给 Agent 一个 10 步的重构任务,它干得挺好——改了前两个文件,第三步跑测试,结果两个 case 挂了。从这一刻起,它的注意力全被测试报错吸走,最初“把所有 Python 文件改成 snake_case 命名”这件事悄悄消失了。等它走完一轮,你会发现测试修好了,但有将近一半的文件根本没动。
这不是模型本身的问题,而是上下文窗口的物理性质决定的。
上下文越长,系统提示越没用
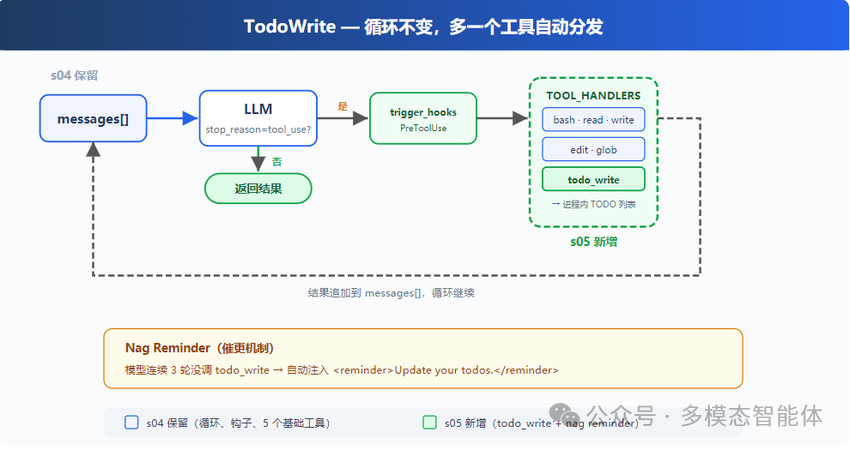
Agent 每调用一次工具,工具的返回值都会被追加进 messages 里。任务进行到第 5 步时,messages 中早已塞满 bash 输出、文件内容、编辑记录。而系统提示(SYSTEM)从第一轮起就固定在最靠前的位置,随着对话推进,在模型视野里越来越“远”了。
模型生成下一步动作时,对上下文里越靠近当前位置的 token 赋予的权重越高——这是 Transformer 注意力机制本身的特性,不是 bug,是设计如此。所以你在第 1 步设定的任务计划,到第 5 步时,影响力已经大幅衰减。对话越长,问题越严重:一个需要 15 步才能完成的重构,做完前三步后,第 4~15 步的计划几乎被稀释殆尽。Agent 进入“即兴发挥”状态,哪里有输出就扑向哪里。
这就是为什么上下文越长,系统提示越显得“没用”。
解法不是让模型“更聪明”,而是把计划钉在消息历史里
问题的根源很清楚:计划消失了,是因为它写在系统提示里,而系统提示随着对话深入逐渐失效。解法随之而来:让计划本身成为 messages 里的内容,并且每一步执行后都能更新它,使最新状态始终出现在上下文靠近当前位置的地方。
这就是 todo_write 工具的核心逻辑。
它不执行任何实际操作,不读文件,也不跑命令,只做一件事:接收一个带状态的任务列表,存入内存,同时将当前状态作为工具结果返回给模型。每次调用 todo_write,模型就像在 messages 中追加了一条新的进度快照——永远新鲜、永远可见。
实现细节
任务列表的数据结构
每个任务都是一个字典,包含两个字段:
{
"content": "Add type hints to all functions",
"status": "in_progress" # pending | in_progress | completed
}
三种状态对应任务的生命周期:待开始 → 进行中 → 已完成。
全局维护一个列表:
CURRENT_TODOS: list[dict] = []
注意,这是进程内存在,退出就清空。设计如此:同一个对话内共享状态,不同会话各自独立,不需要持久化。
run_todo_write 的实现
def run_todo_write(todos: list) -> str:
global CURRENT_TODOS
todos, error = _normalize_todos(todos)
if error:
return error
CURRENT_TODOS = todos
lines = ["\n\033[33m## Current Tasks\033[0m"]
for t in CURRENT_TODOS:
icon = {
"pending": " ",
"in_progress": "\033[36m▸\033[0m",
"completed": "\033[32m✓\033[0m"
}[t["status"]]
lines.append(f" [{icon}] {t['content']}")
print("\n".join(lines))
return f"Updated {len(CURRENT_TODOS)} tasks"
有个细节值得留意:函数里的 print 是给终端看的,让人能知道 Agent 在规划什么;但 return 的字符串才是真正重要的——它作为工具结果追加入 messages,模型下一轮生成时就会读到它。
_normalize_todos 负责输入校验,因为模型有时会把参数序列化成 JSON 字符串而不是直接传列表,需要兼容两种格式:
def _normalize_todos(todos):
if isinstance(todos, str):
try:
todos = json.loads(todos)
except json.JSONDecodeError:
try:
todos = ast.literal_eval(todos)
except (SyntaxError, ValueError):
return None, "Error: todos must be a list or JSON array string"
if not isinstance(todos, list):
return None, "Error: todos must be a list"
for i, t in enumerate(todos):
if not isinstance(t, dict):
return None, f"Error: todos[{i}] must be an object"
if "content" not in t or "status" not in t:
return None, f"Error: todos[{i}] missing 'content' or 'status'"
if t["status"] not in ("pending", "in_progress", "completed"):
return None, f"Error: todos[{i}] has invalid status '{t['status']}'"
return todos, None
接入 dispatch 系统
上一版本已经有一套 TOOL_HANDLERS 分发机制:工具调用根据 tool_call.function.name 找到对应处理函数。新增 todo_write 只需两步。
第一步,把工具定义加入 TOOLS 列表:
{
"type": "function",
"function": {
"name": "todo_write",
"description": "Create and manage a task list for your current coding session.",
"parameters": {
"type": "object",
"properties": {
"todos": {
"type": "array",
"items": {
"type": "object",
"properties": {
"content": {"type": "string"},
"status": {
"type": "string",
"enum": ["pending", "in_progress", "completed"]
}
},
"required": ["content", "status"]
}
}
}
}
}
}
第二步,加进 dispatch map:
TOOL_HANDLERS["todo_write"] = run_todo_write
分发逻辑不用改。todo_write 进来后,TOOL_HANDLERS.get("todo_write") 找到函数,解析参数,调用,返回结果——与 bash、read_file 走完全一样的路径。
系统提示加一句话
SYSTEM = (
f"You are a coding agent at {WORKDIR}. "
"Before starting any multi-step task, use todo_write to plan your steps. "
"Update status as you go."
)
这句话为模型建立了默认行为模式:收到任务 → 先列计划 → 再动手。没有这句,模型不会主动使用 todo_write,因为它根本不知道这个工具的预期使用时机。
Nag Reminder:连续 3 轮没更新就提醒一次
还有个很实际的问题:模型执行途中容易忘了更新 TODO 状态。任务开始时列了计划,可做了三四个工具调用后,停下来更新 todo_write 的意识就被稀释掉了。
解法是在 Agent 循环里加一个计数器:
rounds_since_todo = 0
def agent_loop(messages: list):
global rounds_since_todo
while True:
# 超过 3 轮没调 todo_write,注入提醒
if rounds_since_todo >= 3 and messages:
messages.append({
"role": "user",
"content": "<reminder>Update your todos.</reminder>"
})
rounds_since_todo = 0
response = client.chat.completions.create(...)
messages.append(response.choices[0].message)
if not response.choices[0].message.tool_calls:
# 模型停止工具调用,触发 Stop 钩子后退出
...
return
rounds_since_todo += 1 # 每轮工具调用递增
for tool_call in response.choices[0].message.tool_calls:
...
# 调用 todo_write 时重置计数器
if tool_call.function.name == "todo_write":
rounds_since_todo = 0
...
rounds_since_todo 是全局的,每轮工具调用递增,todo_write 被调用时归零。连续三轮没调,就往 messages 里塞一条 role: user 的提醒消息。
为什么用 role: user 而不是 role: system?很多模型对 user 消息的响应优先级高于 system,注入到对话流里比修改系统提示效果更稳定。
Agent 执行的典型流程

一个正常工作的流程是这样的:
- 用户发送任务:“重构这个文件,加类型注解、docstring,再补一个 main guard”
- Agent 第一次工具调用:
todo_write,列出 3 个 pending 的步骤
- 调用
read_file 读文件内容
- 调用
edit_file 加类型注解,同时更新 todo_write,第一步改成 in_progress
- 完成后再次调用
todo_write,第一步改成 completed,第二步改成 in_progress
- 继续执行,直到所有步骤变成
completed
- 模型停止工具调用,输出总结
每次调用 todo_write,当前的完整任务列表就会出现在 messages 中。模型在后续每一轮生成时,都能看到“现在在做哪步、还有哪些没做”——这才是这个工具真正有效的原因。
这不是在增加执行能力,是在增加规划能力
todo_write 没让 Agent 能做更多事情。它在不改变 Agent 执行能力的前提下,增加了结构化规划和进度追踪能力。
两者的区别很重要。执行能力是“Agent 能调用什么工具”,规划能力是“Agent 知道自己在做什么、下一步该做什么”。上下文稀释导致的问题,根源在规划能力的丧失,不在执行能力。所以加一个不执行任何操作的工具,专门用来保持规划状态,就能把问题解决。
这个设计思路在更复杂的系统里会一再出现:不是给 Agent 加更强的工具,而是给 Agent 加更好的状态管理。
相比上一版本,改动极小
上一版本引入了 Hooks 系统:四个事件(UserPromptSubmit、PreToolUse、PostToolUse、Stop)、一个注册表、一个触发函数。这套机制这一版一行没动。
这一版的变更点只有四个:
- 新增
run_todo_write() 和 _normalize_todos() 两个函数
TOOLS 列表里加一条 todo_write 的定义TOOL_HANDLERS 里加一行 dispatch 映射agent_loop 里加一个 rounds_since_todo 计数器和 reminder 注入
SYSTEM 提示改了一句话。其他全部不变。
加一个工具,改一行提示,加一个计数器——Agent 就从“做着做着就偏”变成了“先列计划再执行,做完打钩,忘了提醒你”。
往深处看:任务系统的两个版本
如果去翻真实的 Claude Code 源码,会发现任务系统有两套实现并存。
V1(也就是这一版实现的原型):一个工具,数据在进程内存的 AppState 里维护,退出清空。交互简单,适合单次会话内的任务追踪。
V2(后面会讲到):四个独立工具(Create/Get/Update/List)、文件持久化(存在 Claude 配置目录的 tasks/{taskListId}/{taskId}.json)、blockedBy 字段支持依赖图、proper-lockfile 做并发安全。
两套系统由 isTodoV2Enabled() 控制切换:交互式会话默认启用 V2,非交互式会话(通过 SDK 调用)默认使用 V1。设置环境变量 CLAUDE_CODE_ENABLE_TASKS 可以在非交互式下强制开启 V2。
注意源码里有一个容易误读的注释:“Force-enable tasks in non-interactive mode”,描述的是这个环境变量路径的用途,而不是 isTodoV2Enabled() 默认分支的返回值语义。读源码的时候要区分清楚。
V1 和 V2 还有一个细节差异:V1 没有 activeForm 字段,V2 有,用来给 UI 的 spinner 展示“正在做什么”。终端版本不需要这个字段,因为 print 直接输出就够了。
跑起来看什么
运行起来之后,重点观察几件事:
- 收到任务后,第一次工具调用是不是
todo_write?如果模型直接开始调 bash 或 read_file,说明系统提示的引导没生效,需要调整提示措辞。
- TODO 列了几步?和任务的实际复杂度匹配吗?过少说明模型对任务理解不够细;过多说明模型在过度拆解,增加了不必要的上下文占用。
pending → in_progress → completed 的状态流转有没有发生?如果所有任务直接跳过 in_progress,说明模型在批量完成后才更新状态,中间过程没有追踪,遇到中断就会丢失进度。- reminder 在什么时候触发?如果一个简单任务就触发了 reminder,说明任务分解可能太细,每步之间频繁切换工具,导致 todo 更新间隔拉长。
这几个观察点加在一起,基本就能判断 Agent 的规划行为是否符合预期。
下一步要面对的问题是:任务大到一定程度,再完善的 TODO 列表也扛不住。如果把“重构整个认证模块”拆成 30 个步骤,放在同一个对话里执行,上下文本身就会成为瓶颈。
解法是把大任务拆成子任务,每个子任务开一个独立的 Agent,各自有干净的上下文,互不干扰。下一版会讲这个。
 发表于 昨天 23:36
|
查看: 3|
回复: 0
发表于 昨天 23:36
|
查看: 3|
回复: 0
