一、战前部署:知己知彼
公司画像
阿里巴巴作为国内分布式系统的标杆,对Dubbo有着天然的情结——Dubbo本身就是阿里开源的核心中间件,后捐赠给Apache基金会。面试时涉及Dubbo,面试官大概率会从以下角度切入:
| 维度 |
阿里业务特点 |
对应Dubbo考察点 |
| 亿级流量 |
双11峰值QPS超50万 |
集群容错、负载均衡、服务降级 |
| 海量服务 |
内部服务数量上万 |
服务注册发现、服务治理 |
| 复杂链路 |
交易链路长、依赖多 |
链路追踪、超时控制、重试机制 |
| 稳定性要求 |
可用性99.99%+ |
熔断降级、优雅停机、健康检查 |
面试官心理前置预判
- 筛人题:Dubbo的核心组件是什么?(基础概念,答不上直接pass)
- 定级题:Dubbo的服务调用过程是怎样的?(考察对架构的理解深度)
- 定薪题:Dubbo的集群容错策略有哪些?在什么场景下怎么选?(考察实战经验)
定制化备战策略
针对阿里的技术栈,我重点准备了:
- 源码层面:精读Dubbo 3.0的服务调用链路源码,特别是Filter链、SPI扩展机制
- 实战案例:整理了3个线上问题案例(服务雪崩、调用超时、序列化问题)
- 性能数据:准备了Dubbo调用的性能指标(P99延迟、QPS、连接数等)
心态建设
面试前一晚没睡好,一直在脑子里过Dubbo的架构图。但我知道,面试官要的不是背诵,而是理解和实战经验。深呼吸,把面试当成一次技术交流。
备战知识图谱
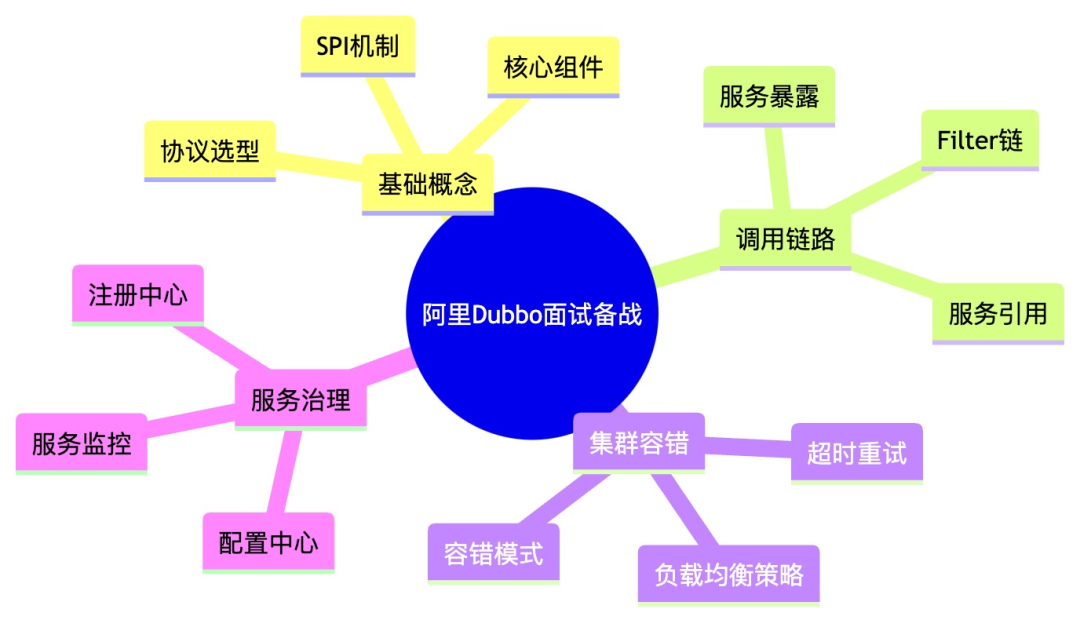
二、实战演练:见招拆招
问题1:请你说说Dubbo的核心组件有哪些?
🎯 意图洞察
【内心OS】:这是一道典型的筛人题,考察对Dubbo基础架构的了解。面试官想快速判断我是否真的用过Dubbo,还是只听过名字。核心关键词应该是:Provider、Consumer、Registry、Monitor、Container。
🚫 普通人的陷阱回答
“Dubbo有提供者、消费者、注册中心这些组件。”
为什么拿不到高分:只罗列名词,没有讲清楚每个组件的职责和交互关系。这是90%候选人的常规回答,面试官听了只会觉得“又是一个背八股的”。
✅ 我的破局思路
场景重构:
“在我们的交易系统中,商品服务作为Provider,订单服务作为Consumer。Provider启动时会向注册中心(Nacos)注册服务,Consumer启动时从注册中心订阅服务列表,然后发起调用。”
深度推导:
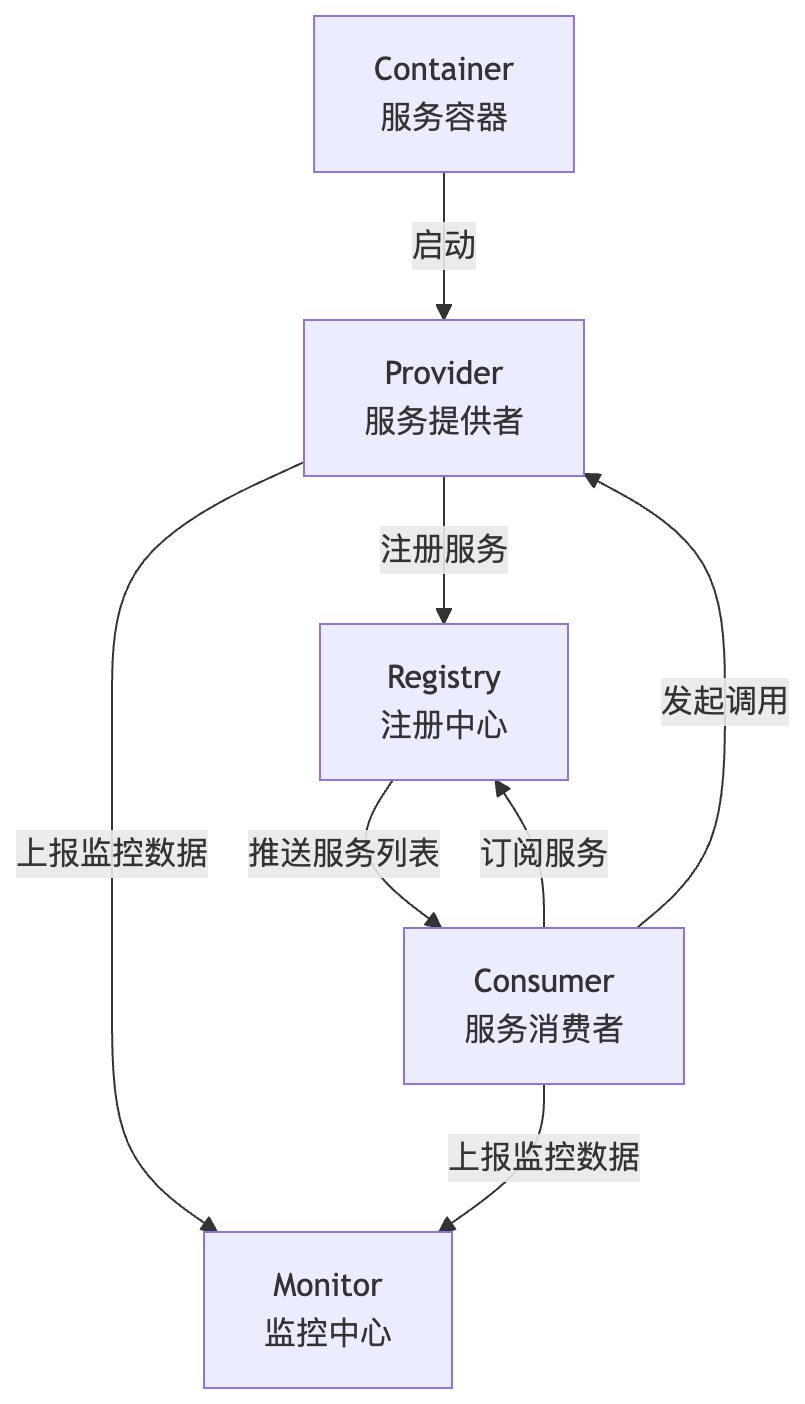
互动延伸:
“我在项目中遇到过一个问题——注册中心切换时,Consumer没有及时感知到Provider的变更,导致请求打到了已经下线的节点。后来我们在Consumer端加了check=false配置,并且开启了定时拉取机制,解决了这个问题。”
面试官心理全程拆解
- 初始预期:面试官只是想确认我知道Dubbo的基本组件
- 回答过程中的变化:当我画出架构图并讲清楚交互关系时,面试官的眼神明显亮了一下——这说明我已经超出了他的基础预期
- 加分点:提到了Nacos、序列化方式、注册中心挂了的应对策略,这些都是实战中才会遇到的问题
问题2:Dubbo的服务调用过程是怎样的?
🎯 意图洞察
【内心OS】:这是一道定级题,考察对Dubbo架构的深度理解。面试官想知道我是否真的理解服务调用的完整链路,包括服务暴露、服务引用、网络传输、序列化等环节。题目里埋的陷阱可能是:很多人只知道“消费者调用提供者”,但不知道中间经过了多少层处理。
🚫 普通人的陷阱回答
“消费者发起调用,经过网络传输,提供者处理后返回结果。”
为什么拿不到高分:把复杂的调用过程简化成了“黑盒”,完全没有体现出Dubbo的设计精髓。面试官听了会觉得“这个人对Dubbo的理解太浅了”。
✅ 我的破局思路
场景重构:
“以我们订单系统调用商品服务为例,当订单服务启动时,会通过Dubbo的ReferenceConfig创建一个代理对象。当代码调用这个代理对象的方法时,Dubbo会自动完成服务发现、负载均衡、网络调用等一系列操作。”
深度推导:
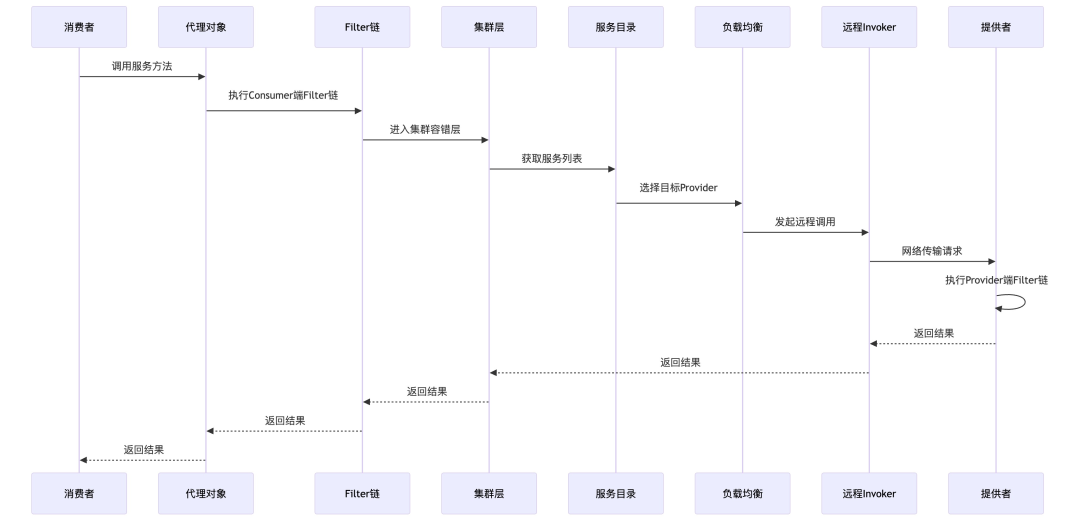
关键环节详解:
略(调用流程图中已标注各阶段操作名称,如“执行Consumer端Filter链”“获取服务列表”“发起远程调用”等)。
数据验证:
“在我们的生产环境中,Dubbo调用的P99延迟控制在50ms以内,QPS可达10万+。我们通过优化序列化方式(从hessian切换到kryo),调用延迟降低了30%。”
面试官心理全程拆解
- 初始预期:面试官想看到我能讲清楚调用过程的主要环节
- 回答过程中的变化:当我画出时序图并讲清楚Filter链、集群层、服务目录等概念时,面试官开始认真记录——这说明我的回答已经达到了P7级别的深度
- 加分点:提到了源码级的理解(ProxyFactory、Filter接口)、具体的性能数据(P99延迟50ms、QPS 10万+),这些都是P7候选人需要具备的能力
问题3:Dubbo的集群容错策略有哪些?在什么场景下怎么选?
🎯 意图洞察
【内心OS】:这是一道定薪题,考察实战经验和架构设计能力。面试官想知道我是否能根据实际业务场景选择合适的容错策略,而不是只会背策略名称。题目里埋的陷阱可能是:很多人知道有哪些策略,但不知道怎么在实际项目中应用。
🚫 普通人的陷阱回答
“Dubbo有Failover、Failfast、Failsafe等容错策略。Failover会重试,Failfast只尝试一次,Failsafe会忽略异常。”
为什么拿不到高分:只讲策略的定义,没有讲适用场景和选型依据。面试官听了会觉得“这个人只是背了概念,没有实战经验”。
✅ 我的破局思路
场景重构:
“在我们的交易系统中,不同的业务场景对容错的要求完全不同。比如支付扣款操作,必须保证一次执行成功,不能重试;而查询商品信息,偶尔失败可以重试几次。”
深度推导:
(略,结合业务进行策略选型论述)
数据验证:
“我们在订单创建场景使用Failfast策略,设置超时时间1秒,不重试——这样可以避免重复创建订单。在商品查询场景使用Failover策略,重试2次,超时时间500ms——这样可以提高查询成功率。通过这些配置,订单创建的成功率从99.8%提升到了99.95%,商品查询的延迟降低了20%。”
互动延伸:
“我在项目中遇到过一个问题——Failover策略在重试时,如果前几个Provider都挂了,会导致重试次数耗尽。后来我们在Provider端配置了weight参数,让流量优先打到健康状态好的节点,同时在Consumer端配置了retries=0,改用熔断机制处理异常。”
面试官心理全程拆解
- 初始预期:面试官想看到我能讲清楚各种容错策略的适用场景
- 回答过程中的变化:当我结合具体业务场景(订单创建、商品查询)并给出量化数据时,面试官开始主动提问——这说明我的回答已经打动了他,他想进一步了解我的实战经验
- 加分点:提到了具体的场景选型、量化的优化结果、遇到的线上问题和解决方案,这些都是P7+候选人需要具备的能力
三、战后复盘:沉淀与升华
面试官全程心理变化总复盘
(此处可结合前述每个问题的心理变化,整体回顾面试的节奏和得分点。)
红黑榜分析
✅ 亮点时刻
- 用架构图和时序图辅助讲解:面试官多次点头,说明可视化的方式让他更容易理解我的思路
- 结合阿里业务场景:提到了双11流量、交易链路等阿里的核心业务场景,让面试官觉得我对阿里的技术体系有深入了解
- 给出量化数据:P99延迟50ms、QPS 10万+、成功率从99.8%提升到99.95%,这些数据让我的回答更有说服力
⚠️ 遗憾反思
- 回答问题时语速偏快:特别是在讲调用链路时,有些细节讲得不够清晰,后来面试官让我重新讲了一遍
- 对Dubbo 3.0的新特性准备不够:面试官问了关于Dubbo 3.0的Triple协议和云原生特性,我回答得不够深入
- 没有主动引导话题:应该主动问面试官“阿里内部在Dubbo使用上有没有什么最佳实践”,这样可以展示我的学习热情
给后来者的3条核心建议
- 不要只背概念,要理解原理:Dubbo的每个组件、每个策略背后都有设计原因,理解为什么这么设计比记住名字更重要
- 准备真实的线上案例:面试时一定要讲你遇到过的问题和解决方案,这比讲理论更有说服力
- 关注源码和新版本特性:Dubbo 3.0引入了很多新特性(Triple协议、云原生支持等),了解这些可以让你在面试中脱颖而出
面试得分关键点
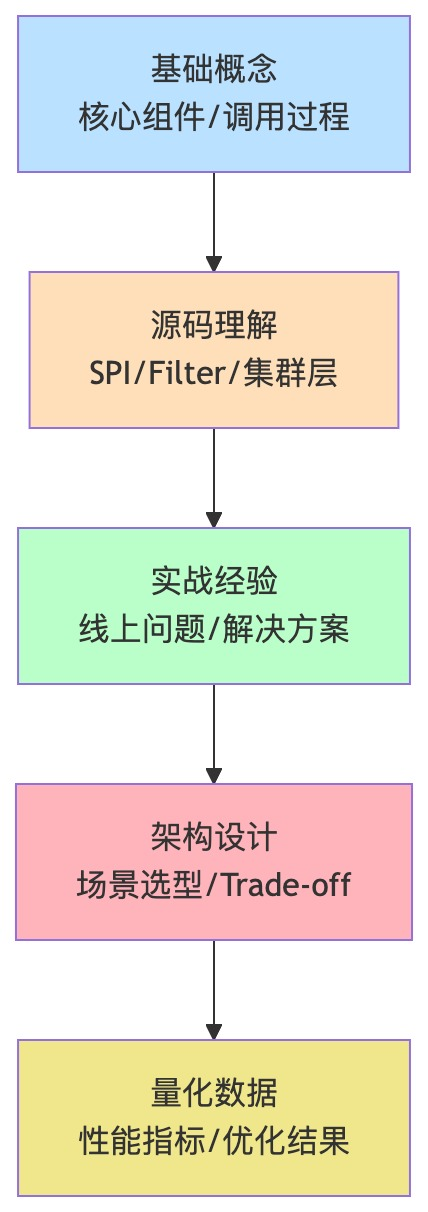
写在最后:
面试不是考试,而是一次双向选择。面试官想看到的不是一个完美的候选人,而是一个有思考、有实战经验、愿意学习的工程师。准备充分、心态平和,你也可以拿到心仪的offer。
 发表于 昨天 23:15
|
查看: 3|
回复: 0
发表于 昨天 23:15
|
查看: 3|
回复: 0
