我负责过一个企业内部制度查询系统,员工通过它来询问公司的报销政策、考勤规则或合同条款,系统需要从数百份文件中检索并生成答案。
采用标准的 RAG(检索增强生成)流程——文档切片、向量检索,再将结果交给大模型生成答案——系统很快就搭建并运行起来了。
然而,系统跑起来后,问题也随之浮现。
当员工询问“试用期员工能否报销差旅费”时,系统回答“不能”。答案本身是正确的,但当我点开引用来源时,却发现它引用了《年假管理办法》的第三条,与差旅费毫无关系。
另一个例子是,员工问“实习生是否享受补充医疗保险”,系统回答“享受”。但我去查阅原始文件,发现原文明确写着“实习生不享受补充医疗保险”。
第一个问题是引用错误,第二个则是答案完全相反。在制度查询这种严谨的业务场景中,任何一种错误都可能导致员工依据错误信息行动,进而引发后续的纠纷和扯皮。
后来我投入了大量时间将这套系统改进到基本可用的状态。最大的体会是:RAG 最难的不是优化单一环节,而是整条链路中每个环节都可能出错,且上游的错误会导致下游的努力全部白费。
一个重要的前提说明
本文所述的方案是在 qwen2:14b 模型本地部署的约束下做出的技术选择(内网私有化、合规可追溯、无公网 API 调用)。文章完成后,我将系统的主链路切换到了 Qwen2.5-32B-Instruct 模型。
需要说明的是,后文会详细讨论的两个关键层——立场分类和 NLI 后验引用验证——在 32B 这种更大规模的模型下,其边际价值显著下降。我会在对应的章节补充说明“换到大模型后这一层是如何退化或可被简化的”。
先抛出核心结论:小模型依赖重度工程化补偿,大模型则受益于结构简化。 因此,请不要将本文视为“RAG 就应该这么做”的通用方案,而应看作特定约束下的工程实践总结。
下图是我最终构建的系统完整链路,后续将逐一剖析其中最难搞定的几个环节。
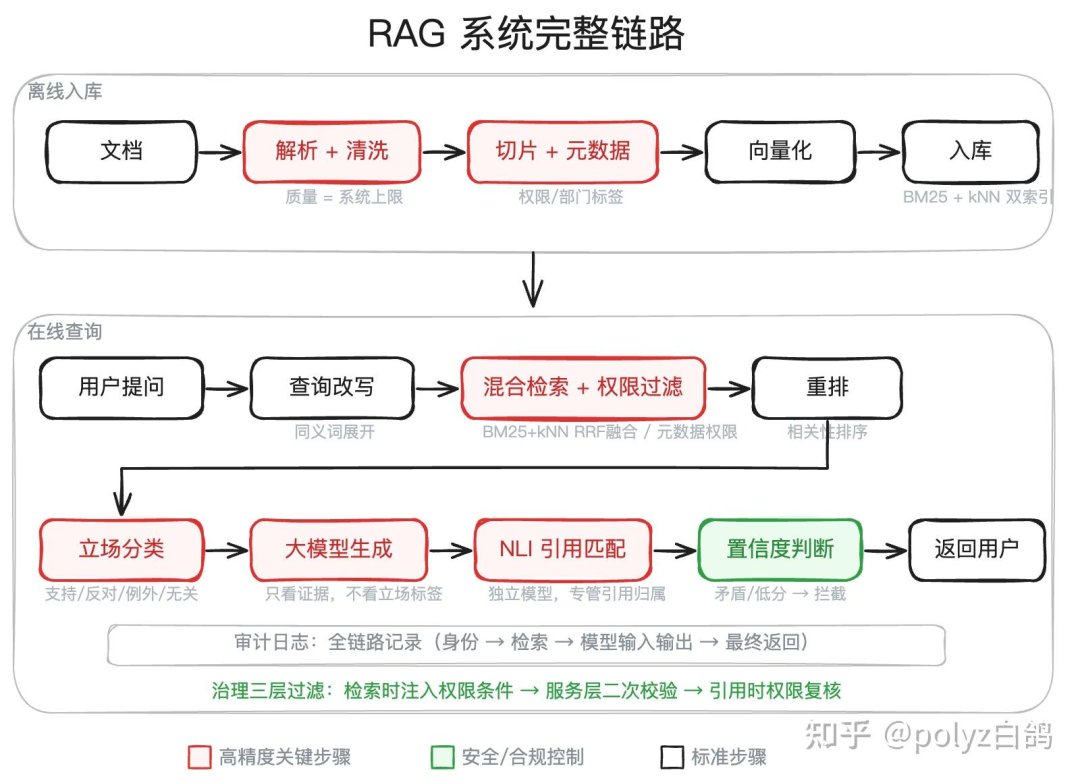
解析层:文档质量决定系统上限
讨论 RAG 优化,很多人会直奔检索策略、重排模型或提示词工程。但在实际业务中,我遇到的第一道难关并非这些,而是文档解析。
企业制度文件通常是 Word 或 PDF 格式,内含大量表格、多级编号、勾选框、页眉页脚。常见的解析工具(如 MinerU、Unstructured 等)处理此类文件时,经常出现令人头疼的问题:
- 符号错乱:勾选框
☐ 被解析成汉字“口”,导致“不接受 ☐ / 接受 ☐”变成了语义不明的“不接受口接受”。
- 结构丢失:多级编号“3.2.1”丢失层级信息,变成孤立的“1”,你无法追溯它属于哪一条款。
- 表格扁平化:表格内容被拍平成纯文本,行列关系全部丢失,关键的对齐信息荡然无存。
这些问题的破坏力在于:无论你后续如何优化检索、调整模型,都只是在有缺陷的数据上做文章。 文档解析一旦出错,后续所有环节的努力都可能付诸东流。
那么,该如何应对?
关键在于:不要默认解析工具的输出是正确的。 必须在文档入库前,增加一道质量检查工序:
- 抽样人工校验:对每批文档抽取 10%-20%,人工对比解析结果与原文件,重点关注表格、编号和特殊符号的处理。
- 自动化规则检测:编写规则脚本,检测常见的解析残留问题,例如孤立的“口”字、断裂的编号序列、异常短的段落(这可能是表格行被意外拆散)。
- 多工具交叉验证:对于关键或格式复杂的文档,使用两种不同的解析工具分别处理,对比输出结果,对存在差异的段落进行人工干预。
这一步毫无技术“性感度”,没有复杂的算法可言。但它却从根本上决定了你整个 RAG 系统能力的天花板。
检索层:为什么必须采用双路召回?
最直接的做法是仅使用向量检索——将文档和问题都转换为向量,然后计算相似度。然而在实际业务中,单一的向量检索存在一个明显的短板:它擅长语义匹配,但对精确关键词不敏感。
例如,员工提问“关于 2024 年第 3 号文件的规定”,其中的“2024 年第 3 号文件”是一个精确的唯一标识符。向量检索会去寻找与“文件规定”语义相关的内容,却不一定能精准命中“第 3 号”这个特定编号。
反之,传统的关键词检索(如 BM25)对文件编号、条款号、专有名词这类精确匹配非常拿手,但它无法理解“差旅报销”和“出差费用”其实是同一回事。
解决方案是采用双路召回:一路用 BM25 做精确的关键词匹配,另一路用向量检索做深度的语义匹配,然后使用 RRF(Reciprocal Rank Fusion) 算法对两路结果进行融合与重排序。
这并非新技术,但很多人在搭建 RAG 时往往会跳过这一步,直接采用纯向量方案。在企业制度查询这种场景下,文件编号、条款号、专有名词俯拾皆是,BM25 这条精确匹配的路径绝不能省。
另一个关键点是:权限过滤必须在检索阶段完成,而不是在返回结果之后再做。
我的做法是为每个文档切片(chunk)附加元数据标签,例如所属部门、密级、适用人群。在发起检索请求时,直接将当前用户的权限条件作为过滤项注入查询中,确保只返回该用户有权访问的内容。
为什么不能先检索再过滤?因为如果你先让大模型“看到”了它不该看的内容,然后再在前端界面隐藏起来,大模型很可能已经在它生成的答案中泄露了这些敏感信息。权限控制必须在源头进行拦截。
检索层进阶:语义相关不等于逻辑一致
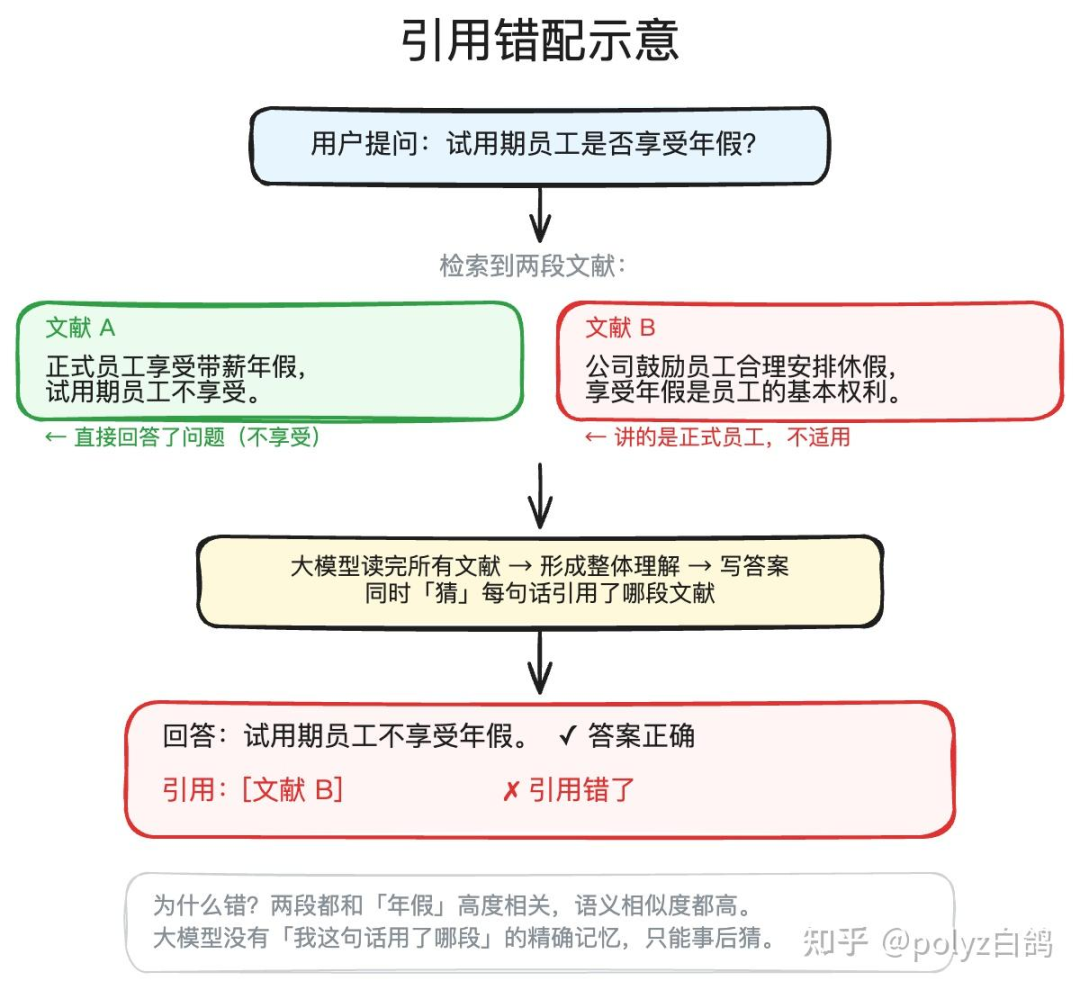
这个坑比前面的更加隐蔽。举个例子,员工提问:“试用期员工是否享受年假?”,系统检索出两段文献:
- 文献 A:“正式员工享受带薪年假,试用期员工不享受。”
- 文献 B:“公司鼓励员工合理安排休假,享受年假是员工的基本权利。”
从语义相关性的角度看,两段文字都与“年假”高度相关,无论是检索模型还是重排模型都可能给它们打出高分。
但从逻辑上看,A 明确说“不享受”,B 则泛泛地谈“享受”。如果系统只依赖语义相关性,而不区分逻辑立场,就可能错误地将 B 作为支撑证据进行引用——而 B 实际上描述的是正式员工的情况,根本不适用于试用期员工。
这并非检索不准,而是检索的维度不足。语义检索只能回答“这段文字和问题是否相关”,却无法回答“这段文字是支持还是反驳问题的结论”。
如何解决?
在重排之后、将内容喂给大模型生成答案之前,增加一个立场分类步骤:
- 对每一段候选文献进行分类,判断其对于用户问题的立场是:支持、反对、例外,还是无关。
- 将分类后的文献按立场分组,在输入给大模型时明确标注:“以下是支持的证据”、“以下是反对的证据”、“以下是例外情况”。
- 如果针对同一问题同时存在支持和反对的证据,绝不让系统自行选择一方——而是将矛盾的证据清晰地呈现给用户,由用户进行判断和决策。
我使用另一个大模型专门进行此项分类任务,将每段文献和用户问题一并输入,让其判断立场。实测表明,这种方法比基于规则的分类准确率更高。
换用 Qwen2.5-32B 后的变化:
立场分类这一层在升级到 32B 模型后显得冗余。主要有两方面原因:
- 架构多余:在实际实现中,生成器收到的是扁平化的上下文(立场标签并未进入提示词),后续的引用匹配也只依赖 NLI 判断,不参考立场标签。这意味着分类结果在下游并无实际消费,成为了一次纯消耗资源的 LLM 调用。
- 边际价值归零:32B 模型本身对于“支持/反对/例外”等逻辑立场的辨别能力已经足够强,不再需要独立的分类器进行兜底。
因此,在 32B 模型下,这一层可以被移除。“呈现矛盾证据”的产品设计理念仍然正确,但具体的分类动作可以合并到后续的引用验证步骤中一并处理。
生成层:不要让大模型自己标注引用
这是我踩过最深的一个坑。
常见的做法是将检索到的文献喂给大模型,并指令它在生成答案的同时,在句末标注引用编号,例如 [1]、[2]。这看起来非常直观,但实际上相当于让模型同时完成两项高度复杂的任务:既要理解问题并组织答案,又要精确记忆答案中每一句话所依据的具体证据。
当模型能力较强或证据区分度明显时,或许还能勉强应付。但在模型参数量较小,或者多段证据内容相似、容易混淆的场景下,引用错配的问题会急剧上升。
大模型生成答案时,它会先读完所有提供的文献,在内部形成一个“对问题的整体理解”,然后基于这个综合性理解来撰写答案。当需要标注引用时,它并没有“我这句话具体引用了哪段文献”的精确记忆——它只能根据整体理解去“猜测”和“回溯”。提供的文献越多、内容越相近,猜错的概率就越高。
在我的实测中,在提供 3-5 段文献的场景下,这种引用错配率大约在 15%。
这种现象在学术界被称为 Citation Unfaithfulness(引用不忠实)。2024 年已有研究论文将“答案正确性”和“引用正确性”拆分为两个独立的评估指标,并证明这并非某个特定模型的问题,而是“让大模型自行生成引用”这种做法本身存在的结构性缺陷。
一个更令人深思的发现是:Anthropic(Claude 的开发商) 在其推出的 Citations API 中,并没有让 Claude 生成引用文本。Claude 仅输出它所引用的原始文档中的字符起止位置(如第 100 至第 150 个字符),具体的引用文本由后端服务根据这个坐标从原文档中精确截取。
这意味着,连模型开发者自己都不完全信任模型来标注引用。
正确的做法是什么?
将“生成答案”和“标注引用”拆解为两个独立的、专责的步骤:
- 大模型只负责生成纯答案:前面步骤得到的“立场分类”结果,不要输入给负责生成的模型。生成器应该只看到原始的文献证据文本。这是为了防止立场分类器万一出错(例如将“反对”错误标为“支持”),其错误会通过标签污染并扩散到整个生成过程中。立场标签仅用于最终答案呈现时的归类展示。
- 引用由独立的后续步骤验证:答案生成后,引入一个独立的 NLI(自然语言推理)模型。该模型逐句检查答案中的每一句话,并与每一个候选证据块进行验证。只有当 NLI 模型判定某段证据“蕴含”了答案中的某句话时,才将该证据标注为这句话的引用。
- 引用文本从原文截取:最终展示的引用文本,严格根据证据块在原文中的字符位置截取,确保一字不差,而非由大模型生成或转述。
这种方式为引用提供了双重保障:
- 物理保障:引用文字精确对应原文的某段字符,可逐字节校验。
- 逻辑保障:经过 NLI 模型的专门验证,确保证据能逻辑推导出结论。
当然,代价是每个回答增加了一轮 NLI 推理,响应时间会有所延长。但换来的,是将引用的准确性从依赖“大模型的记忆与运气”,提升到了依靠“可验证的逻辑推理结果”,这个取舍在要求精确性的场景下是非常值得的。
大模型适合内联标注,小模型需要后验验证
这里需要先厘清两种引用方式的区别:
- 内联标注 (Inline Citation):指令大模型在生成答案的同时,在句末标注引用编号,例如“试用期员工不享受年假
[2]”。
- 后验验证 (Post-hoc Verification):大模型只生成纯文本答案,不标注引用。生成完成后,再用独立步骤(如 NLI 模型)逐句匹配,找出支撑每句话的原文证据。
前面介绍的 NLI 后验方案,主要是为了应对 qwen2:14b 这类较小参数模型的能力局限。小模型对于 [N] 这类结构化引用的指令遵循能力较差,容易漏标、错标,甚至幻觉出不存在的编号。
然而,当模型升级到 Qwen2.5-32B 级别后,情况发生了反转。
我最近的基准测试(Benchmark)显示,使用内联标注方式,引用的精确率(Precision)达到了 0.948,F1 分数达到了 0.896,其性能已经超过了独立的 NLI 后验验证方案。
简单解释下指标:
- 精确率 (Precision):系统标注的引用中,有多少是真正能支撑对应句子的。0.948 意味着每标注 100 条引用,大约有 95 条是正确的。
- F1 分数:综合了精确率和召回率(Recall,即所有应该被标出的引用里,系统实际找出了多少)的平衡指标,数值越高越好。
为什么 32B 模型能做到?因为更大参数量的模型对于“我这句话到底参考了哪段证据”的内部追踪和记忆能力显著增强,“事后猜测”导致错配的问题得到了很大缓解。
这与学术研究(如普林斯顿 2023 年的 ALCE 论文)的结论一致:大模型更适合采用内联标注,小模型则更需要后验验证的工程补偿。
因此,在 32B 模型档位下,那套复杂的 NLI 后验流程可以考虑简化或退回至内联标注。但需要明确,引用不忠实(Citation Unfaithfulness)的现象并不会因为模型变大而消失,只是在 32B 这个级别上,其错误率已经低于引入额外后验步骤所带来的复杂度与延迟代价。对于小模型场景,后验验证方案依然是有效的。
输出层:敢于说“我不知道”
这可能是整套系统中最反直觉的设计——我们费尽心力构建 RAG 系统,不就是为了让它回答问题吗?为何最后却要鼓励它说“我不确定”?
但请思考一下:在制度查询这类具有实际约束力的场景中,“自信满满地给出错误答案”比“坦诚告知不确定性”要危险一万倍。
员工提出一个问题,系统检索到的证据可能都是擦边的、不直接的,但大模型凭借其强大的文本生成能力,依然可以“自圆其说”,产出一个看起来非常通顺、合理的答案。如果系统不加任何警示就直接返回,用户很可能信以为真并据此行动。
如何构建安全网?
设计一个置信度机制,至少在以下三种情况触发时,系统应明确提示用户:
- 检索分数全部低于阈值 → 提示:“未在现有制度中找到直接相关的条款,建议咨询人力资源部确认。”
- 存在无法自动消解的矛盾证据 → 向用户展示冲突双方的具体证据,并标注:“以下相关条款存在不一致,请人工复核。”
- 答案中的句子缺乏高置信度的引用支撑 → 在答案旁标注:“该部分陈述缺乏充分的文献依据,请谨慎参考。”
这些提示并非为了推卸责任,而是为了将系统内在的不确定性从“隐性”变为“显性”。用户看到“我不确定”,至少会意识到需要寻求进一步核实;而若得到一个看似完美实则错误的答案,那才是真正的业务事故。
合规层:权限与审计必须从设计之初就嵌入
权限管控:三层过滤,各司其职
权限控制不能是马后炮,必须融入架构骨髓。我采用的是三层过滤机制,每一层回答一个不同的安全问题:
第一层:访问控制——你能看到吗?
在文档入库切片时,就为每个片段打上权限元数据标签(如部门、密级)。在检索时,直接将用户的权限身份作为过滤条件注入查询。你没有权限看到的内容,根本不会进入候选结果集,而不是检索出来再在前端隐藏。
第二层:冗余校验——万一第一层有漏洞呢?
第一层依赖于底层搜索引擎(如 Elasticsearch、Milvus)正确解析和执行了我们的权限查询条件。但外部系统可能存在未知的 Bug,或者未来更换搜索引擎时配置遗漏。因此,在业务服务层,当检索结果返回后,必须用同样的权限规则对每一条结果进行二次校验。这并非重复劳动,而是必要的安全冗余,类似于飞机的主副两套液压系统。
第三层:引用控制——你能看,但能引用吗?
前两层解决了“信息是否可用”的问题。第三层则解决一个更细致的问题:某些文档,系统可以读取并基于其内容推理生成答案,但不能将原文片段直接展示在引用列表里。
例如,一份内部会议纪要包含某项决策依据,系统可以据此生成答案,但该文档被标记为“不允许直接引用”,因为暴露原文可能泄露会议细节。因此,第三层会额外检查每个证据块的“是否允许引用”、“是否允许展示摘要”等属性。
审计追溯:出了纠纷,何以自证?
当员工与 HR 因对某条制度的理解产生分歧时,第一个问题就是:“你这个信息是哪里来的?” 如果员工回答“系统告诉我的”,那么你必须能完整回溯:
- 他何时提问?
- 系统当时检索到了哪些内容?
- 生成模型收到的完整输入是什么?
- 模型原始输出是什么?
- 最终呈现给用户的答案和引用又是怎样的?
因此,必须记录每一次问答的全链路日志(用户身份 -> 检索请求与结果 -> 模型输入 -> 模型输出 -> 最终返回),确保日志不可篡改并定期归档。缺乏这样的审计能力,整个系统在法务和合规层面是站不住脚的。
权限与审计这两大支柱,如果在系统架构设计初期没有充分考虑,后续补救的成本将是推倒重来级别的。
什么样的场景需要这套方案?
并非所有的 RAG 应用都需要如此复杂的保障。一个简单的判断标准是:问你自己,如果系统答错了,用户会直接按照这个错误答案去行动吗?
- 不会,用户自身具备判断能力(如创意写作辅助)→ 标准、轻量的 RAG 流程可能就足够了。
- 会,且答错会导致实际后果(如制度查询、医疗知识问答)→ 你需要认真考虑本文讨论的这些增强措施。
- 会,且用户高度依赖、无暇核实(如高风险金融咨询、操作指南)→ 你可能需要比本文所述更严格、更重的保障体系。
通用的 RAG 教程和开源框架,通常默认你处于第一种场景。但在真实的企业级落地项目中,大部分需求恰恰属于第二种。
此外,还有一个至关重要的议题本文未及展开:可观测性与可评估性。系统上线后,你如何监测检索质量是否退化?如何量化引用准确率的变化?如何在优化某个环节后,确保没有破坏其他环节?这套监控评估体系的复杂性与重要性,绝不亚于上述任何一个功能模块,限于篇幅,后续有机会再单独探讨。
结语:工程是权衡的艺术
这篇文章发出来后,收到了很多有价值的反馈,特别感谢一些朋友针对“立场分类是否多余”、“大模型是否还需要 NLI 后验”等问题的深度质疑。文中关于模型升级后方案简化的补充说明,正是基于这些讨论的再思考。
工程实践中的每一个“稳妥”的兜底设计,往往都是特定时期为了补偿模型能力不足而留下的“疤痕”。当模型能力迭代升级后,要有勇气和智慧去识别并简化这些部分。这套系统本身也在持续演进中,关于评估体系、多模态文档解析等方向的新的实践和踩坑记录,后续也会通过云栈社区分享出来。
 发表于 2026-4-19 04:25:13
|
查看: 218|
回复: 0
发表于 2026-4-19 04:25:13
|
查看: 218|
回复: 0
