6 月 1 日,MiniMax 发布了新一代模型 M3。
“自研 MSA 稀疏注意力架构、100 万 token 上下文、原生多模态、10 天后开源权重,API 输入只要 $0.3/百万 token。”
放在年初,这可能只是一个模型发布的新闻。放到眼下这个时间点,意义大有不同。
上一个星期还在讨论 Uber 烧光全年 Claude Code 预算的事,开发者圈子里对 AI 账单的焦虑远没退潮。这个时候发布一个开源模型,百万上下文可用、编码逼近 Opus 4.7、价格只要 Claude 的零头,那么带来的影响可就十分深远了。
M3 值得关注,但选模型从来不是选第一名。你的项目类型、预算厚度、数据合规要求,决定了谁才是最适合你的那一个。
百万上下文,AI 怎么从奢侈品变日用品
长上下文窗口对开发者的吸引力不用多讲。整仓代码直接丢进去、跨文件重构不用切来切去、Agent 跑几天不丢记忆,这些场景都需要长窗口。但 Transformer 全注意力机制有个缺点:算力随上下文长度平方级增长。窗口开多了,账单也跟着疯狂上涨。
M3 的思路是从注意力机制本身动手。新架构叫 MSA(MiniMax Sparse Attention),核心逻辑是在计算注意力之前先做一层筛选,只对与当前查询真正相关的 KV 块做精确计算,其余跳过。
和已有的稀疏注意力方案(DSA、MoBA)相比,MSA 对 KV 缓存的块划分精度更高,实际有效的上下文覆盖率也更高。
在算子层面,MSA 做了进一步优化。传统方案中查询是外层循环,需要反复读取 KV 块。MSA 把 KV 块翻到外层,每个块只读一次,内存访问保持连续,查询反向往里聚合。MiniMax 给出的数据是:比 Flash-Sparse-Attention 和 flash-moba 的开源实现快 4 倍以上。
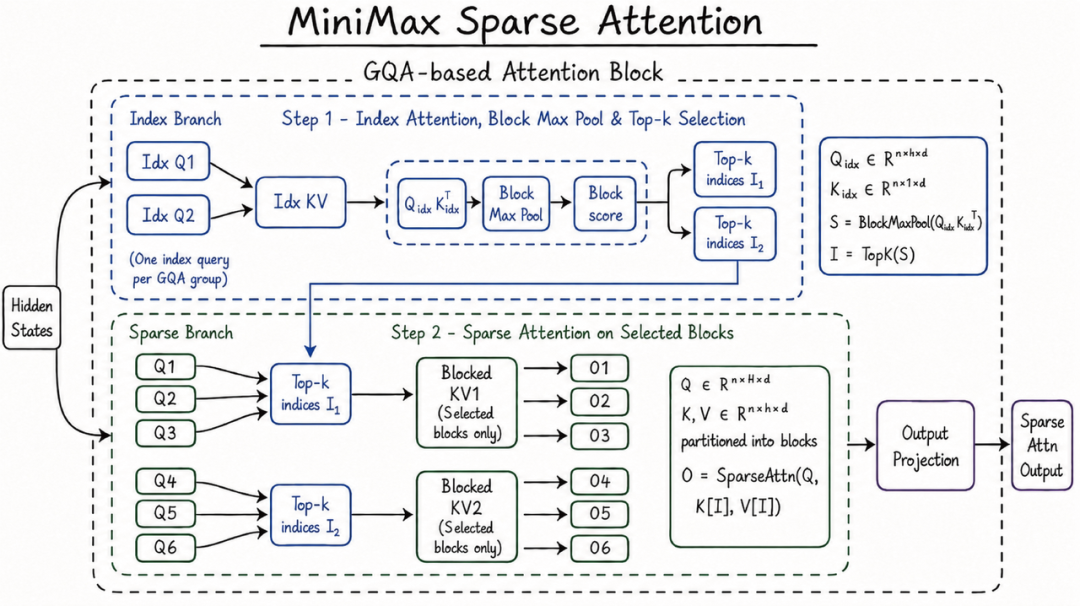
落到实际效果上,M3 在 100 万 token 上下文下,预填充速度比上一代提升超过 9 倍,解码提升超过 15 倍,单 token 计算量只有 M2 的 1/20。 这就意味着 1M 上下文从实验室参数变成了可以日常开着用的功能,不用每调一次 prompt 就心疼一次。
24 小时自动运行,CUDA 算子上限从 7.6% 飙到 71.3%
架构说了那么多,最终得看模型能不能干活。MiniMax 在发布公告里放了三个内部测试案例,其中 CUDA 内核优化这一项最直观。
任务目标:在 NVIDIA Hopper 架构 GPU 上优化 FP8 矩阵乘法。这是大模型推理中计算量最大的算子之一,资深工程师手动写一个生产级内核通常需要一到两周。
M3 拿到手的东西很简陋:一段跑不通的 Triton 框架代码、一套性能评测脚本,没有任何高性能参考实现可以「借鉴」。它得从基本原理出发,自己找优化路径。
接下来约 24 小时里,M3 自主完成了 147 次基准提交和 1959 次工具调用。流程完全串起来:先用最朴素的方式实现基线版本,跑通测评;然后生成立方级自动调优配置,逐个试;找到性能瓶颈后切 CUDA Graph、重写持久化内核、优化主机端调度,每一步都靠测评反馈自我验证,没人插手。
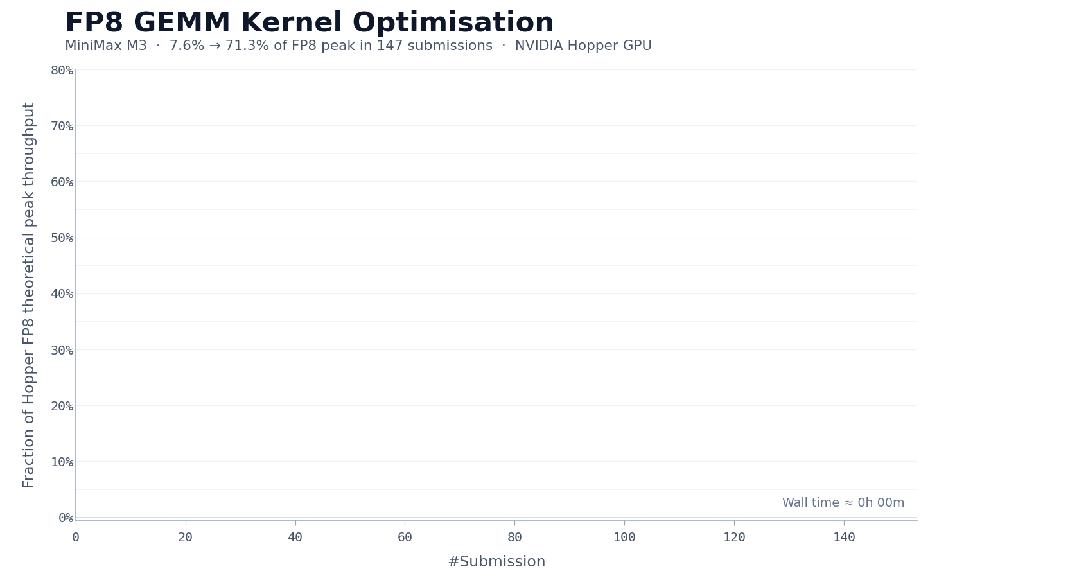
最终,Hopper FP8 硬件峰值利用率从第一版的 7.6% 拉到了 71.3%,速度提升了 9.4 倍。 值得留意的是,最佳方案出在第 145 次提交。在此之前模型经历了多次性能停滞,长时间看不到进展,但它一直在换方向试。
MiniMax 的对比数据显示,大多数模型在前 30 次提交后就放弃迭代了,只有 Opus 4.7 和 M3 能一路推到百次以上。
另外两个案例同样值得一句:M3 用 12 小时独立复现了 ICLR 2025 杰出论文《LLM 微调的学习动态》,自主生成 18 次提交和 23 张实验图,核心结论全部对上。在 PostTrainBench 测试中,给 M3 四个只完成了预训练的基模型,12 小时内自主完成数据合成、训练、评估、迭代全流程,最终评分 0.37,仅次于 Opus 4.7(0.42)和 GPT-5.5(0.39)。
SWE-Bench Pro 59.0%,Claw-Eval 最高分,Agent 短板终于补齐
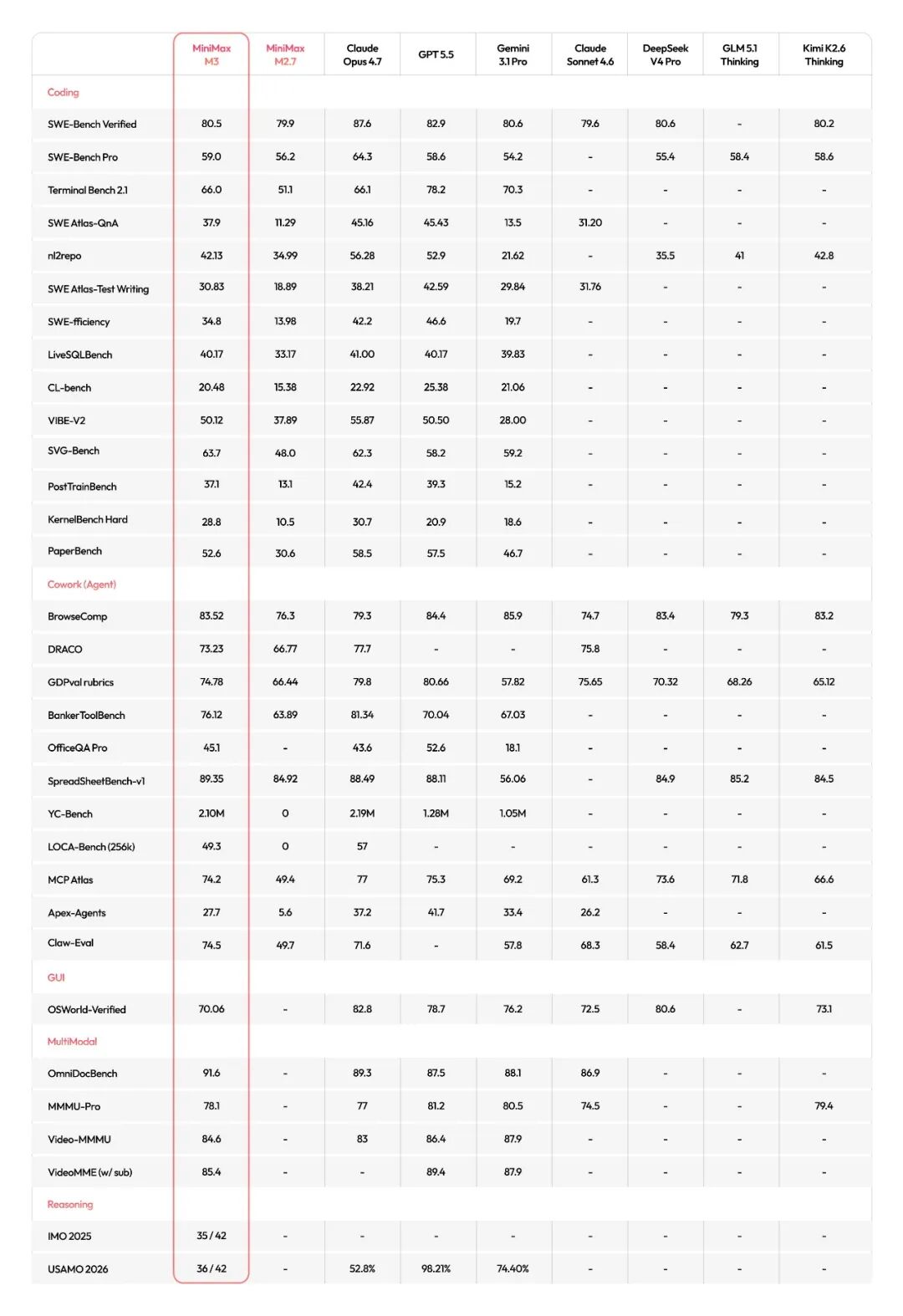
回到开发者最关心的编码和 Agent 基准。所有分数均来自 MiniMax 公布的数据,部分对比分取自官方排行榜。
SWE-Bench Pro:59.0%,超过 GPT-5.5 和 Gemini 3.1Pro,逼近 Claude Opus 4.7。 Terminal-Bench 2.1 拿到 66.0%。MCP Atlas 74.2%。在端到端 Agent 评估框架 Claw-Eval 的 161 项通用任务中,M3 拿了最高分。
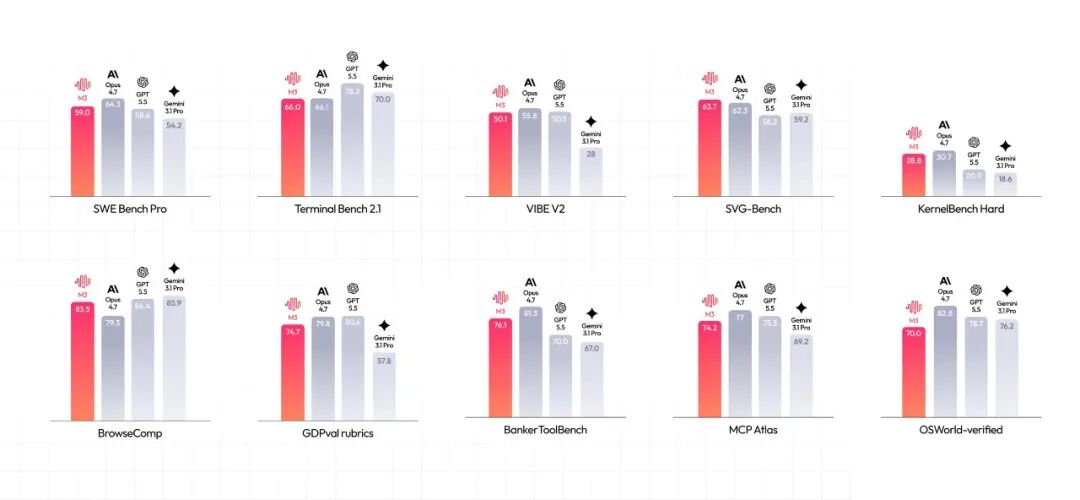
多模态侧也有东西。SVG-Bench 得分超过 Opus 4.7,文档理解基准 OmniDocBench 高于 Gemini 3.1 Pro。OSWorld-Verified 计算机操作测试中,完成率达到 70.06%。原生多模态是从训练第 0 步就引入的,文本、图像、视频混在一起训,支持桌面操作。这意味着模型可以直接看懂屏幕、操作应用,跨软件协同的 Agent 场景有了底座。
MiniMax 还专门提了一个容易忽略的点:大多数代码 Agent 的基准测试基于单轮任务假设,但真实开发是多轮协作,需求会改、方案会调、中间结果会推翻。他们为此搭了一套交互式用户模拟器框架,让模型在训练和评估阶段就接触贴近生产环境的交互模式。方向是对的,效果还需要开发者在实际项目中检验。
每百万 Token $0.30,开发者终于实现了“Token 自由”
能力和架构聊完了,剩下就是大家最关心的事情,账单。
M3 API 当前定价,输入 $0.30/百万 token,输出$1.20/百万 token。开 Prompt Caching 后,重复上下文再压到 $0.06。这是首周 5 折优惠,原价$0.60 和 $2.40,6 月 7 日后回调。
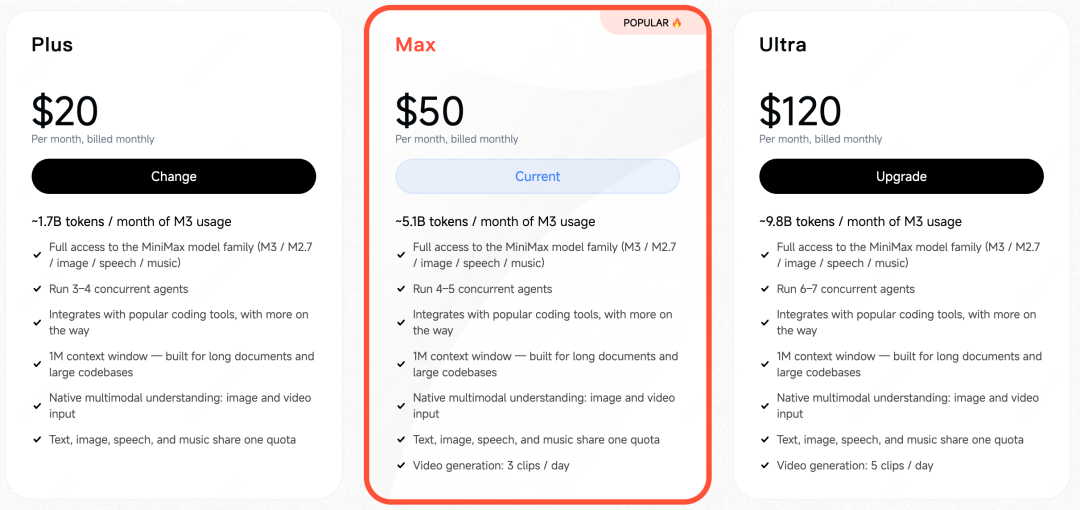
订阅这边分三档:每月 $20 拿 17 亿 token、$50 拿 51 亿、$120 拿 98 亿,图片、视频、文本共享一个池子,不用分开算。拿同样一笔钱去订 Claude,到手的 token 量只有 M3 的十五分之一。
和 Claude 比,差距一眼到底。Opus 输入 $5/百万 token、输出$25,M3 加缓存后不到它的六十分之一。Sonnet 输入 $3、输出$15,M3 也低了一个数量级。更实际的说法是“以前每次调 Opus 都要犹豫一下这条 prompt 值不值得,现在犹豫的次数少了很多。”
拿之前聊过的中型功能重构来算笔账。五到八个文件,带调试循环,一趟下来约 18 万 token。全程 Claude Opus,一个月跑十几次,API 轻松上 $200。同样的任务给 M3,缓存拉满,月费大概率压在$50 到 $80。降幅巨大。如果你的日常里长上下文 Agent 任务是刚需,账单差距还会拉得更大。

M3 的价格夹在一个有趣的位置上。往上,Claude 和 GPT 这类顶级模型,能力强,账单也贵。往下,开源模型几乎不要钱,但 Agent 能力和长上下文稳定性还有距离。
M3 刚好卡在中间:能力接近第一梯队,价格更靠近开源那端。对那些既需要 Opus 级别的编码质量、又不想每个月收到账单时倒吸一口凉气的开发者,这个位置本身就是吸引力。
倒计时 10 天:开源生态里的蓄势待发
M3 对国内开发者的实际价值,几条信息就能清楚。
第一,数据不出域。 10 天后模型权重上 Hugging Face,本地部署后代码敏感度高的项目可以直接跑在内网。这对金融、政务、医疗场景来说是一道硬门槛。
第二,混合栈落地。 架构决策和复杂审查用强模型把关,核心编码和 Agent 任务上 M3,高频琐碎扔给 DeepSeek,本地跑开源的做隐私兜底。这种分层用模的打法,已经在重度用户中跑通,M3 的加入让选项更宽了。
第三,多模态 Agent 有了国产底座。 M3 原生支持图像、视频输入和桌面操作,MiniMax Code 内置了 Agent 团队协作和对抗验证机制。对于想在公司内部搭自动化流程的团队,多了一个开箱可用的选项。
当然,M3 的基准分数要拿到实际项目中检验。PostTrainBench 低于 Opus 4.7 和 GPT-5.5 也说明它在开放探索类任务上还有差距。MiniMax Code 目前仍是早期产品,稳定性需要时间打磨。但方向是清楚的,那就是用架构创新把成本打下来,让 Agent 和长上下文从少数人的重型装备变成多数人的日常工具。
结语
2026 年已经快过半。AI 圈这一年的主旋律正从“模型有多强”转向“用不用得起”。M3 的出现,给这个趋势加了一个来自国内的注脚。
10 天后开源权重,到时候本地跑起来,实际表现是好是坏,开发者自己的终端会给出最诚实的答案。
参考链接:
https://www.minimax.io/blog/minimax-m3
https://www.marktechpost.com/2026/06/01/minimax-releases-minimax-m3-with-msa-architecture-supporting-1m-token-context-native-multimodality-and-agentic-coding/
 发表于 2026-6-2 23:48:41
|
查看: 181|
回复: 0
发表于 2026-6-2 23:48:41
|
查看: 181|
回复: 0
