前言
提到 MyBatis,很多小伙伴都会用,但未必能用出“惊艳”的感觉。
这个轻量级的持久层框架虽然灵活,可一旦面对日常的单表 CRUD 操作,就不得不接受重复代码多、开发效率低的现实。
来看一个最典型的场景:
<!-- 原生MyBatis:每个实体都要写XML,每个方法都要配SQL -->
<mapper namespace="com.example.UserMapper">
<select id="selectById" resultType="User">
SELECT * FROM user WHERE id = #{id}
</select>
<insert id="insert" useGeneratedKeys="true" keyProperty="id">
INSERT INTO user(name, age) VALUES(#{name}, #{age})
</insert>
<update id="updateById">
UPDATE user SET name = #{name}, age = #{age} WHERE id = #{id}
</update>
<delete id="deleteById">
DELETE FROM user WHERE id = #{id}
</delete>
<!-- 还有分页、列表、批量... 无穷无尽 -->
</mapper>
最近有位小伙伴吐槽说:“为什么一个简单的用户表,我要写一百多行的 XML?单表操作不就是增删改查加分页吗,能不能一行代码搞定?”
说实话,听到这话我一点都不意外。当年我们刚接触传统 MyBatis 时,第一反应简直一模一样。
后来有了 MybatisPlus,确实把我们从 XML 地狱里解救了出来,那种畅快感持续了好一阵子。不过日子久了,又开始觉得不够用了——每个接口还得老老实实写 Controller、Service、ServiceImpl……虽然比 MyBatis 强太多,但重复劳动依然不少。
直到最近深度体验了基于 MybatisPlus 抽取的 MybatisPlus Pro—只需继承一个 BaseController,增删改查、分页、列表、排序、条件查询,全部开箱即用。
一、为什么我们需要 MybatisPlus Pro?
在深入讲解之前,不妨先盘点一下日常开发中那些“看似能忍、实则很烦”的场景。
痛点1:MybatisPlus 的 BaseMapper 已经很方便了,但 Service 层还得反复写。
每个 Service 接口基本都在重复定义 findById、findAll、insert、update、delete 等通用方法。虽然 MP 提供了 IService 接口,但依然需要在每个 ServiceImpl 里调用 BaseMapper 的方法,并没有从根本上解决重复劳动的底层逻辑。
痛点2:Controller 层依然逃不掉。
很多小伙伴在职场上都有这样的经历:需求方说要加一个新模块,得做一套完整的增删改查接口。于是我们开始复制粘贴,改类名、改路径、改参数……搞完一两个模块还没啥感觉,等需求方一次性扔来七八个模块,光写这些“复制-粘贴-微调”的代码就要一两个小时,而且极其容易出错。
痛点3:代码质量参差不齐。
同样的增删改查,张三一种写法,李四另一种写法。有的参数校验滴水不漏,有的漏了异常处理,线上直接崩掉。
痛点4:条件查询代码重复率高得离谱。
每个 Controller 里都要对 QueryWrapper 进行各种 eq、like、orderBy 的配置,逻辑惊人地相似,写多了满眼都是重复代码。
有一句话说得好:最好的代码是没有代码。 如果能把这些几乎一模一样的逻辑全部自动化生成,我们就能把 90% 的精力释放出来,投入到真正的业务创新里去。
二、MybatisPlus Pro 是什么?
MybatisPlus Pro 是在 MybatisPlus 的基础上进行增强的工具,它的核心理念是“站在巨人的肩膀上”,只做增强不做改变。从项目结构上看,它就是在 MybatisPlus 之上叠加了更多模板化功能,利用 Spring Boot 将通用能力抽取成一套开箱即用的基类体系。
说白了,MybatisPlus Pro 的核心思路就是:在 MybatisPlus 已经“消灭”了 Mapper 层代码的基础上,继续“消灭”Service 层和 Controller 层的重复代码,让开发者只需要关注核心业务逻辑。
这里需要说明一下,MybatisPlus Pro 目前有两种理解:一种是社区基于 MP 二次封装的项目实现方案,另一种是 MybatisPlus 官方在不断迭代中新增的 Pro 级特性。本文重点围绕前者的设计思路和实战价值展开。
下面从架构师视角画一张图,便于理解 MyBatis、MybatisPlus 和 MybatisPlus Pro 三者之间的关系:
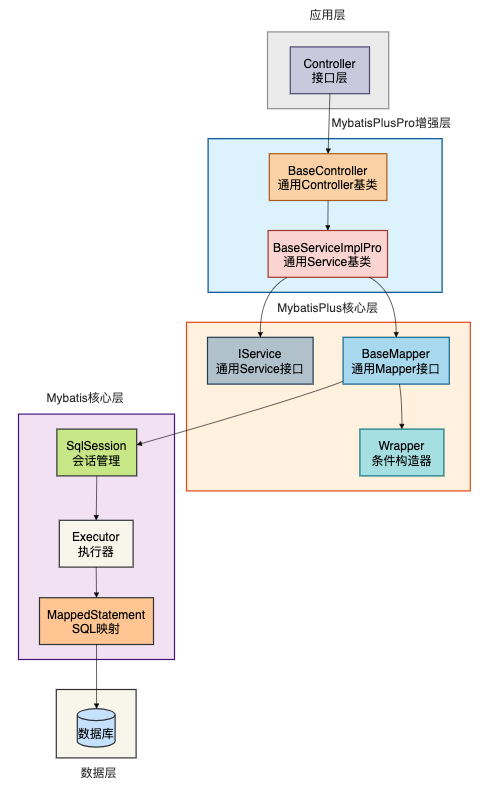
三、快速上手
说了这么多理论,直接上代码,来感受一下 Pro 版的威力。
第一步:引入依赖
MybatisPlus Pro 建立在 MybatisPlus 基础上,所以首先要引入 MybatisPlus 的 starter 依赖:
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.15</version>
</dependency>
官方在 2025 年 11 月 30 日发布了 v3.5.15 版本,支持 SpringBoot 4.0.0 和 Jackson 3.0,推荐直接使用最新的稳定版本。
第二步:编写工具类
工具类是 Pro 版的核心基础设施,它提供了三个关键能力:
- 驼峰与下划线的互相转换——解决 Java 实体类字段名和数据库列名的自动映射问题
- 通过反射获取实体字段值——动态提取实体中各字段的值,为构建 QueryWrapper 做准备
- 基于实体类自动生成 QueryWrapper——零代码构建查询条件,大幅简化条件查询的编写
这里的关键逻辑值得展开讲讲:当一个实体对象(比如 User 对象)传入 getQueryWrapper 方法时,这个方法会利用 Java 反射 获取该类的所有声明字段(通过 entity.getClass().getDeclaredFields())。然后遍历每个字段,跳过被 final 修饰的(它们不可动态修改),再通过 field.setAccessible(true) 突破访问权限限制,拿到被 private 修饰的字段值。
如果字段值不为 null,就把 Java 的驼峰字段名(如 userName)转换成数据库的下划线列名(user_name),然后向 QueryWrapper 添加一个 eq(等值匹配)条件。这样一来,传入的实体里有哪些非空字段,QueryWrapper 就自动用这些字段作为查询条件,完全不需要手动编写。
public class ApprenticeUtil {
private static Pattern humpPattern = Pattern.compile("[A-Z]");
private static Pattern linePattern = Pattern.compile("_(\\w)");
// 驼峰转下划线(userName -> user_name)
public static String humpToLine(String str) {
Matcher matcher = humpPattern.matcher(str);
StringBuffer sb = new StringBuffer();
while (matcher.find()) {
matcher.appendReplacement(sb, "_" + matcher.group(0).toLowerCase());
}
matcher.appendTail(sb);
return sb.toString();
}
// 下划线转驼峰(user_name -> userName)
public static String lineToHump(String str) {
str = str.toLowerCase();
Matcher matcher = linePattern.matcher(str);
StringBuffer sb = new StringBuffer();
while (matcher.find()) {
matcher.appendReplacement(sb, matcher.group(1).toUpperCase());
}
matcher.appendTail(sb);
return sb.toString();
}
// 根据非空字段生成QueryWrapper——这里是核心
public static <E> QueryWrapper<E> getQueryWrapper(E entity) {
Field[] fields = entity.getClass().getDeclaredFields();
QueryWrapper<E> eQueryWrapper = new QueryWrapper<>();
for (Field field : fields) {
// 忽略final字段
if (Modifier.isFinal(field.getModifiers())) {
continue;
}
field.setAccessible(true);
try {
Object obj = field.get(entity);
if (obj != null) {
String name = humpToLine(field.getName());
eQueryWrapper.eq(name, obj);
}
} catch (IllegalAccessException e) {
return null;
}
}
return eQueryWrapper;
}
}
第三步:编写通用 BaseController
BaseController 是整个 Pro 版的“发动机”,它集成了最核心的 CRUD 操作逻辑:
public class BaseController<S extends IService<T>, T> {
@Autowired
protected S baseService;
@PostMapping("add")
public Result add(@RequestBody T entity) {
return Result.success(baseService.save(entity));
}
@PostMapping("update")
public Result update(@RequestBody T entity) {
return Result.success(baseService.updateById(entity));
}
@GetMapping("delete")
public Result delete(String id) {
return Result.success(baseService.removeById(id));
}
@GetMapping("detail")
public Result detail(String id) {
return Result.success(baseService.getById(id));
}
@PostMapping("list")
public Result list(@RequestBody T entity) {
// 利用工具类自动构建查询条件
QueryWrapper<T> wrapper = ApprenticeUtil.getQueryWrapper(entity);
if (wrapper == null) {
wrapper = new QueryWrapper<>();
}
return Result.success(baseService.list(wrapper));
}
@PostMapping("page")
public Result page(@RequestBody PageDto<T> pageDto) {
T entity = pageDto.getEntity();
QueryWrapper<T> wrapper = ApprenticeUtil.getQueryWrapper(entity);
if (wrapper == null) {
wrapper = new QueryWrapper<>();
}
IPage<T> page = new Page<>(pageDto.getPageNo(), pageDto.getPageSize());
return Result.success(baseService.page(page, wrapper));
}
}
这段代码的底层执行逻辑值得好好剖析。当客户端通过 /add 接口发送 POST 请求时,Spring 框架自动将 JSON 格式的请求体解析为 T 类型的实体对象;随后 baseService.save(entity) 被调用,baseService 实际上是 MybatisPlus 的 IService 接口的实现类,其内部持有一个 BaseMapper。save 方法会自动判断:主键为 null 则执行 insert,主键不为 null 则执行 updateById。
MybatisPlus 在应用启动时就会自动向 Mapper 中注入这些基本 CRUD 操作,所以我们一行 SQL 都不用写。
这里特别说一下 list 方法:参数是 T 类型实体,方法内部直接用 ApprenticeUtil.getQueryWrapper(entity) 自动构建 QueryWrapper。比如前端传入一个只有 name 为“张三”的 User 对象(其他字段为 null),那么框架会自动生成 WHERE name = '张三' 的查询条件。所有非空字段都会被纳入查询条件,自动取交集。
这就实现了一个强大的能力——给什么字段查什么字段,完全零代码!
第四步:实际使用
搞定了 BaseController,再来创建一个 ProductController,看看代码量能减少多少:
// 实体类
@Data
@TableName("product")
public class Product {
@TableId(type = IdType.AUTO)
private Long id;
private String name;
private BigDecimal price;
private Integer stock;
private LocalDateTime createTime;
}
// Service接口
public interface ProductService extends IService<Product> {
}
// Service实现(按常规写法,也可以自动生成)
@Service
public class ProductServiceImpl
extends ServiceImpl<ProductMapper, Product>
implements ProductService {
}
// Controller——就这一行!
@RestController
@RequestMapping("/product")
public class ProductController
extends BaseController<ProductService, Product> {
}
你没看错,创建一个完整 CRUD 的 Controller 只需要继承 BaseController。增删改查、分页、列表……这些接口全部自动生成,一条代码都不用写!
四、底层原理深度剖析
很多小伙伴可能会好奇:BaseController 里的这些方法是如何知道要对哪张表操作的呢?为什么写一个方法,对应的 SQL 就自动生成了?答案就藏在 MybatisPlus 的底层执行链路里。
4.1 完整的 SQL 执行链路
我们用一张清晰的流程图来展示从 Controller 调用到数据库返回结果的全过程:

4.2 重点剖析:BaseMapper 的注入机制
很多小伙伴每天都在用 BaseMapper,但可能从未细想过它是怎么生效的。先回顾一下 MyBatis 的核心流程:MyBatis 通过 SqlSessionFactoryBuilder 读取配置文件构建 SqlSessionFactory,再由 SqlSessionFactory 创建 SqlSession,每次数据库操作都经由 SqlSession 完成。MyBatis 底层自定义了 Executor 执行器接口来操作数据库,Executor 有两个主要实现:基本执行器(SimpleExecutor)和缓存执行器(CachingExecutor)。
MybatisPlus 的强大之处正在于它在这个基础上所做的增强:
1. 动态代理机制:在 Spring 启动时,所有继承了 BaseMapper 的接口都会被 MapperProxyFactory 利用 JDK 动态代理 创建代理对象。当你调用 productMapper.selectById(1L) 时,实际上是 MapperProxy 的 invoke 方法在背后拦截了调用,解析出这是一个名为 selectById 的查询操作。
2. MappedStatement 的自动生成:MybatisPlus 的 SQL 注入器(SqlInjector)会在应用启动时,为 BaseMapper 中的所有通用方法生成对应的 MappedStatement。MappedStatement 是 MyBatis 的底层封装对象,它包含了 SQL 模板、参数类型、返回结果类型等完整的 SQL 执行信息,mapper.xml 文件中的一个 SQL 操作就对应一个 MappedStatement。MP 在启动时自动将这些 SQL 注入到 MyBatis 的 Configuration 中,这正是我们不需要写任何 XML 就能执行 SQL 的根本原因。
3. 拦截器链(Interceptor Chain):MybatisPlus 通过 MybatisPlusInterceptor 构建了一套拦截器链,在 Executor 执行前注入各种增强逻辑,比如分页、乐观锁、多租户等,这些功能都是基于拦截器与责任链模式实现的。
4. 完整的方法解析机制:当你的 Mapper 接口调用通用方法时,MybatisPlus 能精准判断这是一个通用方法还是自定义方法,并找到对应的 MappedStatement 来执行 SQL。
4.3 条件构造器(Wrapper)的工作原理
以条件查询为例,下面这张图展示了条件构造器内部执行的详细流程:

Lambda 表达式的核心优势是类型安全——使用 User::getName 而不是字符串 "name",如果字段名写错了,编译器会立即报错,而传统的字符串写法只有到运行时才会发现 SQL 错误。这从技术层面上实现了“约定优于配置”的理念。
五、优缺点
5.1 优点
1. 开发效率呈指数级提升。 一个模块从接口定义到 CRUD 功能完整可用,只需要继承 BaseController 并注入 Service,5 行代码搞定。相比原生 MyBatis 要写 XML、Mapper、Service、ServiceImpl、Controller,工作量减少 80% 以上。
2. 代码风格统一,大幅降低维护成本。 所有模块的增删改查逻辑全部出自同一个 BaseController,代码风格完全一致。新人接手项目时,不需要去研究每个 Controller 用了什么奇技淫巧——所有结构和处理方式都整齐划一。
3. 零 XML 配置。 MybatisPlus 本身已经做到了不需要 XML 配置 BaseCRUD,而 Pro 版更是把 Controller 层的配置也一并省掉了。
4. 功能完备,开箱即用。 分页插件内置就绪,只需传 pageNo 和 pageSize 即可获得完整的分页查询结果。条件构造器可以灵活构建复杂查询条件,eq(等于)、like(模糊匹配)、between(范围查询)、orderBy(排序)等,足以覆盖绝大多数业务场景。
5. 非侵入式设计。 MybatisPlus Pro 是在 MybatisPlus 基础上做的增强,你依然可以在需要复杂 SQL 的地方编写原生 MyBatis 的 Mapper 和 XML,两者完全兼容。
5.2 缺点
1. 复杂多表关联查询仍是痛点。 一旦涉及三张表以上的关联查询,条件构造器会让代码变得非常复杂且难以阅读。有经验的小伙伴应该深有体会:用 Wrapper 写三表关联,代码逻辑可能比手写 SQL 还绕。原因在于 Wrapper 本身设计初衷是处理单表查询条件,它并不擅长表达多表 JOIN 的语义。
2. 部分场景存在性能隐患。 需要特别留意的是,BaseMapper 自带的 selectById、selectList 等方法默认会查询所有字段——相当于 SQL 中的 SELECT *。在 MySQL 性能优化中有一条黄金法则:尽量不要使用 SELECT *,这会增加不必要的网络传输和内存开销,尤其是当表中含有 TEXT、BLOB 这类大字段时,性能问题会更加突出。官方在使用说明中也提醒:MP 启动即自动注入基本 CRUD 操作,性能损耗虽然极小,但在极端场景下仍需谨慎考量。
3. 部分方法存在“魔法值”隐患。 比如使用 QueryWrapper<User>().eq("id", 1) 这种方式,字段名以字符串形式写死。一旦数据库字段名发生变更,编译阶段完全无法察觉,只有运行到那一行代码时才会报错,排查起来非常耗时。这也是官方越来越推崇 LambdaWrapper 的原因——用方法引用代替字符串,从根源上解决这个问题。
4. 部分功能有过度封装之嫌。 有开发者认为 MP 在一定程度上“侵入”了 Service 层,当业务逻辑变得极其复杂时,这些封装好的通用方法反而可能变成一种掣肘。
5. SQL 可读性与调优难度上升。 当使用复杂条件构造器时,生成的 SQL 语句对调试来说不够直观。如果不熟悉 MP 的内部机制,定位慢查询的原因会比直接查看 XML 配置的 SQL 更费劲。
六、使用场景与选型建议
6.1 推荐使用 MybatisPlus Pro 的场景
场景1:中小型项目、快速迭代项目。 这类项目需求变化快,对开发速度要求高,但对极致性能要求相对较低。用 MybatisPlus Pro 可以显著提升交付效率。
场景2:后台管理系统、管理后台类应用。 这些应用的核心功能就是围绕数据的增删改查展开,模块数量多但业务逻辑相对简单。Pro 版就是为这类场景量身打造的。
场景3:基础 CRUD 操作占主导的项目。 如果项目中 80% 以上都是单表增删改查操作(比如各种配置管理、字典管理、基础数据维护),Pro 版能带来巨大的效率红利。
场景4:开发团队规模较小,希望统一代码风格。 小团队或个人开发者,用 Pro 版可以快速搭建项目骨架,同时保证代码结构清晰且一致。
6.2 谨慎使用或不推荐的场景
场景1:业务核心、对 SQL 执行效率要求极高的系统。 比如交易系统、支付系统、高并发订单系统等,需要逐条对 SQL 做极致调优。MP 的通用方法(尤其是 SELECT *)可能成为性能瓶颈。
场景2:复杂报表系统、复杂数据统计系统。 这类系统往往需要编写十几行甚至几十行的复杂 SQL,多表关联、子查询、聚合函数比比皆是。这种情况直接手写原生 SQL 远比使用条件构造器更清晰、更可控。
场景3:对 SQL 需要精细审核的安全敏感系统。 在一些金融、政务等要求对 SQL 语句逐条审查的场景下,框架自动生成的 SQL 可能不太符合审核标准,此时建议全部采用手写的 XML SQL。
6.3 架构选型时的对比参考
下面这张表帮大家快速理清 MyBatis、MybatisPlus 和 MybatisPlus Pro 之间的差异,做到“选型有据”:
| 维度 |
原生 MyBatis |
MybatisPlus |
MybatisPlus Pro |
| CRUD 开发速度 |
慢(需手写 SQL) |
快(BaseMapper) |
极快(全自动) |
| 代码量 |
多 |
较少 |
很少 |
| 多表 SQL 灵活性 |
高(完全可控) |
高(兼容原生) |
高(兼容原生) |
| 学习成本 |
低 |
中等 |
中等 |
| 定制化程度 |
高 |
高 |
中高 |
| 统一代码风格 |
差 |
一般 |
好 |
| 适用项目 |
所有 |
所有 |
中大型+快速开发 |
| 对数据库的掌控力 |
完全掌控 |
单表可封装 |
单表可封装 |
这个对比表帮助你在技术选型时心里有数——每个框架都有自己的优势与局限,关键是根据项目的实际情况来做选择。
七、避坑指南
作为过来人,这些坑我没少踩,下面分享几点实战心得。
坑1:别过度使用通用查询方法。 有小伙伴习惯“一个 selectList 走天下”,方便是方便,但遇到高频查询接口时,SELECT * 查询所有字段会严重影响性能。建议重要的查询接口务必用 select() 明确指定字段。
坑2:Lambda 版本永远优先于字符串版本。 用 LambdaQueryWrapper 代替 QueryWrapper,通过方法引用的方式避免硬编码字符串,既保证了类型安全,又规避了字段名变更时的隐式错误。
// ✅ 推荐写法(类型安全)
userMapper.selectList(Wrappers.<User>lambdaQuery()
.eq(User::getStatus, 1)
.like(User::getUsername, "zhang")
.orderByDesc(User::getCreateTime));
// ❌ 不推荐写法(字符串容易拼错)
userMapper.selectList(Wrappers.<User>query()
.eq("status", 1)
.like("username", "zhang"));
坑3:分页务必使用 MybatisPlus 内置的分页插件。 不要自己手写 LIMIT,MP 内置的分页插件基于物理分页实现,对不同数据库提供了良好的兼容性,不仅代码简洁,性能也更好。
坑4:复杂 SQL 果断放弃 Wrapper,回归原生。 当查询涉及三张表以上的关联时,我的建议是:别挣扎,直接在 Mapper XML 里写 SQL。清晰、可控、易于调优,这才是真正的生产力。
坑5:实体字段命名严格遵循驼峰规范。 MP 的自动映射强依赖驼峰命名规范,建议始终使用标准的驼峰命名,避免不必要的额外配置。
总结
写到这里,来做个简单总结。
MybatisPlus Pro 的出现,核心目标是解决一个根本问题:把开发者从海量的重复代码中彻底解放出来。 它继承了 MybatisPlus 无侵入、高效率的设计理念,通过 BaseController 这一层巧妙的抽象,把 Controller 层、Service 层的重复劳动全部自动化了。再配合工具类的反射机制和 Wrapper 条件构造器,还能实现基于实体非空字段的自动条件查询——开发体验可以说是质的飞跃。
当然,没有银弹。 Pro 版在复杂多表关联、极致性能优化等场景下确实存在短板,但正如业界所公认:它解决了 80% 的简单 CRUD 重复工作,剩下的 20% 复杂场景依然能手写 SQL,两者结合才是最佳实践。MybatisPlus 在 MyBatis 之上只做增强不做改变,既极大简化了开发,又完整保留了 MyBatis 的所有灵活性。
最后,更深入的技术探讨与实战经验分享,欢迎到云栈社区一起交流。用一句话与各位共勉:提高效率不是偷懒,而是把精力投入到更有价值的业务中去。
 发表于 2026-6-2 23:51:01
|
查看: 304|
回复: 0
发表于 2026-6-2 23:51:01
|
查看: 304|
回复: 0
