引用说明
原文链接: https://www.recall.ai/blog/postgres-postmaster-does-not-scale
作者: Elliot Levin
在 Recall.ai,我们运行着一个颇具挑战性的工作负载:每周录制数百万场会议。我们向视频会议中派驻机器人,帮助客户自动化处理从会议记录、更新 CRM 到实时反馈等一系列任务。
人们常问我们如何处理 TB 级别的实时媒体流,但会议还有一个常被忽略的特性——其惊人的同步性。大多数会议都在整点开始,部分在半点,这种模式对我们整个媒体处理基础设施产生了连锁反应。
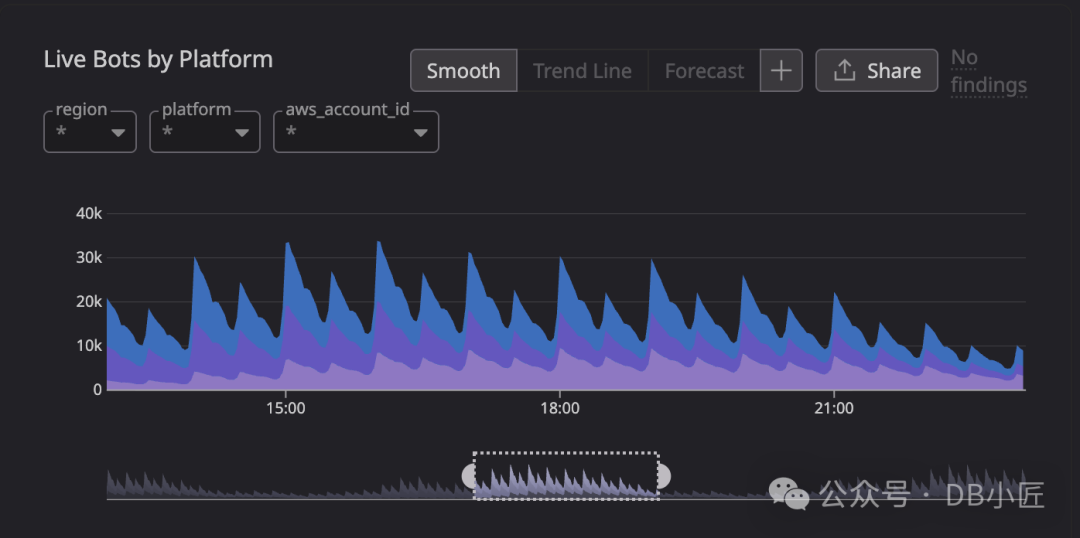
上图展示了我们的负载模式,Y 轴是 EC2 实例数量。那些巨大的峰值就是我们需要捕获的“会议爆发”。会议开始时,计算资源必须就位以处理涌入的数据,否则数据将永久丢失。
这种极端的峰值梯度,让我们在技术栈的各个层面——从 ARP 到 AWS——都遇到了瓶颈。接下来要讲的,就是一个棘手且隐蔽的问题,它迫使我们再次深入 PostgreSQL 内部,揭示了一个在极高规模下才会显现、且常被忽视的性能瓶颈。
TL;DR
每个 PostgreSQL 服务器的起点和终点都是 postmaster 进程。它负责创建和回收子进程,以处理连接和并行工作进程等任务。
Postmaster 运行着一个单线程的主循环。在高工作进程流失率下,这个循环会占满整个 CPU 核心,从而拖慢连接建立、并行查询、信号处理等操作。
这导致了一个罕见且难以调试的问题:我们的一些 EC2 实例会延迟 10-15 秒,只为了等待 postmaster fork 出一个新的后端进程来处理连接。
PostgreSQL 连接为何变慢?
几个月前,我们收到了大量关于 EC2 实例启动延迟的告警。调查发现,实例其实已就绪,只是在等待。
我们最初怀疑是慢查询,但排除了这个可能。最终,我们发现延迟的根源在于建立 PostgreSQL 连接所需的时间变长了。
PostgreSQL 使用自己的二进制通信协议。客户端发送启动消息,服务器响应认证请求。
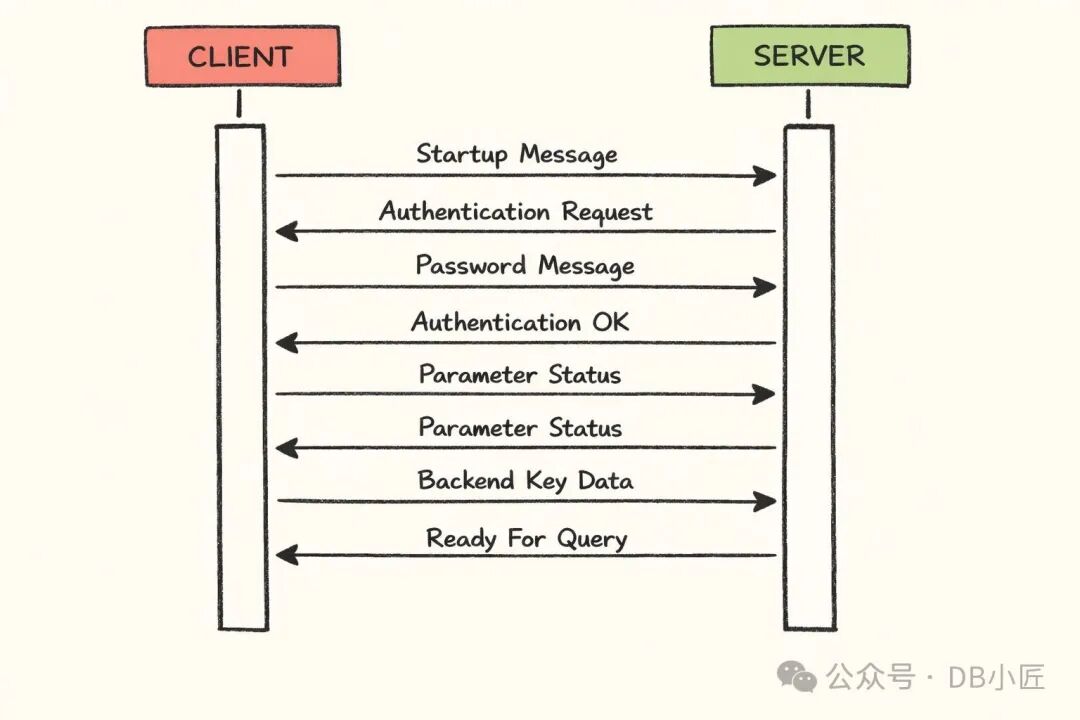
我们观察到的现象非常诡异:客户端成功建立了到 PostgreSQL 的 TCP 连接,但启动消息在 10 秒后才收到响应。
以下是我们在网络抓包中看到的示例:
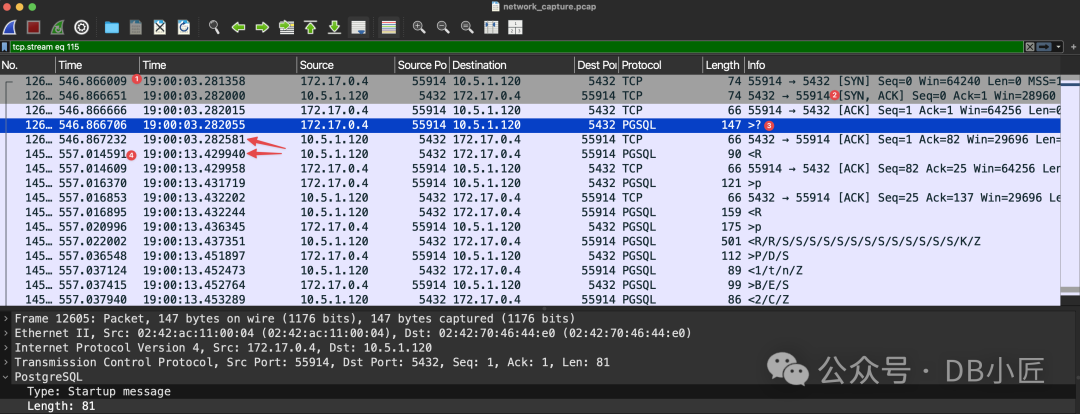
- 客户端发送初始 TCP SYN 包。
- 不到一毫秒,服务器响应 SYN, ACK,客户端 ACK 完成三次握手。
- 客户端向 PostgreSQL 服务器发送启动消息,服务器 ACK 该消息。
- 10 秒后,服务器才响应认证请求,此后连接流程恢复正常。
我们排除了 CPU、内存、磁盘 I/O、网络 I/O 等明显的资源瓶颈。既然所有指标看起来都正常,我们不得不转向对 PostgreSQL 内部的更深层检查。
搭建复现环境
我们注意到延迟只发生在最大负载峰值期间,即数千个 EC2 实例同时启动时。棘手的是,这似乎是偶发性的,可能每周只出现一两次。
我们的生产数据库托管在 RDS PostgreSQL 上,这限制了我们对底层系统的观测能力。因此,我们创建了一个模拟生产环境的复现环境来继续调查。
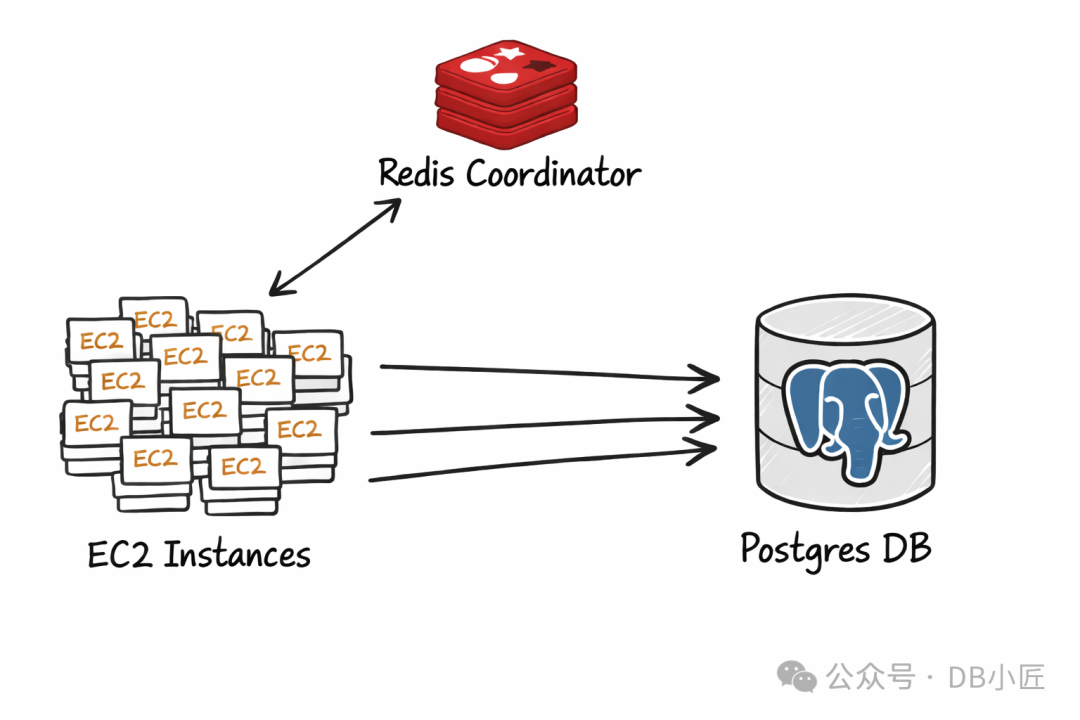
在这个环境中,我们使用 Redis 的发布/订阅功能,从 3000+ 个 EC2 实例触发高度同步的 PostgreSQL 连接请求。由于我们在自己的 EC2 实例上安装了 PostgreSQL,因此可以在复现延迟时对其进行全方位监测。
深入 Postmaster 内部
下一步是形成一个可验证的假设。为此,我们仔细研究了 PostgreSQL 的源代码。
每个 PostgreSQL 实例都有一个监督进程,负责创建和回收新的后端进程和工作进程。这个进程就是 postmaster。
Postmaster 被设计为单线程服务器循环,同步处理所有事件:
- ServerLoop
maybe_start_bgworkerpostmaster_child_launchfork_process
StartBackgroundWorkerBackendStartup
fork_processpostmaster_child_launch
- ChildReaper: 回收已退出的子进程(工作进程、后端进程等)
- AcceptConnection: 启动新后端进程来处理连接
- LaunchBackgroundWorkers: 为并行查询启动后台工作进程
我们的假设是:爆发的连接请求会暂时压垮 postmaster 的主循环,导致它在处理传入的连接队列时严重滞后。
性能剖析
为了验证假设,我们在模拟环境中,于连接峰值期间对 postmaster 进程进行了性能剖析。让 postmaster 进程陷入饱和状态出乎意料地容易。
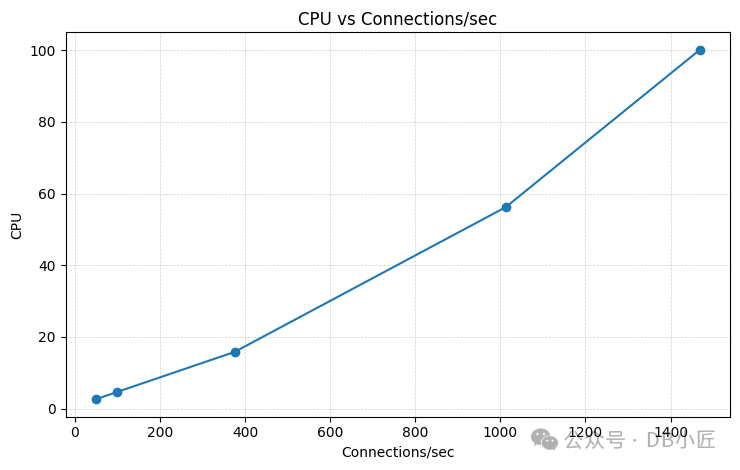
我们在 r8g.8xlarge 实例上运行 PostgreSQL。当连接速率达到约 1400 次/秒时,postmaster 主循环的 CPU 使用率达到饱和,并开始出现明显的延迟。
使用 perf 工具,我们在 postmaster 承受压力时对其进行了采样分析。
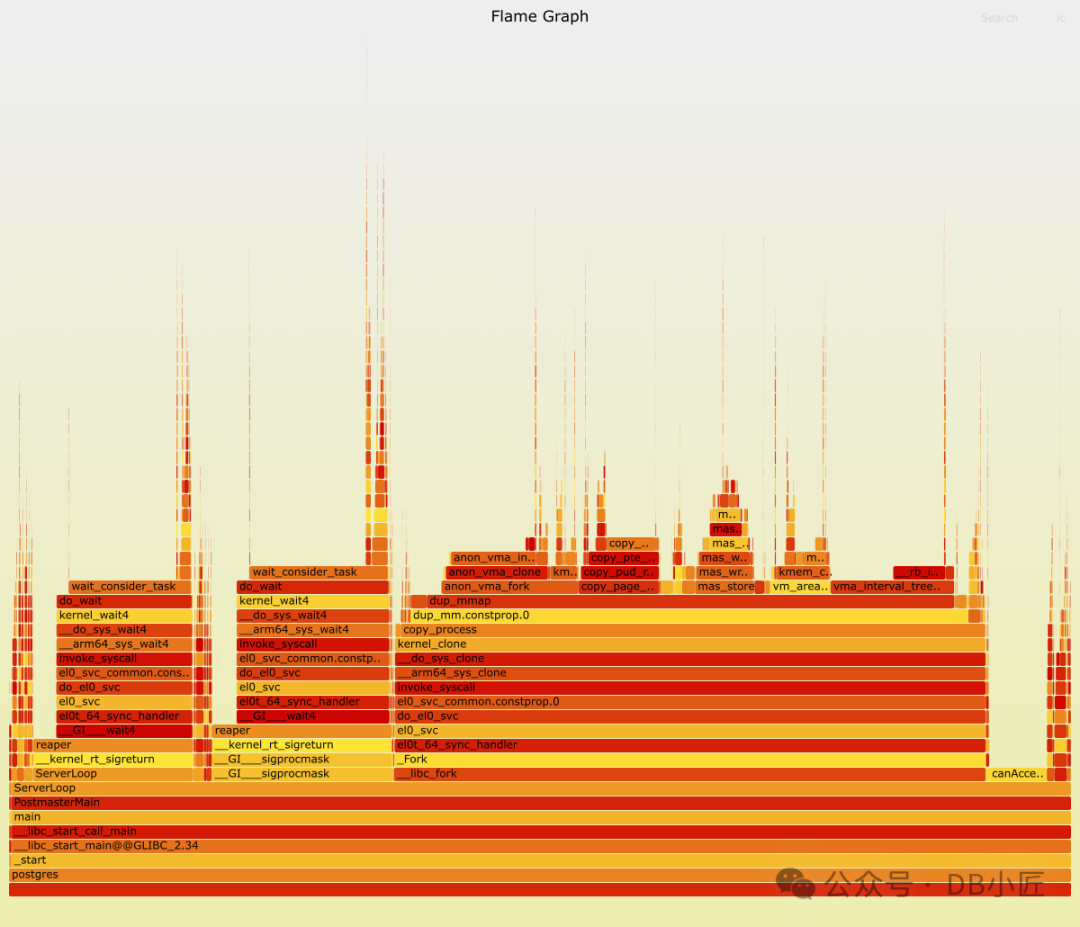
正如预期,绝大多数时间都花在了创建和回收后端进程上。事实证明,fork 系统调用的开销可能非常大!
Huge Pages (大页内存) 的妙用
简单回顾一下 Linux 上 fork 的工作原理。当你调用 fork 时,它会创建一个新的“子”进程,作为父进程的精确副本,并从父进程停止的指令处继续执行。
然而,对于 fork 的典型用法,复制父进程的所有内存页将极其昂贵。因此 Linux 使用了一个巧妙的优化:写时复制(Copy-on-Write, CoW)。这意味着只有在子进程尝试修改父进程的某个内存页时,才会真正复制该页。
但这里有个问题:Linux 仍然需要复制父进程的页表条目(PTEs)。减少 PTE 的数量可以显著降低 fork 进程的开销。
在 Linux 上,这很容易实现。你可以通过 echo $NUM_PAGES | sudo tee /proc/sys/vm/nr_hugepages 在内核中启用 Huge Pages,并配置 PostgreSQL 使用它们。
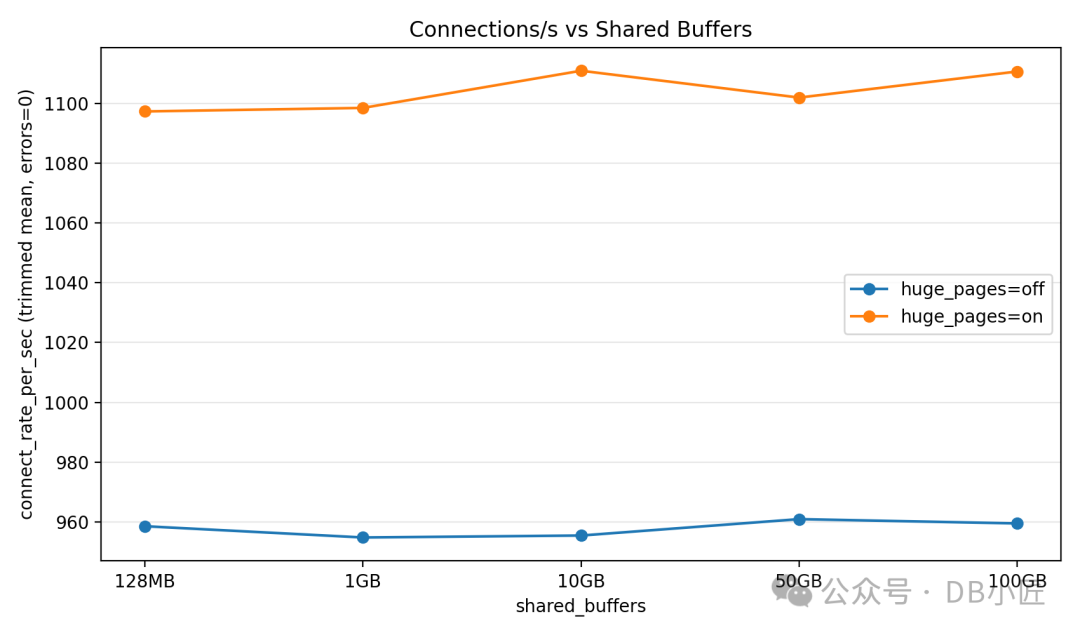
启用 Huge Pages 会大幅减少 postmaster 进程的 PTE 大小。根据我们的经验,启用 huge_pages = on 后,连接速率吞吐量提升了约 20%。
后台工作进程的额外压力
更复杂的是,postmaster 还负责为并行查询启动后台工作进程。高速率的并行查询会进一步给 postmaster 的主循环增加压力。
CREATE OR REPLACE FUNCTION bg_worker_churn(iterations integer)
RETURNS void
LANGUAGE plpgsql
AS $function$
DECLARE
i int;
BEGIN
PERFORM set_config('force_parallel_mode', 'on', true);
PERFORM set_config('parallel_setup_cost','0', true);
PERFORM set_config('parallel_tuple_cost','0', true);
PERFORM set_config('min_parallel_table_scan_size','0', true);
PERFORM set_config('min_parallel_index_scan_size','0', true);
PERFORM set_config('enable_indexscan','off', true);
PERFORM set_config('enable_bitmapscan','off', true);
PERFORM set_config('parallel_leader_participation','off', true);
PERFORM set_config('max_parallel_workers','512', true);
PERFORM set_config('max_parallel_workers_per_gather','128', true);
CREATE TABLE data (id BIGINT);
INSERT INTO data SELECT generate_series(0, 100000);
ANALYZE data;
FOR i IN 1..iterations LOOP
PERFORM sum(id) FROM data;
END LOOP;
DROP TABLE data;
END;
$function$;
高频率的后台工作进程创建与销毁,同样会对 postmaster 主循环施加压力。
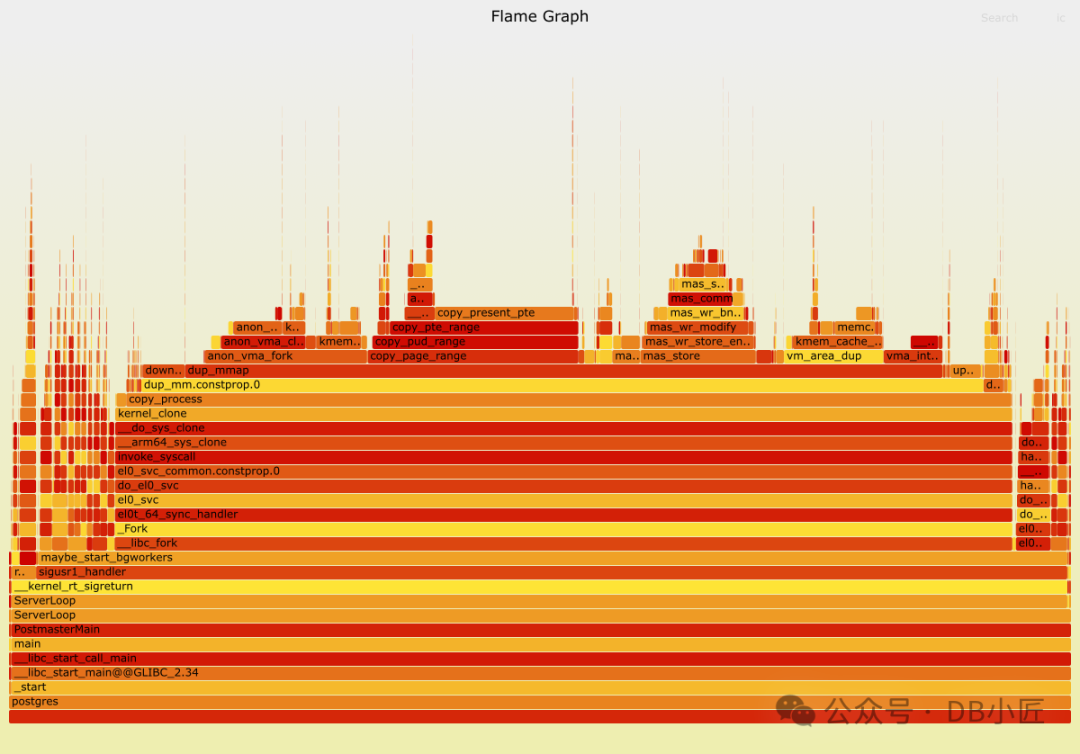
揭开生产环境的神秘面纱
在生产环境中,我们只是偶尔观察到连接延迟。我们确定这是由于另一个混淆因素——后台工作进程流失率增加——所导致的。
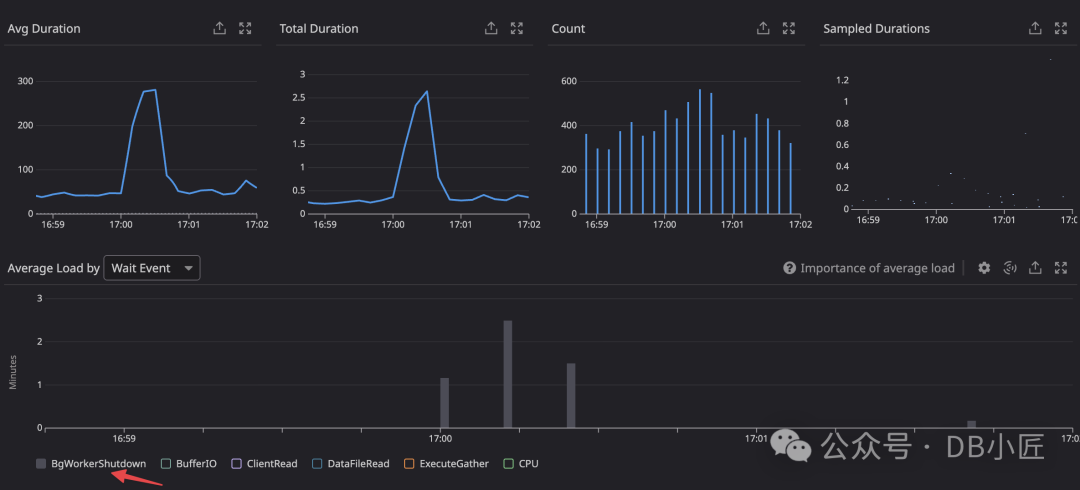
证据一直就在我们的数据库监控数据中,它清楚地显示,在延迟发生时,BgWorkerShutdown 的负载出现了峰值。
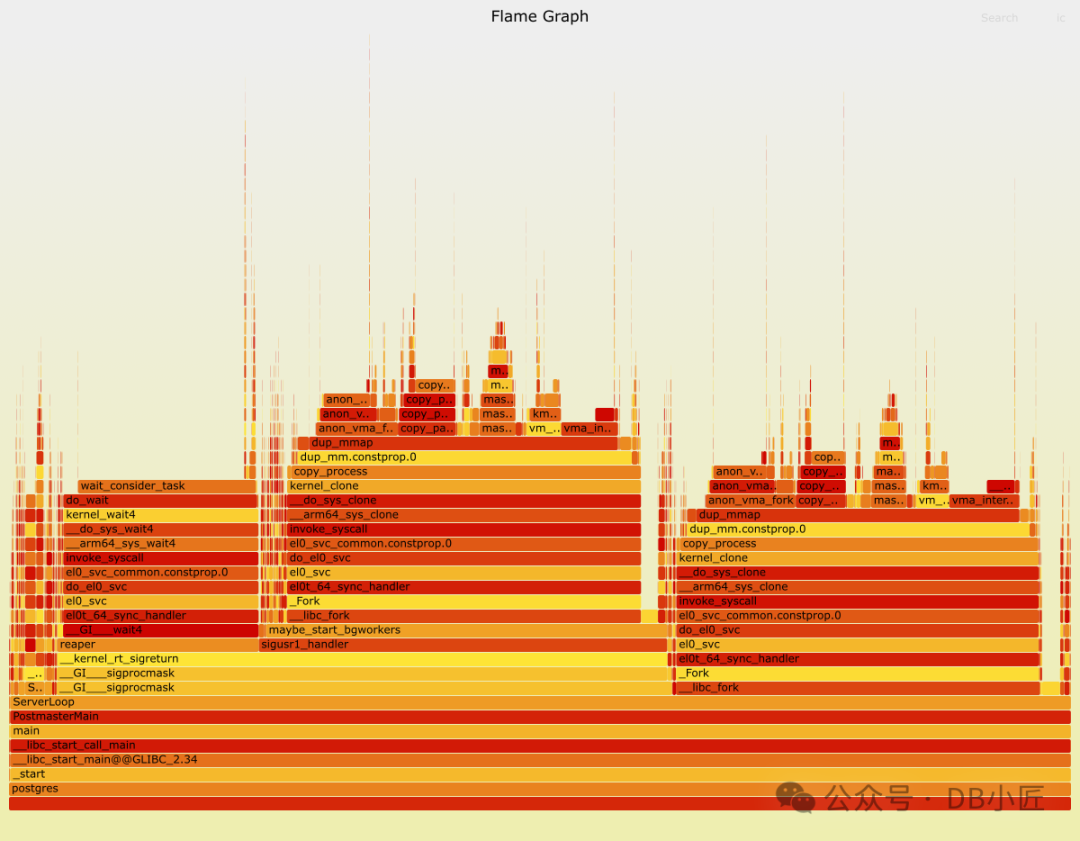
我们成功模拟了高后台工作进程流失与连接洪峰同时发生的情况,并观察到 postmaster 的连接吞吐量大幅下降。
我们将一个触发并行执行计划的查询,与某个会在整点高峰期被频繁调用的 API 端点关联起来。正是这两者在时间上的重合,导致了偶发的连接延迟。
如何解决这个问题?
在深入理解了故障模式后,我们可以系统地推理出解决方案:
- 在 EC2 实例群中引入抖动(Jitter):这平滑了峰值连接速率,降低了瞬间的冲击。
- 消除 API 服务器的并行查询爆发:通过优化查询或调整并行度设置,减少不必要的高并发后台工作进程创建。
这两项措施都显著降低了 postmaster 主循环的压力。
结论与思考
工程领域有许多被广泛传播但理解可能不够深入的“智慧”,PostgreSQL 连接池就是其中之一。通过这次探索,我们找到了连接池在大规模 PostgreSQL 系统中被普遍部署的一个根本原因。
大多数资料将其归因于连接流失、fork 开销或每个连接一个进程模型等。这些说法都对,但在我看来,它们可能“只见树木,不见森林”。
真正的瓶颈在于 postmaster 中单线程的主循环。每个需要 postmaster 参与的操作(连接、并行工作进程启动、子进程回收)都从一个固定的资源池中取用资源,而这个池的大小就是一个 CPU 核心的算力。一个简单的实验表明,在同一主机上运行额外的 postmaster 实例,可以线性地增加连接吞吐量。
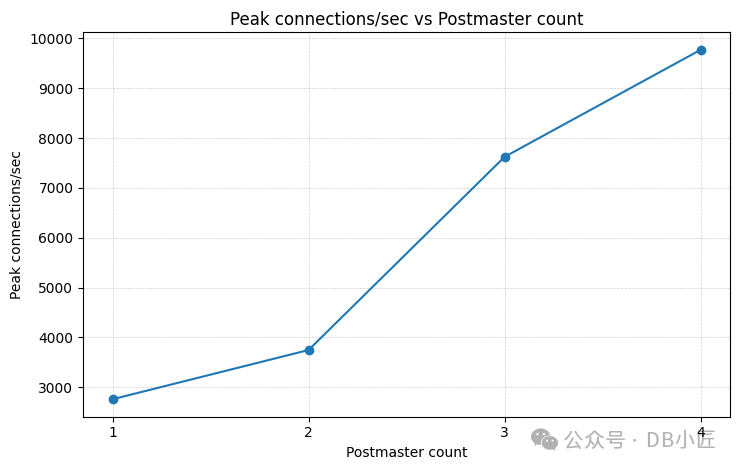
这是我最喜欢的一类发现:一个(或许是历史遗留的)人为约束,深刻地影响了整个开发者生态系统的形态(催生了 RDS Proxy、pgbouncer、pgcat 等工具)。希望有一天这个约束能被解除!
附注:令人费解的是,几乎没有 DBaaS 或监控工具提供对 postmaster 资源争用的可观测性。这到底是怎么回事?
实践建议
如果你也在生产环境中进行类似测试或优化,请注意以下几点:
- 环境差异:不同的 PostgreSQL 版本、硬件配置(特别是 CPU 架构和核心数)以及具体的工作负载特征,都会影响瓶颈出现的阈值和具体表现。
- Huge Pages 配置:启用前务必在测试环境充分验证。需要根据系统总内存和 PostgreSQL 的
shared_buffers 等配置来计算所需的大页数量,并警惕可能的内存碎片化问题。
- 连接池的合理使用:连接池大小需要精细权衡。过小会导致连接排队,增加延迟;过大则会增加 PostgreSQL 的进程管理负担,可能提前触发 postmaster 瓶颈。
- 并行查询的权衡:虽然并行查询能加速大查询,但需要评估其对系统稳定性的潜在影响。在高并发连接期间,或许需要动态调整
max_parallel_workers 等参数。
- 建立完善的监控体系:除了常规的数据库指标,还应考虑监控:
- Postmaster 进程的 CPU 使用率(是否持续接近 100% 单核)
- 连接建立延迟(
pg_stat_activity 中的连接时间戳辅助判断)
- 后台工作进程(BgWorker)的启动/关闭频率
- 系统的 fork 操作频率(可通过
perf 或 bpftrace 等工具采样)
在将任何优化措施应用到生产环境之前,务必在尽可能模拟真实负载的测试环境中进行充分验证,建立清晰的性能基线,并准备好回滚方案。
 发表于 2026-2-28 16:53:19
|
查看: 231|
回复: 0
发表于 2026-2-28 16:53:19
|
查看: 231|
回复: 0
