最近,越来越多的国内企业在云原生架构转型中,开始采用 AutoMQ 来替代传统的 Kafka 集群,取得了显著的降本增效成果。以腾讯音乐为例,其团队在采用 AutoMQ 后,整体集群成本降低了超过 50%。
除了腾讯音乐,Grab、小红书、知乎、吉利汽车、小鹏汽车、360 等企业也陆续将 AutoMQ 应用于生产环境。他们在使用后发现,无论是吞吐性能、分区重分配效率还是成本效益,都得到了大幅提升。那么,AutoMQ 究竟有何魅力?今天我们一起来深入探讨。
Kafka 的云原生困境
在云原生时代,技术栈持续迭代。然而,许多围绕 Java 构建的传统中间件在云环境中遇到了挑战。以 Kafka 为例,许多企业在云上部署 Kafka 后,面临高昂的费用账单和运维难题,主要痛点包括跨可用区的流量费用(可能占总成本 50% 以上)以及长达数天甚至数周的扩缩容周期。这些痛点正在催生消息队列领域的“云原生革命”。
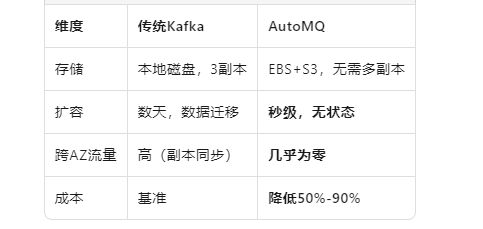
传统 Kafka 采用“Shared Nothing”架构,数据强绑定在本地磁盘,通过多副本(通常是 3 副本)机制保证可靠性。这种架构在物理机时代表现出色,但在云环境中却暴露出明显短板:
- 成本失控:跨可用区(AZ)的数据复制会产生巨额网络流量费用,有数据显示这可能占据总成本的 50% 以上。
- 弹性灾难:扩容需要迁移 TB 级别的数据,耗时漫长且风险极高。
- 资源浪费:计算和存储资源捆绑,无法独立扩缩容,导致闲时资源大量闲置。
AutoMQ 的诞生,正是为了引领消息和流存储软件走向真正的云原生时代。其目标是通过架构革新,实现 10 倍的成本缩减和百倍的运维效率提升,打造具备自动伸缩、自动运维和极致弹性的新一代消息队列。
AutoMQ 是什么?
简单来说,AutoMQ 是一款100% 兼容 Kafka 协议的云原生消息队列系统。它由 Apache RocketMQ 核心团队打造,完整保留了 Kafka 的上层 API 和生态,但彻底重构了底层存储架构,将数据持久化从本地磁盘卸载到了云存储(如 EBS 和 S3) 上。
AutoMQ 的核心定位非常清晰:它并非 Kafka 的一个“插件”或优化版本,而是一次架构级别的重新设计。根据其官网数据,相比传统 Kafka,它能实现10 倍的成本下降和百倍的弹性提升。
存算分离与云原生优先
在 AutoMQ 之前,业界已有存算分离的尝试,但 AutoMQ 将其理念贯彻得更为彻底。其设计核心可概括为两点:存储计算彻底分离和可靠性与可用性分离。
存储计算彻底分离
传统方案需要自建并管理复杂的分布式存储集群,而 AutoMQ 将存储彻底解耦,完全依托云厂商提供的共享存储服务:
- 热数据:写入低延迟的云盘(如 EBS)。
- 冷数据:归档至低成本的对象存储(如 S3)。
通过自研的 S3Stream 流式存储库,AutoMQ 实现了无限容量、按需扩展的存储层,让用户从繁琐的存储运维中解放出来,更专注于业务逻辑。
可靠性与可用性分离
传统 Kafka 通过多副本机制同时实现数据可靠性和服务高可用。AutoMQ 则将可靠性职责交给了云存储本身(例如 S3 提供 11 个 9 的数据持久性),自身则专注于优化服务可用性机制。这种职责分离使得架构更加简洁,成本也得以降低。
下图清晰地展示了 AutoMQ 与传统 Kafka 在架构上的核心区别:
企业为何集体选择 AutoMQ?
众多企业选择 AutoMQ,源于其在云时代带来的切实价值。其核心优势可归纳为以下三点:
成本革命,直降50%+
降低成本是企业最直接的驱动力。以小鹏汽车的技术分析为例,Kafka 成本主要来源于两方面:
- 存储成本:高性能云盘(如 ESSD)的单价远高于对象存储(S3),加上三副本机制,成本差距可达 18 倍。
- 闲置浪费:无法及时缩容导致资源预留过度。
AutoMQ 通过将冷数据沉降到廉价对象存储,并利用“零成本复制”技术(通过 S3 WAL 和机架感知 Broker 映射,让生产数据尽量停留在本地可用区),从根本上消除了跨 AZ 流量费用。腾讯音乐的实践表明,采用 AutoMQ 后,Kafka 集群成本平均降低超过 50%。
秒级弹性,运维效率质变
传统 Kafka 扩容通常需要 1-2 天的人工数据迁移操作。而 AutoMQ 由于 Broker 无状态(数据在云端),实现了:
- 分区秒级迁移:无需搬迁实际数据。
- 自动流量均衡:内置 Self-Balancing 机制。
- 快速吞吐扩展:可在数十秒内扩展出 1GiB/s 的吞吐能力,轻松应对突发流量。
这种极速弹性能力,让运维团队从被动的“救火式”运维转向自动化的高效管理。
真正云原生,Kubernetes 深度集成
AutoMQ 采用“Kubernetes Native”的设计,能够充分利用 Kubernetes 的调度和编排能力:
- 提升资源利用率:支持细粒度的 Pod 调度和快速迁移。
- 标准化部署:提供 Helm Chart,支持一键部署。
- 混合云支持:例如吉利汽车就采用 EMQX + AutoMQ 构建了公私一体化的车联网架构。
Kafka 会被 AutoMQ 取代吗?
这是一个需要理性看待的问题。AutoMQ 的目标并非“取代” Kafka,而是在公有云和 Kubernetes 环境下提供一个更优的解决方案。两者的关系更可能是共存与互补:
- 传统/私有云场景:在物理机或私有云环境中,经过多年验证的 Kafka 仍是稳妥的选择。
- 云原生场景:在公有云、尤其是深度使用 K8s 的环境中,AutoMQ 在成本和弹性上的优势非常明显。
Apache Kafka 社区也在持续进化(如 4.0 版本致力于简化部署)。未来的格局很可能是双轨并行:
- 存量系统:根据成本和技术栈情况,分阶段逐步迁移。
- 增量系统:在新的云原生项目中,AutoMQ 会成为更有吸引力的选项。
当然,AutoMQ 也面临着自己的挑战,例如在 AI 向边缘延伸的背景下,其对中心云资源依赖的设计能否适配资源受限的边缘环境,仍需观察。
结语
哪里有痛点,哪里就有创新。AutoMQ 的成功并非偶然,它精准地命中了云原生时代的核心诉求:成本与效率。当企业从简单“上云”转向深度“用云”时,架构的云原生改造势在必行。Kafka 不会消失,但像 AutoMQ 这样“为云而生”的解决方案,无疑代表了消息队列技术的重要演进方向。正如业界观点所言,不是 Kafka 不够好,而是云时代需要新的架构解法,AutoMQ 正是这个新解法的有力候选者之一。
 发表于 2025-12-1 14:21:30
|
查看: 227|
回复: 0
发表于 2025-12-1 14:21:30
|
查看: 227|
回复: 0
