本篇源码:https://gitee.com/YanX2000/yan-batis/tree/master/yanbatis-14
在 Mybatis 的日常使用中,我们经常需要获取 INSERT 操作后数据库自动生成的主键 ID。但在之前的 YanBatis-13 版本中,执行插入只能返回受影响的行数,参数对象的主键字段始终为空。YanBatis-14 正是为了解决这个问题而诞生的,它实现了 Insert 操作后主键自增索引值的返回功能,完整支持了 <selectKey> 标签的解析与执行,能够在插入数据后自动将数据库生成的主键 ID 回填到参数对象上。如果你对框架底层的实现机制感兴趣,不妨来 云栈社区 与其他开发者交流探讨。
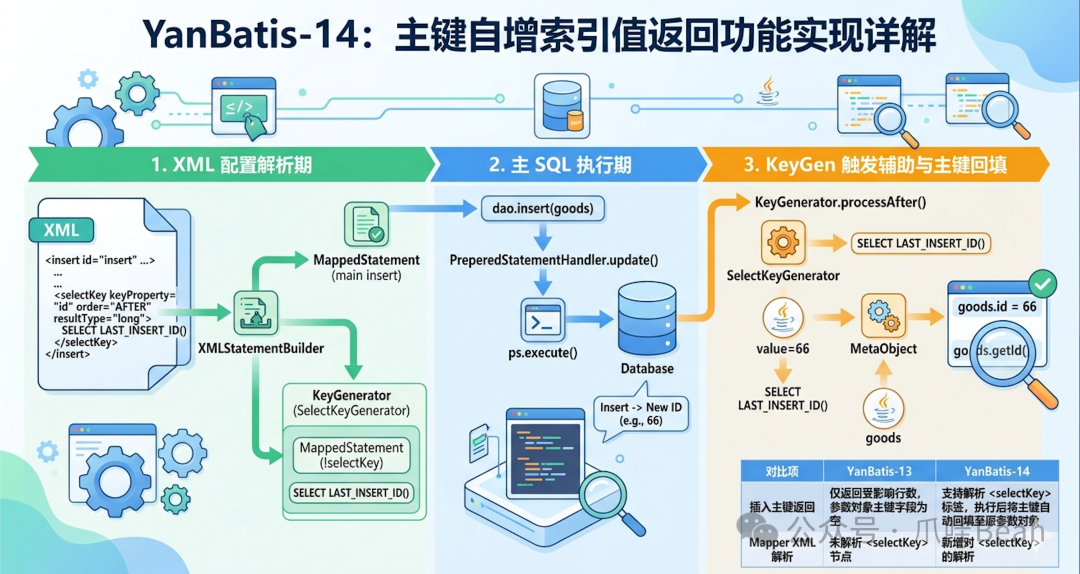
相比 YanBatis-13,新版本的主要改进如下:
| 对比项 |
YanBatis-13 |
YanBatis-14 |
| 插入主键返回 |
仅返回受影响行数,参数对象主键字段为空 |
支持解析 <selectKey> 标签,执行后将主键自动回填至原参数对象 |
| Mapper XML 解析 |
未解析 <selectKey> 节点 |
新增对 <selectKey> 的解析,并注册为带有 !selectKey 后缀的代理子 MappedStatement |
| 生成策略模型 |
无 |
引入 KeyGenerator 体系(如 SelectKeyGenerator),通过 processAfter 赋值策略实现双工协作 |
一、模块背景
在业务开发中,执行数据插入时常常需要立即获取数据库自动生成的主键 ID,以便后续通过这个 ID 去操作其他关联表。YanBatis-14 的核心目标,就是提供一套完整的 <selectKey> 机制封装。从解析 XML 阶段开始,它就会拆解出用于查询键值的子 SQL,然后在运行时,于真正的 Insert SQL 执行之后(或之前),回调执行这个查询来获取最新主键,最后通过反射组件将值无缝填入原始的业务参数对象中。
来看一个典型的 GoodsMapper.xml 配置示例:
<insert id="insert" parameterType="com.yanx.yanbatis.test.po.Goods">
insert into goods (...) values (...)
<selectKey keyProperty="id" order="AFTER" resultType="long">
SELECT LAST_INSERT_ID()
</selectKey>
</insert>
二、新增与变更模块一览
为了实现上述功能,代码结构发生了一些关键变化:
builder/xml/
└── XMLStatementBuilder.java (增强:增加 processSelectKeyNodes 等针对 <selectKey> 节点的解析)
executor/
├── keygen/ ★ 整包新增
│ ├── KeyGenerator.java (新增:键值生成策略顶层接口,规定了 processBefore和processAfter行为)
│ ├── NoKeyGenerator.java (新增:默认不处理键值的策略实现,兜底组件)
│ ├── Jdbc3KeyGenerator.java (新增:基于 jdbc getGeneratedKeys 特性的策略实现,后续完善)
│ └── SelectKeyGenerator.java (新增:基于 <selectKey> 查询的键值回调回填策略实现)
└── statement/
└── PreparedStatementHandler.java (增强:在 update 执行成功完成后,抽取并回调 keyGenerator.processAfter)
mapping/
└── MappedStatement.java (增强:新增 KeyGenerator 等属性成员及关键配置的绑定)
三、执行流程详解 (基于 test_insert)
我们以 ApiTest.test_insert 中保存一条新的电脑商品(Goods)为例,梳理整个自增 ID 自动反推和绑定的完整流程。
阶段一:配置文件扫描与 KeyGenerator 构建
当系统启动并扫描解析 GoodsMapper.xml 中的 <insert id="insert"> 时,会注意到其内部的子标签 <selectKey>。
配置解析:XMLStatementBuilder.parseStatementNode()
↓
┌──────────────────────────────────────────────────────────────────┐
│ ★ 新增环节:抽取解析 <selectKey> 节点 │
│ 过程:调用 processSelectKeyNodes() -> parseSelectKeyNode() │
│ │
│ 1. 独立解析封装: │
│ 将查询语句(SELECT LAST_INSERT_ID())解析为一个单独的 │
│ MappedStatement,为避免混淆,ID 命名加上后缀,此时标识为 │
│ "com.yanx.yanbatis.test.dao.IGoodsDao.insert!selectKey" │
│ │
│ 2. 绑定键值生成器 SelectKeyGenerator: │
│ 把拆解出来的子 Statement 封装关联进 SelectKeyGenerator 返回 │
│ │
│ 3. 主 Statement 初始化: │
│ 继续主 <insert> Statement 的组装,指定 keyProperty (id列) │
│ 并将其 KeyGenerator 属性指向前面构建好的 SelectKeyGenerator │
└──────────────────────────────────────────────────────────────────┘
↓
到此解析完毕,Configuration 全局配置注册了带主流程和键值提取支线的各种状态模型。
阶段二:主 SQL (数据插入)先发执行
当我们在业务代码中正式调用 dao.insert(goods) 时,执行流程开始:
dao.insert(goods)
↓
由 MapperProxy 拦截进而提交 Executor 处理
↓
流转至 PreparedStatementHandler.update(Statement)
↓
┌─────────────────────────────────────────────────────────┐
│ 执行 SQL: │
│ 调用 ps.execute() 实际向数据库插入一条带有基本字段的 goods │
│ 等待数据库确认返回受影响行数并生成新的自增主键标识 │
│ │
│ 锁定环境预备回填: │
│ Object parameterObject = boundSql.getParameterObject(); │
│ KeyGenerator keyGen = mappedStatement.getKeyGenerator();│
└─────────────────────────────────────────────────────────┘
阶段三:主键回填阶段(核心)
此时行数据已完成存储,接着马上唤醒相关的 KeyGenerator 对原始参数对象进行赋值。
马上触发 `keyGenerator.processAfter(..., parameterObject)`:
↓
┌──────────────────────────────────────────────────────────┐
│ ★ SelectKeyGenerator.processAfter() 开始运转 (order=AFTER) │
│ │
│ 1. 触发附属查询任务: │
│ 通过预埋的 "!selectKey" 内部子 MappedStatement │
│ 委托执行 "SELECT LAST_INSERT_ID()" │
│ │
│ 2. 获取并确认主键返回值: │
│ 拿到结果集如 value = 66 │
│ │
│ 3. 依赖元数据驱动 (MetaObject) 绑定赋值: │
│ 利用 configuration.newMetaObject(parameterObject) 把原 │
│ goods 形参转为反射操作件 MetaObject,随后利用其能力调用: │
│ metaParam.setValue("id", 66) │
└──────────────────────────────────────────────────────────┘
↓
此后回退向上层代码返回受影响更新行数。因为是指针原址变更,这时候回到 ApiTest 中的 goods,其 goods.getId() 已经是 66 了!
四、整体生命周期架构图
===== 1. XML 配置解析期 =====
XMLStatementBuilder
│
分析 <insert> 内配置的 <selectKey>标签
│
生成专属影子 MappedStatement (固定后缀 !selectKey)
使用 SelectKeyGenerator 将该影子拦截器裹挟缓存,
挂载赋予给主 <insert> 对应的 MappedStatement
│
...
===== 2. 主 结 论 期 =====
dao.insert(goods)
│
发起执行阶段
│
PreparedStatementHandler.update()
│
┌────────────────────────────────┐
│ 步骤 A: ps.execute() 落地主体数据 │
└────────────────────────────────┘ ──> [DB 真实产生一条主键如: 12]
│
┌────────────────────────────────┐ ===== 3. KeyGen 触发辅助期 =====
│ 步骤 B: processAfter 钩子回调启动 │ ───────▶ SelectKeyGenerator
└────────────────────────────────┘ │
│ 将内部截留的影子语句压入子查询引擎
▼ (SELECT LAST_INSERT_ID())
返回插入行数 │
│ 拿到值利用 MetaObject 把值给入参 goods 中的对应列赋值
任务执行完出场响应确认 ◀───────┘
测试用例打印 goods 可见有 ID
五、总结
YanBatis-14 巧妙地运用了 流程分块(独立 Statement) 与 生命周期拦截(KeyGenerator) 的策略组合,实现了对业务层透明无感的参数反向补充与自增属性映射机制。通过引入抽象的 KeyGenerator 模式,主执行逻辑得以与具体的主键生成实现解耦。框架只需预定义好 processBefore 和 processAfter 等锚点,未来无论是集成分布式 UUID、雪花算法,还是其他如 JDBC3 getGeneratedKeys 机制,都可以通过装配不同的 Generator 子类轻松扩展覆盖。这不仅解决了当前的自增主键回填需求,更为整个 数据库 访问层框架的灵活性与统一性打下了坚实基础,体现了优秀的设计思想。
 发表于 2026-4-19 04:18:13
|
查看: 241|
回复: 0
发表于 2026-4-19 04:18:13
|
查看: 241|
回复: 0
