今年以来,OpenClaw、Hermes 这类 AI Agent 工具接连爆火,很多人都想部署体验一番。
但很快大家就发现,使用云端 API 的 Token 消耗速度快得吓人。仅仅是几次对话、简单设置几个任务,一天就可能烧掉几十块钱,成本压力不小。
于是,越来越多开发者将目光投向了本地模型部署。这种方式既能节省开支,又能离线使用,数据隐私也更有保障。
然而,真到了动手的时候,问题就来了。面对 Hugging Face 上成千上万的开源模型,根本无从下手。即便好不容易选好一个模型下载到本地,却很可能因为电脑配置不足而无法流畅运行,白白浪费了时间和精力。
最近在 GitHub 上发现了一款非常实用的开源小工具——llmfit。它专为解决本地大模型运行的硬件匹配问题而生,只需运行一条命令,就能帮你找出哪些大模型适合在你当前的电脑上本地部署并流畅运行。
整个工具采用全键盘操作的 TUI 界面,使用方向键即可上下浏览,轻量且直观。界面顶部会自动显示检测到的 CPU、内存、显卡型号和显存等硬件信息。
中间是一个可滚动的模型表格,默认按综合评分从高到低排序。每一行都清晰地标注了模型的预估生成速度、推荐量化等级、内存占用百分比以及系统适配等级。
llmfit 并非简单地根据电脑配置粗暴判断“能不能装下”,其背后内置了一套四维打分系统。它会从质量、速度、适配度、上下文长度四个维度对每个模型进行评分,帮助我们做出更明智的筛选。
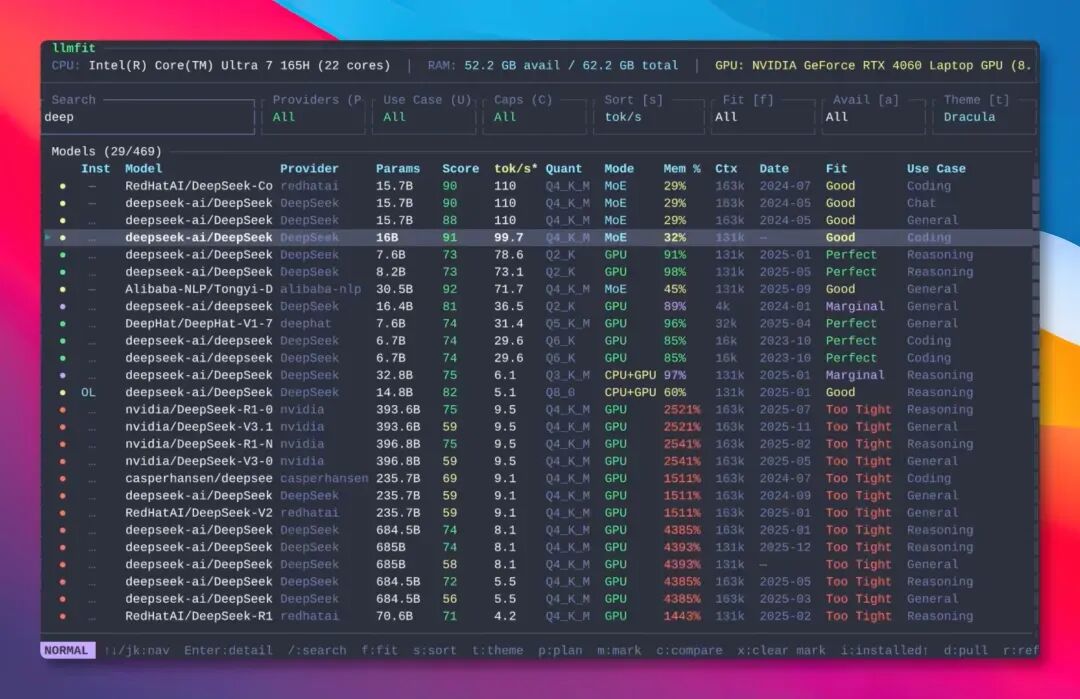
例如,同样是 7B 参数量的模型,用于编程场景和对话场景时,各项评分的权重会有所不同。编程场景更看重模型质量与上下文支持能力,而对话场景则更注重响应速度。这种设计思路非常贴近实际的使用体验。
更难得的是,它的速度预估相当靠谱。作者为大约 80 款主流显卡建立了真实的性能映射数据库,覆盖了 NVIDIA、AMD 和 Apple Silicon。因此,每个模型显示的“每秒生成 Token 数(tok/s)”,并非随意估算,而是有实打实的数据作为支撑。
除此之外,llmfit 还提供了一个非常实用的“硬件模拟”功能。按下 S 键,会弹出一个模拟配置窗口。
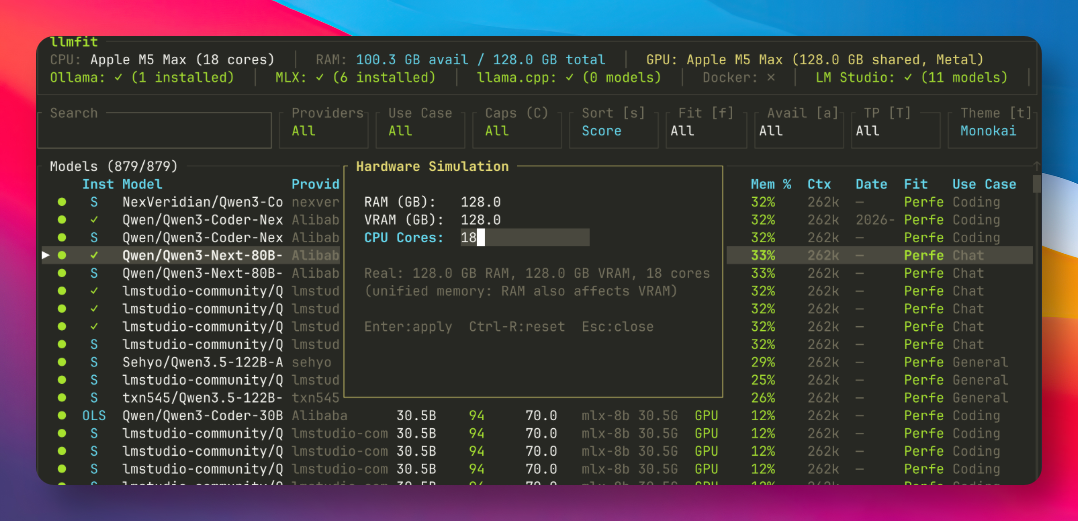
你可以在这里自由修改内存大小、显存容量和 CPU 核心数等虚拟硬件配置。点击应用后,整张模型表格会立即按照模拟后的硬件重新计算评分和适配等级。
这个功能对于计划升级电脑硬件的朋友来说尤其有用,可以提前了解心仪的模型需要什么样的配置才能满足,避免盲目升级。
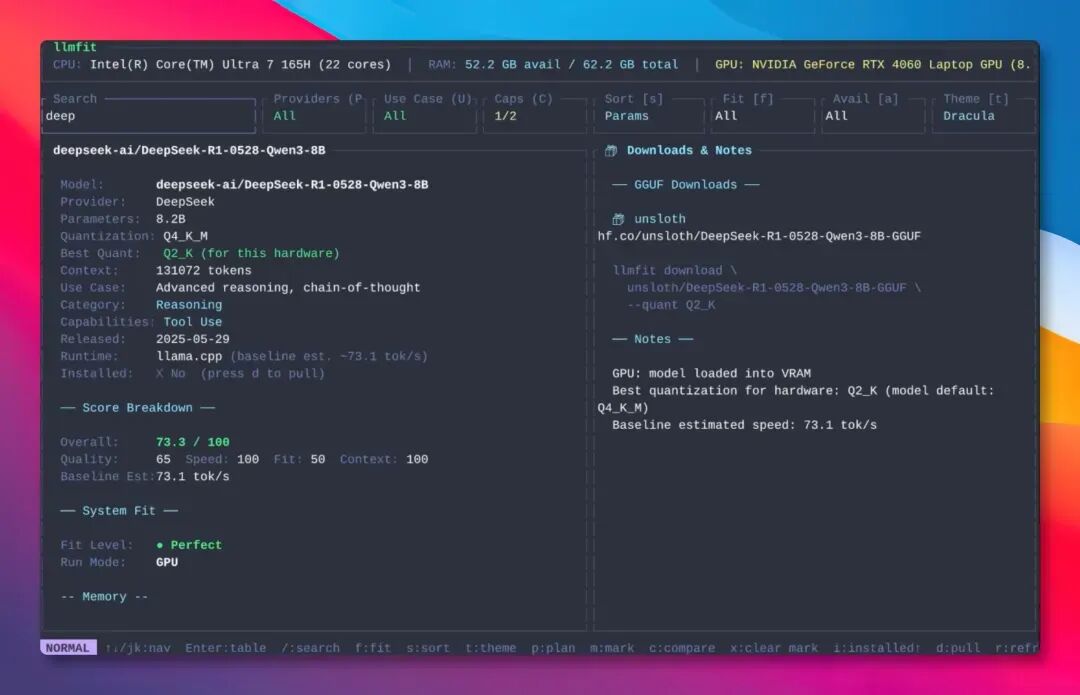
那么,当我们通过筛选找到合适的模型后,该如何部署呢?llmfit 提供了无缝衔接的体验。只需选中目标模型,按下 d 键,它就能直接调用对应的后端工具将模型下载并部署好。
目前,llmfit 已经支持对接 Ollama、llama.cpp、LM Studio、MLX 和 VLLM 这五大主流本地模型运行工具。
想要使用 llmfit 非常简单,它支持 macOS、Windows 和 Linux 系统,并提供了多种安装方式,包括一键安装脚本。
相关的安装命令如下,你可以根据自己所用的系统和包管理器自由选择:
# macOS / Linux (使用 Homebrew)
brew install llmfit
# Windows (使用 Scoop)
scoop install llmfit
# 通用一键脚本
curl -fsSL https://llmfit.axjns.dev/install.sh | sh
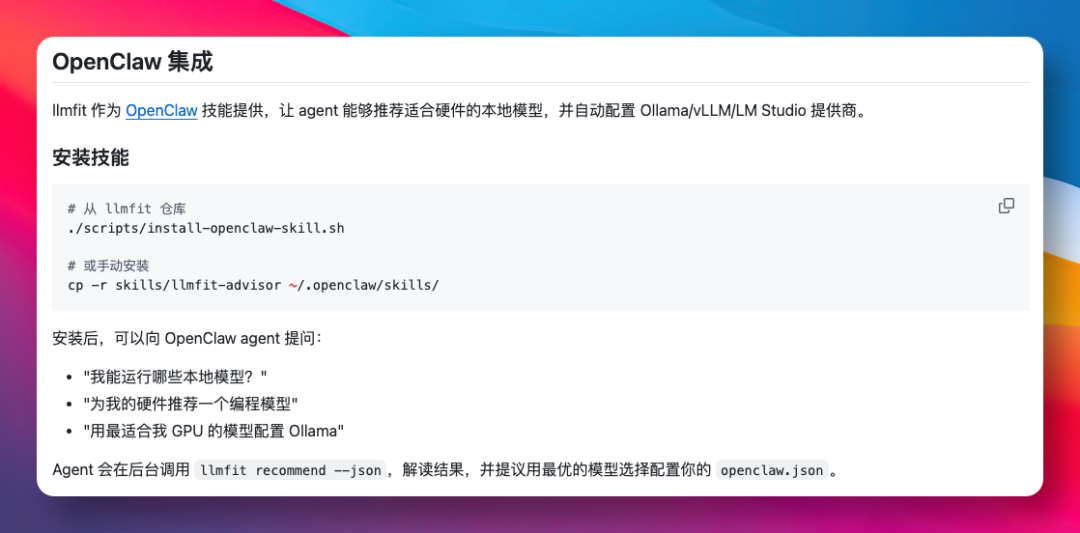
值得一提的是,llmfit 还以 OpenClaw Skill 的形式提供了更深度的集成。只需在项目仓库中执行一条安装脚本,就能将其添加为 Agent 的一个技能。
./scripts/install-openclaw-skill.sh
安装完成后,你就可以直接在 OpenClaw 中向 Agent 提问,例如:“我的电脑能跑哪些本地模型?” 或 “为我的硬件推荐一个编程模型”。Agent 会在后台调用 llmfit recommend --json,解读结果,并主动为你提议最优的模型选择和配置方案。从硬件检测、模型选型到后端环境配置,整个链路几乎无需手动干预。
写在最后
随着 OpenClaw、Hermes 等 AI Agent 工具的流行,本地部署模型的需求持续增长。Ollama、llama.cpp 这类工具已经解决了“如何在本地部署模型”的问题。
但对于大多数用户而言,门槛从一开始就存在:我该选哪个模型?我的电脑到底能不能跑得动?
llmfit 的出现,正好填补了这个关键缺口。它让本地大模型部署从少数极客的“黑科技”,变成了普通开发者也能轻松上手的日常操作。当算力真正回到我们每个人手中时,AI 的潜力才可能被更自由、更个性化地发掘。
如果你也在为本地模型部署的选择而烦恼,不妨试试这个工具。在 云栈社区 的开发者圈子里,分享和讨论这类提升效率的开源工具,总能带来新的灵感和解决方案。
GitHub 项目地址:https://github.com/AlexsJones/llmfit
 发表于 2026-4-23 01:57:45
|
查看: 192|
回复: 0
发表于 2026-4-23 01:57:45
|
查看: 192|
回复: 0
