我们正经历从“对话式AI”向“自主智能体(Agentic AI)”的关键跃迁。到了2026年,核心命题或许不再是模型本身够不够聪明,而是AI能否真正、安全地接管生产环境中的复杂工作流。
设想这样一个场景:一个帮助客户执行跨云迁移的Agent。前两个小时,它近乎完美地在AWS和GCP之间配置了VPC、拉起新实例,并在流程的第12步成功删除了旧数据库。然而,就在看似胜利在望的第13步,它因为一个罕见的API限流错误而彻底崩溃。
此时,你该怎么办?盲目重试?它可能会再次尝试删除那个已经不存在的数据库。简单重启?它完全忘记了哪些实例已经成功拉起。在没有有效状态恢复机制的情况下,你的整个云环境可能瞬间陷入一团乱麻。
这并非危言耸听,而是任何在生产环境中运行超过10个步骤的Agent都可能遇到的现实困境,只是严重程度不同。本文将深入探讨:为何这个问题是结构性的?现有基础设施为何无力解决?以及,构建下一代Agent基础设施可能需要哪些核心原语。
Agent 的独特执行特征
许多开发团队仍将Agent简单地视为大语言模型(LLM)的“包装器”,挂载几个工具调用(tool call),加上一些简单的测试框架就部署上线。但当你赋予Agent真实的系统权限,并期望它长时间自主运行时,才会发现其执行特征与我们熟悉的任何软件形态都截然不同。
Agent的执行同时具备五个关键属性:长程运行、敌意输入、真实权限、不确定决策、真实副作用。
- 长程运行:意味着崩溃是统计上的高概率事件,必须为中断和恢复做设计。
- 敌意输入:并非指用户恶意攻击,而是类比浏览器中运行的客户端JavaScript——Agent处理的输入(如邮件正文、网页内容、API返回值)随时可能包含被注入的指令,架构层面必须默认输入不可信。
- 真实权限:Agent持有API密钥、数据库凭证、云平台令牌等。
- 不确定决策:源于LLM本身的概率生成特性,相同的提示词在不同时间点可能产生不同的输出。
- 真实副作用:每一步操作都可能不可逆地改变外部世界状态,例如发送无法撤回的邮件,或执行无法回滚的数据库删改。
近期引起广泛关注的“龙虾”项目(OpenClaw)将这一问题推至前台。它表明,赋予模型真实系统权限能带来能力上的巨大跃迁,但也将安全风险从理论讨论变成了迫在眉睫的现实。
这五个属性单独来看并不新鲜。数据库用事务语义处理副作用,浏览器用沙箱模型处理敌意输入,分布式系统用检查点(checkpoint)处理长程任务。Agent的独特挑战在于,它将这五个属性同时绑定在了同一条执行链上,而没有任何现成的系统是为这个特殊组合设计的。即使收紧权限、要求每一步都人工审批,“长程运行”加上“不确定决策”也使得可恢复的语义成为刚性需求。
两个已然过时的基础设施假设
现有的Agent基础设施,大多建立在两个与Agent现实不匹配的过时假设之上。
首先是威胁模型的假设。整个行业仍在用运行服务器端代码的安全假设,来运行本质是客户端代码的Agent。除了用户输入,服务器端假设环境完全可信、执行环境受控、API接口由开发者明确定义。然而,Agent读取的内容是“敌意”的,它持有真实的密钥,并在开发者无法完全控制的环境中执行。它的正确威胁模型应该是浏览器,而非服务器。
其次是执行模型的假设。现有的执行基础设施是为确定性、短时、无状态的任务设计的:一个请求进来,处理完毕,返回结果。而Agent的执行是概率性的、长程的、带状态的。它的决策路径不可复现,副作用不可撤销,并且运行时间长得让崩溃成为统计必然。将这样的执行体塞进以“请求/进程”为容错单元的基础设施里,问题不会在演示阶段暴露,只会在生产规模上爆发。
这两个错位假设的具体后果,体现在三个核心能力的缺失上:
- 没有副作用日志,出事时无法回溯到底发生了什么。
- 没有可恢复的执行状态,中断后无法从任意点恢复完整的上下文与环境。
- 没有隔离边界,将权限与数据暴露给不可信的输入。
三条必须补全的基础原语
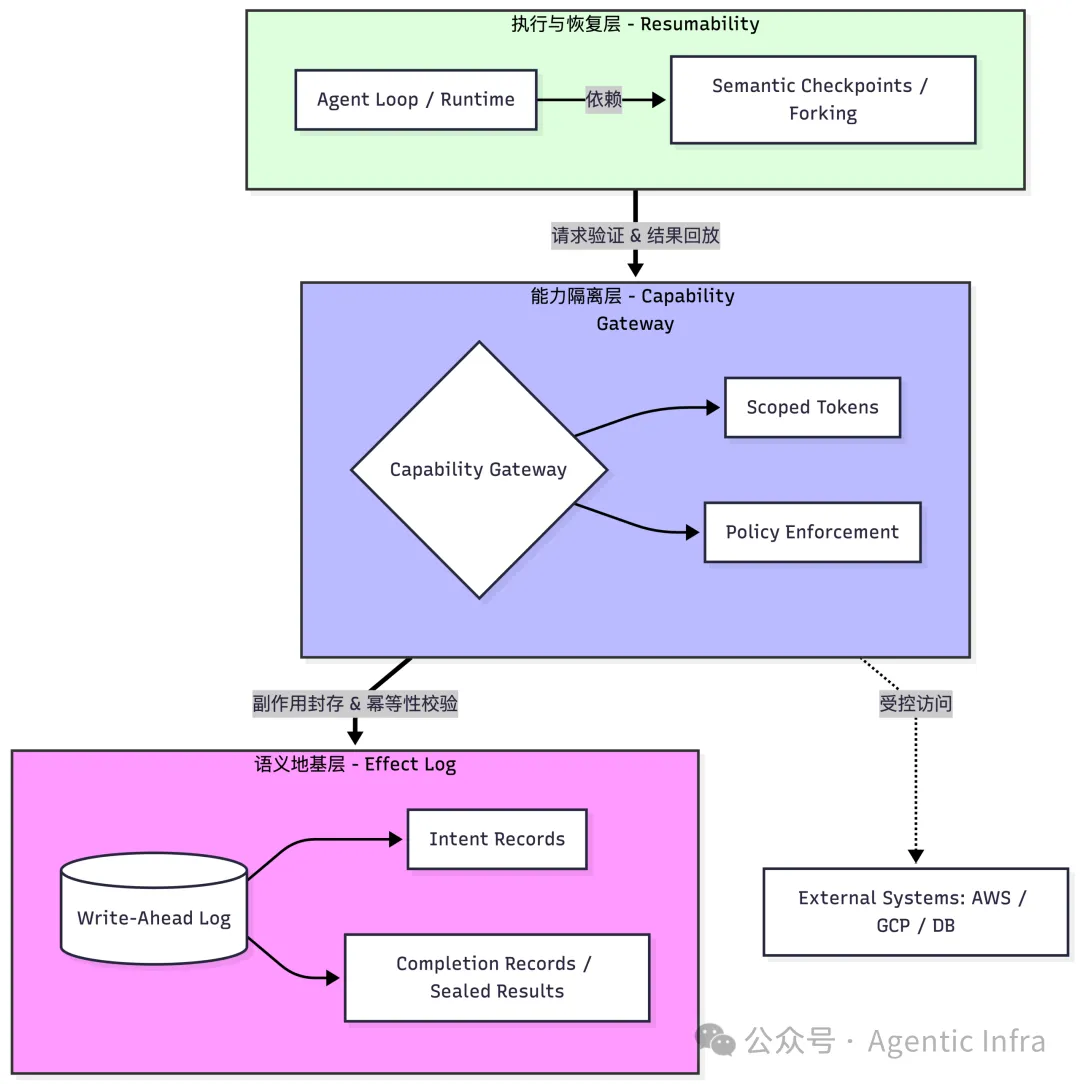
从上述两个根本性错位出发,我认为构建面向生产级的Agent基础设施需要补上三条核心原语。这三条原语存在严格的构建顺序:副作用必须先被妥善封存,能力边界才能被正确执行,恢复机制才能是安全的。
原语一:语义地基层 —— Effect Log(副作用日志)
这是另外两个原语的地基。生产环境的恢复以语义正确性为最高优先级,调试回放则以可复现性为前提。其核心思路是:将对外部世界产生的副作用,构建成一套“预写日志(Write-Ahead Log)”。
任何可能产生副作用的调用,在执行前必须先写入“意图记录(Intent Record)”,记录幂等键、预期影响范围、所需的审批级别等信息。执行成功后,再写入“完成记录(Completion Record)”,保存完整的请求、响应、ETag以及操作是否已造成不可逆改变。当系统需要恢复时,只读调用可以直接重放;而有副作用的调用则默认返回完成记录中已封存的结果,不再实际触碰外部系统。
Effect Log的关键在于,依据可恢复语义对工具调用进行最小化分类,并规定明确的恢复策略:
- 纯读调用:可以安全重放。若为了可复现的调试,可直接返回日志中封存的响应,而非重新请求外部系统。
- 幂等写调用:需携带幂等键。恢复时允许重放,必要时由中介层利用Effect Log进行去重,以保障幂等性。
- 不可逆写调用:一律禁止重放。恢复时直接返回完成记录中封存的“既成事实”结果。
- 读写混合调用:最为危险。必须先将读操作获得的响应或版本指纹写入意图记录,并与完成记录一并封存。恢复时禁止重新执行读操作,只能基于封存的“读快照”继续推进,避免因外部状态漂移导致逻辑分叉。
这些分类应由工具开发者在注册工具时主动声明,成为一种接口契约——就像HTTP方法中GET是安全的、PUT是幂等的一样。现实中存在模糊地带,例如一个携带幂等键但结果不可撤回的Stripe退款调用。裁决原则应是按最保守的分类处理:如果一个调用的任何维度是不可逆的,恢复时就按不可逆写对待。错误地重放一次不可逆操作的代价,远高于错误地跳过一次幂等重试。
回到开头的跨云迁移场景:Effect Log会在第12步删除数据库的瞬间,就写下对应的完成记录。当崩溃恢复时,基础设施读取到这条记录,直接返回已封存的结果,“重复删库”的风险从根源上被排除。这些分类规则是强制的接口契约,必须由下一个原语——能力控制网关(Capability Gateway)来强制执行。
原语二:能力隔离层 —— Capability Gateway(能力控制网关)
有了Effect Log作为可信的语义地基,下一步是勾勒清晰的能力边界。
不应将真实凭证直接交给Agent进程,而是通过一个“能力控制网关”中介所有对外部系统的访问。Agent拿到的应是具有时间限制、范围限制且可即时撤销的临时令牌(Scoped Tokens)。权限边界在基础设施层被强制执行,不依赖LLM的“自觉”。
这与浏览器的安全模型思路一致:浏览器标签页无法直接访问操作系统,并非因为JavaScript代码承诺不越界,而是因为浏览器在架构上就没赋予它这个能力。
你授予Agent的权限范围,就是其“爆炸半径”。这个权衡永远存在:权限越大,Agent能力越强、越有用,但出事时的潜在损害也越大。关键在于要有意识、有控制地做出选择,而非将所有权限制“一把梭”地丢给Agent。
当崩溃触发后,临时令牌即刻失效。即使崩溃是由于恶意指令注入所致,失去凭证的Agent也无法继续造成损害。我们在ClawShell项目中的实践,正是这一思路的具体体现。
原语三:执行与恢复层 —— Forking Recovery(分叉恢复)
只有在副作用事实被可靠封存、能力边界被清晰隔离的前提下,“分叉”才是安全的。
Agent的执行本质上是搜索:它在一个巨大的决策空间中探索路径。这个搜索过程并非单一线程,而是一张不断展开的图。每个决策分支都需要独立的检查点,这是一个包含模型输出、工具调用结果以及Effect Log游标位置的“语义闭包”。恢复时,系统能够精确地回到某个节点继续推进,而不必一切从头开始。
分叉恢复不仅是性能优化,更是让Agent系统变得可调试、可观测的前提。没有它,出了问题只能盲目猜测。可追踪性必须从第一天起就内建于基础设施中,无法事后补救。
再次回到迁移场景:你看到的将不再是一个“死掉”的任务,而是执行图谱上的一个精确断点。你可以从第12步之后的状态直接“续跑”,携带完整的上下文,彻底避免重复执行已完成的操作。
从“保活”(Uptime)到“可恢复”(Resumability)的范式转变
在SaaS时代,基础设施的核心指标是正常运行时间(Uptime)。我们通过多副本、自愈和冗余来保障服务等级协议(SLA)。
但对于Agent而言,Uptime是一个“代理指标”。你无法保证一个需要运行48小时的Agent永不遭遇网络抖动或硬件故障。我在Cloudflare参与构建边缘基础设施时学到的一个原则是:设计目标不应是保证机器永不宕机,而是在故障发生时,全力保障执行语义的正确性。
正确的核心指标应是可恢复性(Resumability):能否在任意时间点重新进入执行,并完整恢复状态、上下文和環境?
这是一个从“保证不死”到“允许随时死掉并能满血复活”的范式转变。一个可以被中断然后被正确恢复的Agent,远比一个理论上永不停机但遇到硬件故障就毫无退路的Agent更为可靠。
这个转变还有一个反直觉的推论:对Agent进行扩容,往往不是横向添加更多副本,而是垂直为同一个Agent分配更大的计算资源。垂直扩容在实践中通常意味着“做检查点 -> 重启”,这使得可恢复性从异常处理路径变成了常规操作。如果你的基础设施没有将恢复机制作为一等公民来设计,那么扩容本身就会成为新的风险源。
现有基础设施的抽象层错位
需要强调的是,下文提及的各类系统在它们各自的抽象层上都是正确且优秀的。问题在于,Agent的生产级需求恰好落在了这些抽象层的缝隙之外。
- Kubernetes 解决的是资源与进程层面的隔离。它能将容器隔离起来,但“看不见”容器内工具调用的语义。一个被注入恶意指令的Agent,其所有危险行为都通过合法渠道(真实的API Key、正常的HTTP请求)发生。对Kubernetes而言,一个Agent在正常调用API与一个Agent在执行注入指令,所产生的网络流量看起来完全一样。
- Firecracker与gVisor 提供了更细粒度的工作负载隔离。Firecracker的微虚拟机结合了虚拟机的隔离性与容器的速度,gVisor则在用户空间提供了一个类Linux的应用内核。它们在隔离层做了出色工作,但“隔离层”与“语义层”是两回事。它们能阻止一个进程访问另一个进程的内存,但无法判断一个Agent是否在用其持有的API密钥执行一个由注入指令触发的危险操作。
- Modal与E2B 在代码执行沙箱层做出了有价值的贡献。Modal提供了Python原生的执行环境以降低部署摩擦,E2B则明确将自己定位为让Agent安全执行代码的隔离沙箱。然而,代码隔离与能力隔离是不同的问题。Agent在获得一个干净的沙箱后,依然可以使用其持有的真实API密钥调用任何外部服务。崩溃恢复、副作用记录、幂等重放等问题,仍需在应用层自行实现。
- WASM与Unikernels 前景广阔,但成熟度尚待提升。Python的大量C语言扩展绑定在WASM中几乎无解;Unikernels虽然极大缩小了攻击面,但难以保证完整的Linux语义兼容——而调用bash恰恰是当前Agent最强的能力之一。
这些系统的共同特点是:它们实现了“执行隔离”(将代码关起来),但未能提供“语义隔离”(将能力与副作用关起来)。这种区分在传统软件场景中并不重要,因为传统软件的逻辑是确定且可信的。Agent的出现,彻底打破了这个前提。
编排层为何无法填补这一缺口
或许有人会问:Temporal或Netflix Conductor这类工作流编排系统,不是已经解决了“持久化执行(Durable Execution)”的问题吗?它们确实解决了,但解决的是不同前提下的问题。
Temporal和Conductor提供了持久化工作流历史、断点恢复、幂等重试等强大能力,在微服务编排场景中价值巨大。然而,它们都有一个核心前提:工作流本身的代码逻辑是确定性的、可信的。Temporal官方明确要求工作流代码必须具备确定性,当代码改动可能引入非确定性时,需要使用“Worker版本控制”或“补丁API”等机制来保护正在运行的工作流。
LLM从根本上打破了这一前提,具体带来两个问题:
- 确定性重放的失效:Temporal的容错严重依赖“重放(Replay)”机制,其前提是代码确定。LLM崩溃后若简单重放,会走入不同的决策路径。你必须缓存每一次LLM调用的结果,并在重放时直接返回缓存。此时,你实际上是在Temporal之上自行实现了一套状态机,Temporal的重放机制反而成了额外的约束成本。
- 信任边界的缺失:Temporal最根本的基础假设是代码逻辑本身可信,基础设施可能出错(如网络、进程、机器故障)。但Agent的核心问题之一是LLM的输出本身不可信。Temporal会忠实地执行一个由提示词注入(Prompt Injection)发起的攻击,因为从它的视角看,这只是工作流的正常逻辑。这意味着你需要在Temporal的执行模型之外,独立构建类似Capability Gateway的能力隔离层。然而Temporal并未为此预留集成点——它的“活动(Activity)”边界是执行边界,而非信任边界。你不得不在两套系统的接缝处自行维护一致性,而这个接缝处恰恰是攻击面最大的地方。
因此,Temporal或Conductor可以作为上层的编排器。但能力隔离与副作用语义必须在它们之外首先确立。编排可以在已确立的语义地基上组织流程,却无法替代地基本身。
一个关于演进方向的隐含赌注
本文的论述包含一个隐含假设:Agent的主流形态终将收敛于“长程、高权限、带真实副作用的自主执行”。
这并非唯一可能的演进路径。另一种方向是Agent始终保持“短程、低权限、每一步都需要人工审批”的模式。如果这一路径成立,上文所述三条原语的优先级将发生变化:能力隔离依然重要,但副作用日志和分叉恢复的紧迫性会大大降低,因为人工审批本身就是一个强大的“断点”。
我选择押注“长程自主执行”的方向,原因有二:第一,模型能力在快速提升,每一步都需人工审批的模式在体验上将越来越令人难以忍受,正如你不会愿意每个网页链接都弹一次安全确认框。第二,Agent的核心价值本质上源于其自主性——能够独立完成一段复杂的、跨系统的工作流。如果每一步都需要人盯着,那它只是一个更花哨的自动补全工具。
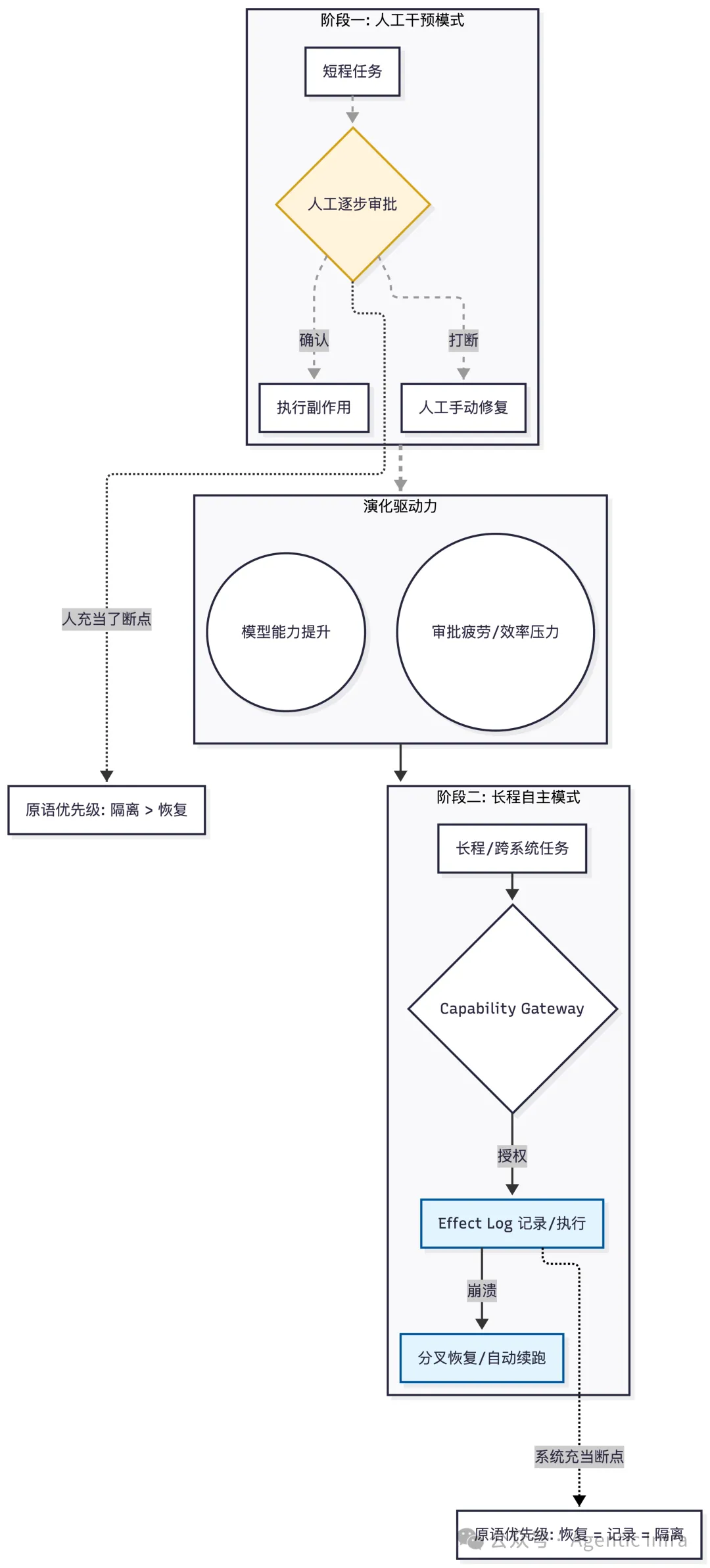
即便在人工审批模式下,审批的粒度也会随着信任的积累而逐渐粗化。一个团队第一次让Agent执行“删库删表”操作时会要求人工确认,但在第10次成功执行后,这个审批很可能被取消或自动通过。这意味着,长程自主执行是一个必然的演化终点。审批终将被疲劳打败:系统一旦运行顺畅,人会主动取消审批;如果审批过多,流程效率的压力也会迫使你跳过它们。
基础设施的真正使命:对抗不确定性熵增
LLM与生俱来的不确定性不会消失,模型能力的提升也不会自动解决这个问题。更强的模型意味着被赋予更多的自主权,而更多的自主权则意味着潜在的“爆炸半径”更大。
LLM的核心任务是在决策空间中持续进行“熵增”(探索不确定性),而基础设施的真正使命,则是围绕其进行“熵减”(建立确定性边界)。
Agent的循环(Agent Loop)决定了它将做什么。
基础设施(Infra)则决定了它被允许做的边界。
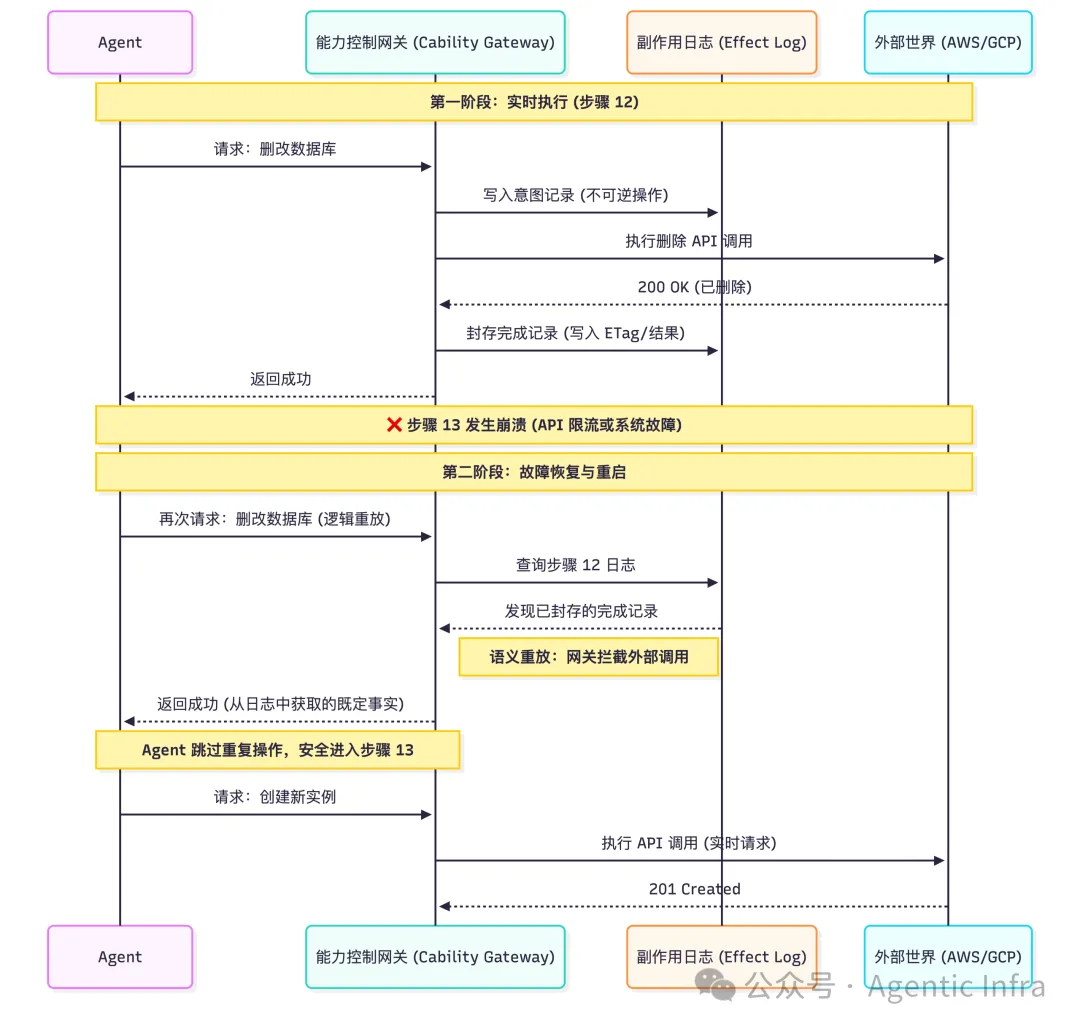
让我们最后一次回到开头的场景:在没有为Agent设计的基础设施时,开发者面对的是“废墟”——数据库已消失,实例状态未知,客户可能已经流失甚至索赔。如果拥有了正确的、面向Agent设计的基础原语,当Agent在第13步失败时,开发者会收到通知,打开Effect Log界面,清晰看到第12步的数据库删改已完成并被封存。只需点击“恢复”,执行便会从故障的精确断点分叉出来,携带完整上下文,丝滑地继续运行,彻底规避了重复执行已完成操作的风险。
基础设施的目标不应是追求模型永远正确,而是让模型的错误变得可预测、可隔离、可挽回。在模型的不可预测性周围,用系统的确定性画出一道坚固的边界,以此收敛和驾驭模型的不确定性。
如果说SaaS时代的基础设施,解决的是计算力如何被高效分配;那么在Agent时代,基础设施要解决的根本命题是:不确定性如何被安全地收敛与驾驭。
现有的基础设施堆栈还远远不够。当Agent的自主权从分钟级任务扩展到天级甚至周级,当Agent的容错单位从“进程”转变为“语义执行”时,我们的基础设施栈,亟需从执行层开始重建。对于关注人工智能前沿实践与系统架构演进的开发者而言,深入理解并参与构建这些新的基础原语,将是把握下一个技术周期的关键。
 发表于 2026-3-9 08:57:25
|
查看: 188|
回复: 0
发表于 2026-3-9 08:57:25
|
查看: 188|
回复: 0
