当前AI与智能体(Agent)是技术热点,但实际体验过的开发者都知道,让AI Agent有效访问网络信息是一大挑战。绝大多数网站并未开放API,传统的无头浏览器方案容易被反爬机制识别,而自行编写爬虫则需要反复处理登录、鉴权等一系列繁琐问题。
最近在GitHub上发现一个名为 bb-browser(昵称“坏孩子浏览器”)的开源项目,它提供了一种新颖的思路:直接复用用户真实浏览器中已存在的登录状态,将浏览器本身当作一个API来使用,从而绕过复杂的认证流程。
项目核心思路
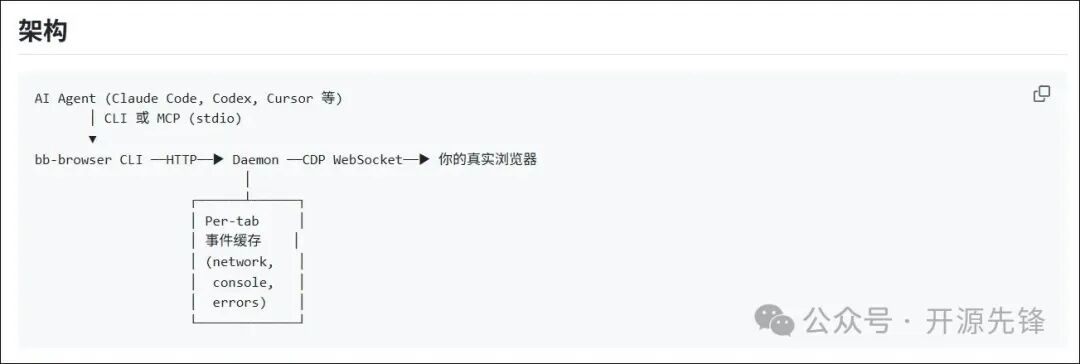
bb-browser 是一个为AI Agent和开发者设计的强大浏览器自动化工具。其核心在于通过Chrome DevTools Protocol (CDP) 连接用户正在使用的真实Chrome浏览器,直接利用该浏览器标签页中已有的Cookie、LocalStorage等登录态进行操作。
这意味着,只要你已经在Chrome中登录了微博、知乎、GitHub等网站,bb-browser 就能让AI Agent直接以“你”的身份去访问这些网站,无需额外配置密钥或模拟登录过程。

该项目通过一个常驻的守护进程(Daemon)连接浏览器,并将浏览器操作封装成简洁的CLI命令或MCP(Model Context Protocol)服务,供AI Agent调用。
与主流方案的对比
为了更清晰地理解其优势,可以看下它与常见工具的差异:
|
Playwright / Selenium |
爬虫库 (如 requests) |
bb-browser |
| 浏览器 |
无头、隔离的仿真环境 |
没有浏览器 |
你的真实 Chrome |
| 登录态 |
没有,需要脚本重新登录 |
需要手动获取并维护Cookie |
已经在了(复用现有登录态) |
| 反爬检测 |
容易被识别为自动化脚本 |
持续的“猫鼠游戏” |
无法检测 — 它就是真实用户行为 |
| 复杂鉴权 |
难以复制(如动态Token) |
需要逆向接口 |
页面自己处理(由真实浏览器执行) |
目前,这个创新的开源项目在GitHub上已经获得了超过4.5k的Star,受到了社区的广泛关注。
主要功能特性
- 真实登录态复用:直接使用已登录浏览器的会话,绕过重新登录、Cookie导出等步骤,天然规避复杂鉴权与反爬检测。
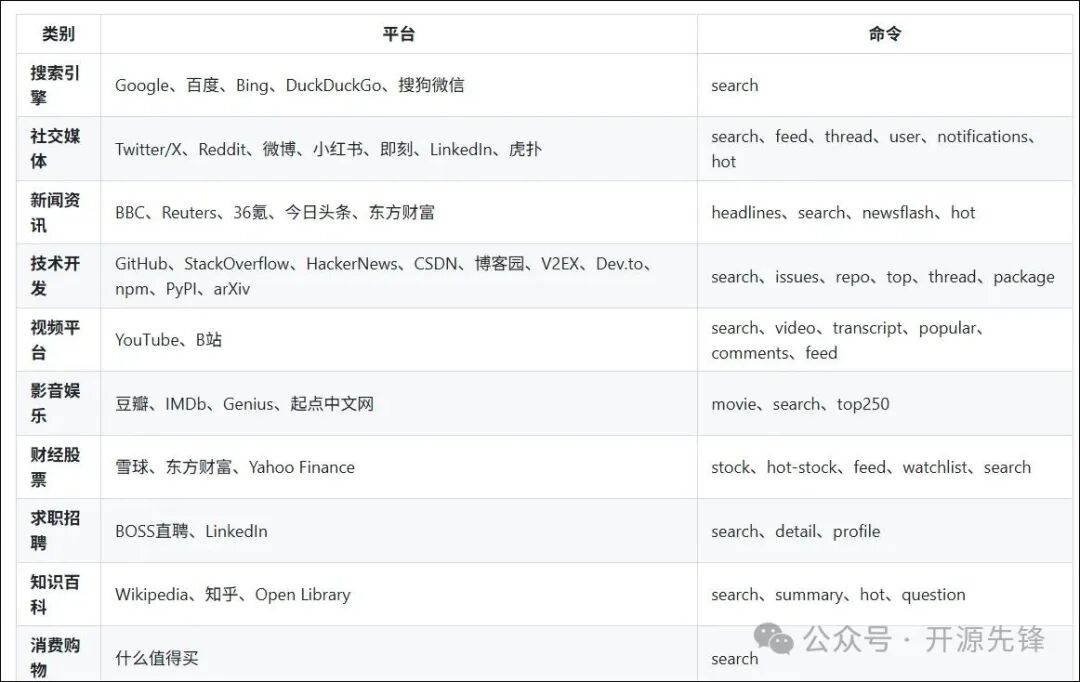
- 丰富的预置命令:内置支持36个主流平台、103条命令,覆盖社交媒体、技术开发、财经资讯、视频、知识百科等多个场景。
- 多模式接入:支持命令行直接调用,也提供MCP模式,可无缝接入Claude Code、Cursor等AI代码编辑器。
- 完整的浏览器自动化:支持打开网页、点击元素、输入文本、执行JavaScript、网络抓包、截图等原生浏览器操作。
- 社区驱动生态:适配器(Adapter)由社区共同维护,AI Agent甚至能在10分钟内自动逆向一个新网站并生成可用的适配命令。
- 结构化输出:所有命令默认返回结构化的JSON数据,支持使用
jq 进行过滤,并支持多标签页并发操作,便于脚本和Agent进行后续处理。
快速开始
安装
首先,确保你的系统已安装 Node.js 18+ 版本。然后通过npm全局安装:
npm install -g bb-browser
基础使用
安装完成后,可以按照以下步骤体验:
- 更新社区适配器库:获取最新的网站命令支持。
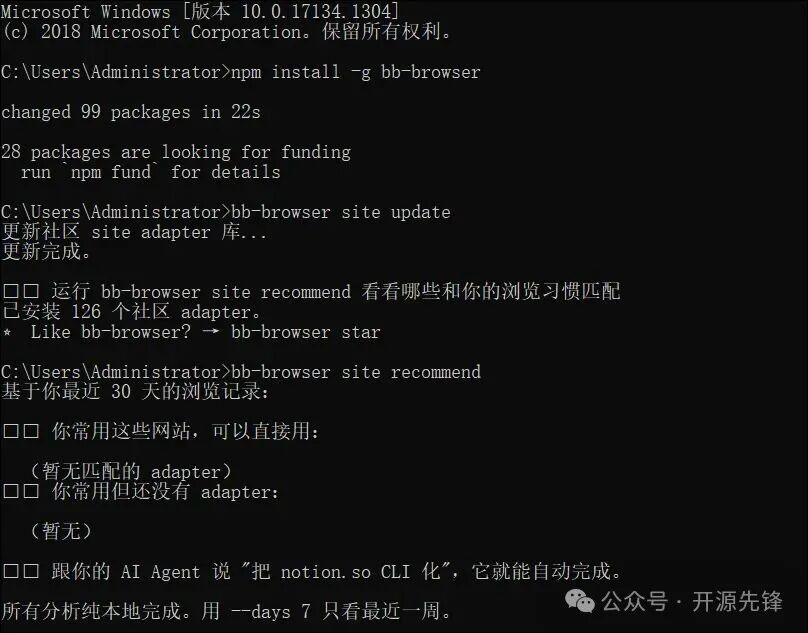
bb-browser site update
- 查看个性化推荐:工具会分析你的浏览器历史,推荐你可能需要的适配器。
bb-browser site recommend
- 执行第一个命令:例如,获取知乎热榜。
bb-browser site zhihu/hot

常见问题:如果执行命令时遇到类似以下错误,提示Chrome未连接:

错误:Daemon HTTP 503: {"id":"8d35696c-5028-4466-86c9-3ca5871d9d9e","success":false,"error":"Chrome not connected (CDP at 127.0.0.1:9222)","reason":"CDP WebSocket closed unexpectedly","hint":"Make sure Chrome is running. Try: bb-browser daemon shutdown && bb-browser tab list"}
只需执行以下命令重启守护进程,然后重试即可:
bb-browser daemon shutdown
进阶使用模式
- OpenClaw模式:一种无需安装浏览器扩展的轻量级模式。
bb-browser site reddit/hot --openclaw
- MCP模式接入AI编辑器:在AI编辑器(如Cursor)的配置文件中添加MCP服务器设置,即可让AI直接调用浏览器能力。
{
"mcpServers": {
"bb-browser": {
"command": "npx",
"args": ["-y", "bb-browser", "--mcp"]
}
}
}
如何扩展支持新网站?
如果内置的103个命令尚未覆盖你需要的网站,bb-browser 提供了强大的扩展能力。核心在于其“适配器”概念。
运行 bb-browser guide 可以查看完整的适配器开发教程。更酷的是,你可以直接告诉你的AI Agent:“帮我把XX网站CLI化”。AI会阅读指南,利用 bb-browser 的抓包功能逆向分析网站接口,自动编写适配器代码并进行测试,最终可以向社区仓库提交Pull Request。整个过程高度自动化。
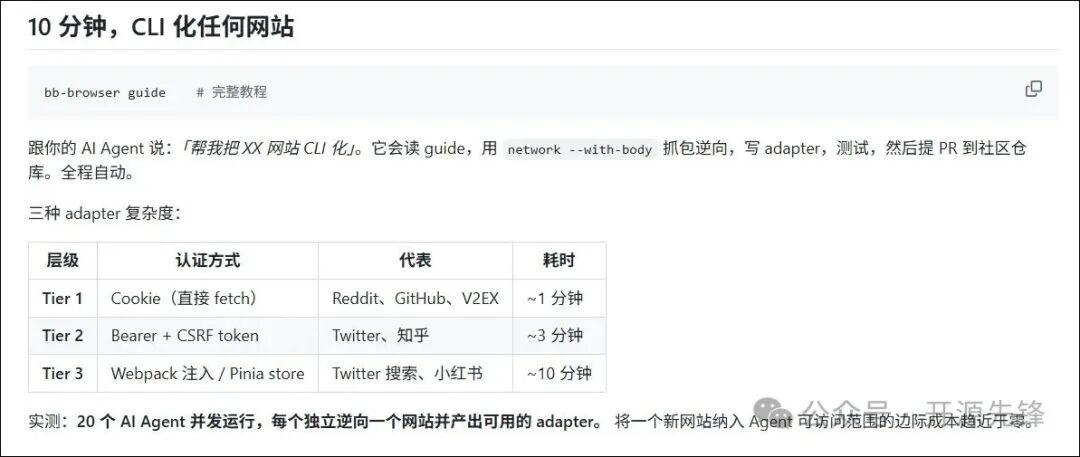
根据网站的鉴权复杂度,适配器开发时间从1分钟到10分钟不等,极大地降低了将任意网站纳入AI可访问范围的边际成本。
实用场景示例
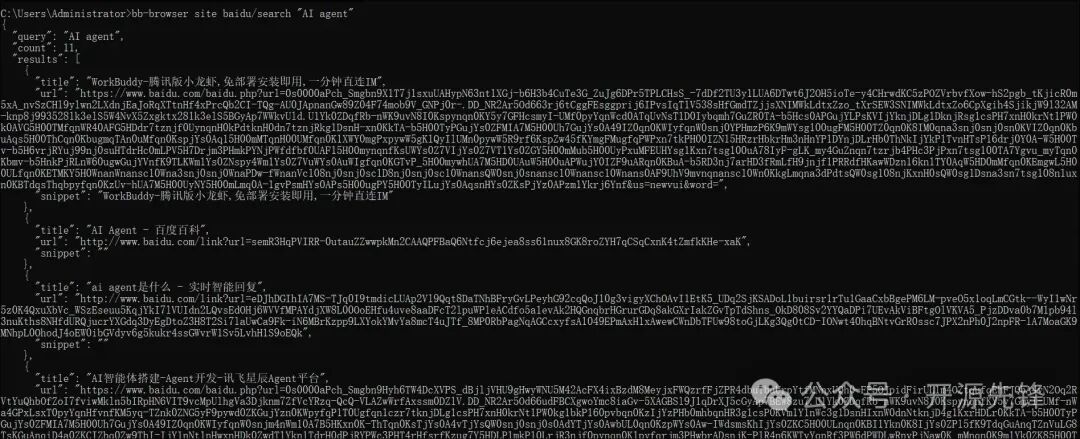
1. 跨平台信息聚合检索
# 在百度搜索关键词
bb-browser site baidu/search "AI agent"
# 查询A股股票实时行情
bb-browser site eastmoney/stock "茅台"
# 获取YouTube视频的字幕全文
bb-browser site youtube/transcript VIDEO_ID
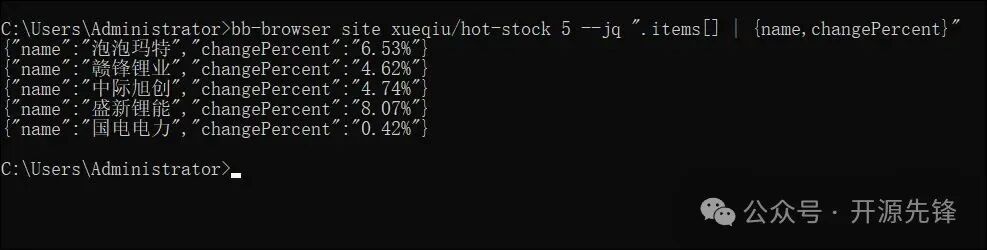
2. 获取并处理结构化数据
结合 jq 工具,可以轻松提取和格式化返回的JSON数据。
# 获取雪球热门股票,并仅输出名称和涨跌幅
bb-browser site xueqiu/hot-stock 5 --jq ".items[] | {name, changePercent}"
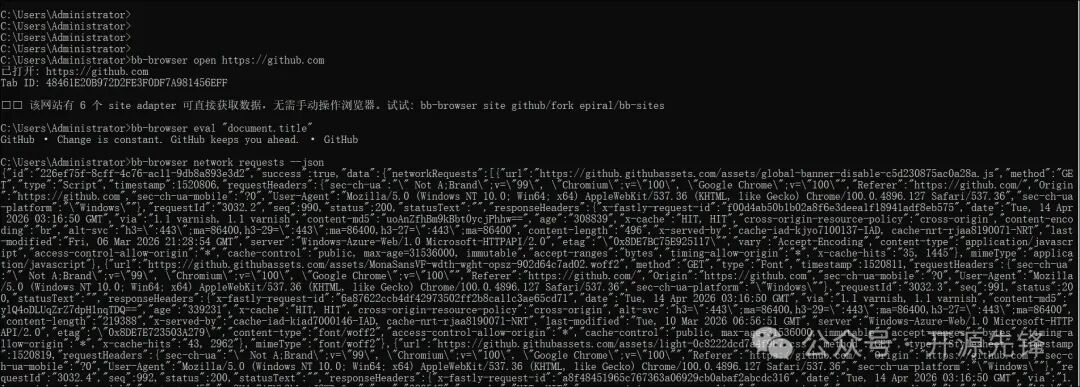
3. 执行原生浏览器操作
bb-browser open https://github.com # 打开网页
bb-browser eval "document.title" # 在当前页面执行JavaScript
bb-browser network requests --json # 捕获并导出网络请求数据
4. AI Agent高效调研任务
让AI Agent在短时间内完成多平台、多维度信息采集,输出结构化数据,极大提升调研效率。
# 一次性调研“RAG”相关的最新学术、社交、代码、问答、资讯信息
bb-browser site arxiv/search "retrieval augmented generation"
bb-browser site twitter/search "RAG"
bb-browser site github search rag-framework
bb-browser site stackoverflow/search "RAG implementation"
bb-browser site zhihu/search "RAG"
bb-browser site 36kr/newsflash
总结
bb-browser 通过“复用真实浏览器登录态”这一巧妙的思路,为AI Agent访问网络提供了一个既强大又优雅的解决方案。它有效地规避了传统爬虫面临的反爬难题,将复杂的鉴权过程交由浏览器本身处理。
无论是用于提升个人工作效率、构建自动化脚本,还是集成到AI应用开发工具链中,bb-browser 都展现出巨大的潜力和实用性。项目完全开源,并由社区驱动发展,感兴趣的朋友可以访问其GitHub仓库探索更多细节:
https://github.com/epiral/bb-browser
如果你对这类能解决实际开发痛点的创新工具感兴趣,欢迎在云栈社区与其他开发者一起交流探讨。
 发表于 2026-4-19 04:22:01
|
查看: 288|
回复: 0
发表于 2026-4-19 04:22:01
|
查看: 288|
回复: 0
