在量化交易领域,Alpha因子的质量直接决定策略的超额收益。传统的提示级优化方法因上下文爆炸和搜索停滞而受限,而近期学界提出的QuantEvolver框架通过强化微调(Reinforcement Fine‑Tuning)让轻量级大型语言模型(LLM)实现自我进化,将定量回测反馈直接转化为模型参数的策略更新。在云栈社区的技术讨论中,许多开发者对这套“从反馈循环到策略更新”的范式表现出浓厚兴趣。本文将系统解读该框架的设计思路与实验效果。
摘要
量化交易依赖系统模型从大规模金融数据中提取预测信号,其中Alpha因子发现至关重要。现有的大语言模型(LLM)因子生成方法存在上下文爆炸、推理成本高、信息稀释、反馈漂移、生成表达式结构相似等问题。为此,QuantEvolver框架提出基于强化微调的自进化Alpha因子发现方案。它将可执行的量化评估转化为策略更新,让Miner LLM通过参数学习内化历史优化经验,构建种子因子与训练任务,生成因子表达式,经由制度回测评估,利用多样性互补奖励(DiCo Reward)优化Miner LLM,训练过程中积累高质量因子到挖掘因子数据库。在三个真实市场基准上的实验表明,该框架能够提升评估指标,产生更高质量、更具互补性的因子池。
简介
现代量化交易依赖系统模型从大规模金融数据中提取预测信号。金融市场噪声大、结构弱、非平稳,量化研究的关键是发现能跨资产、时间和市场条件的稳健且有经济意义的信号。Alpha因子正是用来解决这一挑战的工具,但其发现过程极其困难:候选空间巨大,金融信号微弱且依赖市场状态,有用因子必须表现强、跨期稳健且信息不冗余。
为攻克这一难题,非大语言模型方法分为两类:一是基于规则的符号搜索,用预定义操作探索候选空间;二是学习引导生成,用可训练模型或强化学习策略构建、排序或选择因子表达式。但这些方法难以从高级市场语义灵活组合因子表达式。
大语言模型(LLMs)的出现缓解了传统方法的局限。现有基于LLM的框架已从交互式因子生成发展到反馈驱动和搜索增强的Alpha挖掘,但仍然面临两大挑战:
- 上下文爆炸和反馈漂移:多轮生成‑评估‑反馈循环使上下文持续累积,增加推理成本、稀释反馈、引入无关信息,导致优化不稳定。
- 大模型依赖和搜索停滞:依赖大型LLM生成因子表达式,生成偏好稳定,限制探索多样性,产出冗余候选因子。
本文提出的QuantEvolver框架正是针对上述问题:
- 用强化微调替代提示级反馈积累,减少上下文增长,缓解反馈漂移。
- 采用轻量级LLM,通过可执行量化奖励进化生成分布,设计DiCo Reward鼓励生成有预测性、结构多样、行为独特且互补的因子。
- 引入种子任务构建策略,用Oracle LLM构建种子池,任务库构建器将其扩展为训练任务,为轻量级LLM提供起点和训练上下文。
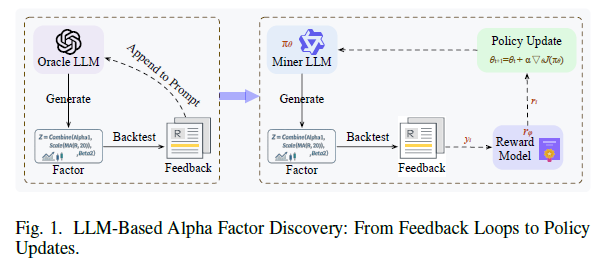
在三个现实市场基准上的实验结果显示,QuantEvolver在各任务的主要评估指标上均优于现有基于大语言模型的Alpha因子发现方法,且在不同任务中均有显著提升。
本文的主要贡献:
- 引入基于策略更新的LLM Alpha因子发现范式,用强化微调替代提示级反馈积累。
- 提出QuantEvolver自进化Alpha因子发现框架,结合多种方法提供稳定的训练任务和奖励信号。
- 在三个市场基准上验证其有效性,实验表明它在主要评估指标上超越现有方法,尤其在因子质量、多样性和样本外有效性方面表现出色。
相关工作
基于LLM的量化交易
随着大语言模型(LLMs)的发展,其在量化金融领域的应用受到广泛关注。相关研究可分为五类:
- 数据分析:用LLMs处理金融信息,包括文本总结等任务,特定金融LLMs提升了语言理解能力。
- 投资研究:支持市场分析等,近期已用于Alpha因子挖掘。
- 交易:用LLMs支持策略执行和决策,探索记忆增强或智能交易系统。
- 投资管理:协助投资组合推理等,有潜力但面临长文本推理等挑战。
- 风险管理:应用于欺诈检测等,需处理不平衡数据等问题。
本文属于投资研究方向,聚焦基于LLMs的Alpha因子发现。
Alpha因子挖掘
Alpha因子发现旨在从历史市场数据中自动识别预测信号。现有方法按探索因子表达空间的方式可分为:
- 早期基于规则的符号搜索:将因子表示为符号表达式,利用遗传编程等方法搜索,但受手工规则限制,难以扩展到语义丰富的大因子空间。
- 学习引导的因子生成:用可训练模型引导构建、排序和选择表达式,提高了搜索适应性,但仍受预定义空间和训练目标的限制。
- 基于大语言模型(LLM)的方法:利用其能力生成和优化因子表达式,提升挖掘灵活性,但多数仍将LLM作为提示驱动工具。
本文结合学习引导因子生成与基于LLM的Alpha挖掘:QuantEvolver使用语言模型策略生成DSL因子表达式,并通过强化微调优化搜索分布,目的是在训练过程中收集、验证和选择高质量因子集。
背景
Alpha因子挖掘
Alpha因子是捕捉金融市场预测模式的数值信号,可将市场观测数据映射为标量信号用于预测、排名或构建投资组合,许多因子可以用公式表达。
以简单动量和反转因子为例,公式化因子可表示为符号表达式,应用于历史市场数据可得因子值。用评估函数衡量因子经验质量,常见评估信号包括预测准确性等。实践中,多个因子组合成因子集并融合为复合信号,有效因子集应兼具预测性、多样性和互补性。
例如,一个简单的因子表达式为:
$f = \operatorname{rank}(\operatorname{ts\_mean}(\text{return}, 5)),\ \ (1)$
由此产生的因子值向量记为 $z_f = f(X),\ \ (2)$
所有候选因子的集合可表示为 $F = \{f_1, f_2, \ldots, f_n\},\ f_i \in L,\ \ (3)$
对应的因子值矩阵为 $Z_F = [z_{f_1}, z_{f_2}, \ldots, z_{f_n}],\ \ (4)$
最终融合信号为 $s = g(Z_F),\ \ (5)$
Alpha因子发现的目标是寻找在验证协议下表现好、为下游融合提供有用信号的因子集,但面临候选空间大、金融信号有噪声和制度依赖等挑战,新因子需具备增量价值。
强化学习微调 (RFT)
强化学习微调(Reinforcement Fine‑Tuning, RFT)是利用特定任务奖励信号调整语言模型的训练范式。与监督微调不同,它让模型生成候选输出,并根据外部评估器的奖励更新策略,特别适用于难以穷举标注高质量输出但可通过反馈评估的结构化生成任务。
RFT的目标是更新策略参数以最大化预期奖励:
$\max_{\theta} \mathbb{E}_{x \sim D, y \sim \pi_{\theta}(\cdot | x)} [R(x, y)],\ \ (6)$
现代RFT方法在奖励收集和策略更新方式上存在差异,例如PPO稳定策略更新,DPO简化偏好优化,GRPO通过组内输出比较改进推理型语言模型。在GRPO中,首先从旧策略采样一组输出:
$Y(x) = \{y_1, y_2, \ldots, y_K\},\quad y_i \sim \pi_{\theta_{\text{old}}}(\cdot \mid x),\ \ (7)$
然后计算组内归一化的优势:
$\hat{A}_i = \frac{R(x, y_i) - \operatorname{mean}(\{R(x, y_j)\}_{j=1}^K)}{\operatorname{std}(\{R(x, y_j)\}_{j=1}^K)},\ \ (8)$
RFT在推理、代码生成等结构化任务中已取得成功,但在基于LLM的Alpha因子发现中的应用尚未被充分探索。现有LLM Alpha挖掘方法大多依赖提示交互和迭代反馈,少有研究关注RFT对因子生成策略的直接改进。
QuantEvolver
QuantEvolver的工作流程如下:首先根据用户指定的因子挖掘场景进行种子构建,将原始场景细化后由Oracle LLM生成原始种子候选,经验证、评分和去重形成高质量种子池;然后结合种子与不同时间分割构建任务库,为强化微调提供训练实例;基于任务库,用Miner LLM进行基于RFT的因子发现,通过DiCo Reward引导,迭代生成候选因子表达式,接收反馈并通过GRPO微调更新;训练过程中产生的高质量因子存入数据库,最终输出针对目标场景的验证因子库。
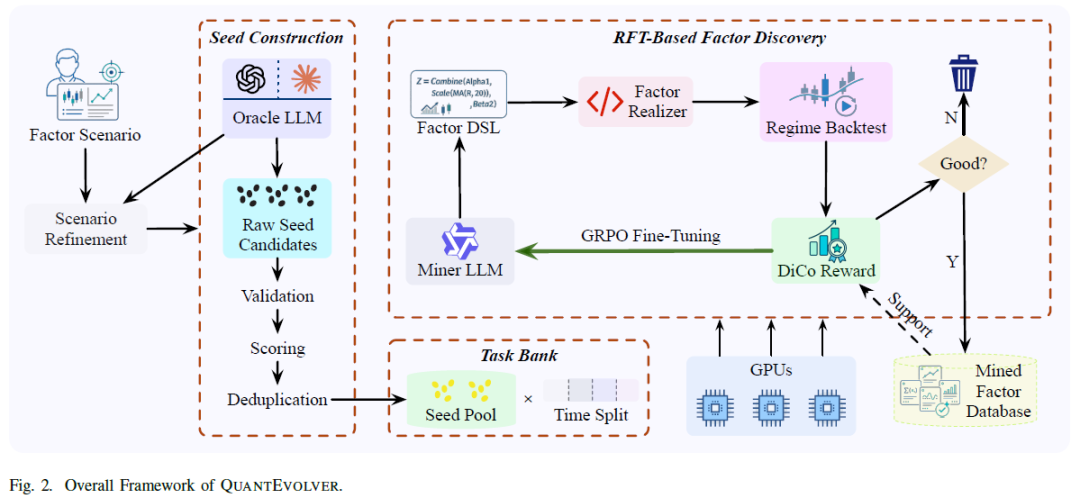
种子构建
种子构建的目标是为强化微调提供优质起点。QuantEvolver从用户指定或预设场景构建紧凑的种子池,以提升后续策略优化的稳定性。
对原始用户场景 $u$ 进行细化,得到结构化场景:
$s = \varphi_{\text{refine}}(u),\ \ (9)$
基于 $s$ 由强大的大语言模型或预设种子源提出原始候选集:
$C_{\text{raw}} = \{c_1, c_2, \ldots, c_m\} = \varphi_{\text{seccd}}(s),\ \ (10)$
对 $C_{\text{raw}}$ 进行过滤:DSL验证得有效候选集 $C_{\text{valid}} = \{c_i \in C_{\text{raw}} \mid c_i \in L\},\ \ (11)$
在历史市场数据上执行并打分,去除冗余候选,得有效、非冗余种子池 $S$:
$q(c_i) = M(c_i(X)),\ \ (12)$
$S = \operatorname{TopK}(\{c_i \in C_{\text{valid}} \mid q(c_i) \ge \tau_q,\ h(c_i) \notin H_{\text{selected}}\}),\ \ (13)$
构建评估窗口集 $W = \{w_j\}_{j=1}^n = \{(\text{start}_j, \text{end}_j)\}_{j=1}^n,\ \ (14)$
为种子池 $S$ 中每个种子 $f$ 和窗口 $w_j$ 构建任务 $\tau_{f,j} = (f, s, w_j, o),\ \ (15)$
任务库 $B$ 为 $S$ 和 $W$ 的笛卡尔积:
$B = \{\tau_{f,j} \mid f \in S, w_j \in W\},\ \ (16)$
这些任务为Miner LLM提供结构化训练实例,降低过拟合风险,聚焦优化和多样化候选因子。
基于RFT的因子发现
QuantEvolver构建任务库后,用基于强化学习的微调进行因子发现,优化Miner LLM的因子生成分布。
给定任务 $\tau$,Miner LLM(策略 $\pi_\theta$)生成候选因子表达式 $\hat{f}$,需符合Factor DSL语法:
$\hat{f} \sim \pi_\theta(\cdot \mid \tau),\ \ (17)$
用Factor Realizer将 $\hat{f}$ 转换为可执行代码 $p_{\hat{f}}$:
$p_{\hat{f}} = \psi_{\text{realize}}(\hat{f}),\ \ (18)$
对有效 $p_{\hat{f}}$ 进行Regime Backtest,得到因子值 $z_{\hat{f}}$ 和评估结果 $e_{\hat{f}}$:
$z_{\hat{f}} = p_{\hat{f}}(X^T),\ \ (19)$
$e_{\hat{f}} = \psi_{\text{bt}}(z_{\hat{f}}, y^T, \tau),\ \ (20)$
根据 $e_{\hat{f}}$ 计算训练奖励 $r_{\hat{f}}$:
$r_{\hat{f}} = R_{\text{DiCo}}(\hat{f}, e_{\hat{f}}, \tau, A),\ \ (21)$
通过选择函数 $\eta$ 决定是否将候选因子存入Mined Factor Database:
$A \leftarrow A \cup \{\hat{f} \mid \eta(\hat{f}, e_{\hat{f}}) = 1\},\ \ (22)$
用GRPO对Miner LLM进行基于组的强化微调:对任务 $\tau$ 采样一组候选 $\{\hat{f}_k\}$,
$G_\tau = \{\hat{f}_1, \hat{f}_2, \ldots, \hat{f}_K\},\ \hat{f}_k \sim \pi_\theta(\cdot \mid \tau),\ \ (23)$
然后利用组内奖励归一化更新策略,增加高奖励候选因子的生成概率。
DiCo奖励
DiCo Reward即多样性‑互补性奖励,用于引导基于RFT的因子发现,超越单纯预测性能。它在特定任务预测奖励的基础上增加轻量级塑形项,鼓励结构多样性和行为互补性。
预测奖励:从回测结果提取特定任务预测奖励,无效或覆盖不足的候选因子获得低奖励。具体地,结构家族塑形项为:
$r_{\text{fam}}(\hat{f}) = \lambda_{\text{new}} I_{\text{new}}(\hat{f}) - \lambda_{\text{fam}} I_{\text{over}}(\hat{f}),\ \ (24)$
精确重复惩罚:对在已挖掘精英因子集合 $A_{\text{elite}}$ 中精确重复的表达式施加惩罚,通过计算与已存因子的最大相关性:
$c_{\max}(\hat{f}) = \max_{f \in A_{\text{elite}}} \operatorname{corr}(b(\hat{f}), b(f)),\ \ (25)$
互补性项:奖励行为独特的候选因子并惩罚高度相关的因子:
$r_{\text{comp}}(\hat{f}) = \lambda_{\text{low}} \|_{\text{low}}(\hat{f}) - \lambda_{\text{corr}} [c_{\max}(\hat{f}) - \tau_{\text{corr}}]_+,\ \ (26)$
最终奖励:结合预测和塑形成分,预测成分占主导,多样性和互补性项起轻量级正则化作用,不同任务可启用不同组件:
$r_f = \operatorname{clip}(r_{\text{pred}} + r_{\text{exact}} + r_{\text{fam}} + r_{\text{comp}},\ r_{\min},\ r_{\max}),\ \ (27)$
DiCo Reward有助于减少RFT过程中的模式崩溃,提高最终因子库的质量。
实验
实验从整体评估、消融研究、超参数敏感性、训练奖励分析、盈利能力案例研究五个视角评估QuantEvolver。
实验设置
QuantEvolver默认使用Qwen3‑14B模型,采用验证引导的去相关选择,相关阈值设为0.7,并报告融合组合结果。实验在本地服务器上进行,配备160个英特尔至强CPU核心、1.8TiB内存和8块英伟达H20 GPU。
下游评估采用统一的候选选择与融合协议:先单独评估候选因子,按验证表现排名,经过去相关筛选后,等权融合成多因子信号。
评估指标
从预测准确性和排名质量两方面评估发现的Alpha因子,采用四个常用指标:
- 方向准确率(DirAcc):衡量因子对未来收益方向的预测能力,即因子信号与未来收益符号一致的样本比例,值越高预测能力越强:
$\operatorname{DirAcc}(f) = \frac{1}{|\Omega|} \sum_{(i,t) \in \Omega} \mathbb{I}[\operatorname{sign}(z_{i,t}) = \operatorname{sign}(r_{i,t+1})],\ \ (28)$
- 信息系数(IC):测度因子值与未来收益的线性相关性,先计算各时间截面的皮尔逊相关系数,再求所有评估期的平均值,绝对值越高线性关联越强:
$\operatorname{IC}_t(f) = \operatorname{corr}_i(z_{i,t}, r_{i,t+1}),\ \ (29)$
$\operatorname{IC}(f) = \frac{1}{T} \sum_{t=1}^T \operatorname{IC}_t(f),\ \ (30)$
- 排名信息系数(RankIC):衡量因子值与未来收益的排名相关性,计算各时间步的斯皮尔曼相关系数并求均值,适用于横截面因子评估:
$\operatorname{RankIC}_t(f) = \operatorname{corr}_x(\operatorname{rank}(z_{i,t}), \operatorname{rank}(r_{i,t+1})),\ \ (31)$
$\operatorname{RankIC}(f) = \frac{1}{T} \sum_{t=1}^T \operatorname{RankIC}_t(f),\ \ (32)$
- 信息系数信息比率(ICIR):衡量IC随时间的稳定性,为IC均值除以IC标准差(加一个小常数 $\varepsilon$),值越高表明因子不仅预测相关性强,且在不同时期表现稳定:
$\operatorname{ICIR}(f) = \frac{\operatorname{mean}(\{\operatorname{IC}_t(f)\}_{t=1}^T)}{\operatorname{std}(\{\operatorname{IC}_t(f)\}_{t=1}^T + \varepsilon)},\ \ (33)$
基准
将QuantEvolver与AlphaBench、QuantaAlpha、R&D‑Agent、Alpha‑Jungle四个基于大语言模型的Alpha因子发现方法对比,所有方法均以Qwen‑3.6‑Plus作为骨干大语言模型,在相同条件下评估。
在三个基准上评估各方法:
- 基准A:基于真实资产5分钟市场数据的单资产方向预测,用方向准确率(DirAcc)评估。
- 基准B:基于高频多资产数据的高频横截面因子发现,以小时为重新平衡周期,用IC、RankIC、ICIR评估,RankIC为主指标。
- 基准Γ:基于沪深300ETF成分股每日市场数据的因子发现,用IC、RankIC、ICIR评估,RankIC为主指标。
结果
表I展示了QuantEvolver与代表性LLM基线在三个基准测试中的表现。QuantEvolver在各基准的主指标上均取得最佳成绩。
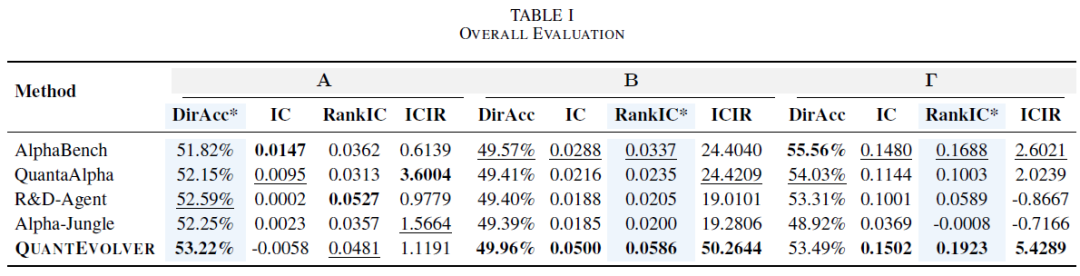
- 基准A(短期单资产方向预测):QuantEvolver的DirAcc达到53.22%,超越最强基线。强化微调帮助其发现与目标决策规则更契合的因子。
- 基准B(高频横截面因子挖掘):QuantEvolver的RankIC达0.0586,IC和ICIR也最高,发现的因子相关性强、系数稳定。
- 基准Γ(每日股票ETF因子发现):QuantEvolver的RankIC为0.1923、ICIR为5.4289、IC为0.1502,均是最佳值,虽然AlphaBench的DirAcc最高,但该基准的主指标为RankIC。
QuantEvolver在各基准上持续提升主指标,充分证明策略更新驱动的因子发现方式有效。在两个排名导向的基准上优势尤为明显,表明它学习到了可跨场景迁移的更强因子生成策略。
消融分析
表II展示了QuantEvolver在基准B上的消融实验结果,以RankIC为主要指标。研究三个关键组件:种子构建(Seed)、多样性感知奖励塑造(Div)和因子DSL约束(DSL)。
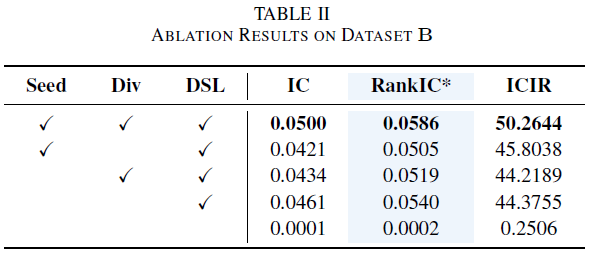
全模型(包含所有三个组件)各项指标表现最佳,RankIC达0.0586。移除Seed或Div后,RankIC分别下降,表明二者有助于有效因子发现。即使移除Seed和Div但保留DSL,RankIC仍有0.0540,说明DSL提供了重要的归纳偏置。若移除DSL,RankIC骤降至0.0002,表明无约束的代码生成完全不可靠,DSL使强化微调变得可行且高效。
三个组件结合时表现最强:DSL确保因子生成,Seed提供起点,Div避免重复挖掘。
超参数敏感性
图3研究了基准B上因子融合性能对两个超参数(所选因子数量 $k$ 和因子选择时的相关阈值)的敏感性,以RankIC为主要指标。
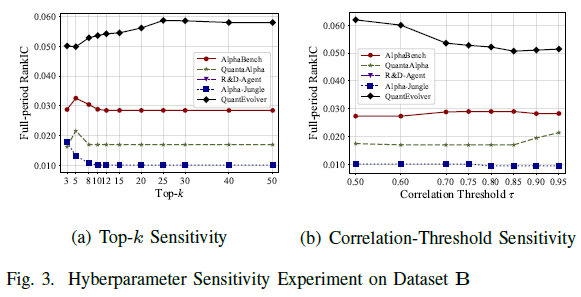
图3(a)显示,QuantEvolver在不同top‑k设置下始终优于所有基线方法,RankIC在选前3~5个因子时约为0.050,随高质量因子增加而提升,$k=25$ 时达到最佳0.0587,之后性能保持稳定。
图3(b)表明,因子选择时相关阈值越低,QuantEvolver的性能越强,严格阈值下RankIC可达0.0620,阈值放宽后RankIC降至0.052~0.054,说明控制因子冗余对于获得强融合信号至关重要。
敏感性分析显示,QuantEvolver对融合超参数具有鲁棒性,在广泛的top‑k值和相关阈值下均优于基线方法。最佳配置倾向于规模适度且去相关性较严格的因子集,这再次验证其发现的因子池具有多样性和互补性。
挖掘过程分析
图4对比了不同组件配置下的训练奖励动态和高质量因子发现比例。
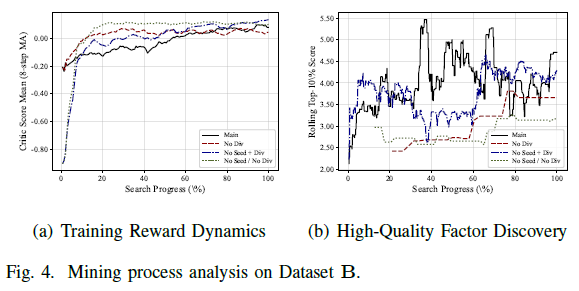
图4(a)显示,完整的QuantEvolver设计(Main)的奖励轨迹更稳定且持续改善,种子初始化与多样性感知探索的结合有助于寻优;去除任一或两者则会使优化效果变差。
图4(b)表明,完整方法在大部分搜索过程中保持最强的滚动前10%分数,能够更可靠地发现优质因子;消融变体改善较慢或质量较低。
盈利能力案例分析
图5展示了将基准B中发现的横截面因子转化为简单多空投资组合的累计净值表现,用以检验更高的RankIC能否转化为经济回报。
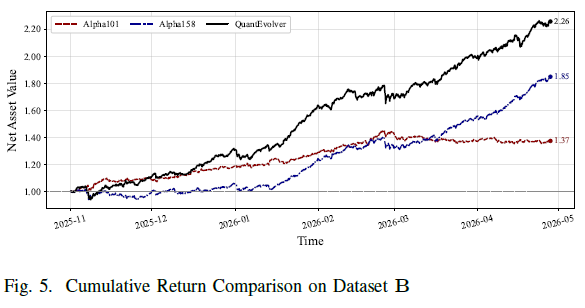
结果显示,QuantEvolver组合在评估期(2025年11月至2026年4月)内累计回报约125.6%,净值从1.00增至约2.26,显著优于Alpha158(净值1.85)和Alpha101(净值1.37)。回报轨迹表明,QuantEvolver挖掘的因子能持续捕捉横截面回报信号,长期优于经典Alpha集。
该案例证明,QuantEvolver发现的因子池不仅具有统计预测性,在简单投资组合构建中也具备经济实用性,有力支持了基于策略更新的高频横截面Alpha挖掘。
总结
本文研究了基于LLM的Alpha因子发现,指出现有提示级优化方法存在上下文爆炸和搜索停滞的问题,并提出QuantEvolver——一个基于强化微调的自进化Alpha因子发现框架。它将定量的回测评估转化为策略更新,让Miner LLM通过参数学习内化优化经验、改进因子生成策略。在三个市场基准上的实验表明,其发现的Alpha因子比LLM基线更强、更稳健。这一范式为量化因子挖掘开辟了新的方向。
 发表于 2026-5-28 05:18:12
|
查看: 199|
回复: 0
发表于 2026-5-28 05:18:12
|
查看: 199|
回复: 0
