这篇论文从数据中心视角给出一个解释:大模型更强,不只因为能表示更多内容,也因为更能保留长尾任务。
大模型为什么比小模型强?
参数更多、数据更多、算力更多,模型能力也随之提高,似乎已经成了过去几年大模型发展的稳定经验。更难的问题是,大模型到底比小模型多学到了什么?是小模型完全表示不了这些任务,还是它其实能表示,只是在预训练中很难稳定学到?如果给小模型更多数据、更长训练,它是否总有机会追上?
Stanford、Harvard、MIT、Anthropic 等机构参与的这篇新论文,给出了一个更具体的解释:大模型的优势不只是表达能力更强,也不只是样本效率更高。很多时候,小模型不是完全学不会,而是在混合数据训练中留不住那些低频、复杂的任务信号。

论文标题:
Why Larger Models Learn More: Effects of Capacity, Interference, and Rare-Task Retention
论文地址:
https://arxiv.org/abs/2605.29548
大模型多出来的容量,降低了高频任务对低频任务的覆盖,让稀有任务的微弱信号不至于在后续训练中马上被冲掉。
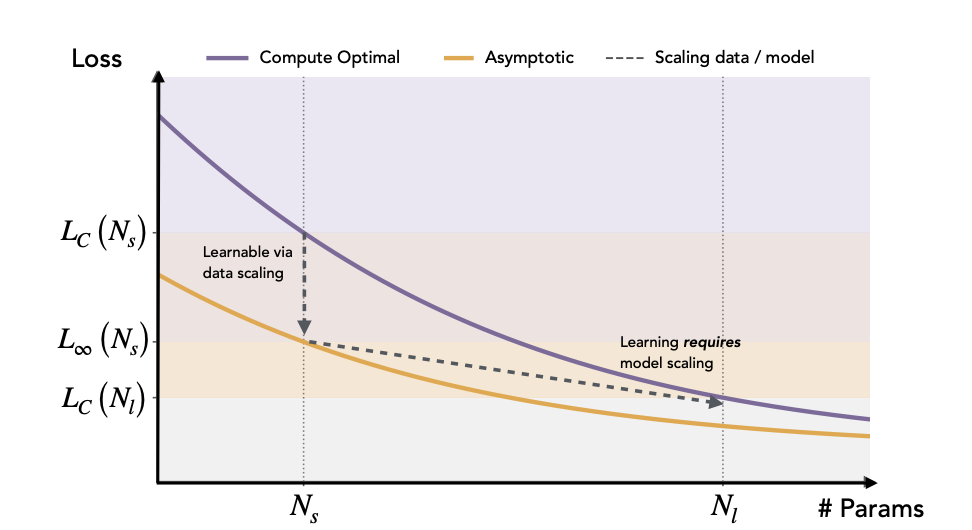
数据扩展可以弥补一部分差距,但另一部分需要模型扩展
大模型多出的能力
论文先把“大模型更强”拆成两种情况。
一类差距可以靠数据扩展弥补。小模型在有限算力下不如大模型,但如果继续增加数据或训练资源,理论上仍有机会追上。这里的大模型更像是学得更快、更省样本。
另一类差距必须依赖模型扩展。即使考虑无限数据下的极限表现,小模型仍达不到大模型在有限算力下取得的 loss。这意味着训练分布中存在一部分内容,是小模型在同样训练条件下难以学到的。
在同一份混合训练数据里,哪些任务会先被学到,哪些任务会被挤出去?真实预训练语料中的任务并不均匀。语言建模目标背后混着大量子任务:有的高频,有的低频;有的简单,有的需要更多结构才能泛化。模型容量有限时,这些任务会竞争同一批表示资源。
模型会先学什么?
作者构造了一个合成多任务回归实验。每个任务有两个关键属性:出现频率和复杂度。
任务在数据中出现越频繁,对整体 loss 的影响越大。复杂度则通过任务特征谱来刻画。谱衰减越慢,说明任务需要更多特征方向才能学好,也就更难被有限宽度的模型充分保留。
最核心的排序规则是:
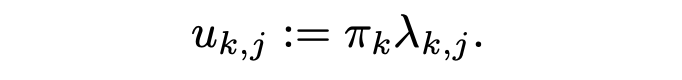
其中 $π_k$ 是任务频率,$λ_{k,j}$ 是任务中某个特征方向的重要性。二者相乘,就是这个特征的效用。
模型宽度为 $N$ 时,会优先保留效用最大的前 $N$ 个特征。模型不会均匀分配容量,而是优先保留最能降低整体 loss 的特征。因此,高频任务和低复杂度任务更容易被学到。低频、复杂任务不一定不可表达,但在资源竞争中排位更靠后。小模型容量被高效用特征占满后,长尾任务就很难进入模型表示。
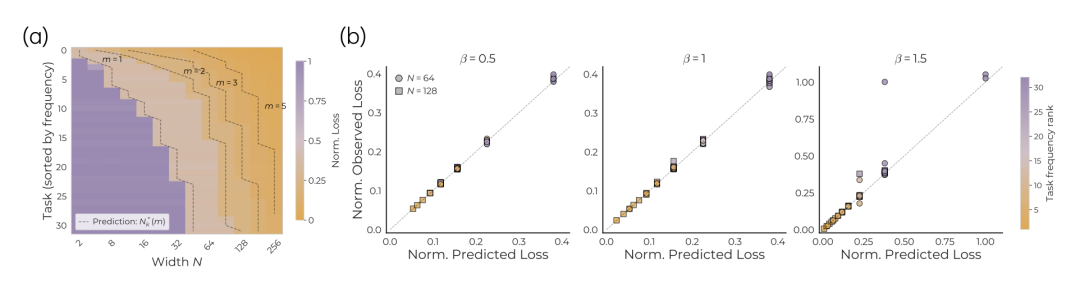
模型宽度增加后,低频任务开始被逐步学到
上图中,作者训练不同宽度的模型,并混合 32 个频率不同的回归任务。结果显示,随着模型宽度增加,模型开始保留更低效用的特征,并更好学习低频任务。实验趋势与定理 3 中的效用排序基本一致。
大模型多出来的参数,让原本排在后面的任务也有机会进入表示空间。
梯度干扰与信号保留
低频任务很少出现,模型要学会它,必须能在多次稀有样本出现之间保留已有信号。
稀有任务样本出现时,小模型参数确实会朝这个任务更新。但在下一次稀有任务出现前,大量高频任务样本会继续更新同一批参数,刚写入的稀有任务信号很快被覆盖。
论文把这种动态概括为更新—遗忘循环:稀有任务出现一次,小模型短暂写入相关信号;高频任务继续训练,信号逐步衰减;下一次稀有任务再出现时,模型几乎又回到起点。
模型宽度足够大时,可以先把常见任务解释得更充分。常见任务的残差信号下降后,对参数的梯度拉力也会变弱。稀有任务带来的更新不再那么容易被冲掉,模型就能把多次低频观察累积起来。
定理 4 给出的直观结论是:常见任务的整体梯度受残差信号控制。常见任务还没学好时,会持续占用更新方向;解释得越充分,干扰越弱,剩余容量越可能留给稀有任务。
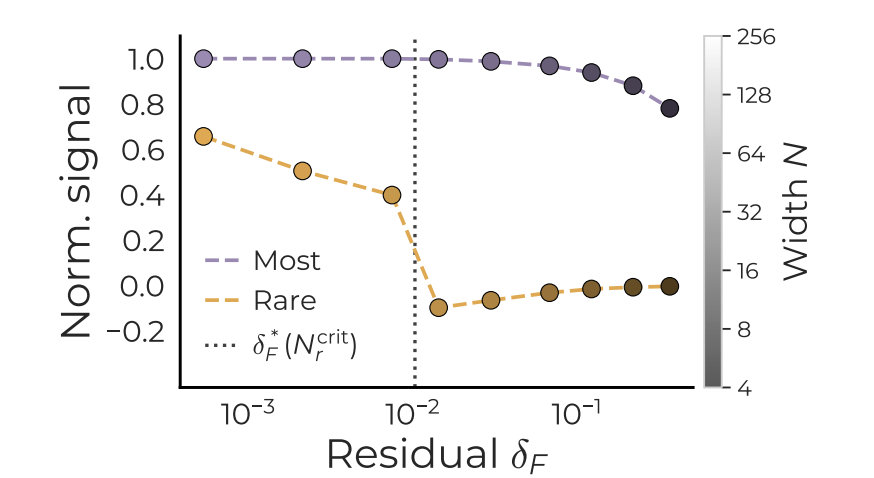
常见任务残差下降后,稀有任务信号才稳定进入表示
上图中,小模型仍有大量常见任务残差信号需要解释,稀有任务信号接近随机;当模型宽度跨过论文预测的阈值,常见任务残差下降,稀有任务才开始被稳定编码。
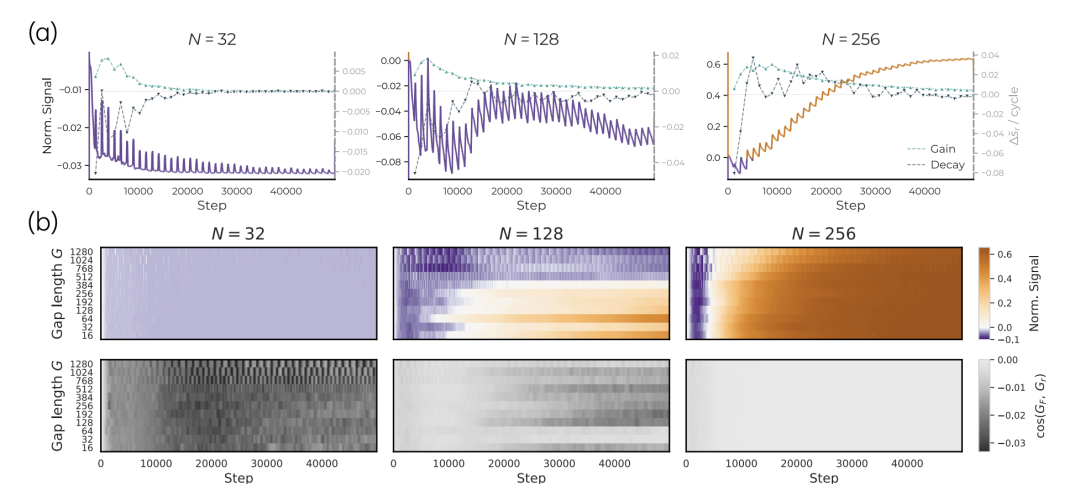
小模型短暂编码稀有任务后很快衰减,大模型能保留并累积信号
在上图中,作者保持稀有任务的总体频率不变,只改变相邻两次注入之间的间隔。小模型在每次注入后会短暂编码稀有任务,但随后迅速衰减;大模型则能在注入间隔之间保留更多信号,并在训练中逐步累积。
这意味着,大模型优势不只来自可表示内容更多,也来自对低频任务信号的保留能力更强。
OLMo 预训练验证
论文还把这套机制放到 OLMo 预训练 pipeline 里验证。实验训练了 4M、20M、300M、1B、4B 五个档位的 OLMo 模型,最多训练到 210B tokens。
预训练语料使用 Dolma v1.7。为了控制任务频率,作者向语料中注入两个在常规预训练数据中不太可能自然出现的任务:比较任务 TCMP 和模加任务 TADD。
这两个任务不是简单记忆题。每个任务有 10K 个实例,训练和测试各一半。比较任务要求模型学到 token 的全局顺序结构,模加任务则需要捕捉傅里叶模式。测试准确率衡量的是模型是否学到可泛化结构,而不是只记住训练样本。
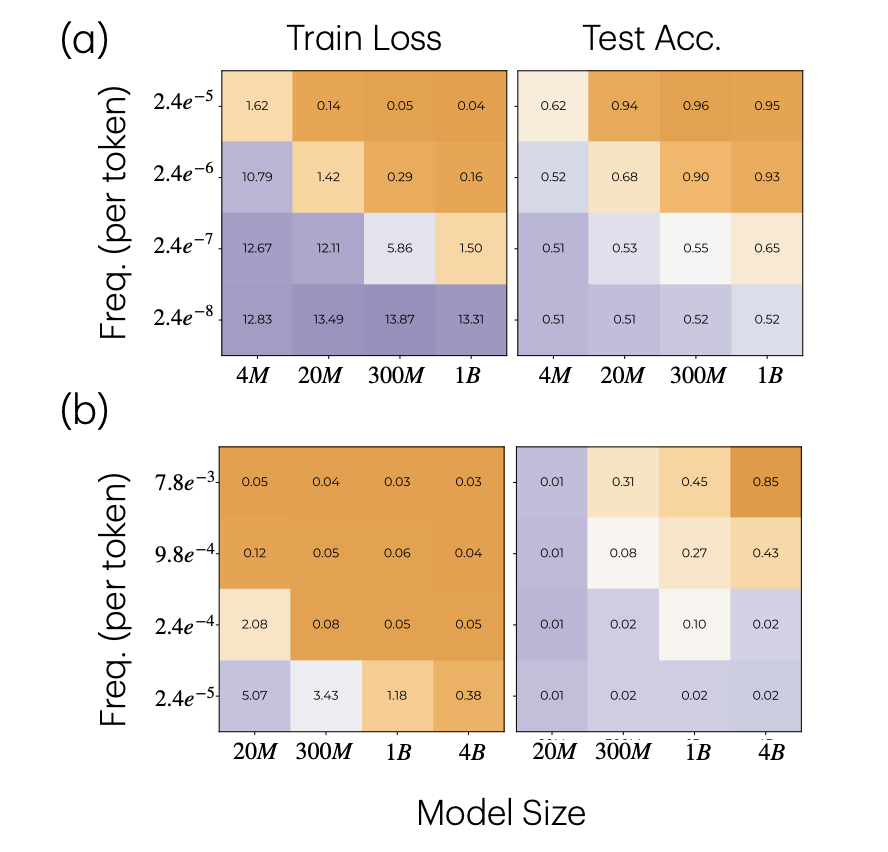
在 OLMo 预训练中,大模型更能学会低频注入任务
行为结果和合成实验一致:模型越大,越能学到更低频的注入任务;小模型在低频任务上的训练 loss 更高,测试准确率更低。
作者不只看 loss,还继续追到表示和梯度层面。
表示层面,随着模型规模和任务频率提升,TCMP 的全局顺序特征、TADD 的傅里叶特征会更明显地出现在模型内部表示中。
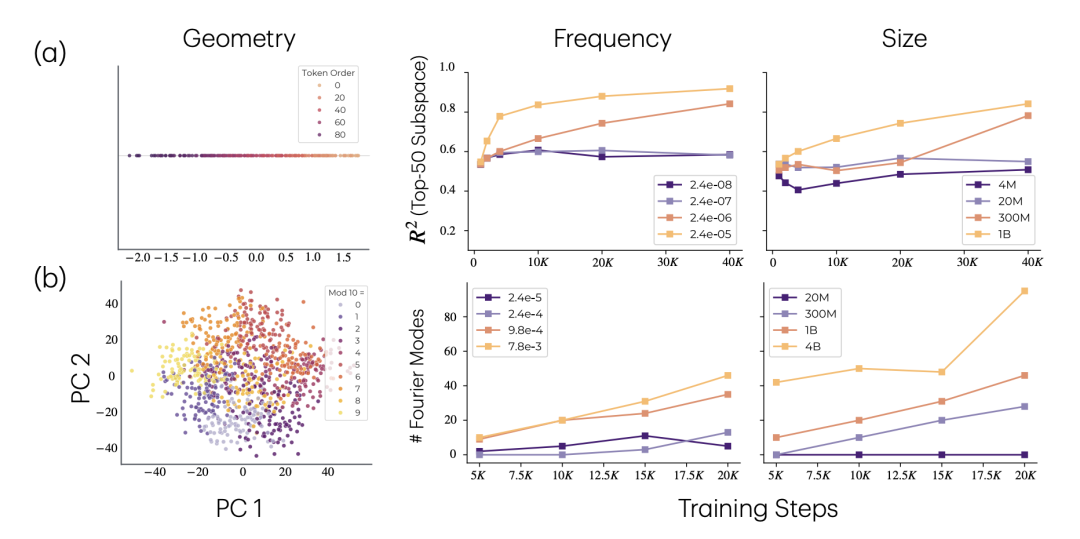
模型更大、任务频率更高时,任务相关特征更清晰地进入表示空间
梯度层面,作者聚焦 TCMP 训练运行中的一组任务相关神经元,分析 batch 梯度与任务参考方向的余弦相似度。
随后,他们把 batch 梯度拆成任务 token 梯度和非任务 token 梯度。
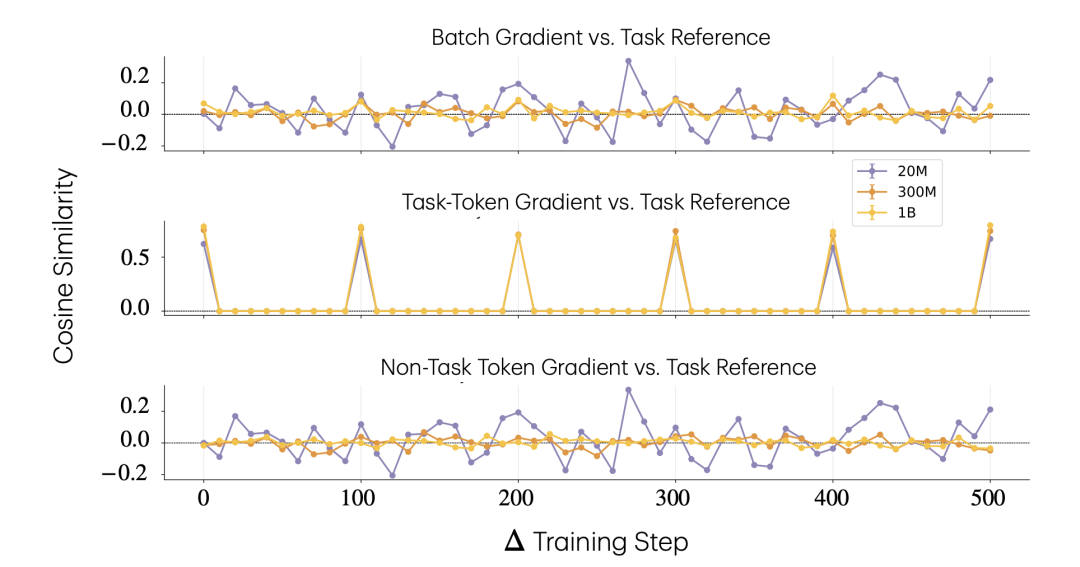
大模型的非任务梯度对任务方向干扰更小
结果显示,大模型在任务注入时携带更清晰的任务信号,非任务 token 梯度几乎不干扰任务方向;小模型则更容易出现随机碰撞和干扰。
三层证据指向同一个结论:模型越大,任务之间的互相覆盖越少。
Scaling 之外的启示
这篇论文并没有把 scaling 的优势归结为单一原因。大模型当然有更强的表达能力,也常常有更好的样本效率。论文讨论部分也强调,这里的解释不是 scaling 的完整理论,而是与表达能力、样本效率互补。
这篇论文真正补充的是另一层问题。在混合数据训练中,能力不只由模型能不能表示决定,还取决于梯度优化能不能从当前数据分布里稳定学到。
如果目标能力本身是低频、复杂任务,扩大模型并不是唯一选择。调整数据配比、提高目标任务频率,可能比单纯扩大模型更高效。至于如何系统性降低任务间梯度干扰,仍然需要后续研究。你可以在云栈社区找到更多关于模型训练与资源管理的深度讨论。
论文还提示,记忆并不总是训练中的副作用。在稀有任务上,它可能是模型跨 batch 累积信号、最终学到抽象结构的前提。
大模型比小模型强,不只是因为参数更多、容量更大。更具体地说,它让常见任务和稀有任务少了一些正面竞争。那些在小模型里刚写入、又很快被冲掉的稀有任务信号,可能正是大模型真正多学到的部分。 这背后折射的,正是当前人工智能领域在训练动力学上亟需深入理解的关键瓶颈。
 发表于 2026-6-4 21:23:41
|
查看: 52|
回复: 0
发表于 2026-6-4 21:23:41
|
查看: 52|
回复: 0
