在电商场景下,每天数百万次的商品查询对系统响应速度提出了严苛要求。引入Redis缓存后,如何保证“公告栏”上的价格与仓库里的记录保持同步,就成了核心难题。这本质上是在用空间换时间,用复杂度换准确性。本文将围绕一个电商商品查询系统,系统性地剖析查询缓存机制与主流数据一致性方案,助你避开常见的并发陷阱。
1. 缓存到底是什么?
1.1 大白话解释
想象你是一家商场的老顾客。每次想了解商品价格,都要让店员跑去仓库翻记录,效率实在低。于是,商场在门口设了个“热门商品公告栏”,把常被询问的信息贴上去。
你的查询流程就变成了这样:
- 先看公告栏上有没有你要的信息(相当于查Redis);
- 如果有,直接拿走,速度飞快;
- 如果没有,店员再去仓库查(相当于查数据库),查完顺手把新信息贴到公告栏上。
这个“公告栏”就是Redis缓存。它把高频访问的数据放在内存里,避免了每次都去慢速的数据库中查找,从而大幅提升响应速度。
电商系统示例: 在我们的电商商品查询系统中,引入Redis后,将热门商品(如爆款手机、服饰)的信息缓存起来,95%以上的查询可以直接从Redis获取结果,响应时间从800ms骤降至80ms以内。
但如果商家修改了价格,如何确保公告栏不显示旧价?这就引出了关键问题:如何保持缓存与数据库的一致性?
类比一下: 这套机制就像给繁忙的前台配了一名高速助手,让他先处理重复性高的任务。只有当助手处理不了时,才去打扰后台主管(数据库)。既提升了效率,又减轻了核心系统的压力。
1.2 专业解释
Redis作为一种高性能内存键值存储,广泛用于实现旁路缓存模式(Cache-Aside Pattern)。在此模式下,应用程序主动管理缓存与数据库的交互逻辑。
核心读写流程如下:
- 读操作: 应用首先尝试从Redis中获取数据。若命中(Cache Hit),直接返回;若未命中(Cache Miss),则回源到数据库查询,并将结果写入Redis供后续使用。
- 写操作: 采用“先更新数据库,再删除缓存”的策略。确保数据持久化成功后,使旧缓存失效,下次读请求会自动加载最新数据并重建缓存。
该模式适用于读多写少、能容忍短暂不一致的业务场景,如商品详情页、用户资料展示等。它的优势在于实现简单且性能高,是当前互联网系统的主流选择。

常见风险与应对策略
| 问题 |
定义 |
解决方案 |
| 缓存穿透 |
查询根本不存在的数据,导致请求直达数据库。 |
- 缓存空对象
- 使用布隆过滤器拦截无效请求 |
| 缓存击穿 |
热点key突然失效,大量并发请求同时打向数据库。 |
- 加互斥锁
- 逻辑过期控制刷新 |
| 缓存雪崩 |
大量key集体失效或Redis宕机,造成数据库雪崩式冲击。 |
- 过期时间加随机值
- 构建主从+哨兵/集群高可用架构 |
这些防护机制共同构成了一个健壮的缓存体系,防止系统因极端情况而崩溃。
2. 主流一致性解决方案

2.1 旁路缓存模式
2.1.1 读写基本流转
这是最标准、最常用的缓存策略,也就是我们常说的Cache-Aside Pattern。
✅ 读流程 (Lazy Loading 懒加载)
当用户请求查看商品信息时:
- 应用尝试从Redis读取
product:1001;
- 若命中,则直接返回商品数据;
- 若未命中(缓存空或已过期),则访问MySQL执行
SELECT * FROM products WHERE id=1001;
- 将查询结果写入Redis并设置TTL(如30分钟±随机偏移);
- 返回结果给前端。
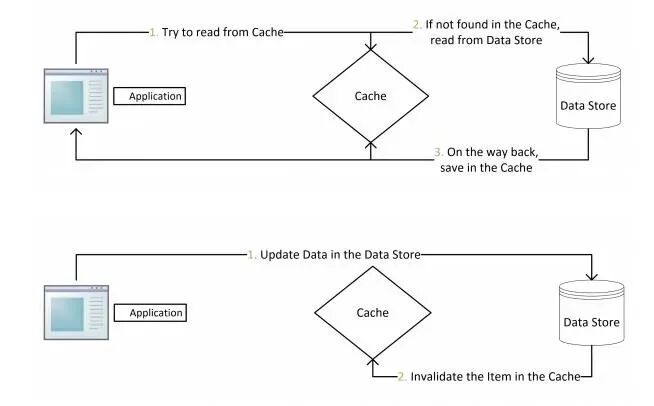
Cache-Aside 读流程:客户端 → API网关 → 商品服务 → Redis → (未命中)→ 数据库 → 回填Redis → 返回数据
写流程 (Invalidate on Write 失效写)
当管理员更新商品价格时:
- 首先执行SQL语句更新MySQL中的price字段;
- 更新成功后,立即发送
DEL product:1001 命令删除Redis中对应的缓存;
- 下一次用户请求时会触发缓存重建,加载新价格。
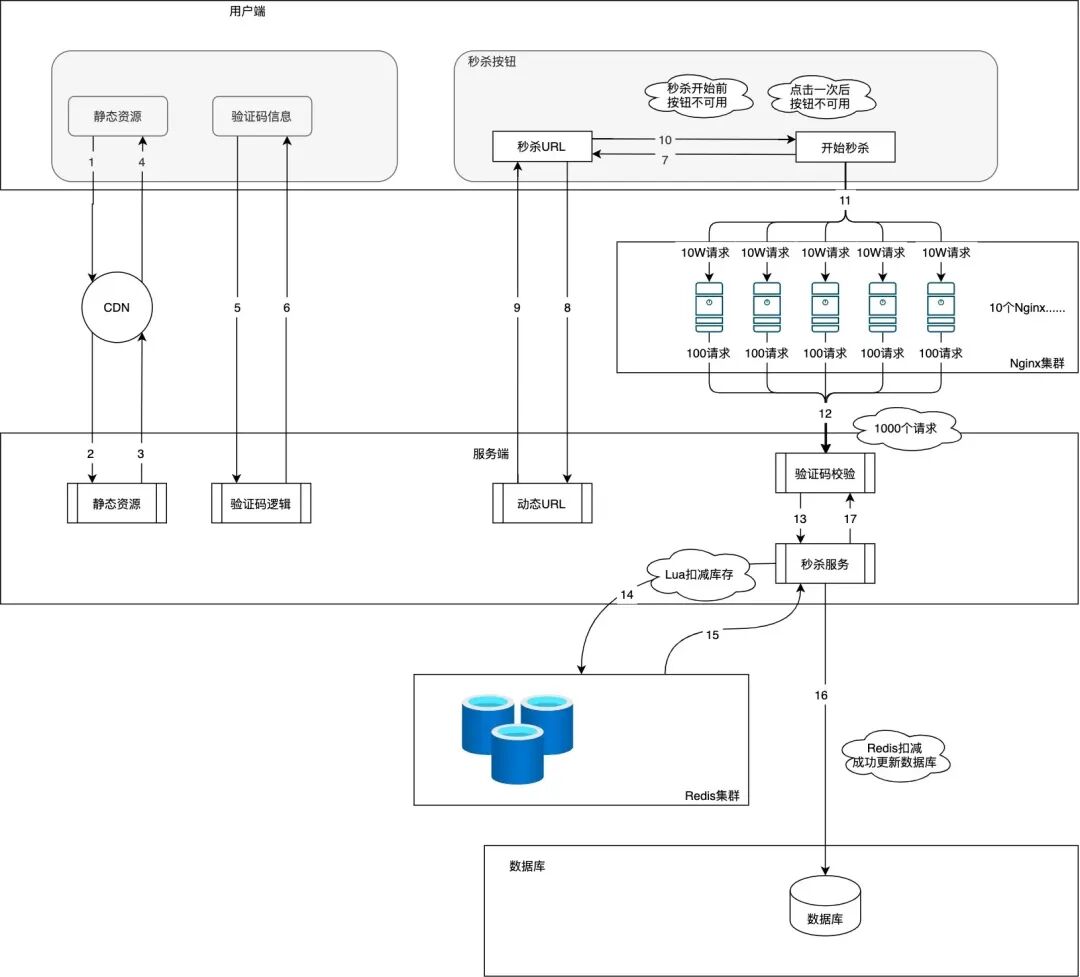
Cache-Aside 写流程:更新请求 → 商品服务 → 更新数据库 → 删除Redis缓存 → 完成
❓为什么是“删除”缓存而不是“更新”它?
这个问题很关键。乍一看,“更新缓存”似乎能立刻让缓存变新,但实际上它藏着几个致命陷阱。
2.2 方案1:更新缓存的陷阱
有人在写操作时选择直接“更新缓存”而非删除,看似能保持缓存新鲜,实则隐患巨大。

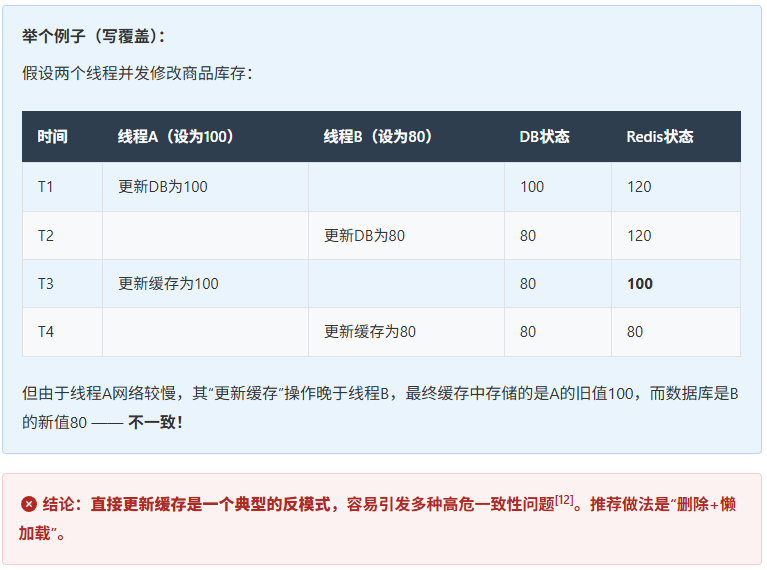
2.3 方案2:先删缓存后更数据库
此方案的流程是:先删除Redis缓存 → 再更新MySQL数据。
2.3.1 并发读写的脏数据
但在高并发下,可能出现以下竞态条件:
- 线程A删除缓存key;
- 线程B发起读请求,发现缓存为空;
- 线程B从数据库读取旧数据V1;
- 线程B将V1写回缓存;
- 线程A完成数据库更新为V2;
- 此时缓存中仍为旧值V1,形成脏数据。
这个问题的根源在于“删除缓存”与“更新数据库”之间有个时间窗口,让其他读请求趁机把旧数据又填了回去。
类比一下: 你刚撕掉公告栏上的旧通知,还没来得及改仓库里的记录,就有顾客看到了空栏,跑去仓库抄了一份旧记录重新贴了上去。
因此,该方案不被推荐作为主策略。
2.4 方案3:延迟双删策略
为了缓解上述问题,引入了延迟双删机制:
- 第一次删除缓存;
- 更新数据库;
- 异步延迟一段时间(如500ms)后,再次删除缓存。
这“第二脚”的目的是为了清除在“主从同步延迟”或“读请求耗时”期间被人回填的旧数据。
延迟时间建议公式:
延迟时间 ≥ 主从同步最大延迟 + 读请求平均耗时 + 网络抖动缓冲
通常设置为500ms~1s。

2.5 方案4:先更数据库后删缓存
这是当前业界首选方案,约90%的应用场景都采用此方式。
2.5.1 极低概率的脏数据
尽管如此,理论上仍存在一种极其罕见的脏读场景:
- 线程A读缓存 → 未命中;
- 线程B更新数据库 → 成功;
- 线程B删除缓存 → 成功;
- 线程A此时才从数据库读到旧数据(因主从延迟或事务隔离级别);
- 线程A将旧数据写回缓存 → 导致短暂脏读。
这个情况发生概率极低,需同时满足“缓存刚好过期 + 读写并发 + 写操作快于读操作”三个条件。
再类比一下: 这次公告栏自己掉了,新价格还没同步到分仓库,就有人去了分仓库,抄了旧价格回来贴上。
风险虽小,但仍需加固。接下来看看如何增强保障。
2.5.2 消息队列重试机制
为应对“删除缓存失败”导致的长期不一致,可以引入MQ进行异步补偿:
- 数据库更新成功后,发送MQ消息通知“删除缓存”;
- 消费者监听队列,执行DEL命令;
- 若失败,则按指数退避策略重试(如2s, 4s, 8s);
- 超过重试次数后进入死信队列(DLQ),触发告警并由补偿服务处理。
关键可靠性保障:
- 生产者确认: 启用Publisher Confirm机制,确保消息投递成功
- 消息持久化: 队列和消息均设置为durable/persistent
- 消费者手动ACK: 处理成功后再确认,防止丢失
- 本地事务表: 保证“更新DB”与“发消息”的原子性
这种方式解耦了主流程与缓存清理,提升了系统的整体可用性。
2.6 方案5:最终一致性的订阅方案
这是大型系统的终极解决方案。
2.6.1 数据库日志同步原理
这个方案利用MySQL的Binlog(二进制日志)机制,通过Canal或Debezium等工具伪装成从库,实时拉取并解析数据变更事件。
前提配置要求:
- 开启
log-bin=mysql-bin
- 设置
binlog-format=ROW(必须)
- 配置
server-id
- 推荐开启GTID支持自动位点定位
Canal Server连接MySQL主库,接收Row-based Event(如UpdateRowsEvent),解析为结构化数据后推送至Kafka/RocketMQ。
2.6.2 全链路架构流转
- 业务系统正常更新MySQL;
- MySQL生成ROW格式Binlog;
- Canal Server伪装成Slave拉取Binlog并解析;
- 将变更事件发布到Kafka;
- 缓存同步服务消费消息,提取主键ID,生成Redis Key并执行DEL操作;
- 下一次读请求自动重建缓存,加载最新数据。

对于金融、电商、支付等强一致性要求的系统而言,这是最可靠的方案。
3. 总结
我们围绕“电商商品查询系统”这个真实业务场景,把Redis查询缓存的核心原理与一致性方案从头到尾梳理了一遍。
五大一致性方案对比总结:
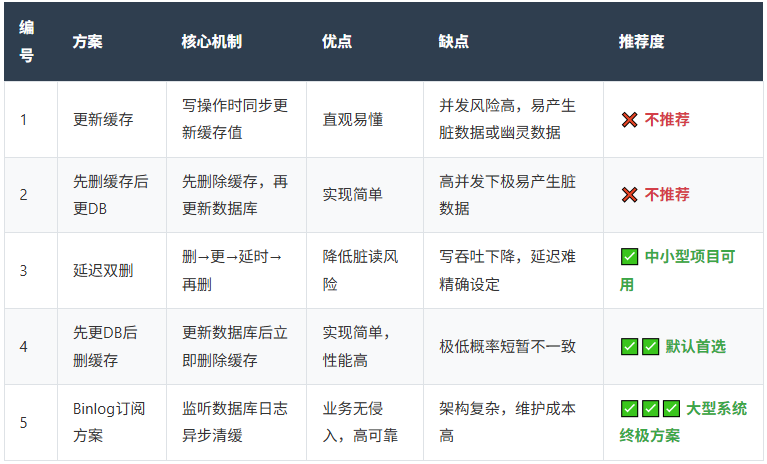
最佳实践建议:
- 优先采用“先更新数据库,再删除缓存”作为基础方案;
- 配合TTL过期兜底,防止脏数据长期驻留(如设置30~3600秒);
- 引入MQ异步重试机制,提升删除可靠性;
- 对强一致性要求高的系统,推荐使用Canal+Kafka的订阅方案;
- 合理设计Redis Key命名规范,如
{业务}:{实体}:{ID}(例:product:detail:1001);
- 监控关键指标:缓存命中率、回源QPS、删除失败率、TTL分布等。
最终理念:
缓存的本质是用空间换时间,而一致性则是用复杂度换准确性。在实际工程中,你应该根据业务特点权衡选择,构建稳定高效的查询加速体系。
对于大多数互联网业务,“先更DB后删缓存 + TTL兜底”已是足够稳健的选择;而对于资金、库存等关键领域,则应不惜代价去追求更高的一致性保障。
所有技术决策,最终服务于业务目标。没有最好的方案,只有最适合的方案。
在技术社区中,关于数据库/中间件/技术栈的选型和实践讨论一直都非常热烈,但核心永远落在业务需求上。同样,深入理解后端 & 架构领域的分布式系统与高并发设计,也是构建稳健服务的基石。如果你对更多技术细节感兴趣,欢迎常来云栈社区和志同道合的开发者们一起交流探讨。
 发表于 2026-4-25 08:13:42
|
查看: 224|
回复: 0
发表于 2026-4-25 08:13:42
|
查看: 224|
回复: 0
