本篇是“Android系统底层解析”系列的第六篇。我们已梳理了HMI与视频的显示链路,了解了UI和画面如何最终呈现。那么,另一个关键输出——音频,又是如何从应用层走入我们耳朵的呢?
设想几个常见场景:
- 音乐App播放全景声(7.1.4+),需要精确控制多个扬声器同时输出。
- App1和App2的声音需要合并,通过一路扬声器混合输出。
- App1和App2的声音混合后从喇叭A输出,而App3的声音则独立地从蓝牙音箱(喇叭B)输出。
本文将以 AudioFlinger 为核心枢纽,串联起从声道概念到硬件驱动的完整链路,深入解析Android系统如何基于 AudioFlinger 与 Linux ALSA 架构实现复杂的音频输出机制。
一、基础认知:声道与主流音频编码
要理解音频输出的核心逻辑,首先要掌握“声道”这一基础概念。它是音频数据的“空间维度”,也是实现立体声、环绕声乃至全景声效果的核心载体。
1. 声道的核心定义
声道本质上是独立的音频数据流,每一路声道对应一条物理音频输出通道,并最终通过硬件映射到一个或一组物理扬声器上:
- 单声道(Mono):仅1路音频流,对应单个扬声器,无空间感(如早期收音机、语音播报)。
- 立体声(Stereo):2路音频流(左/右声道),对应左右两个扬声器,实现基础的空间定位感(手机、耳机默认模式)。
- 5.1声道:6路音频流(左前/右前/中置/低音炮/左后/右后),对应6个物理扬声器,是家庭影院和车载音响的主流配置。
- 全景声(7.1.4+):12路及以上音频流(7.1基础声道 + 4个顶部声道),对应空间中的多个方位扬声器,旨在实现“沉浸式三维音效”(即场景1的核心)。
2. 音频编码与PCM的核心转换
所有压缩编码的音频(如MP3、AAC、FLAC及各类全景声编码)都无法直接驱动硬件扬声器。它们必须先转换为PCM(脉冲编码调制)原始数据:
- 编码音频:是对PCM数据的压缩,目的是降低存储或传输体积(例如MP3的压缩比可达10:1)。这是App中存储和网络传输的主要形式。
- PCM数据:是未经压缩的原始音频采样数据,按照“声道数 × 采样率 × 位深”的格式组织(例如7.1.4全景声对应 12声道 × 48kHz采样率 × 16bit位深)。这是
AudioFlinger、ALSA 及硬件CODEC能够识别和处理的唯一数据格式。
二、底层核心:ALSA与硬件CODEC的协作
Android基于Linux内核构建,其音频硬件的底层交互完全依赖ALSA(Advanced Linux Sound Architecture,Android实际使用其轻量级实现tinyALSA)。而硬件CODEC,则是将数字音频数据转换为模拟电信号,最终驱动扬声器的物理执行者。二者协同工作,完成了“逻辑声道”到“物理扬声器”的关键映射。
1. 核心组件定义
(1)什么是ALSA?
ALSA是Linux内核层的音频硬件抽象层,也是用户空间(如AudioFlinger)与各式各样音频驱动/硬件之间的标准化接口。它主要解决了以下问题:
- 屏蔽硬件差异:统一了不同芯片厂商(高通、联发科等)音频驱动的操作接口,上层只需调用标准API即可。
- 管理设备节点:管理如
/dev/snd/pcmC0D0p 这样的音频设备节点,每个节点对应一个物理输入/输出通道。
- 高效数据传输:负责音频数据在用户空间与内核空间之间的搬运,支持
mmap零拷贝、DMA等高性能机制。
(2)什么是硬件CODEC?
CODEC(编解码器)是音频硬件板上的核心芯片,全称“Coder-Decoder”。它在音频输出链路中的核心职责包括:
- 数模转换(DAC):将
ALSA传入的数字PCM数据转换为可以驱动扬声器振动的模拟电信号。
- 模数转换(ADC):(录音时)将麦克风采集的模拟信号转换为数字PCM数据。
- 硬件级声道管理:芯片内部集成了多路独立的音频通道,可以同时驱动多个扬声器,并支持在硬件层面配置声道与扬声器引脚的映射关系。
2. ALSA核心应用接口(tinyALSA)
tinyALSA 是Android对标准ALSA的轻量化实现,其核心API专注于音频设备操作和数据传输,足以适配所有音频输出场景:
| 接口函数 |
核心作用 |
典型使用场景 |
pcm_open() |
打开ALSA PCM设备节点 |
所有音频输出场景 |
pcm_config |
配置PCM参数(声道数/采样率/位深) |
场景1(多声道)/2/3 |
pcm_write() |
向CODEC写入PCM数据(常规方式) |
单路输出(场景1/2) |
pcm_mmap_write() |
内存映射写入(零拷贝) |
高性能场景(全景声/混音) |
pcm_close() |
关闭PCM设备,释放资源 |
所有场景资源释放 |
pcm_get_error() |
获取设备操作错误信息 |
异常排查 |
3. ALSA+CODEC实现声道-喇叭映射的完整流程
声道与物理扬声器的映射是实现全景声等复杂音频输出的核心,该过程由ALSA与硬件CODEC协同完成。如果你想深入了解ALSA与其他网络及系统底层技术的协作,可以访问 云栈社区的网络/系统板块 进行探讨。
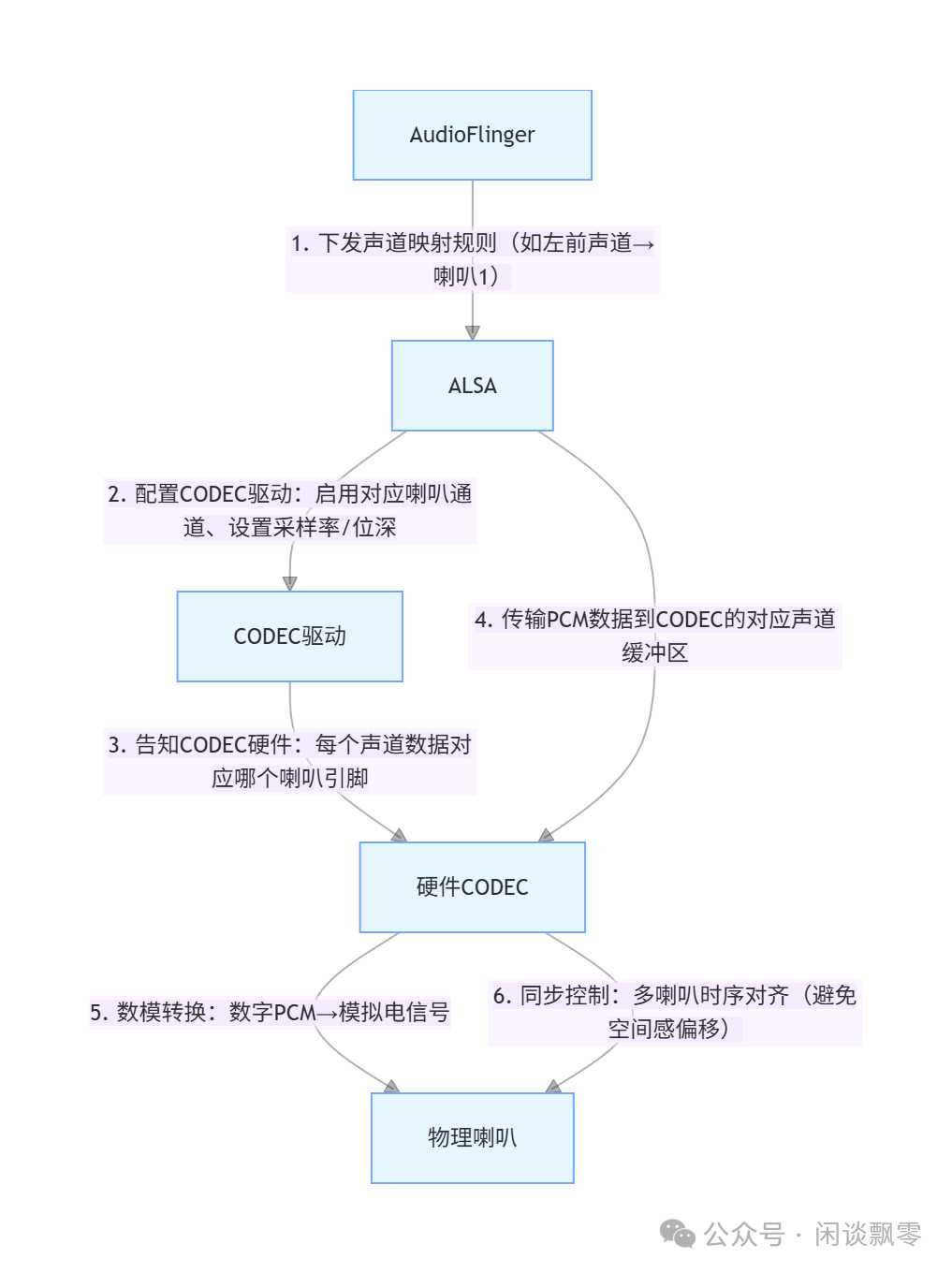
关键细节:
- 映射规则由
AudioFlinger根据音频硬件配置文件(如audio_policy_configuration.xml)和能力制定。
CODEC的硬件多通道是“物理层保障”,支持所有映射的扬声器同时被驱动,无需软件进行分时复用。ALSA负责数据搬运和时序控制,确保多个扬声器能够同步发声,避免声音的空间感错位。
4. ALSA实操Demo:基于设备节点的单路/多路输出
以下Demo基于tinyALSA实现,可在Android的Linux层编译运行(需链接libtinyalsa.so),直观展示了ALSA如何操作CODEC实现音频输出。
(1)单路音频输出(场景2:混音后单喇叭)
#include <tinyalsa/asoundlib.h>
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
// 核心配置:单声道、44.1kHz、16bit
#define CARD 0 // 音频卡编号(Android默认0)
#define DEVICE 0 // 单喇叭对应的设备节点
#define CHANNELS 1 // 单声道
#define RATE 44100 // 采样率
#define PERIOD_SIZE 1024// 单次写入数据量(帧)
#define PERIOD_COUNT 4 // 缓冲区周期数
int main() {
// 1. 配置PCM参数(匹配CODEC硬件能力)
struct pcm_config config = {
.channels = CHANNELS,
.rate = RATE,
.format = PCM_FORMAT_S16_LE, // 16bit小端(Android主流)
.period_size = PERIOD_SIZE,
.period_count = PERIOD_COUNT,
.start_threshold = 0,
.stop_threshold = 0,
.silence_threshold = 0
};
// 2. 打开PCM设备节点(关联CODEC的单声道通道)
struct pcm *pcm = pcm_open(CARD, DEVICE, PCM_OUT, &config);
if (!pcm || !pcm_is_ready(pcm)) {
fprintf(stderr, "ALSA打开失败:%s\n", pcm_get_error(pcm));
return -1;
}
// 3. 生成模拟混音PCM数据(App1+App2叠加)
int16_t *pcm_data = malloc(PERIOD_SIZE * sizeof(int16_t));
for (int i = 0; i < PERIOD_SIZE; i++) {
// 440Hz(App1) + 880Hz(App2) 叠加,降低音量避免爆音
pcm_data[i] = (int16_t)(32767 * 0.4 *
(sin(2 * M_PI * 440 * i / RATE) + 0.3 * sin(2 * M_PI * 880 * i / RATE)));
}
// 4. 写入数据到CODEC(数字→模拟,驱动单喇叭)
int ret = pcm_write(pcm, pcm_data, PERIOD_SIZE * sizeof(int16_t));
if (ret < 0) {
fprintf(stderr, "ALSA写入失败:%s\n", pcm_get_error(pcm));
free(pcm_data);
pcm_close(pcm);
return -1;
}
// 5. 释放资源
free(pcm_data);
pcm_close(pcm);
printf("ALSA单路输出完成\n");
return 0;
}
(2)多路音频输出(场景3:双路喇叭)
#include <tinyalsa/asoundlib.h>
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#define CARD 0
#define DEVICE_SPEAKER 0 // 内置扬声器设备节点(关联CODEC通道1)
#define DEVICE_BT 1 // 蓝牙音箱设备节点(关联CODEC通道2)
#define CHANNELS 1
#define RATE 44100
#define PERIOD_SIZE 1024
// 通用播放函数:向指定设备节点写入音频数据(驱动对应CODEC通道)
int play_to_device(int device_id, const int16_t *data) {
struct pcm_config config = {
.channels = CHANNELS,
.rate = RATE,
.format = PCM_FORMAT_S16_LE,
.period_size = PERIOD_SIZE,
.period_count = 4
};
// 打开指定设备节点(关联CODEC的对应通道)
struct pcm *pcm = pcm_open(CARD, device_id, PCM_OUT, &config);
if (!pcm || !pcm_is_ready(pcm)) {
fprintf(stderr, "设备%d打开失败:%s\n", device_id, pcm_get_error(pcm));
return -1;
}
// 写入数据到CODEC,驱动对应喇叭
int ret = pcm_write(pcm, data, PERIOD_SIZE * sizeof(int16_t));
pcm_close(pcm);
return ret;
}
int main() {
// 1. 生成扬声器数据(App1+App2混音)
int16_t speaker_data[PERIOD_SIZE];
for (int i = 0; i < PERIOD_SIZE; i++) {
speaker_data[i] = (int16_t)(32767 * 0.4 *
(sin(2 * M_PI * 440 * i / RATE) + 0.3 * sin(2 * M_PI * 880 * i / RATE)));
}
// 2. 生成蓝牙音箱数据(App3单独输出)
int16_t bt_data[PERIOD_SIZE];
for (int i = 0; i < PERIOD_SIZE; i++) {
bt_data[i] = (int16_t)(32767 * 0.5 * sin(2 * M_PI * 1000 * i / RATE));
}
// 3. 双路输出:同时驱动两个CODEC通道,对应两个喇叭
play_to_device(DEVICE_SPEAKER, speaker_data);
play_to_device(DEVICE_BT, bt_data);
printf("ALSA多路输出完成\n");
return 0;
}
三、Android系统层:从编码音频到PCM的转换
在 ALSA + CODEC 的底层硬件交互之上,Android系统层完成了将“编码音频”转换为“PCM原始数据”的核心工作。这依赖于 MediaCodec、AudioTrack 和 AudioFlinger 三大组件的精密协作,它们构成了从App到ALSA的关键桥梁。
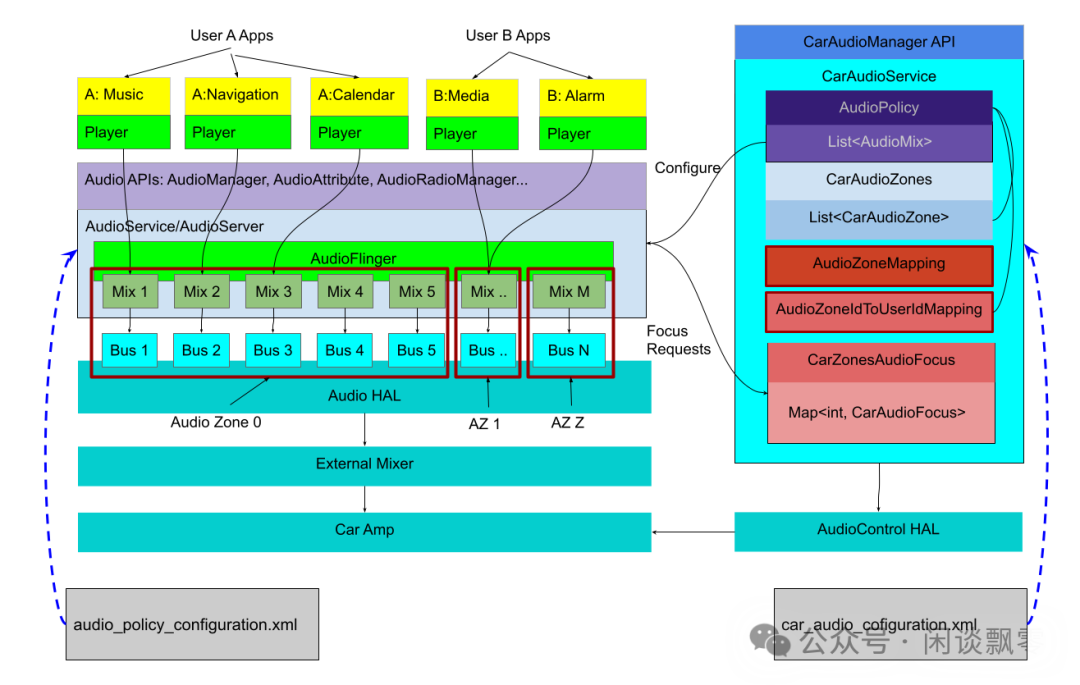
1. 完整转换链路
App(编码音频文件)→ MediaCodec(解码)→ AudioTrack(数据传输)→ AudioFlinger(混音/格式转换)→ ALSA(硬件映射)→ CODEC(数模转换)→ 物理喇叭
2. 核心组件分工
| 组件 |
核心职责 |
| MediaCodec |
音频解码核心:将MP3、AAC、全景声等编码文件解码为PCM原始数据。AudioFlinger本身不具备解码能力。 |
| AudioTrack |
App层音频传输接口:封装PCM数据,并通过匿名共享内存(Ashmem)等机制将数据传递给AudioFlinger。 |
| AudioFlinger |
系统级音频枢纽:接收来自多个App的PCM数据流,完成混音、采样率/位深格式归一化、声道映射、音频路由管理等核心功能。 |
3. 关键优化:零拷贝传输
为了减少数据多次拷贝带来的CPU开销和延迟,Android采用了“匿名共享内存(Ashmem) + mmap内存映射”来实现近似零拷贝的传输:
- App通过
AudioTrack向AudioFlinger申请一块Ashmem共享内存。
MediaCodec解码后的PCM数据直接写入这块共享内存。AudioFlinger无需拷贝,直接读取共享内存中的PCM数据进行混音等处理。- 处理后的PCM数据通过
mmap映射到ALSA驱动的内核缓冲区,避免了用户空间到内核空间的数据拷贝。
- 最后,
CODEC通过DMA(直接内存访问)直接从ALSA内核缓冲区读取数据,整个过程无需CPU参与数据搬运。
四、三大典型场景:全链路实战解析
结合上述基础知识,我们现在可以清晰地拆解文章开头提出的三个典型场景,看看App、AudioFlinger、ALSA、CODEC是如何协同工作的。
场景1:全景声(7.1.4+)多喇叭输出
核心逻辑
App输出全景声编码音频 → MediaCodec解码为12声道PCM → AudioFlinger完成声道映射与路由 → ALSA配置CODEC的12个硬件通道 → 12个(或更多)扬声器同步发声。
(1)App层Demo(Java):全景声PCM传输
这个Demo展示了App如何通过AudioTrack将多声道PCM数据提交给系统。如果你想了解更多关于Android和Kotlin在音频处理方面的实践,云栈社区的Android/iOS板块 有不少相关的讨论和资源。
import android.media.AudioAttributes;
import android.media.AudioFormat;
import android.media.AudioTrack;
import android.os.Build;
public class SurroundSoundDemo {
// 7.1.4全景声参数:12声道、48kHz采样率、16bit位深
private static final int SAMPLE_RATE = 48000;
private static final int CHANNEL_CONFIG = AudioFormat.CHANNEL_OUT_7POINT1_4; // 12声道
private static final int AUDIO_FORMAT = AudioFormat.ENCODING_PCM_16BIT;
private AudioTrack audioTrack;
public void playSurroundSound() {
// 1. 配置音频属性:声明全景声音乐类型
AudioAttributes audioAttributes = new AudioAttributes.Builder()
.setUsage(AudioAttributes.USAGE_MEDIA)
.setContentType(AudioAttributes.CONTENT_TYPE_MUSIC)
.build();
// 2. 配置12声道PCM格式(匹配全景声解码结果)
AudioFormat audioFormat = new AudioFormat.Builder()
.setSampleRate(SAMPLE_RATE)
.setEncoding(AUDIO_FORMAT)
.setChannelMask(CHANNEL_CONFIG)
.build();
// 3. 计算最小缓冲区大小(适配共享内存)
int bufferSize = AudioTrack.getMinBufferSize(
SAMPLE_RATE, CHANNEL_CONFIG, AUDIO_FORMAT);
// 4. 创建AudioTrack:通过Ashmem共享内存传输PCM
audioTrack = new AudioTrack(
audioAttributes,
audioFormat,
bufferSize,
AudioTrack.MODE_STREAM, // 流模式,适合实时音频
AudioTrack.AUDIO_SESSION_ID_GENERATE);
// 5. 生成12声道PCM数据(模拟MediaCodec解码结果)
short[] surroundPcm = generate12ChannelPCM(1024); // 1024帧
// 6. 播放:数据写入共享内存,AudioFlinger直接读取
audioTrack.play();
audioTrack.write(surroundPcm, 0, surroundPcm.length);
// 7. 释放资源(实际需在生命周期中处理)
audioTrack.stop();
audioTrack.release();
}
// 生成12声道PCM数据:每帧包含12个声道的采样值(模拟全景声)
private short[] generate12ChannelPCM(int frameCount) {
int channelCount = 12; // 7.1.4对应12声道
short[] data = new short[frameCount * channelCount];
for (int i = 0; i < frameCount; i++) {
// 不同声道生成不同频率,模拟空间定位
for (int ch = 0; ch < channelCount; ch++) {
double freq = 440 + ch * 100; // 每个声道频率不同
data[i * channelCount + ch] = (short) (32767 * 0.5 * Math.sin(2 * Math.PI * freq * i / SAMPLE_RATE));
}
}
return data;
}
}
(2)AudioFlinger核心逻辑(C++):声道映射
#include <vector>
#include <cmath>
// 7.1.4声道映射表:AudioFlinger将逻辑声道映射到CODEC的物理通道
const int CHANNEL_MAP[12] = {0,1,2,3,4,5,6,7,8,9,10,11}; // 左前→顶右后
// AudioFlinger处理全景声PCM:格式校验+声道映射
std::vector<int16_t> processSurroundPCM(const std::vector<int16_t>& input) {
// 1. 校验输入格式:必须是12声道
if (input.size() % 12 != 0) {
return {};
}
// 2. 声道映射:将逻辑声道数据绑定到CODEC的物理通道
std::vector<int16_t> output = input;
for (int i = 0; i < output.size(); i += 12) {
for (int ch = 0; ch < 12; ch++) {
output[i + ch] = input[i + CHANNEL_MAP[ch]];
}
}
// 3. 格式适配:确保采样率/位深匹配CODEC能力(此处简化)
return output;
}
(3)ALSA+CODEC层:多喇叭输出(C)
#include <tinyalsa/asoundlib.h>
#include <stdio.h>
#include <stdlib.h>
#define CARD 0
#define DEVICE 0
#define CHANNELS 12 // 7.1.4对应12声道(CODEC需支持12通道)
#define RATE 48000
int main() {
// 1. 配置12声道PCM参数(匹配CODEC的多通道能力)
struct pcm_config config = {
.channels = CHANNELS,
.rate = RATE,
.format = PCM_FORMAT_S16_LE,
.period_size = 1024,
.period_count = 4
};
// 2. 打开PCM设备(关联CODEC的12个通道)
struct pcm *pcm = pcm_open(CARD, DEVICE, PCM_OUT, &config);
if (!pcm || !pcm_is_ready(pcm)) {
fprintf(stderr, "全景声设备打开失败:%s\n", pcm_get_error(pcm));
return -1;
}
// 3. 写入AudioFlinger处理后的12声道PCM数据
int16_t *surround_data = malloc(1024 * 12 * sizeof(int16_t));
pcm_write(pcm, surround_data, 1024 * 12 * sizeof(int16_t));
// 4. 释放资源
free(surround_data);
pcm_close(pcm);
return 0;
}
场景2:App1+App2混音→单喇叭输出
核心逻辑
两个App的PCM数据 → AudioFlinger进行格式归一化并混合 → ALSA配置CODEC的单通道 → 单喇叭输出混合后的声音。
关键Demo:AudioFlinger混音逻辑(C++)
PCM数据的混合涉及采样、量化等基础概念,这属于计算机科学的基石。对这类底层原理感兴趣的朋友,可以在 云栈社区的计算机基础板块 找到更多延伸阅读。
#include <vector>
#include <algorithm>
#define MAX_AMPLITUDE 32767 // 16bit PCM最大值(避免爆音)
// AudioFlinger混音核心:两路PCM叠加,按音量比例混合
std::vector<int16_t> mixAudio(const std::vector<int16_t>& app1_pcm, float app1_vol,
const std::vector<int16_t>& app2_pcm, float app2_vol) {
// 1. 格式归一化:确保两路数据长度一致(实际还会做采样率/位深适配)
int frame_count = std::min(app1_pcm.size(), app2_pcm.size());
std::vector<int16_t> mix_pcm(frame_count);
// 2. 混音计算:先转int32避免溢出,叠加后限幅
for (int i = 0; i < frame_count; i++) {
int32_t mix_value = (int32_t)(app1_pcm[i] * app1_vol) + (int32_t)(app2_pcm[i] * app2_vol);
// 限幅:防止超出16bit范围导致爆音
mix_value = std::clamp(mix_value, (int32_t)-MAX_AMPLITUDE, (int32_t)MAX_AMPLITUDE);
mix_pcm[i] = (int16_t)mix_value;
}
return mix_pcm;
}
场景3:App1+App2混音(喇叭A)+ App3单独输出(喇叭B)
核心逻辑
AudioFlinger创建并管理两路独立的音频流:
- 流1:接收App1和App2的PCM数据,混合后,路由到“喇叭A”对应的
ALSA设备节点。
- 流2:接收App3的PCM数据,直接路由到“喇叭B”(如蓝牙音箱)对应的
ALSA设备节点。
ALSA层同时驱动两个CODEC通道(或不同音频设备),实现两路音频的独立、并发输出。
App层关键逻辑(Java):指定输出设备
import android.media.AudioAttributes;
import android.media.AudioDeviceInfo;
import android.media.AudioFormat;
import android.media.AudioManager;
import android.media.AudioTrack;
public class MultiOutputDemo {
private AudioManager audioManager;
public MultiOutputDemo(AudioManager audioManager) {
this.audioManager = audioManager;
}
// App3单独输出到蓝牙音箱(喇叭B)
public void playApp3ToBluetooth() {
// 1. 获取蓝牙音箱的设备ID(匹配ALSA设备节点)
int bluetooth_device_id = -1;
AudioDeviceInfo[] devices = audioManager.getDevices(AudioManager.GET_DEVICES_OUTPUTS);
for (AudioDeviceInfo device : devices) {
if (device.getType() == AudioDeviceInfo.TYPE_BLUETOOTH_A2DP) {
bluetooth_device_id = device.getId();
break;
}
}
if (bluetooth_device_id == -1) {
return;
}
// 2. 配置AudioAttributes:绑定到蓝牙音箱
AudioAttributes attrs = new AudioAttributes.Builder()
.setDeviceId(bluetooth_device_id) // 指定输出设备
.setUsage(AudioAttributes.USAGE_NAVIGATION_GUIDANCE)
.setContentType(AudioAttributes.CONTENT_TYPE_SPEECH)
.build();
// 3. 配置PCM格式(单声道、44.1kHz、16bit)
AudioFormat format = new AudioFormat.Builder()
.setSampleRate(44100)
.setEncoding(AudioFormat.ENCODING_PCM_16BIT)
.setChannelMask(AudioFormat.CHANNEL_OUT_MONO)
.build();
// 4. 创建AudioTrack并播放(数据写入共享内存,AudioFlinger直接读取)
int buffer_size = AudioTrack.getMinBufferSize(44100, AudioFormat.CHANNEL_OUT_MONO, AudioFormat.ENCODING_PCM_16BIT);
AudioTrack track = new AudioTrack(attrs, format, buffer_size, AudioTrack.MODE_STREAM, AudioTrack.AUDIO_SESSION_ID_GENERATE);
short[] app3_pcm = generateSineWave(1000, 1024); // 生成App3的PCM数据
track.play();
track.write(app3_pcm, 0, app3_pcm.length);
// 5. 释放资源
track.stop();
track.release();
}
// 生成指定频率的单声道PCM数据
private short[] generateSineWave(int freq, int frameCount) {
short[] data = new short[frameCount];
for (int i = 0; i < frameCount; i++) {
data[i] = (short) (32767 * 0.5 * Math.sin(2 * Math.PI * freq * i / 44100));
}
return data;
}
}
五、总结
Android音频输出机制的核心设计哲学是“分层解耦”与“高效传输”。整个链路环环相扣,我们可以将其关键要点总结如下:
- 核心链路:编码音频经
MediaCodec解码为PCM,通过AudioTrack利用共享内存传输给AudioFlinger,经混音、格式转换、路由后,由ALSA映射到CODEC的物理通道,最终驱动扬声器。
- AudioFlinger角色:作为系统级的音频枢纽,它负责混音、格式归一化、声道映射及多路音频流的管理,是连接上层App与底层硬件的核心桥梁。
- ALSA+CODEC角色:
ALSA提供了标准化的硬件操作接口,而CODEC则完成了数模转换和硬件级的声道管理。二者协同,实现了“逻辑音频流”到“物理声音”的最终映射。
- 性能优化:通过Ashmem共享内存和
mmap映射技术实现的零拷贝传输,极大地降低了CPU在数据搬运上的开销,为全景声、多App混音等高复杂度、高性能的音频场景提供了保障。
从App中的一段编码音频文件,到最终传入我们耳朵的真实声音,本质上是一个“压缩数据 → 原始数据 → 硬件驱动”的层层转换与接力过程。AudioFlinger与ALSA、CODEC的精密协作,正是Android系统能够灵活、高效地应对各种复杂音频输出场景的核心保障。希望这篇深入Android音频栈的解析,能帮助你更好地理解这一过程。更多深入的技术讨论,欢迎前往云栈社区与广大开发者交流。
 发表于 2026-2-28 16:45:18
|
查看: 299|
回复: 0
发表于 2026-2-28 16:45:18
|
查看: 299|
回复: 0
