每一次 LLM 调用都是无状态的。模型读上下文窗口,生成响应然后忘掉一切。这对单轮问答没问题。但对需要连续交互的智能体(Agent)而言,这就是致命的短板。你的 Agent 是否遇到过这些问题?
- 保持连续性——“我昨天刚跟人说过这件事,为什么还要再解释一遍?”
- 从交互中学习——Agent 应当知道这个用户的账户、历史问题、首选语言。
- 积累组织知识——哪些解决路径能关闭工单,哪些意图预示需要升级处理。
- 从崩溃中恢复——一个外呼 20 万通电话的批处理 Agent,失败后必须能从呼叫者 #87,431 续上,而不是从头重启。
我们的第一反应可能是把整段对话历史都塞进上下文窗口,但这在生产环境中会带来一系列问题:
- 成本高昂:满上下文加载在特定基准测试(如 LOCOMO)上或许能拿到 72.9% 的准确率,但代价是 p95 延迟高达 17.12 秒,token 开销翻 14 倍,在实时场景中根本不可用。
- 质量下降:上下文窗口越满,模型对早期指令的注意力就越低,埋在中间的细节开始被忽略,这是长上下文 LLM 一个被反复记录过的弱点。
- 误差累积:研究(如 Databricks 2026 年 4 月的报告)发现,Agent 会引用之前运行中错误的输出,并以更高的信心复用,没有经过策展的记忆会把一次性错误固化成永久谎言。
下图清晰地展示了这一矛盾:橙色线代表 Agent 需要记住的内容,蓝色线代表记忆系统实际能交付的内容。两者之间的裂缝正是生产级 Agent 失效的地方;虽然裂缝在收窄,但从未完全合上。
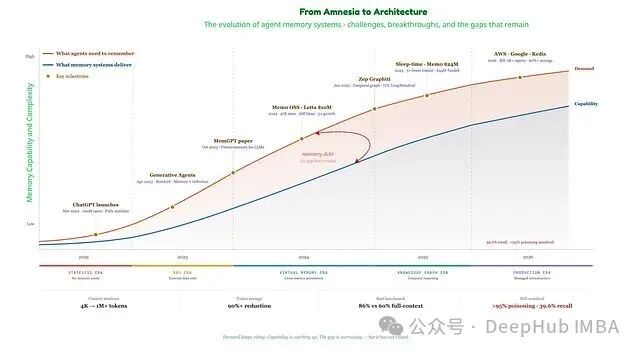
因此,更优的策略是:从对话中抽取重要的部分,加以整合后存储到合适的后端,按需进行智能检索,并主动遗忘陈旧内容。用牺牲少量准确率,换来 12 倍的延迟下降和 10 倍的成本下降,这种工程取舍正是 demo 原型与能交付给付费用户的成熟系统之间的分界线。
将10倍成本差距具体化:一个中等规模的 SaaS,每月 1000 万次 Agent 调用,若采用满上下文方案,仅 LLM token 成本就大约要 100 万美元(按每次调用约 26K token,GPT-5 混合价估算);同样的工作负载若换成选择性记忆方案,成本会骤降至约 10 万美元。这往往是决定一个产品“业务可行”还是“在用户规模增长前就被成本压垮”的关键。
Agent 记忆的四种类型
人类记忆不是单一类型的,AI Agent 的记忆也不应该是。《Memory in the Age of AI Agents》及更早由 CoALA 论文(TMLR 2024)形式化的框架指出,为 LLM(如 GPT-3.5)增加一层认知架构,可以将其在编码基准上的成绩从 48% 提升到 95%。
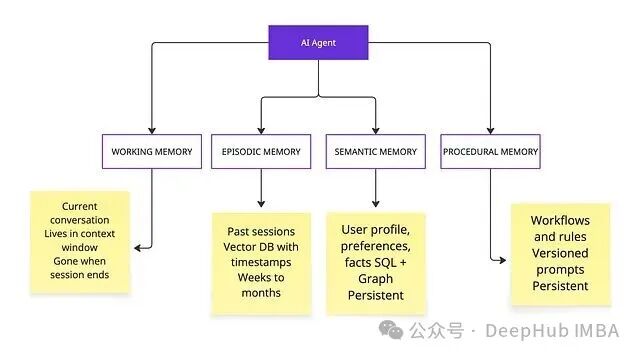
生产级 Agent 的记忆系统通常包含四种类型,它们各自有独立的后端、生命周期与失效模式。
-
工作记忆:Agent 当前正在思考的内容。
- 存放什么:当前对话、工具调用结果、中间推理链。
- 存在哪里:上下文窗口内部,即当前的 prompt 本身。
- 生命周期:仅限当前会话。
- 典型失效:窗口填满,模型丢失更早的指令。
-
情景记忆:Agent 的过往交互日记。
- 存放什么:过往具体会话的记录,附带时间戳、参与者、结果等元数据。
- 存在哪里:带元数据过滤能力的向量数据库(如 Qdrant、Pinecone、pgvector)。
- 生命周期:数周到数月,通常伴有衰减机制。
- 典型失效:检索到不相关的旧情景、发生时间混淆。
-
语义记忆:从原始交互中蒸馏出的抽象事实与关系。
- 存放什么:用户画像、偏好、实体关系、从具体情景中抽象出的可复用知识。
- 存在哪里:向量数据库、知识图谱(如 Neo4j、Apache AGE)或混合存储。
- 生命周期:持久化,但需要冲突解决机制。
- 典型失效:事实过时、条目相互矛盾、随着陈旧信息堆积导致渐进式腐化。
-
过程记忆:Agent 学到的行为模式与规则。
- 存放什么:工作流、决策规则、系统 prompt 模板、few-shot 示例。
- 存在哪里:配置文件、版本化的 prompt 模板存储、数据库。
- 生命周期:持久化,但需版本控制。
- 典型失效:业务政策已变更,但过程记忆还停留在旧版本,未被更新。
这四种记忆类型是协同工作的,而非独立存在。一个真实的 Agent 会同时调用它们:工作记忆承载当前对话流;情景记忆召回相关的过往会话片段;语义记忆加载用户画像与稳定偏好;过程记忆则触发正确的工作流。目前,并非所有框架都完全覆盖这四种类型——情景记忆是基本盘,语义图谱在逐步完善,而过程记忆仍处于前沿探索阶段。
五阶段记忆流水线
无论是学术研究还是生产框架,普遍采用一个五阶段的记忆流水线。每个阶段都在解决上一阶段引入的问题,跳过任何一步都会导致不同形式的故障——原始噪声、逻辑矛盾、响应延迟、时间漂移,或是无声的系统腐化。
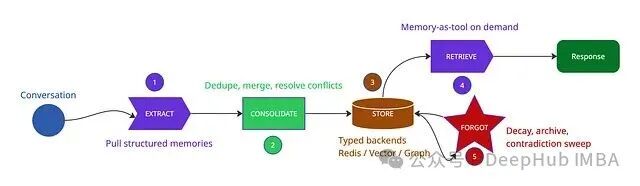
- 阶段 1 抽取:把原始对话转换成结构化的记忆记录。
- 阶段 2 整合:对新记忆进行去重、合并,并与已有记忆解决冲突。
- 阶段 3 存储:将每种记忆类型路由到最合适的后端存储。
- 阶段 4 检索:让 Agent 能够按需拉取记忆,而不是每轮对话都强制检索。
- 阶段 5 遗忘:主动衰减、归档、裁剪记忆,防止存储膨胀和检索质量下降。
阶段 1 抽取:从对话到结构化知识
抽取阶段的核心任务,是使用一个 LLM 来阅读对话,将每一条陈述归类为五种类型之一:事实、偏好、事件、过程或噪声(直接丢弃)。每一条被提取出的记忆记录都附带四个关键属性:置信度分数、关联实体、时间戳以及来源(用户陈述、Agent 推断或工具返回)。
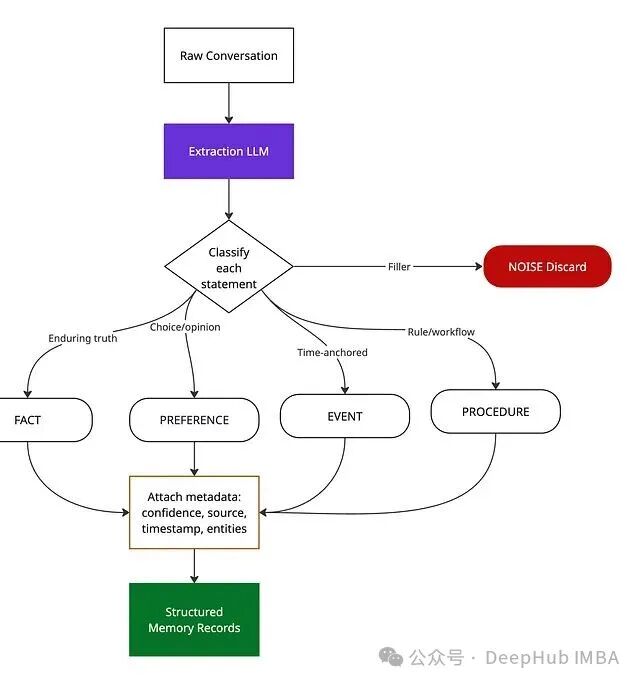
何时进行抽取?
- 同步(每轮):适用于轻量级的事实检测,每轮增加 100–300ms 延迟,仅对高价值信息使用。
- 异步(会话后):进行深度整合、情景摘要和图谱更新,对对话内的实时延迟零影响。
- 计划任务(Cron):执行矛盾扫描、衰减计算、索引重建等非高峰期的批处理作业。
目前的主流趋势是异步抽取。例如,Mem0 v1.0.0 将 async_mode=True 设为默认,因为同步写入会阻塞响应流水线,增加用户可感知的延迟。AWS AgentCore 的报告也显示,其抽取过程通常在会话结束后 20–40 秒内异步完成。
阶段 2 整合:真正困难的部分
新提取的记忆经常与已存储的内容重复或冲突。整合阶段正是区分生产级记忆系统与简单“只追加”式存储的关键。
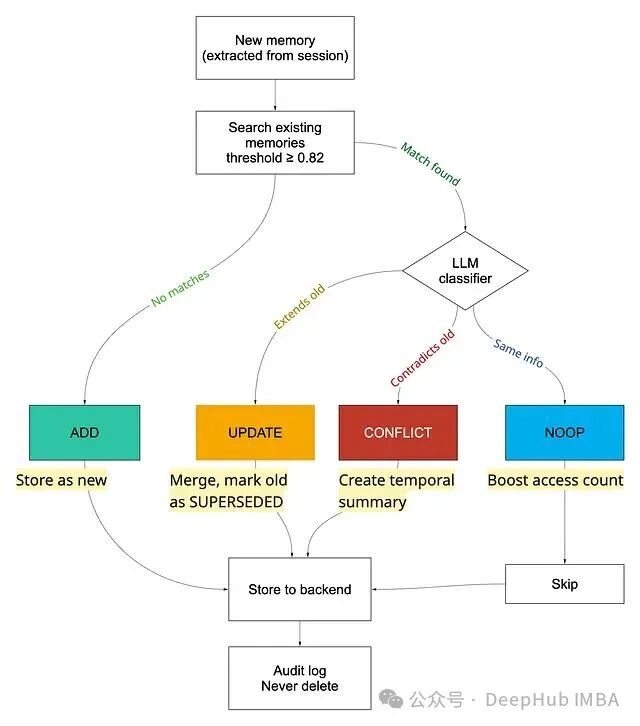
整合流程通常包含三步:
- 搜索匹配:在同一用户、同一记忆类型下,搜索已存储的最接近匹配(通常使用余弦相似度,阈值约 0.82)。
- LLM 分类:由一个 LLM 判定新记忆与旧记忆的关系:
- ADD:独立的新信息,单独存储。
- NOOP:完全冗余,跳过存储,但提升旧记忆的访问计数。
- UPDATE:扩展或取代旧记忆,合并后将旧记忆标记为
SUPERSEDED。
- CONFLICT:与已有记忆矛盾,创建时间感知的摘要,同时保留新旧版本。
- 审计记录:写入审计日志。过时的记忆被标记而非删除,以便追踪系统在任何时间点的认知状态。
冲突解决是重中之重。切勿直接覆盖,这会抹除历史,使系统变得不可审计。AWS AgentCore 将过时记忆标记为 INVALID;Zep 的 Graphiti 则引入了双时态建模——为每个事实记录两个时间戳:事实在现实世界中成立的时间,以及 Agent 获知该事实的时间。
阶段 3 存储:类型化的数据需要类型化的后端
将所有记忆类型都塞进同一个向量数据库,是最常见的错误之一。不同的记忆类型对存储的读写模式、查询需求截然不同。
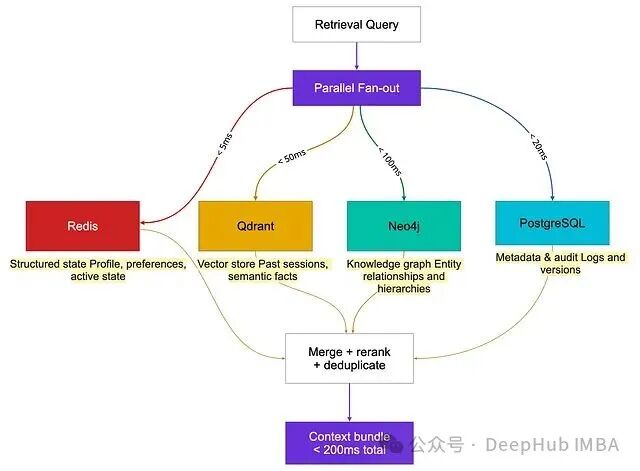
四种记忆类型对应四种推荐的后端:
- 结构化状态(Redis / PostgreSQL JSONB):存储稳定的用户画像和活跃会话状态。支持精确的 key-value 查找,延迟小于 5ms,检索结果零噪声。
- 向量存储(Qdrant, Pinecone, pgvector):存储需要模糊匹配的语义事实和情景记忆。支持带元数据过滤的相似度搜索,延迟小于 50ms。
- 知识图谱(Neo4j, Apache AGE):存储需要多跳遍历的复杂实体关系。查询延迟通常在 100ms 以内。Zep 的 Graphiti 在此类查询上达到了 94.8% 的准确率。
- 元数据与审计(PostgreSQL):存储时间戳、来源追踪、访问计数和完整的审计轨迹。
核心架构原则是:查询应并行扇出到各个后端,而非串行执行,并将总的检索预算控制在 200ms 以内。
阶段 4 检索:将记忆视为工具,而非固定流水线步骤
最常见的反模式是每轮对话都自动触发全量检索。在生产环境中,通行做法是 memory-as-a-tool(记忆即工具)。
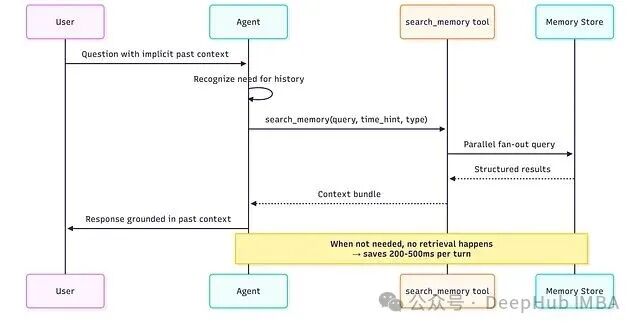
即向 Agent 提供一个显式的搜索函数(如 search_memory),由 Agent 自己判断何时需要召回历史记忆,而不是由编排器(orchestrator)强制每轮检索。这样,在那些不需要历史上下文的轮次中,每轮可节省 200–500ms 的延迟。Mem0 的选择性检索方案报告显示,其中位搜索延迟为 0.20 秒、准确率 66.9%,而标准每轮 RAG 的延迟为 0.70 秒、准确率仅 61.0%。
两种主流风格:
- 被动检索(Mem0 风格):系统在后台自动抽取和存储记忆,Agent 按需调用搜索工具。框架无关,易于集成。
- 自编辑式(Leta 风格):Agent 通过显式函数调用(如
core_memory_append, archival_memory_search)管理自己的记忆,将上下文窗口视为 RAM,外部存储视为磁盘。更灵活,但每个记忆操作都消耗额外 token。
阶段 5 遗忘:最容易被忽略却至关重要的环节
记忆应当是一种导向机制,而不是囤积者的阁楼。
如果没有主动遗忘,系统最终会因存储膨胀而检索变慢,无关或过时的事实将主导结果,导致 Agent 运行越久性能越差。
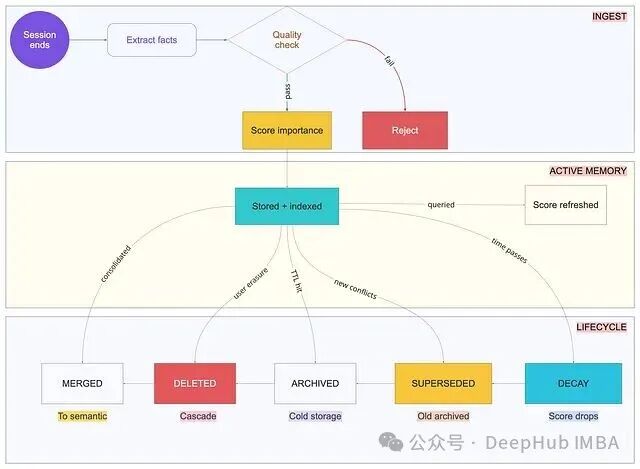
三种必须同时工作的遗忘机制:
- 基于时间的衰减:使用指数衰减函数降低老旧、低频访问记忆的检索分数(半衰期通常设为70天)。不删除,仅降低其被检索到的概率。
- 基于 TTL 的归档:将超过一定时间(如事件90天,事实180天)未访问的记忆移至冷存储。仍支持显式查询,但默认检索不包含它们。
- 矛盾扫描:周期性扫描活跃记忆中是否存在冲突,并触发整合流程。缺少此环节,Agent 可能被困在过时与当前偏好之间。
流水线定义了记忆系统需要做什么,而设计模式则指导你如何根据具体用例将其组装起来。
四种可行的设计模式
在生产实践中,有四种经过验证的记忆系统设计模式。它们主要在三个维度上有所区别:Agent 自我管理记忆的程度、存储的历史量、以及检索的粒度。
经验法则:从模式 2 开始,它能解决 80% 的用例;只有在需求明确要求时,才增加复杂度。

模式 1:分层记忆(Leta / MemGPT)
核心思路:将有限的上下文窗口视为高速缓存(类似 RAM),将外部数据库视为大容量、可搜索的存储(类似磁盘)。Agent 通过函数调用在两者之间主动搬运信息。
适用场景:长期陪伴型 Agent,如心理疗愈机器人、长时间运行的编码助手。代价是较高的架构锁定性和约 10–15% 的 token 预算用于记忆管理本身。
模式 2:结构化状态 + 语义搜索(80/20 法则)
核心思路:使用 Redis/PostgreSQL 等键值或关系型数据库处理 80% 需要精确匹配的查询(零延迟、完美准确率),剩余 20% 需要模糊匹配的查询则回退到向量搜索。
适用场景:绝大多数项目的起点。优势是结果确定性强,没有嵌入质量导致的漂移问题。代价是需要预先设计好明确的数据模式(Schema)。
模式 3:图谱记忆(Zep / Graphiti)
核心思路:以实体为节点,关系为边来组织记忆,并支持沿连接链进行多跳推理。关键创新是“双时态”边,为事实记录有效时间窗口。
适用场景:企业知识管理、合规要求高的复杂工作流。Zep 在相关基准上表现出色。代价是运维复杂度显著更高。
模式 4:检查点记忆(崩溃恢复)
核心思路:在每次重要动作后保存完整状态检查点。通常包含三层:操作日志(原始事件)、状态记忆(当前任务进度)、长期记忆(提炼的经验)。
适用场景:长时间运行的批处理任务、CI/CD 流水线、无人值守自动化。崩溃后可从最新检查点恢复。代价是写入密集,需要高性能持久化存储。
选择正确的模式是成功的一半,另一半则是避免那些悄然而至的反模式。
生产环境中常见的六个问题
失效的记忆系统,其根源通常不出以下六类。它们往往相互关联,一次部署就可能引入多个问题。这一切都可追溯到一个根本错误:将记忆视为一个无脑的“写入-检索”桶,而非一个经过策展、具备时间感知和来源追踪的系统。
这六个问题可分为三类:
- 保留太多:囤积者、单体、吸血鬼,导致系统臃肿,检索结果噪音大于信号。
- 信错对象:时间旅行者、回音室, silently 污染 Agent 的输出。
- 从不闭环:失忆循环,使得前期构建的记忆能力无法产生实际价值。
1. 囤积者(从不遗忘)
症状:向量存储无限增长。运行上万个会话后,检索结果混杂着数月前相互矛盾的事实和最新更新,导致 Agent 困惑。
根因:没有设置 TTL、没有衰减机制、没有定期的矛盾扫描。
修复:实施 TTL 自动归档、近因衰减算法,并建立定期矛盾扫描任务。在上线前就设计好“删除路径”。
2. 吸血鬼(每轮自动检索)
症状:无论本轮对话是否需要历史,都触发全量检索,每轮平白增加 200–500ms 延迟和数百个无关 token。
根因:“以防万一”式的检索策略,将筛选负担抛给模型。
修复:采用 memory-as-a-tool 模式,将召回时机交给 Agent 决定。对必须的主动检索,严格限制返回 token 数量(如 500 以内)。
3. 单体(所有东西堆一个库)
症状:用户画像、历史对话、工作流配置全部存入同一个向量库。一次查询返回杂乱无章、类型混合的结果。
根因:没有按记忆类型进行存储隔离。
修复:按记忆类型拆分存储,使用独立的 Schema。即使在同一个 PostgreSQL 实例中,也应用不同的表来逻辑隔离。
4. 时间旅行者(没有时间感知)
症状:Agent 依据一个已过时的旧偏好(如用户去年的风险承受能力)做出行动建议。
根因:相似度搜索只匹配内容文本,而不考虑时间新鲜度,旧记录因表述更匹配而排名靠前。
修复:为每条记忆存储 created_at 和 valid_until 时间戳,在检索时给近期记忆更高权重,并为冲突事实创建时间感知摘要而非直接覆盖。
5. 回音室(跨 Agent 污染)
症状:Agent A 将某个推断(可能为幻觉)写入共享记忆,Agent B 将其读取为事实并据此行动,使幻觉被“坐实”。
根因:记忆没有来源标签,无法区分“用户陈述”、“工具返回”和“Agent 推断”。
修复:为每条记忆强制附加来源和置信度标签,并建立信任层级:用户陈述 > 工具返回 > Agent 推断。
6. 失忆循环(检索-遗忘-检索)
症状:同一段记忆在同一会话中被反复检索、放入提示词,但 Agent 从未“吸收”它,导致 token 成本螺旋上升而效果不变。
根因:系统没有记录某条记忆是否已在当前会话中被应用过。
修复:在记忆元数据中追踪“已应用于会话 X”的状态,在同一会话内跳过对已应用记忆的重复检索。
完整的生产架构示例
让我们以一个最复杂的场景——实时语音客服 Agent 为例,构建一个完整的生产架构。该 Agent 必须在 200ms 内响应,并携带用户的历史上下文(工单、账户状态、偏好)。
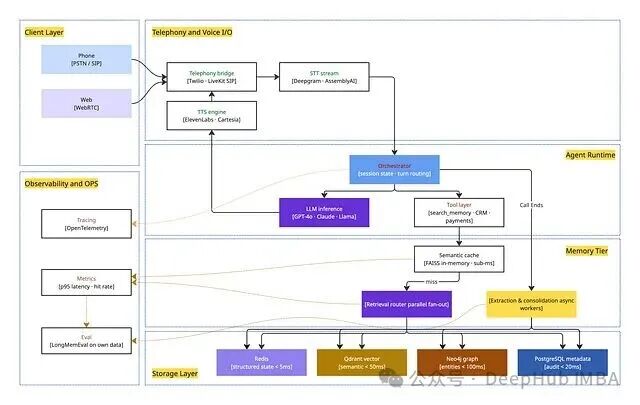
该架构的核心特点是记忆层与 Agent 运行时分离,同一套记忆服务可以支撑销售、客服等多个不同的 Agent。存储层是类型化的:Redis(状态)、Qdrant(向量)、Neo4j(图谱)、PostgreSQL(审计)。可观测性(指标、追踪)被作为独立的一层融入设计。
运行时分为三个关键区域,以严格满足 200ms 的响应预算:
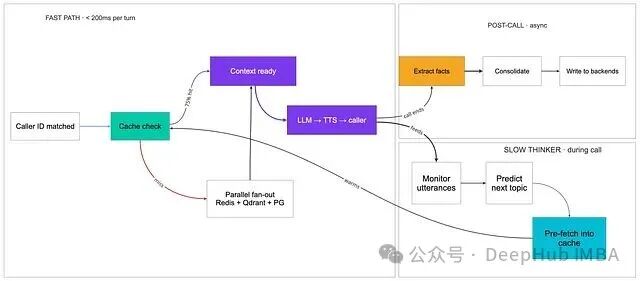
- 快速路径(<200ms):处理来电者 ID 匹配、缓存检查、LLM 推理和 TTS 合成。任何更慢的操作都不允许进入此路径。
- 慢思考者(通话期间):在后台实时分析对话流,预测用户下一个可能的问题,并预取相关记忆到缓存中,提升下一轮缓存的命中率。
- 通话后处理(完全异步):执行深度的记忆抽取、整合和存储写入,绝不阻塞实时响应。
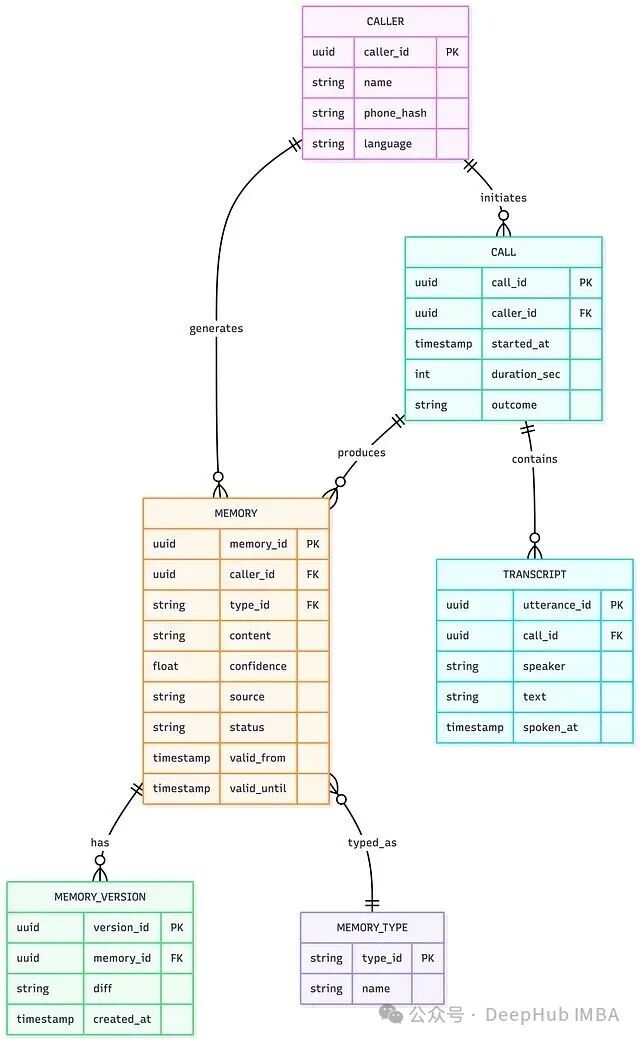
其核心数据模型围绕呼叫者、通话、记忆、转录等实体构建,注意使用 phone_hash 而非原始号码来保护用户隐私。
代码示例
整个记忆集成的核心逻辑可以非常简洁,主要挂载在几个生命周期钩子上:
class VoiceAgent:
async def on_call_start(self, caller_id):
# 1. 尝试从缓存获取上下文
ctx = await self.cache.get(caller_id) \
or await self.memory.retrieve(user_id=caller_id, query="recent calls")
# 2. 启动后台预取任务
self.slow_thinker.start(caller_id, ctx)
return ctx
async def on_utterance(self, caller_id, utterance, ctx):
# 基于当前上下文生成响应
response = await self.llm.generate(system=ctx, message=utterance)
# 通知后台思考器,用于预测下一轮
self.slow_thinker.observe(caller_id, utterance, response.text)
return response.text
async def on_call_end(self, caller_id, transcript):
# 异步执行记忆抽取与整合,不阻塞
asyncio.create_task(self.extractor.extract_and_consolidate(caller_id, transcript))
总结
当前,基础大模型在原始能力上正趋于收敛。真正能将生产级 Agent 与演示原型区分开来的,往往是记忆系统的成熟度,而非模型本身。
实施建议:
- 从简开始:优先采用模式 2(结构化状态 + 向量搜索),它足以应对 80% 的用例。
- 设计遗忘:在系统上线前,就明确设计好记忆的衰减、归档和删除路径。
- 检索即工具:将记忆检索的主动权交给 Agent,而非做成每轮的固定开销。
- 监控关键指标:密切关注检索延迟(p95)、缓存命中率、记忆精确度和新记忆写入耗时。没有这些数据,你就是在盲目优化。
当然,并非每个 Agent 都需要如此复杂的记忆系统。对于处理单轮、无状态查询的 Agent,这可能属于过度工程。记忆,本质上是 Agent 实现连续性、个性化和可信赖交互的基石。
本文探讨的架构与模式,在 云栈社区 的「人工智能」和「后端架构」等板块有更多深入的讨论与资源分享,欢迎开发者们进一步交流。
 发表于 2026-4-23 03:41:13
|
查看: 202|
回复: 0
发表于 2026-4-23 03:41:13
|
查看: 202|
回复: 0
