上一个版本的 Agent 已经能熟练调用多个工具——读文件、写文件、执行 bash 命令,整条链路跑下来相当顺畅。但顺畅得让人有点不放心。
我们不妨做个小实验。让 Agent 帮你“清理一下项目里的临时文件”。
它可能会毫不犹豫地生成这条命令:
rm -rf /tmp/../
甚至更夸张一点:
rm -rf /
没有任何机制会拦截它。Agent 循环会兴高采烈地把这条命令传给 subprocess.run(),等它静默执行完毕,然后把一段 (no output) 的结果返回给模型。
问题并不出在模型身上。模型只是在努力完成你交代的任务。真正的问题隐藏在架构层面:我们把安全的决策权完全托付给了模型的判断,而没有在代码层设置任何硬性的保障措施。
安全不能建立在信任上
“但我可以在 system prompt 里明确告诉它不能删系统文件啊。”
这话没错,但远远不够。Prompt 是软约束,代码才是硬约束。模型可能产生幻觉,可能被用户精心构造的 prompt 绕过,也可能在多轮对话后淡忘了最初的指令。而且,你永远无法在 system prompt 里穷举所有可能的危险操作。
安全红线必须由代码来守住,这条检查点要放在工具执行之前,不管模型当时在想什么,都必须无条件经过。
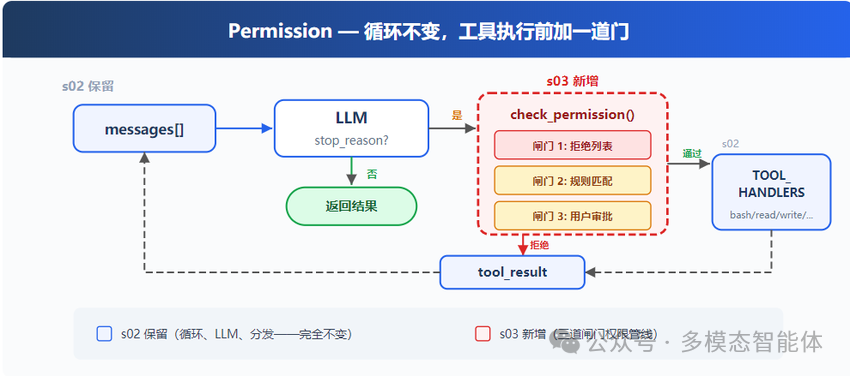
这正是本文要深入探讨的内容:在工具执行前插入一条权限管线(Permission Pipeline),由三道闸门串联而成,每个工具调用都逃不过它的审视。
三道闸门的设计
整个结构可以用下面这张图清晰地勾勒出来:

三道闸门对应着三种不同的决策逻辑:
- 闸门 1:永远拒绝。 某些操作,无论任何场景,无论用户怎么解释,一律直接拒绝。这是一张硬拒绝名单,上榜的操作不问原因、不等待确认,当场返回错误。
- 闸门 2:视情况而定。 有些操作本身未必危险,但在特定条件下需要谨慎对待——比如所有包含
rm 的 bash 命令,或者企图将文件写到工作区之外的操作。这里是规则匹配的核心地带:对工具名和参数进行检查,一旦命中,就交给闸门 3 处理。
- 闸门 3:由人来定。 闸门 2 命中后,不会自动拒绝,而是暂停流程,将操作细节展示给用户,等待一个明确的
y/N 指令。用户允许则执行,拒绝则返回 Permission denied。
这三道门是串联关系,而非并联——调用必须依照 1、2、3 的顺序依次通过,一旦前面的门命中,后续的门就不再执行。绝大多数日常操作(如读文件、glob 搜索、执行常规测试脚本)会毫无波澜地穿过这三道门,直接落入工具执行步骤。
逐门实现
闸门 1:拒绝名单
DENY_LIST = [
"rm -rf /",
"sudo",
"shutdown",
"reboot",
"mkfs",
"dd if=",
"> /dev/sda",
]
def check_deny_list(command: str) -> str | None:
for pattern in DENY_LIST:
if pattern in command:
return f"Blocked: '{pattern}' is on the deny list"
return None
逻辑非常直白:遍历名单,如果命令字符串中包含危险模式,就返回拒绝原因;否则返回 None。
这里需要明确指出一个事实:单纯的字符串匹配并非坚不可摧的安全机制。rm -rf / 可以写成 rm -rf /(多个空格),或者通过 shell 变量展开、子命令替换等方式绕过。这份 DENY_LIST 的核心价值在于拦截模型“无意中”产生的危险操作,而不是对抗蓄意的攻击。
真正的生产级实现(例如 Claude Code 的做法)会采用更细粒度的规则和来自多个源的配置,后文会展开讨论。
闸门 1 目前仅检查 bash 命令。文件类工具不经过此门——文件操作的限制由 safe_path 处理,那是另一道防线,不属于权限管线的一部分。
闸门 2:规则匹配
PERMISSION_RULES = [
{
"tools": ["write_file", "edit_file"],
"check": lambda args: not (WORKDIR / args.get("path", "")).resolve().is_relative_to(WORKDIR),
"message": "Writing outside workspace",
},
{
"tools": ["bash"],
"check": lambda args: any(
kw in args.get("command", "")
for kw in ["rm ", "> /etc/", "chmod 777"]
),
"message": "Potentially destructive command",
},
]
def check_rules(tool_name: str, args: dict) -> str | None:
for rule in PERMISSION_RULES:
if tool_name in rule["tools"] and rule["check"](args):
return rule["message"]
return None
规则的结构可以概括为:工具范围 + 条件检查 + 描述文字。
每条规则只对 tools 字段中列出的特定工具生效。条件逻辑被封装在一个 lambda 函数里,它接收工具调用的参数字典,返回 True 或 False。命中后返回的描述文字会被传递到闸门 3,用以向用户解释。
这种设计的精妙之处在于规则与执行逻辑的解耦。想增加一条新规则?只需写一个字典塞进 PERMISSION_RULES 列表,完全不需要修改任何现有函数。规则本身的复杂度可以无限扩展——你可以检查文件扩展名、排查命令中是否出现生产环境域名、甚至校验参数的长度。
请注意第一条规则的写法:(WORKDIR / args.get("path", "")).resolve().is_relative_to(WORKDIR)。进行这种路径解析是必要的,因为 Agent 可能会传递 ../../etc/passwd 这样的相对路径,直接进行字符串匹配会存在疏漏。
闸门 3:用户审批
def ask_user(tool_name: str, args: dict, reason: str) -> str:
print(f"\n\033[33m⚠ {reason}\033[0m")
print(f" Tool: {tool_name}({args})")
choice = input(" Allow? [y/N] ").strip().lower()
return "allow" if choice in ("y", "yes") else "deny"
这是一个简单的终端交互模块,将触发原因、工具名称和参数清晰地打印出来,然后静候用户决策。
这里有一个关键细节:默认选项是拒绝([y/N],大写的 N 暗示默认值)。用户若直接按回车,就会被视为拒绝。这就是安全设计里的“默认安全”(Secure by Default)原则——在情况不明朗时,倾向保守。
串联成管线
将三道门串联起来的函数如下:
def check_permission(tool_call) -> bool:
# 闸门 1:仅检查 bash
if tool_call.function.name == "bash":
args = json.loads(tool_call.function.arguments)
reason = check_deny_list(args.get("command", ""))
if reason:
print(f"\n\033[31m⛔ {reason}\033[0m")
return False
# 闸门 2 & 3
args = json.loads(tool_call.function.arguments)
reason = check_rules(tool_call.function.name, args)
if reason:
decision = ask_user(tool_call.function.name, args, reason)
if decision == "deny":
return False
return True
返回值 True 代表放行,False 代表拦截。调用方则根据此布尔值决定是否继续执行。
植入 Agent 循环
上一个版本的 Agent Loop 核心片段大概是这样的:
for tool_call in response.choices[0].message.tool_calls:
handler = TOOL_HANDLERS.get(tool_call.function.name)
output = handler(**json.loads(tool_call.function.arguments))
results.append({"role": "tool", "tool_call_id": tool_call.id, "content": str(output)})
在植入权限管线之后,只做了一处核心变动:
for tool_call in response.choices[0].message.tool_calls:
print(f"\033[36m> {tool_call.function.name}\033[0m")
# 权限检查——这是到当前版本唯一的核心变动
if not check_permission(tool_call):
results.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": "Permission denied."
})
continue
handler = TOOL_HANDLERS.get(tool_call.function.name)
output = handler(**json.loads(tool_call.function.arguments))
results.append({"role": "tool", "tool_call_id": tool_call.id, "content": str(output)})
请注意权限被拒绝时的处理方式:并非粗暴地跳出整个循环,而是将 "Permission denied." 作为一次工具调用的结果追加到 results 中,然后执行 continue。这样一来,模型仍然会收到关于此次工具调用的反馈,知晓操作被拒的事实,从而相应地调整后续行为——比如,它会向用户解释为什么它无法完成该操作。
这体现了 Harness 层的一个关键设计原则:循环结构保持稳定,仅在循环内部插入拦截点。上一个版本的循环逻辑照单全收,现在,仅仅是在工具执行前多了一行 if not check_permission(...): continue,循环的整体语义未受丝毫影响。
跑起来是什么感觉
我们来尝试几个 prompt,看看不同操作会走上哪条路。
列出当前目录下的文件
Agent 会调用 bash("ls -la") 或 glob("*")。bash 调用途经闸门 1(ls 不在拒绝名单),再过闸门 2(ls 不含 rm 等关键词),直接放行。终端不会有任何提示,命令静默执行。
删掉 /tmp 下所有 .log 文件
Agent 会生成 bash("rm /tmp/*.log")。命令中包含 rm(注意后面的空格,这是闸门 2 的检查关键字),触发规则匹配,闸门 3 随即弹出:
⚠ Potentially destructive command
Tool: bash({'command': 'rm /tmp/*.log'})
Allow? [y/N]
决策权交到了你的手上。
执行 sudo apt update
sudo 赫然在拒绝名单上,闸门 1 直接将其挡下:
⛔ Blocked: 'sudo' is on the deny list
不等用户确认,不给模型任何商量余地。
把配置写入 /etc/myapp.conf
Agent 调用 write_file("/etc/myapp.conf", ...),/etc/myapp.conf 路径解析后,判定其不在 WORKDIR 之内,从而触发第一条规则 “Writing outside workspace”,步入闸门 3 等待用户确认。
生产版实现有什么不同
拿 Claude Code 的权限系统来对比一下,你就能看清当前实现在哪里做了简化,以及这些简化的代价是什么。
权限结果不止两种,而是四种
我们当前的 check_permission() 返回一个布尔值:通过或拦截。但 Claude Code 的 PermissionResult 拥有四种 behavior:
| behavior |
含义 |
allow |
直接放行 |
deny |
直接拒绝 |
ask |
询问用户 |
passthrough |
工具不表态,交由上层管线决定 |
passthrough 状态的存在,前提是权限判断存在多个层级——工具自身可以选择不发表意见,让更上游的规则来做决定。这在插件化架构中至关重要:工具无需了解全局的权限策略,只需处理自己确知的情况。
规则来自八个来源
我们当前的版本只有一个硬编码的 DENY_LIST 和一个 PERMISSION_RULES 列表。而 Claude Code 的规则来自八个不同的来源,每个来源拥有不同的优先级:
userSettings → ~/.claude/settings.json
projectSettings → .claude/settings.json
localSettings → settings.local.json
flagSettings → Feature flags
policySettings → 企业管理策略
cliArg → --allowedTools / --deniedTools
command → 内联命令参数
session → 会话内临时授权
优先级由低到高排列,高优先级来源可以覆盖低优先级。每条规则的格式是 { toolName, ruleBehavior, ruleContent }。这套设计让不同角色(用户、项目负责人、企业管理员)能在不同层级独立配置权限,互不干扰,又能统一合并生效。
Auto 模式下不问人
当前实现的闸门 3,每次命中规则都会暂停下来等用户输入。Claude Code 在 auto 模式中引入了一个 YoloClassifier——它将工具调用和对话上下文一并发送给一个分类器模型,让其判断此操作是否安全。安全则直接放行,不安全才弹出对话框给用户。如果分类器连续拒绝超过一定次数,系统会回退到全人工审批模式。
此设计的背景是:auto 模式面向的是长时间无人值守的任务,每次都打断用户的工作流并不现实。用另一个模型来做安全判断,相当于在人工审批和完全自动化之间找到了一个理想的平衡点。
多层验证
Claude Code 的工具调用并非只经过权限检查这一关,实际上它穿过了更多验证阶段:Zod schema 验证参数类型、validateInput() 进行语义检查、Pre/PostToolUse hooks 在权限判断前后运行、工具自身的 checkPermissions() 方法……这些阶段的输出最终需要被协调整合为一个决策。
而当前实现将这些全部合并进了 check_permission() 这一个函数里。好处是结构简单明了,代价是扩展性堪忧——想加日志、想在特定操作后自动触发某个动作,都得去修改这个函数。
当前实现的局限
说完了生产版的对比,回头审视我们当前的实现,有几个问题需要关注:
- 字符串匹配可以被绕过。
rm -rf / 加个空格就不一样了。真正的命令分析要求解析 shell 语法,或者干脆在沙箱中执行。
- 规则是全局的,非上下文感知。 当前的规则无法区分“身在 CI 环境”还是“本地开发”,也无法辨别用户是管理员还是普通用户。
- 闸门 3 是同步阻塞的。
input() 会卡住整个进程。在 Web 应用或异步架构中,这种设计需要被替换成事件驱动的审批流程。
- 权限拦截的结果对模型不够友好。 目前只返回一个干巴巴的
"Permission denied."。如果它能附上拒绝原因,甚至建议一个替代操作,模型就能更有效地调整后续行为,而不是一头雾水。
下一步要解决的问题
权限管线解决了“哪些操作能执行”这个核心问题。但眼下的实现方式,把所有逻辑都硬编码在了主循环里:权限检查在这儿,未来想加个日志记录也得塞在这,如果想在写文件之后自动执行 git commit,同样得加在这里……
这样下去,循环体迟早变得臃肿不堪。
解决这一困境的思路,便是引入 Hooks 机制:将“循环中应当发生的事情”抽象为一个个钩子,在工具执行前后挂载扩展逻辑,让循环本身保持清爽。这正是我们下一篇要深入探讨的内容。
 发表于 昨天 23:39
|
查看: 4|
回复: 0
发表于 昨天 23:39
|
查看: 4|
回复: 0
