Google GKE Labs 开源了 OpenRL,这是一个自托管 API,专为在标准 Kubernetes 集群上对大型语言模型(LLM)进行后训练和微调而设计。
谷歌表示,OpenRL 将强化学习(RL)基础设施从 AI 研究中抽象出来,使机器学习团队能够直接在自己的集群上扩展后训练工作流。
据谷歌工程师称,在 LLM 上进行基于代理的强化学习时,极易因系统复杂性过高而陷入困境。即使是一个简单的强化学习循环,也需同时处理许多环节:数据准备与清洗、环境选择、训练循环调试、奖励设计、处理推理不一致、硬件配置以及底层基础设施管理。
这些都是棘手的问题。但真正让情况变得更复杂的是,在当今的工具和框架中,AI 研究与基础设施问题紧密地交织在一起。
谷歌工程师认为,将基础设施与 AI 研究分离后,这些挑战会变得更容易应对,使专业团队能够聚焦各自领域——这与 Kubernetes 通过基础设施抽象化为应用开发人员和 SRE 简化工作流的思路如出一辙。
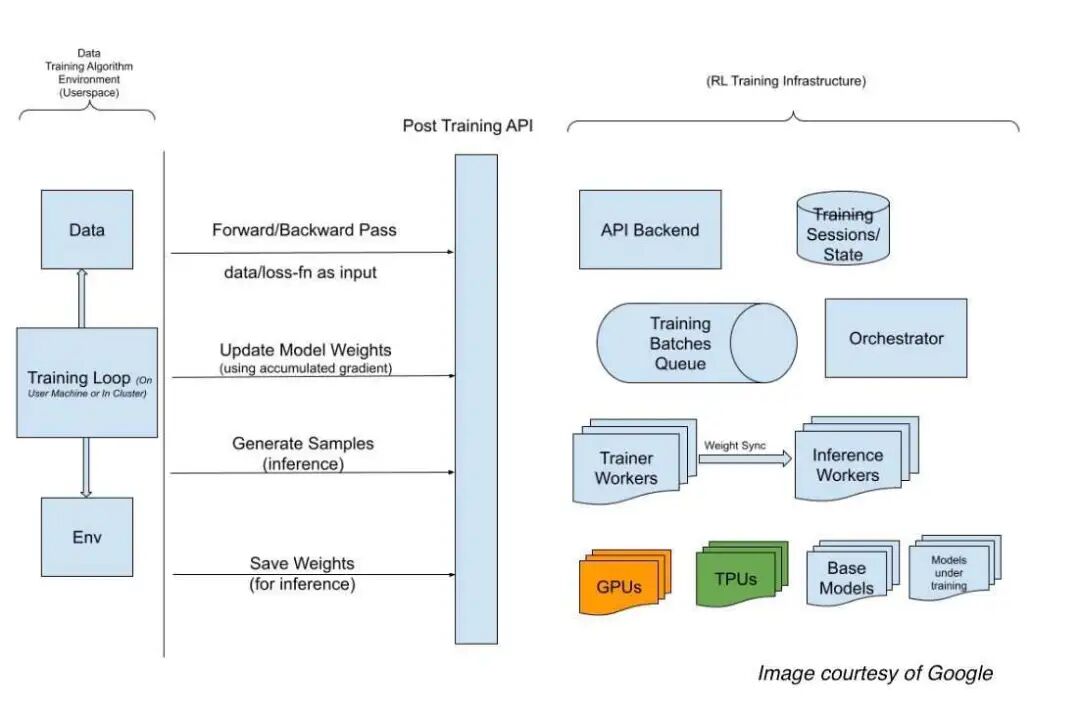
OpenRL 提升训练后微调效率的一种方式,是在基础设施上并行运行多个强化学习任务,从而提升整体 GPU 利用率。据谷歌研究人员称,传统的强化学习循环严格按顺序执行,GPU 往往在等待 CPU 或网络受限任务(尤其是奖励计算)期间处于空闲状态。
此外,OpenRL 通过明确划分职责来改善用户体验:研究人员可以专注于开发强化学习循环,工程师则负责执行和扩展训练后微调工作流。
在进行研发时,你无需直接在配备 GPU 的机器上运行强化学习循环,只需在 Mac 上运行循环,并将其指向 Kubernetes 集群或虚拟机上运行的训练 API 即可。
OpenRL 代码库还包含一个 autoresearch 方案,演示了如何在 Gemma 模型的 text-to-sql 工作流中针对参数扫描运行并行实验,并优化奖励信号。除了实际应用价值外,谷歌还将其作为自动化如何简化并扩展 AI 研究的范例加以重点介绍。
OpenRL 可轻松在 macOS、Nvidia GPU 和 GKE 上运行,并且因为它兼容 Tinker 端点,还能与 Tinker-Cookbook 集成。
值得一提的是,OpenRL 并非唯一尝试通过更好的关注点分离来简化训练后微调的项目。例如,FeynRL 确保了微调方案与系统逻辑的分离,让研究人员不仅能更轻松地开发和测试新方法,还可以借助 DeepSpeed、Ray 和 vLLM 等工具实现规模化应用。
原文链接:https://www.infoq.com/news/2026/06/google-open-rl-fine-tuning/
声明:本文由 InfoQ 翻译,未经许可禁止转载。
|  发表于 1 小时前
|
查看: 4|
回复: 0
发表于 1 小时前
|
查看: 4|
回复: 0
