nb_samples 递增?
3. sample_fmt :
- enc_ctx->sample_fmt 和实际喂进去的 AVFrame->format 、 frame->data 布局一致?
- 若 ALSA 是 S16、编码器要 FLTP,是否有 swr_convert ?
4. 帧长:
- nb_samples 是否对应一个合理的帧长(如 960@48k=20ms)?
希望这份从实战出发的梳理,能帮助你在 云栈社区 等开发者社区分享或实现类似的实时音频项目时,少走弯路,直达核心。构建稳定的音视频底层是富有挑战但极具价值的工作。
 发表于 2026-1-24 05:55:55
|
查看: 239|
回复: 0
发表于 2026-1-24 05:55:55
|
查看: 239|
回复: 0
