上周帮一个朋友看他写的 Agent,代码逻辑很简单:一个 while 循环,调用 LLM,拿到工具调用就执行,执行完把结果塞回 messages,再调用 LLM。一个标准的 Agent Loop,几十行代码就能跑起来。
但他给我看的是另一个版本——同样的循环,已经膨胀到两百多行。我让他解释每一段在干什么,他想了半天,说:“这段是上周加的,要给每次 bash 调用打日志;这段是给写文件加权限确认;这段是上上周加的,操作完成后自动 git add;这段……我也不记得为什么加了。”
这是几乎所有 Agent 项目都会经历的阶段。核心循环很简单,但“附加需求”会不断冒出来:记日志、做权限检查、发通知、统计 token 消耗、自动备份……每一个需求单独看都很合理,全部塞进循环之后,循环就不再是“循环”了,它变成了一个谁都不敢动的巨型 if-else 堆。
问题出在哪?你想扩展的是 Agent 的“行为”,但你改动的却是 Agent 的“核心”。这两件事本来应该是分开的。
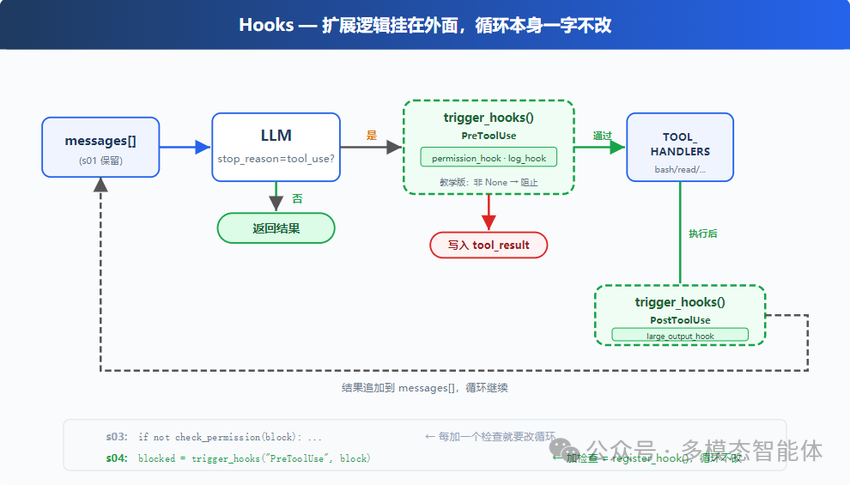
循环应该只做一件事
先看一个最简化的 Agent Loop 长什么样:
def agent_loop(messages):
while True:
response = client.chat.completions.create(
model=MODEL,
messages=[{"role": "system", "content": SYSTEM}] + messages,
tools=TOOLS,
)
messages.append(response.choices[0].message)
if not response.choices[0].message.tool_calls:
return # 模型没有调用工具,这一轮结束
results = []
for tool_call in response.choices[0].message.tool_calls:
handler = TOOL_HANDLERS.get(tool_call.function.name)
output = handler(**json.loads(tool_call.function.arguments))
results.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": str(output),
})
messages.extend(results)
这段代码只做四件事:调用 LLM、判断要不要执行工具、执行工具、把结果写回对话。这四件事是 Agent Loop 的本质,剩下的一切——权限、日志、通知、统计——都是“附加值”,本不该出现在这个函数里。
但现实是,大部分人第一次给 Agent 加权限检查的时候,都是直接在 for 循环里插一行 if not check_permission(tool_call): ... 。这没什么错,能跑就行。问题是当你加第二个、第三个检查的时候,循环体里会出现越来越多互相纠缠的 if,最后变成开头那两百行代码。
Hooks:把“扩展点”做成一等公民
解决办法其实很朴素:把所有“附加逻辑”都写成独立的函数,循环本身不直接调用它们,而是在固定的几个时间点“喊一声”,谁注册了就谁来响应。
这就是 hook 机制。实现起来比想象中简单,核心只有三样东西:
# 钩子注册表:事件名 -> 回调函数列表
HOOKS = {
"UserPromptSubmit": [],
"PreToolUse": [],
"PostToolUse": [],
"Stop": [],
}
def register_hook(event: str, callback):
HOOKS[event].append(callback)
def trigger_hooks(event: str, *args):
for callback in HOOKS[event]:
result = callback(*args)
if result is not None:
return result
return None
HOOKS 是一个字典,key 是事件名,value 是回调函数列表。 register_hook 往列表里加函数, trigger_hooks 按顺序执行某个事件下的所有回调。
有一个细节值得多说两句: trigger_hooks 的返回值。如果某个回调返回了 None ,表示“我看过了,没意见,继续往下走”;如果返回了非 None 的值(一个字符串、一段说明),就表示“我有话要说,到此为止”。一个简单的约定,同时承担了两种语义——在 PreToolUse 上是“拦截这次工具调用”,在 Stop 上是“先别退出,把这段话当成新的输入继续跑”。一个返回值约定,两种行为,这也是为什么这套机制能用极少的代码覆盖很多场景。
四个挂载点,覆盖一次完整的交互
接下来的问题是:到底该在哪些时间点“喊一声”?
答案取决于你想在 Agent 的生命周期里插入什么。我自己常用的是四个点,刚好覆盖一次用户交互的全过程:用户输入提交时、工具执行前、工具执行后、循环准备退出时。
UserPromptSubmit:在请求送进 LLM 之前
用户刚敲完一行 prompt,还没进入 LLM。这是修改或检查输入的最后机会——比如往对话里临时塞一段上下文,或者对输入做敏感词过滤。
def context_inject_hook(query: str):
print(f"[HOOK] working in {WORKDIR}")
return None
register_hook("UserPromptSubmit", context_inject_hook)
在主循环里,用户输入之后立刻触发:
query = input(">> ")
trigger_hooks("UserPromptSubmit", query)
history.append({"role": "user", "content": query})
agent_loop(history)
这个例子只打了一行日志,但同样的位置可以做得更激进——比如根据当前工作目录、当前 git 分支,动态往对话里注入一段说明,让模型在执行任务前就知道“现在在哪个项目、哪个分支”。
这是最容易踩坑、也是最值得花心思的一个点。模型已经决定要执行某个工具调用了,但还没真正执行——这时候挂的 hook,决定了“这次调用到底会不会发生”。
权限检查就应该放在这里:
DENY_LIST = ["rm -rf /", "sudo", "shutdown", "reboot", "mkfs", "dd if="]
def permission_hook(tool_call):
if tool_call.function.name == "bash":
args = json.loads(tool_call.function.arguments)
for pattern in DENY_LIST:
if pattern in args.get("command", ""):
return f"Permission denied: matched '{pattern}'"
if tool_call.function.name in ("write_file", "edit_file"):
args = json.loads(tool_call.function.arguments)
path = (WORKDIR / args.get("path", "")).resolve()
if not path.is_relative_to(WORKDIR):
choice = input(f" 写入 {path} 超出工作目录,允许吗?[y/N] ")
if choice.lower() not in ("y", "yes"):
return "Permission denied by user"
return None
register_hook("PreToolUse", permission_hook)
同一个事件上可以挂多个 hook,执行顺序就是注册顺序。比如再加一个纯日志的:
def log_hook(tool_call):
args = json.loads(tool_call.function.arguments)
preview = str(list(args.values())[:2])[:60]
print(f"[HOOK] {tool_call.function.name}({preview})")
return None
register_hook("PreToolUse", log_hook)
permission_hook 注册在前, log_hook 在后——如果权限检查拦截了这次调用, trigger_hooks 在第一个回调就返回了非 None 值, log_hook 根本不会被执行。这个顺序是有意义的:被拒绝的调用不需要留下“执行日志”,只需要留下“拦截记录”(这部分逻辑可以写在 permission_hook 内部)。
PostToolUse:工具执行完之后,结果还没回到对话里
工具已经跑完了,输出也拿到了,但还没塞进 messages 。这个点适合做“基于结果”的判断——比如输出太大要预警,或者某类操作完成后要触发副作用(自动 git add、发通知)。
def large_output_hook(tool_call, output):
if len(str(output)) > 100000:
print(f"[HOOK] ⚠ {tool_call.function.name} 输出过大:{len(str(output))} 字符")
return None
register_hook("PostToolUse", large_output_hook)
这个示例里 PostToolUse 的返回值没有被使用,但它完全可以被用来“改写”即将进入对话的结果——比如把超长输出截断后再塞回去,避免一次工具调用就吃掉大半个 context window。
Stop:循环准备退出的最后一关
当模型这一轮没有调用任何工具,意味着它认为任务完成了,循环准备退出。这时候触发 Stop hook:
def summary_hook(messages):
tool_count = sum(1 for m in messages if m.get("role") == "tool")
print(f"[HOOK] 本次会话共执行 {tool_count} 次工具调用")
return None
register_hook("Stop", summary_hook)
这就用到了前面那条返回值约定:如果 Stop hook 返回了一段字符串,循环不会真的退出,而是把这段字符串当成一条新的消息塞进 messages ,再跑一轮。
if not response.choices[0].message.tool_calls:
force = trigger_hooks("Stop", messages)
if force:
messages.append({"role": "user", "content": force})
continue
return
这个机制能干什么?想象一个场景:模型说“任务完成”,但你写了一个 Stop hook,检查发现它声称修改的文件其实并没有被写入。这时候 hook 返回一句“你说完成了,但 xxx.py 没有任何改动,请确认”,循环就不会退出,而是把这句话当成新指令,让模型自己去发现并修正问题。
循环本身,只改了一行
把上面四个 hook 全部接上之后,回头看循环代码,会发现一个有意思的事情:循环结构和最初那个“四步走”的极简版本几乎一模一样,唯一变化的地方,是把原来直接调用 check_permission(tool_call) 的那一行,换成了 trigger_hooks("PreToolUse", tool_call) :
for tool_call in response.choices[0].message.tool_calls:
blocked = trigger_hooks("PreToolUse", tool_call)
if blocked:
results.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": str(blocked),
})
continue
handler = TOOL_HANDLERS.get(tool_call.function.name)
output = handler(**json.loads(tool_call.function.arguments))
trigger_hooks("PostToolUse", tool_call, output)
results.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": str(output),
})
外加循环退出前的那个 Stop 判断、循环外面用户输入后的 UserPromptSubmit。三处调用,加起来不超过五行。从这天起,再有新的需求——记日志、加通知、做统计——都不再需要碰这个函数了,写一个新函数,调一次 register_hook ,就结束了。
我觉得这是这个模式真正的价值:它不是让代码“更优雅”这种说不清楚的好处,而是给了你一个承诺——核心循环的代码量从今天起不会再增长。所有未来的需求,都会以“新增一个文件、新增一个函数”的形式出现,而不是“修改这个已经被无数功能依赖、谁都不敢动的核心函数”。如果对这种架构设计思路感兴趣,你会发现它在很多场景下都能派上用场。
Claude Code 里的 hook,比这复杂得多
上面这套是我自己项目里在用的精简版本,四个事件基本能覆盖日常需求。但如果去翻 Claude Code 的源码( toolHooks.ts 、 hooks.ts 、 coreTypes.ts ),会发现它的 hook 系统复杂得多,复杂到我觉得有必要单独讲讲——因为里面有几个设计,是我自己这套精简版本完全没考虑到、但在真实生产环境里非常关键的。
第一点,也是最直观的一点:事件不是 4 个,是 27 个。 coreTypes.ts 里定义的 hook 事件,除了 PreToolUse / PostToolUse / UserPromptSubmit / Stop 之外,还包括会话生命周期(SessionStart、SessionEnd、Setup)、子 Agent 生命周期(SubagentStart、SubagentStop)、上下文压缩前后(PreCompact、PostCompact)、权限相关(PermissionRequest、PermissionDenied)、文件变化(FileChanged、CwdChanged)等等。模式是一样的——本质上还是“在某个时间点喊一声,谁注册了谁响应”——区别只是 Claude Code 把这个模式用到了 Agent 生命周期里几乎所有可观察的节点上。
第二点更有意思:hook 的返回值远不止“None / 非 None”这么简单。我们前面那套返回值只有两种状态。Claude Code 里 hook 的返回值是一个有 14 个字段的 HookResult 对象,常用的字段包括 permissionBehavior (allow / deny / ask / passthrough,hook 可以直接给出权限决策)、 updatedInput (hook 可以修改即将执行的工具调用的参数)、 additionalContext (往对话里追加上下文)、 blockingError (带着错误信息阻塞,并把错误注入对话让模型自己纠正)、 preventContinuation (阻止循环继续)。光是 updatedInput 这一个字段,能做的事情就比“允许/拒绝”丰富得多——比如一个 hook 发现模型想写入的路径有问题,不是直接拒绝,而是把路径改写成正确的之后再放行,模型甚至不会意识到自己的输入被“修正”过。
第三点是我读源码时印象最深的一个设计:hook 说“允许”,不代表真的允许。 toolHooks.ts 里有这样一段逻辑——即使某个 PreToolUse hook 返回了 permissionBehavior: allow ,系统仍然会去检查 settings.json 里配置的 deny/ask 规则;如果某个工具在配置里被显式禁用了,hook 的“允许”是不能覆盖这条规则的。这个设计的意义在于:hook 本身是用户或项目可以自己写的脚本,理论上可能被写错或被篡改。如果 hook 的 allow 拥有最终决定权,一个写错的 hook 脚本就能突破项目级的安全配置;而 deny/ask 规则是更上层、更难被意外绕过的配置,hook 只能在“deny/ask 规则允许的范围内”做进一步收紧,不能反过来放宽。换句话说,权限系统里拒绝的优先级永远高于允许,无论这个“允许”来自哪一层。我们前面那个 permission_hook 返回 None 就等于允许,没有任何“更上层规则”去复核——这在本地写脚本玩玩没问题,但要给团队用、要接入有写权限的生产环境,这一层是绕不过去的。
第四点解决的是一个隐患:Stop hook 有一个防死循环的开关。前面提到 Stop hook 可以返回一段话,让循环“先别退出,继续跑一轮”。但这里藏着一个风险——如果 Stop hook 每次都触发同一个错误(比如它检查的某个条件永远不满足),循环就会陷入“模型自纠 → Stop hook 再报错 → 模型再自纠”的死循环,永远退不出去。Claude Code 用一个叫 stopHookActive 的状态字段处理这个问题:当 Stop hook 产生了 blockingError、循环被强制续跑之后,下一轮会带着 stopHookActive: true 这个标记重新进入;再下一次到达 Stop 判断时,如果这个标记是 true,Stop hook 就不会再次触发——相当于“这一轮的强制续跑额度已经用过了,不能无限续”。
第五点,也是最后一点:PostToolUse 也能让 Agent“体面地”停下来。如果一个 PostToolUse hook 返回 preventContinuation: true ,会产生一个特殊的内部信号( hook_stopped_continuation ),主循环检测到之后会主动退出。我自己一开始看到这个设计时,下意识觉得这是某种“异常终止”的兜底机制——但读完上下文才发现完全不是,它是一种正常的、设计内的退出路径:某个 hook 判断“任务到这里就该结束了”,于是让 Agent 停下来——这是“完成”,不是“出错”。
这套思路能直接搬到你的项目里吗
能,而且我建议这么做——但有取舍。
如果你的 Agent 是给自己用、给小团队内部用,前面那个三件套( HOOKS 字典 + register_hook + trigger_hooks )外加四个挂载点,基本就够了。它能解决“核心循环不断膨胀”这个最痛的问题,成本几乎为零——加起来不超过 15 行代码。
但如果你的 Agent 要接触真实的写权限(写文件、执行命令、调用外部 API),尤其是会被多人使用、hook 脚本可能来自不同来源的场景,上面提到的几点——allow 不能绕过 deny/ask、防死循环的状态标记、hook 能修改工具输入而不只是拦截——这些都不是“锦上添花”的功能,而是安全边界的一部分。一个只会“允许/拒绝”的 hook 系统看起来够用,但只要有一天某个 hook 脚本写错了、或者被恶意修改了,“允许”就会变成“无条件允许”,没有任何上层规则能兜底。在构建这类涉及安全性的后端系统时,从开源项目中借鉴成熟方案往往是最高效的路径。
我自己现在的做法是:本地实验和小工具,用精简版三件套;一旦涉及到团队共享、涉及写权限的场景,至少把“deny 规则独立于 hook、且优先级更高”这一条补上——这是性价比最高的一条,加起来可能就十几行代码,但能把“hook 脚本出错”和“系统被攻破”之间画一条明确的线。至于 27 个事件、14 个字段的完整 HookResult,这些更多是 Agent 复杂到一定程度之后自然会长出来的东西,不需要一开始就照搬。先把核心循环和扩展点解耦,剩下的可以慢慢加。
如果你现在的 Agent 项目里,权限检查、日志、通知这些逻辑还混在主循环里——花十分钟把它们搬出去,会发现循环突然“轻”了很多。
一个 Hook 机制,解决 Agent Loop 越写越臃肿的问题。云栈社区上还有很多类似的工程化实践分享,值得一逛。
 发表于 昨天 23:37
|
查看: 3|
回复: 0
发表于 昨天 23:37
|
查看: 3|
回复: 0
