我见过太多人第一次接触 Agent 框架时的反应——看完一堆架构图,什么 Orchestrator、Planner、Memory、Tool Registry,全是框,框和框之间连着箭头,看完点点头,感觉懂了。
然后问他:Agent 最核心的代码是什么?
答不上来。
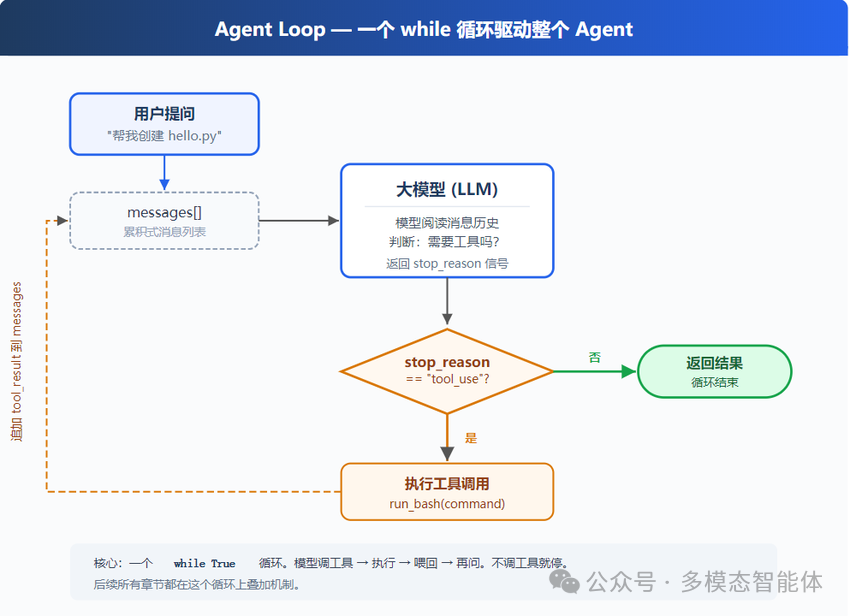
今天我们不看框,只看代码。而且只有一个核心:一个 while True 循环。
先说你现在是什么角色
在还没有 Agent 之前,你用大模型的方式大概是这样的:
你在对话框输入「帮我看看当前目录有哪些 Python 文件,然后分析一下哪个文件最大」。模型很给力,输出了一条命令:
ls -lh *.py | sort -k5 -rh
但它自己不跑。你切到终端,粘贴进去,回车,看到输出,再切回来,把输出复制进对话框,模型接着说「好,最大的是 main.py,我来分析一下……」。
然后给了下一条命令:
wc -l main.py
cat main.py | head -50
你再去终端跑,再把输出粘回来。
每一次来回,你都在做同一件事——把工具结果手动传回给模型。你是人工 API,你是那个「中间层」。
把这个中间层自动化,就是 Agent Loop 要做的唯一一件事。
两个信号,一个循环
Agent Loop 的逻辑极其简单,整个决策树只有两个分支:
模型调工具了?
├── 是 → 执行工具,把结果喂回去,再问一次
└── 否 → 模型觉得做完了,退出
翻译成信号:
| 信号 |
含义 |
动作 |
stop_reason == "tool_use" |
模型举手说「我要用工具」 |
执行 → 结果喂回去 → 继续循环 |
stop_reason != "tool_use" |
模型说「我做完了」 |
退出循环 |
注意这里「循环」是机械的,没有任何智能。智能全在模型里,循环只是它的手脚。
五步拆解:代码怎么跑起来的
第一步:用户问题进消息列表
messages = [{"role": "user", "content": query}]
这没什么神秘的,就是把你说的话放进一个列表。消息列表是整个对话历史的载体,后面每一轮的模型输出、工具结果,都会追加到这里。
第二步:把消息 + 工具定义一起发给模型
response = client.chat.completions.create(
model=MODEL,
messages=[{"role": "system", "content": SYSTEM}] + list(messages),
tools=TOOLS,
max_tokens=8000,
)
TOOLS 是你事先定义好的工具描述,告诉模型「你现在有哪些手」。在这里只有一个工具:bash。模型接到这个请求之后,会决定:要不要调工具,调哪个,传什么参数。这里面涉及到了 人工智能 在 Agent 架构中的核心决策机制。
第三步:追加模型回答,检查是否调了工具
assistant_msg = response.choices[0].message
msg = {"role": assistant_msg.role, "content": assistant_msg.content}
if assistant_msg.tool_calls:
msg["tool_calls"] = [
{
"id": tc.id,
"type": tc.type,
"function": {"name": tc.function.name, "arguments": tc.function.arguments},
}
for tc in assistant_msg.tool_calls
]
messages.append(msg)
if not response.choices[0].message.tool_calls:
return # 没调工具,结束
这里有个细节值得注意:模型的回复对象是 Pydantic 模型,直接塞回 messages 里下一次 API 调用会报错,必须先转成纯字典。
另一个细节:循环退出的条件不是「模型说完了」,而是「模型没有调工具」。这两件事不等价——模型可以一边输出文本,一边调工具;也可以只调工具不说话;也可以只说话不调工具。我们只关心它有没有举手要工具。
第四步:执行工具,收集结果
for tool_call in response.choices[0].message.tool_calls:
command = json.loads(tool_call.function.arguments)["command"]
output = run_bash(command)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": str(output),
})
run_bash 就是 subprocess.run 的包装,捕获 stdout + stderr,超时 120 秒,输出截断到 50000 字符。
这里每个工具调用结果都对应一个独立的 role: "tool" 消息,而且要通过 tool_call_id 和前面的调用对应上——这是 OpenAI 格式的要求,让模型知道哪个结果对应哪次调用。
第五步:把结果追加,回到第二步
# 上一步已经 append 了 tool 消息
# 直接回到 while True 的顶部,再次调用模型
循环结构本身就实现了「回到第二步」。这一轮模型看到的消息历史里,包含了它上一次的输出 + 工具执行结果,于是可以继续推理:「好,文件列表我拿到了,现在我需要……」
完整的 agent_loop 函数
把上面五步组装起来:
def agent_loop(messages: list):
while True:
response = client.chat.completions.create(
model=MODEL,
messages=[{"role": "system", "content": SYSTEM}] + list(messages),
tools=TOOLS,
max_tokens=8000,
)
# 追加模型回答(转为纯字典)
assistant_msg = response.choices[0].message
msg = {"role": assistant_msg.role, "content": assistant_msg.content}
if assistant_msg.tool_calls:
msg["tool_calls"] = [
{
"id": tc.id,
"type": tc.type,
"function": {"name": tc.function.name, "arguments": tc.function.arguments},
}
for tc in assistant_msg.tool_calls
]
messages.append(msg)
# 没有工具调用 → 退出
if not response.choices[0].message.tool_calls:
return
# 执行工具,结果追加回消息列表
for tool_call in response.choices[0].message.tool_calls:
command = json.loads(tool_call.function.arguments)["command"]
output = run_bash(command)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": str(output),
})
不到 30 行。这就是一个能跑起来的 Agent Harness 的最小内核。这种极简实现,也是 开源实战 中理解复杂项目源码的常见切入点。
一个容易被忽略的差异:Anthropic 格式 vs OpenAI 格式
这份代码用的是 OpenAI 兼容格式,但如果你去读 Anthropic 官方的 API 文档,会发现消息结构稍有不同。把这两种格式对比放在一起,能帮你更清楚地理解「信号」本身:
| 概念 |
Anthropic 格式 |
OpenAI 格式 |
| 判断模型是否调工具 |
response.stop_reason == "tool_use" |
response.choices[0].message.tool_calls 是否非空 |
| 工具调用 ID 字段 |
tool_use_id |
tool_call_id |
| 工具结果消息的 role |
user(把 tool_result 嵌在 user 消息里) |
tool |
| 工具调用块的格式 |
content 里的 type: "tool_use" 块 |
message.tool_calls 数组 |
形式不同,但本质信号是一样的:「模型有没有举手要工具」。这是 Agent Loop 唯一需要感知的信号,和用哪家的 SDK 无关。
顺手说一下 run_bash 里的那几行黑名单
dangerous = ["rm -rf /", "sudo", "shutdown", "reboot", "> /dev/"]
if any(d in command for d in dangerous):
return "Error: Dangerous command blocked"
有人看到这里会觉得:这个黑名单太简单了,根本拦不住什么。
对,拦不住。这不是一个安全系统,它只是一个 demo 级别的保护,防止新手运行代码时不小心让模型把自己的系统搞坏。真正的权限系统是另一个话题——需要 sandboxing、最小权限原则、操作审计、用户确认流程。这些是系统设计层面的事,不是几行黑名单能解决的。
30 行 vs 1729 行:CC 源码的差距在哪
Claude Code(CC)的 query.ts 有 1729 行。核心循环逻辑是上面这 30 行。那剩下的 1700 行干什么的?
全是保护机制。
差异一:循环继续的判断方式
上面的代码靠 tool_calls 是否非空来判断是否继续。CC 的做法不同:
// query.ts:554-558
// stop_reason === 'tool_use' is unreliable.
// Set during streaming whenever a tool_use block arrives.
let needsFollowUp = false
CC 用一个 needsFollowUp 标志位,在流式接收响应时,只要检测到 tool_use 块就设为 true。而不是等整个响应接收完再看 stop_reason。
为什么?因为流式响应里 stop_reason 可能滞后——内容块已经到了,元数据字段还没更新。如果只看 stop_reason,在流式场景下可能漏判,导致工具没被执行,循环提前退出。这是生产级代码对流式传输的具体适配,不是理论层面的差异。
差异二:State 对象扛了 10 个字段
我们的代码只维护了一个 messages 列表。CC 的循环 State 对象有 10 个字段:
| 字段 |
用途 |
messages |
当前迭代的消息数组 |
toolUseContext |
工具、信号、权限上下文 |
autoCompactTracking |
context 压缩状态追踪 |
maxOutputTokensRecoveryCount |
token 恢复尝试次数,上限 3 次 |
hasAttemptedReactiveCompact |
本轮是否已尝试响应式压缩 |
maxOutputTokensOverride |
输出 token 限制从 8K 升至 64K 的覆盖 |
pendingToolUseSummary |
后台用 Haiku 生成的工具调用摘要 |
stopHookActive |
停止钩子是否产生阻塞错误 |
turnCount |
轮次计数,用于 maxTurns 检查 |
transition |
上一次循环继续的原因 |
举两个有意思的:
maxOutputTokensRecoveryCount 最多重试 3 次——因为模型有时候会被 token 上限截断,输出还没说完就停了,生产系统需要检测并恢复,不能直接当成「模型做完了」退出。
pendingToolUseSummary 是在后台用更便宜的模型(Haiku)给工具调用历史生成摘要,压缩 context 长度省 token。这是在 Agent 长时间跑任务时做 context 管理的手段之一。
另外注意:taskBudgetRemaining(任务预算剩余)不在 State 上,源码注释明确写了 "Loop-local (not on State)"——它只是循环内部的局部变量,每次进入循环重置。
差异三:退出路径
我们的代码只有 1 条退出路径:模型不调工具。
CC 的退出路径覆盖了:
- 达到最大轮次(maxTurns)
- Context 超长(prompt too long),尝试压缩后继续
- 模型输出被 token 上限截断,恢复后继续
- 模型报错
- 用户主动中断(abort)
- Stop Hook 拦截并产生阻塞错误
- token budget 耗尽后的继续策略
- 响应式压缩重试
每种路径都有独立的处理逻辑和恢复策略,不是简单的 return 或 raise。我们的代码是单行道,CC 是带匝道和应急车道的高速公路。
差异四:流式并行工具执行
CC 有一个 StreamingToolExecutor(query.ts:561),在模型还在生成响应内容的时候,对已经到达的工具调用就开始执行了——不等模型说完。
具体怎么决定并发还是串行?看工具的 concurrency-safe 标记。安全的工具可以并行跑,有状态冲突风险的工具独占执行。这是纯性能优化,和循环本身的正确性无关,但在有大量工具调用的 Agent 任务里能显著减少总延迟。
把上面的东西放在一起
现在可以给出一个清晰的结论:
Agent = 模型决策 + Harness 执行 + 消息历史传递
这三件事加在一起就是 Agent。不需要 Planner、不需要 Memory、不需要 Orchestrator,都是在这三件事的基础上叠加的能力。
- 模型决策:「要不要用工具、用哪个、传什么参数」——这是智能,在模型里,代码管不了
- Harness 执行:「工具调了就跑,结果喂回去」——这是机械,30 行代码
- 消息历史传递:「每一轮的输入输出都追加进列表」——这是记忆,
messages 列表
三件事里,Harness 执行是我们今天写的这 30 行。剩下 1700 行 CC 源码,是围绕「Harness 执行」加的保护、恢复和优化。核心循环本身,始终没变。这种从核心逻辑入手理解复杂 后端 & 架构 的方式,也适用于其他大型系统。
手里只有 bash 的问题
目前这个 Agent 手里只有一个工具:bash。
这意味着:
- 读文件要
cat /path/to/file
- 写文件要
echo "..." > /path/to/file 或者让模型生成一个 heredoc
- 找文件要
find . -name "*.py"
- 移动文件要
mv
用起来又丑又脆——路径有空格就出问题,文件内容有特殊字符 echo 就炸,多步操作没有原子性。
下一篇给它真正的工具:read_file、write_file、list_dir、search_files、run_python。
会出现新问题:模型会不会一次调用多个工具?两个工具同时写同一个文件会怎样?并行执行的边界在哪?这些问题都将在后续的 Python 实战中逐一拆解。
 发表于 昨天 23:33
|
查看: 4|
回复: 0
发表于 昨天 23:33
|
查看: 4|
回复: 0
