做微服务开发,全链路追踪是刚需,把一个 TraceId 从网关一路传到最底层的数据库,中间难免会遇到多线程异步处理的场景。
在跨线程时传递 TraceId、用户上下文这些信息,只要去网上一搜,或者翻翻 JDK 源码,它有一个类:InheritableThreadLocal(后边统一叫 ITL),它能自动把父线程的本地变量,传递给子线程。不过在线上环境并不建议贸然使用它。我之前用它踩过一个坑:平时低峰期查日志,链路全是对的;可一到高并发压测,日志里的 TraceId 就会出现大面积的串号。
前半段代码还在处理用户 A 的请求,走到异步任务的日志里,TraceId 莫名其妙就变成了用户 B 的。还好只是日志服务,不是业务逻辑依赖这个上下文去读写数据,要不然数据都得错乱。
ITL 为啥会失效?
想弄明白为什么会串号,得先吃透 ITL 的生效机制。
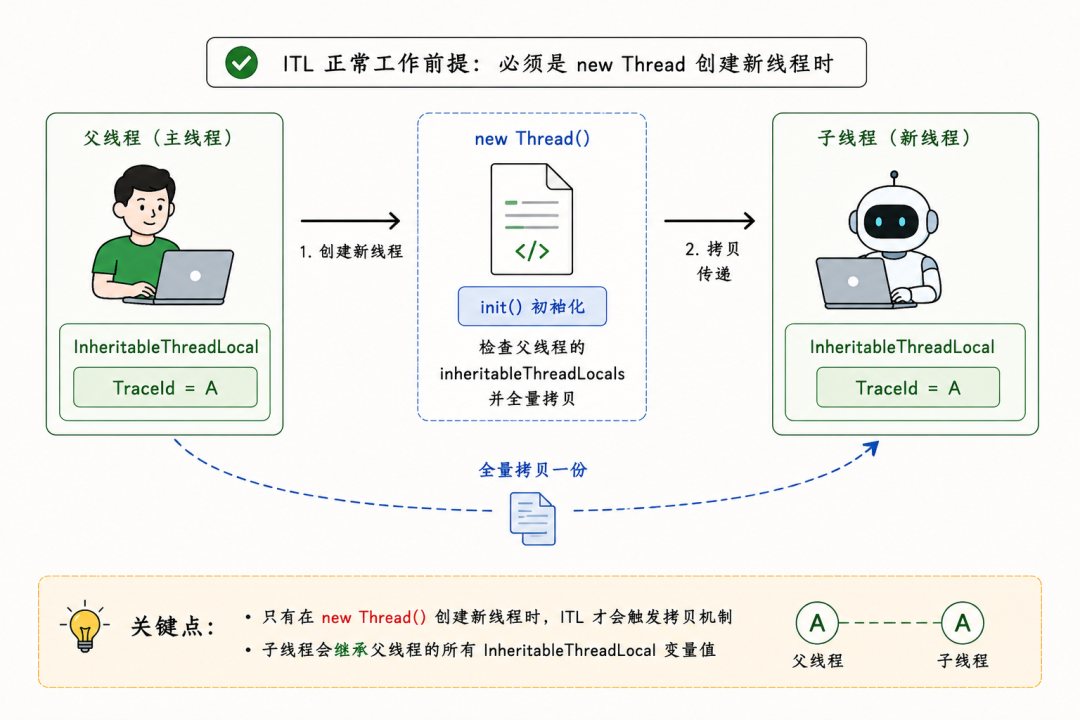
JDK 的 Thread 类源码里,其实藏着一个很简单的逻辑:当程序执行 new Thread() 去创建一个新线程时,在它的 init() 初始化方法里,会去检查父线程有没有 inheritableThreadLocals。如果有,就全量拷贝一份到自己的内存里。
注意这个核心触发条件:必须是创建新线程的时候。
如果代码这么写,ITL 是绝对管用的:
new Thread(() -> {...}).start()
但现实业务中,我们写生产级代码,压根不可能去手动 new Thread,所有的异步任务必然是丢进线程池 ThreadPoolExecutor 里执行的。
线程复用问题
线程池的核心思想在于复用,而问题恰恰就出在这两个字上。
咱们看一下真实的高并发现场:
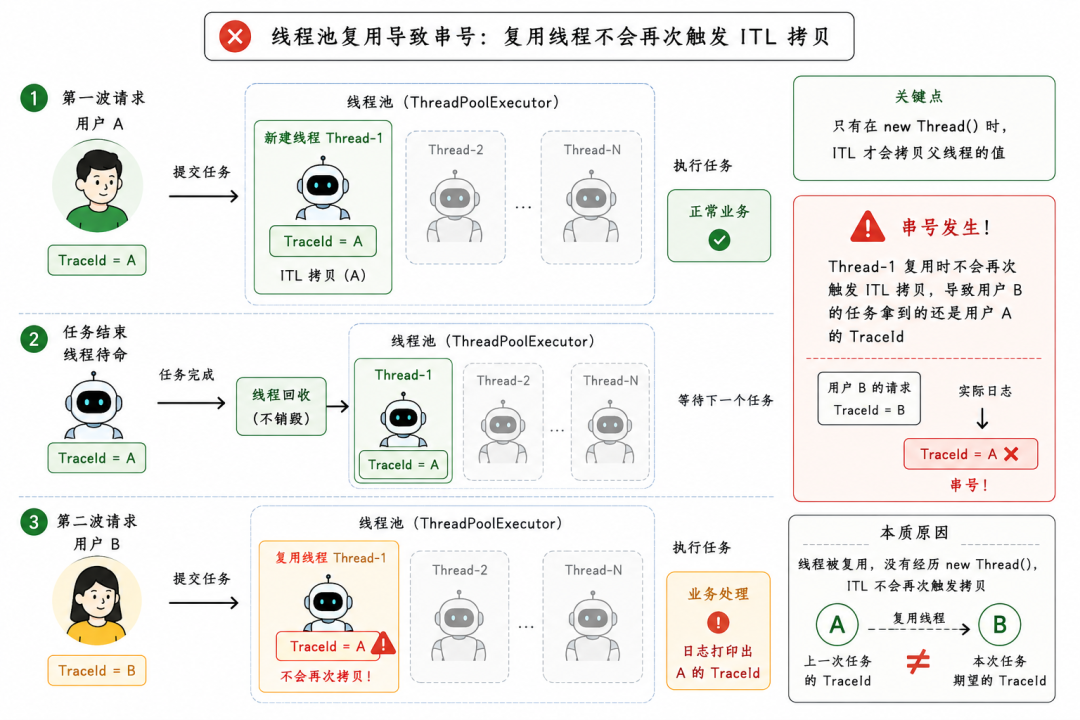
- 第一波请求进来: 用户 A 的任务丢进线程池。线程池刚启动,核心线程还没满,
new 一个工作线程(比如叫 Thread-1)。在这个新建的瞬间 ITL 触发,Thread-1 拿到了用户 A 的 TraceId,任务正常执行。
- 任务结束,线程待命: Thread-1 干完活了不销毁,回到线程池的队列里等下一个任务。
- 第二波请求跟上: 用户 B 的任务进来了,线程池一看,Thread-1 刚好闲着,直接把用户 B 的任务塞给了它。
这时候问题来了。
因为 Thread-1 是被复用的,它根本没有经历 new Thread() 的过程,也就不会再次触发 ITL 的拷贝。Thread-1 内部的 InheritableThreadLocal 里,依然是上一个任务留下的用户 A 的 TraceId。
当用户 B 的业务代码在这个线程里跑起来、打印日志时,输出的自然全都是 A 的信息。这就是所谓的串号。
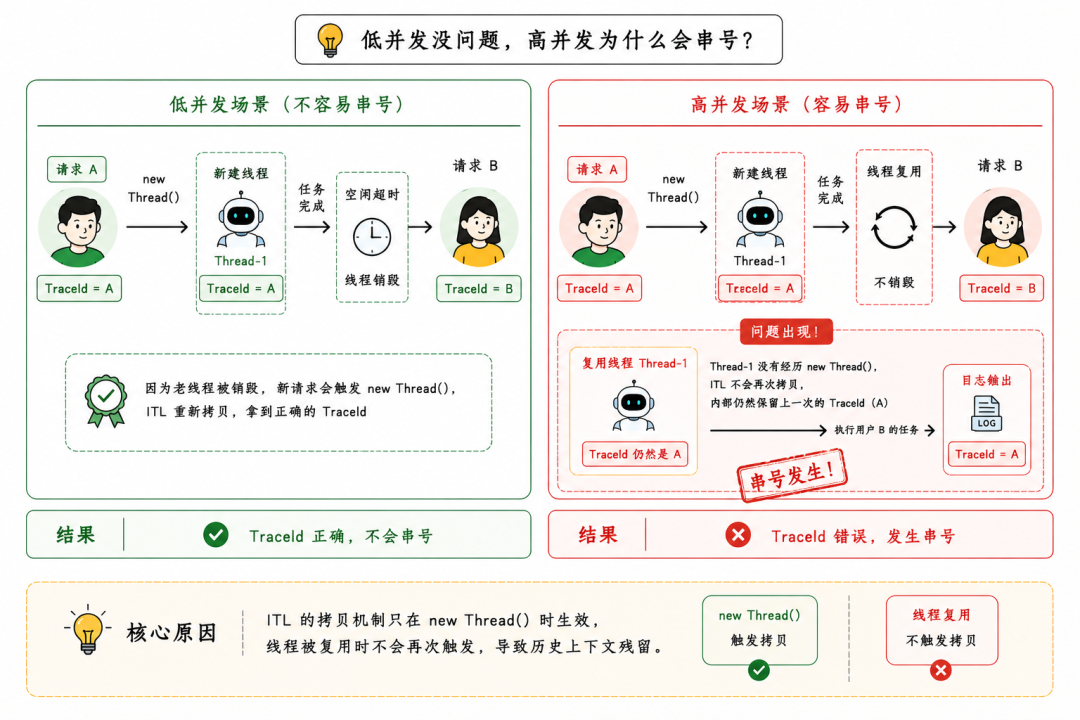
为什么低峰期测不出来呢?
因为低峰期线程有空闲超时(keepAliveTime),老线程销毁了,新请求进来刚好触发了新线程的创建。但 高并发 场景下,所有线程都在被极限复用,历史脏数据被成千上万次地打印。
怎么解决异步串号问题
手动透传
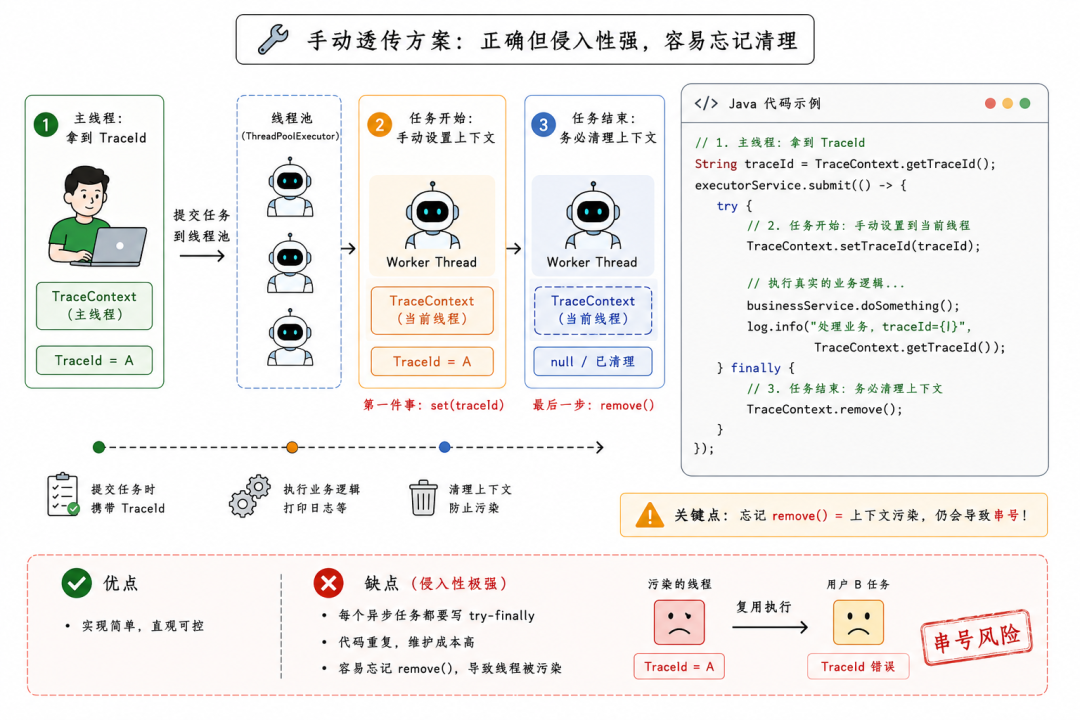
不用那些隐式传递的方式,把上下文当成变量传进去。这是最简单直接的做法。
// 1. 在把任务丢进线程池之前,先在主线程把 TraceId 拿出来
String traceId = TraceContext.getTraceId();
executorService.submit(() -> {
try {
// 2. 任务一进去,第一件事就是把 TraceId 塞进当前执行线程的上下文中
TraceContext.setTraceId(traceId);
// 执行真实的业务逻辑...
} finally {
// 3. 【生死攸关的一步】干完活,必须手动清理上下文!
TraceContext.remove();
}
});
这种做法绝对不会串号。但它的问题在于代码侵入性极强。如果系统里有五十个地方用到了线程池,就得把这段 try-finally 复制五十遍。一旦有个别新来的开发忘了写 finally { remove() },那这个工作线程一样会被污染。
阿里 TTL
想解决手动传值的强侵入性问题,目前国内 Java 圈子里最通用的底层解法,是引入阿里巴巴开源的 TransmittableThreadLocal(简称 TTL)。
TTL 的定位非常明确,就是专门用来解决 ITL 在线程池环境下的问题。
它的用法很简单,你可以用 TtlRunnable.get() 把普通的 Runnable 包装一下。
// 主线程 set 值
UserContextHolder.set(userInfo);
// 用 TtlRunnable 包装你的任务 → 值自动透传
Runnable ttlRunnable = TtlRunnable.get(() -> {
// 子线程里能拿到!
Map<String, Object> user = UserContextHolder.get();
});
// 丢进线程池
executorService.execute(ttlRunnable);
或者更彻底一点,直接用 TTL 提供的工具类把整个 ExecutorService 代理掉。
import com.alibaba.ttl.threadpool.TtlExecutors;
// 1. 你的普通线程池
ExecutorService normalPool = Executors.newFixedThreadPool(5);
// 2. 用 TTL 包装成「自动透传线程池」
ExecutorService ttlPool = TtlExecutors.getTtlExecutorService(normalPool);
// 3. 以后全部使用 ttlPool 即可
// 任何 Runnable/Callable 都自动传值,无需手动包装
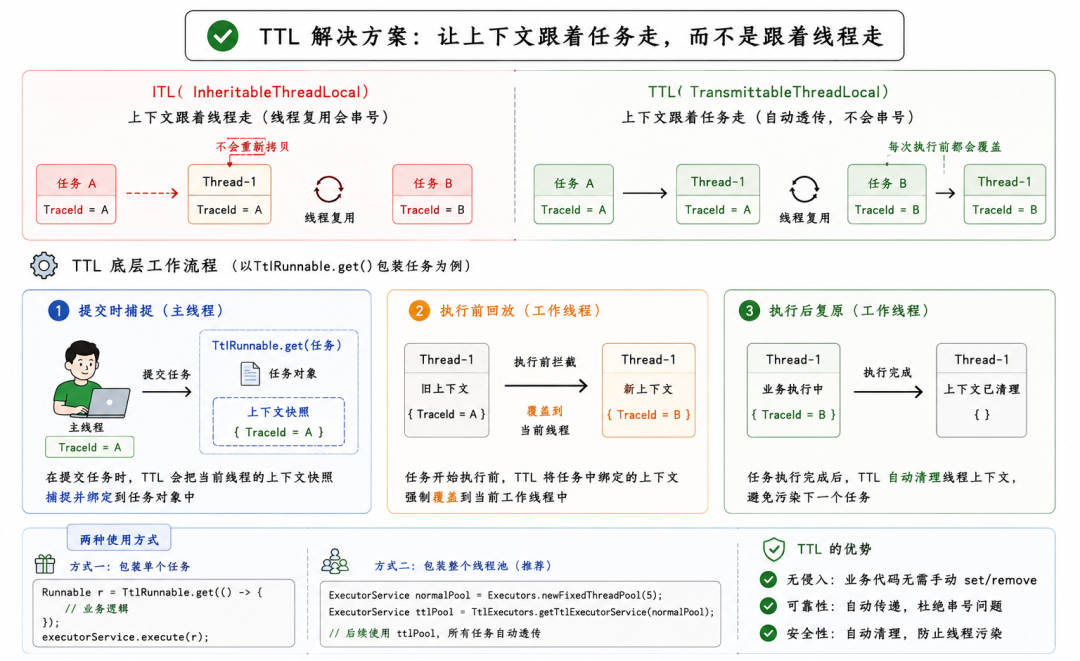
TTL 底层流程其实也不难,本质上是把上下文的生命周期,从跟着线程走变成了跟着任务走。任务在哪,上下文就覆盖到哪。
- 提交时捕捉: 当调用
submit() 把任务丢给线程池,TTL 会悄悄把当前主线程的上下文快照抓取下来,绑定到这个具体的任务对象上。
- 执行前回放: 等到线程池分配了一个具体的 Worker 线程准备调
run() 方法,TTL 会拦截一下,把之前绑在任务上的上下文,强行覆盖到当前这个 Worker 线程里。不管这个 Worker 线程上一把跑的是谁的数据,直接抹掉重写。
- 执行后复原: 业务代码跑完,TTL 会在底层自动把 Worker 线程的状态清理干净。
说在最后
只要在业务里用到了线程池,上下文传递就是一个绕不开的问题,要有这个意识,必须时刻小心谨慎操作。
永远不要假设线程池分给你的线程是绝对没问题的!
 发表于 2026-6-1 02:40:48
|
查看: 107|
回复: 0
发表于 2026-6-1 02:40:48
|
查看: 107|
回复: 0
