在量化交易中,反身性与市场冲击始终是个经典难题——当你依信号交易时,交易行为本身就会扰动价格,进而反馈到后续信号的预测目标上。
这类反馈通常呈现复杂的非线性结构,传统线性模型(如 OLS 或 Lasso)对此束手无策。深度学习等黑盒模型虽然能够拟合此类非线性关系,却吐不出清晰的解析表达式,这给策略校准和风控带来了不小的麻烦。
为此,本文提出一套名为 SEER(Self-Equation Extractor & Recognizer)的符号回归管线,它将多层感知机(MLP)信号发生器与 PySR 符号回归引擎结合,在受控仿真环境中,无需线性假设就能还原交易信号与价格收益之间的非线性反馈公式。
因果识别难题与市场反馈的本质
在真实交易场景中,识别信号对下一期收益率的反馈关系面临着严重的“因果识别难题”。
标准回归之所以失效,根源在于信号本身就是基于当前市场状态特征预测得到的,因此信号与下一期收益率共同依赖于相同的市场历史特征。如果直接对两者做回归,历史特征的混杂效应会被错误地归因成信号自身的反馈效应。
实际研究中,我们极少能获得完美的外生工具变量,也难以进行随机化干预实验。传统的 Granger 因果检验等计量工具高度依赖线性假设,无法应对非线性市场反馈;随机森林等机器学习算法虽然能捕获部分非线性结构,但其黑盒属性导致我们无法提取可供策略研发直接使用的精确公式。
SEER 框架的出发点,正是通过“受控合成注入”来规避观测数据中的因果识别困境。在确定特征空间后,研究者在模型拟合前将地面真值系数用 SHA-256 哈希锁定,防止后期调参。该方法在真实市场噪声背景中注入各种特定的非线性反馈结构,测试符号回归能否精准还原这些数学解析式,并探讨其探测极限。
核心技术
SEER 并不是单一步骤的算法,而是一套包含六个步骤的模块化管线:
1. 特征工程与输入准备
数据源自 Binance 交易所小时级数据。提取的外生特征包括:RSI、MACD、布林带位置、24 小时实现波动率以及成交量比率。所有特征均在滚动窗口上进行标准化,以规避前瞻偏差。
2. 自身模型构建
构建一个包含两个隐藏层(节点数分别为 64 和 32)的多层感知机。此网络负责学习市场外生特征并输出标量预测信号。该模型在注入反馈之前完成训练,确保信号仅仅是外生市场状态的函数。
3. 受控反馈注入
通过叠加合成反馈来构建合成收益率。其方式是将真实的比特币小时对数收益率(作为天然的背景噪声)与研究者设计的反馈公式(如二次函数、正弦函数等信号的函数组合)直接相加。其系数在拟合前被哈希加密封存,保证公式发现过程的客观性。
4. 基于 PySR 的符号回归
在合成数据集上运行符号回归。操作符候选集设定为加、减、乘、平方、立方、正弦、余弦及指数。为了在公式复杂度和拟合精度之间取得平衡,引入解析复杂度惩罚。最终在 70/30 的时间序列划分下(无随机打乱,保证时间顺序),选取测试集均方误差最小的显式表达式作为恢复的反馈公式。
5. 归因与混杂因子筛选
为了确保发现的公式确实来自交易信号本身,SEER 引入三重归因防线:
- 消融测试: 将信号替换为其随机打乱的副本,观测拟合优度 $R^2$ 的降幅,以此量化信号的独特贡献。
- 特征重要性: 在恢复的模型上计算重要性得分。
- 条件独立性筛查: 针对与信号高度相关的混杂变量,使用偏相关检验判定其在给定信号的情况下是否与收益率独立。若独立,则将其从归因中剔除,防止伪相关带来的错误归因。
6. 自适应信号衰减
在估计出反馈公式后,若检测到信号反馈的绝对值超过特定阈值,算法会自动等比例缩小信号。这种设计在仿真环境下能够降低系统收益的波动方差。
实验场景
为了验证 SEER 的公式恢复能力,作者在 2022 至 2024 年历史数据(约 17,500 个观测值)上设计了六个不同的实验场景,并与 OLS、Lasso 以及随机森林进行了横向对比。
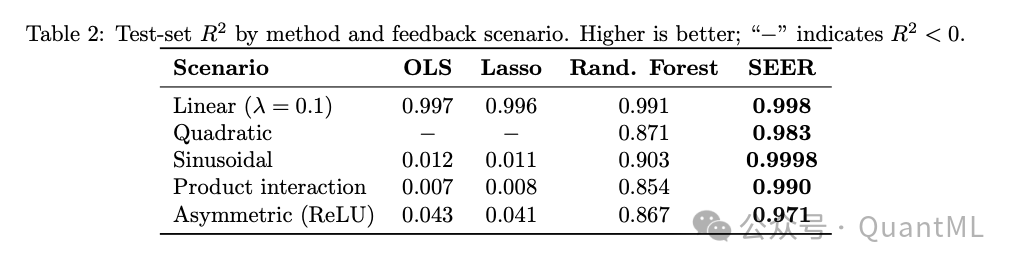
场景 1:线性反馈与负控制
- 设定: 信号与收益率呈简单的线性关系。
- 结果: SEER 成功发现该线性公式,相对误差仅为 0.13%,测试集 $R^2$ 达到 0.998。
- 真实数据负控制: 当不注入任何合成信号、直接在真实的比特币历史数据上运行 SEER 时,其估计的反馈系数仅为 10⁻⁵,完全处于噪声水平。这一结果与学术界关于散户级交易在小时级别上市场冲击可忽略不计的结论相吻合,表明 SEER 框架具备良好的负控制特性,不易产生伪阳性检测。
场景 2:二次非线性反馈
- 设定: 信号的平方对价格产生单向推升。由于反馈关系是对称的,线性基准模型在此处失效。
- 结果: OLS 和 Lasso 的测试集 $R^2$ 降至负值(低于零,表现劣于均值模型)。随机森林取得了 0.871 的 $R^2$,但无法给出解析式。SEER 成功提取出二次方公式,相对误差仅为 0.97%,测试集 $R^2$ 达到 0.983。
场景 3:周期性正弦反馈
- 设定: 信号对收益率的反馈呈现正弦波波动。
- 结果: OLS 和 Lasso 表现惨淡($R^2$ 分别为 0.012 和 0.011)。随机森林表现尚可($R^2$=0.903)。SEER 则在浮点数精度误差范围内精准还原了正弦公式,测试集 $R^2$ 达 0.9998。
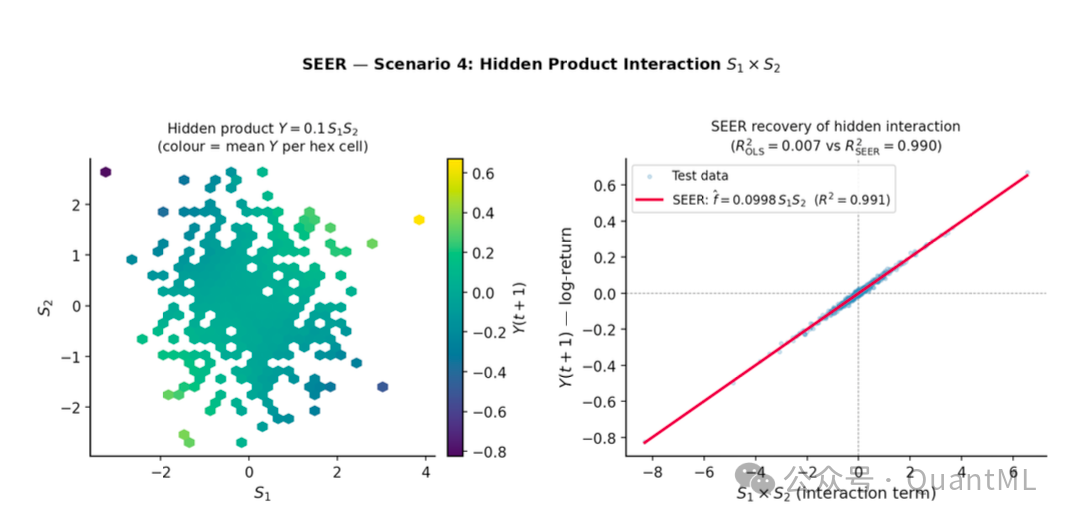
场景 4:隐式乘积交互
- 设定: 两个信号的乘积项对收益率产生影响。
- 结果: 线性基准无法处理这种非线性交互(OLS 的 $R^2$ 仅为 0.007)。SEER 能够定位乘积关系,恢复出相乘公式,相对误差为 0.25%,测试集 $R^2$ 达到 0.990。
场景 5:非对称反馈
- 设定: 仅在信号大于零时产生线性反馈,小于零时无反馈(类似于神经网络中的 ReLU 激活函数)。
- 结果: SEER 准确地识别了这一单侧特征,相对误差为 1.72%,测试集 $R^2$ 为 0.971。而 OLS 和 Lasso 的 $R^2$ 仅有约 0.04。
场景 6:混杂因子处理
- 设定: 引入一个与真实信号高度相关的干扰变量,但该变量不直接引起价格改变。
- 结果: 通过偏相关条件独立性检验,SEER 判定干扰变量在给定真实信号的情况下与收益率独立,成功阻止了伪归因。
下表总结了各场景下各模型的测试集 $R^2$ 表现:
信噪比探测极限分析
对于量化从业者而言,最关键的问题在于:该算法能承受多大的市场噪声?
作者在固定市场真实波动率(以 0.003 代表的小时级收益率波动)的前提下,对反馈强度进行了从强到弱的扫频测试。
敏感性测试显示:
- 以测试集 $R^2$=0.7 作为可探测的实用阈值,SEER 的探测下限对应信噪比(SNR)为 –15 dB。在此极限下,系数估计的相对误差仍能保持在 0.30% 的极低水平。
- 一旦反馈强度继续减弱,使信噪比低于 –18 dB 时,恢复出的测试集 $R^2$ 骤降至 0.03 以下,相对误差明显扩大,表明信号已经完全被淹没在市场噪声之中。
这合理解释了为什么在未注入的真市场中,SEER 无法识别出显著公式。真实的散户或中型策略的小时级市场冲击,远远低于该框架 –15 dB 的检测底噪。
结论
本文展现了符号回归作为一种可解释、高精度公式提取工具在量化仿真中的潜力。它的价值在于提供了一种严谨的研究流程,向我们展示了如何在复杂的非线性反馈下,利用 PySR 还原出公式级别的精确规律。
 发表于 昨天 23:11
|
查看: 4|
回复: 0
发表于 昨天 23:11
|
查看: 4|
回复: 0
