不动损失函数、不加参数、不做最优传输,仅仅换掉一个集合的定义,跨分词器蒸馏在12个评测格子上全部刷新——中科大团队提出SimCT,把跨分词器蒸馏的天花板抬到了新的位置。
On-Policy Distillation(OPD)是把老师的能力迁到学生身上的主流路径。但它有一个几乎从未被认真追问过的隐含假设,即老师和学生用的是同一套分词器。
一旦换成跨家族的师生对,分词器不一样,OPD在每一步要对齐的“预测单元”就对不上,老师的大部分指导信号会被悄悄扔掉。
中科大团队联合腾讯混元、上海创智学院提出 Simple Cross-Tokenizer OPD(SimCT),不改OPD的损失函数、不加任何可训练模块、不做最优传输,仅通过把监督集合从“完全相同的token”扩成“两个分词器都能拼出来的最小对齐单元”,就把被丢掉的老师信号捡了回来。
在三组异构师生对、四个数学和代码benchmark上,SimCT在全部12个评测格子上均取得最优,全面超过DSKD、GOLD、ALM等更复杂的跨分词器蒸馏基线,且训练开销几乎等同于最轻量的SimpleOPD。
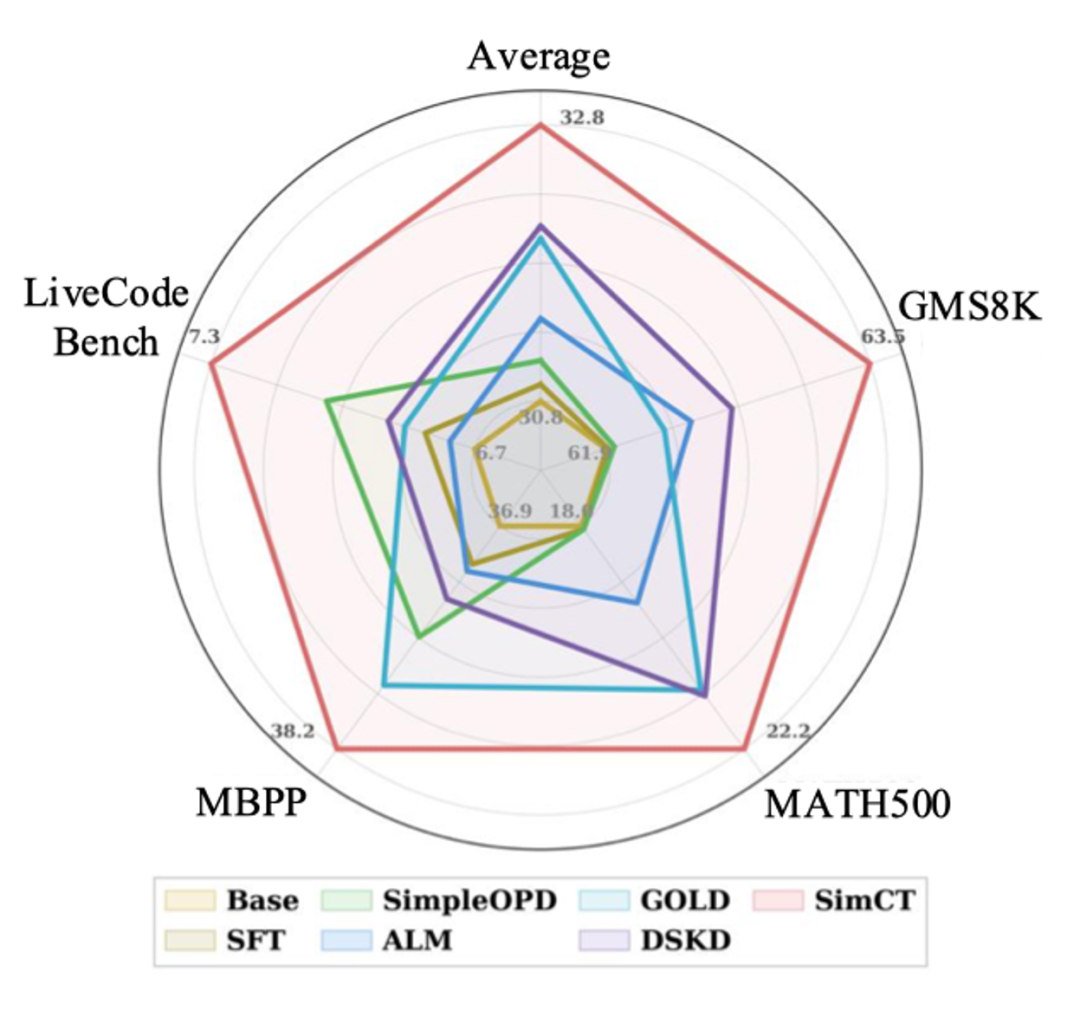
图1:SimCT在四个benchmark上的平均Pass@1全面领先SFT和现有跨分词器基线。

论文标题:
SimCT: Recovering Lost Supervision for Cross-Tokenizer On-Policy Distillation
论文地址:
https://arxiv.org/pdf/2605.07711
代码地址:
https://github.com/sunjie279/SimCT-
背景介绍
OPD的基本流程是这样的:学生模型先自己rollout一段前缀,老师在这段前缀上给出下一个token的分布,学生用这个分布作为监督信号来更新自己。
这套做法的好处是训练分布和推理分布一致,避免了离线蒸馏里“训练时见的上下文和推理时见的上下文对不上”的老问题。
但OPD在每一步都要回答一个问题,那就是老师的下一个token分布和学生的下一个token分布该怎么比。
在同分词器的情况下这不是问题,两个分布都落在同一个词表上,可以直接逐token算KL:
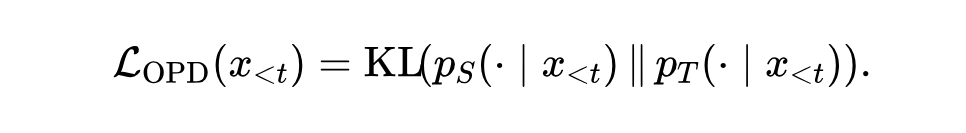
一旦分词器不同,麻烦就来了,并且会以两种方式同时出现。
第一种是词表层面的不匹配。老师和学生的下一token分布分别落在各自的词表上:
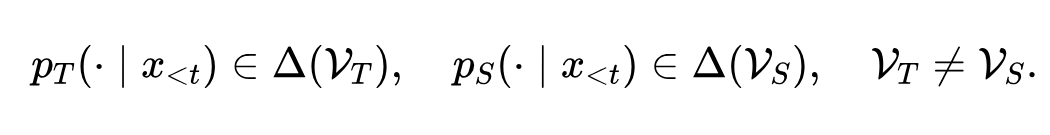
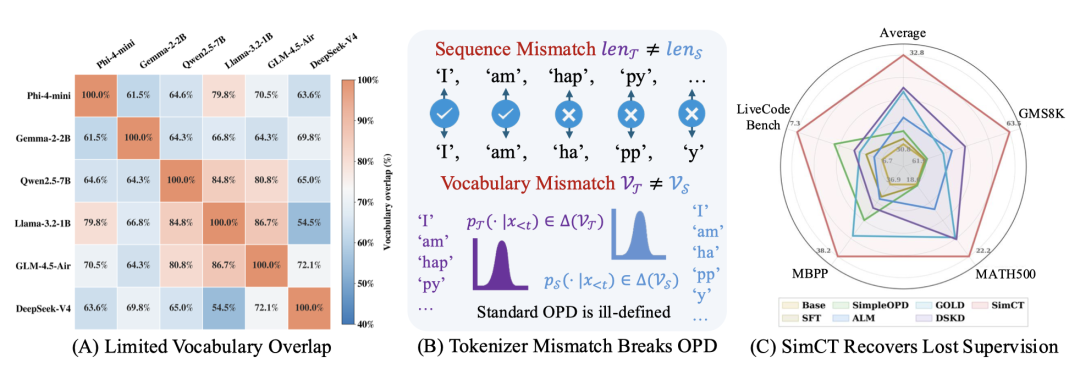
图2:SimCT的动机与效果。(A)主流大模型的词表两两交集普遍只有60%–80%,靠“共享词表”做蒸馏先天就被砍掉一大块;(B)即使在1:1对齐的位置,老师和学生切出来的token序列长度也常常不一样,标准OPD在这种位置上ill-defined;(C)SimCT在四个benchmark上的平均Pass@1全面领先SFT和现有跨分词器基线。
如图2(A)所示,主流LLM两两词表的交集通常只有60%–80%。如果只在交集里做监督,老师那一大块“非共享词”上的概率就直接被丢掉了。
第二种是序列层面的不匹配。同一段文字“happy”,老师可能切成“hap”+“py”,学生可能切成“ha”+“pp”+“y”,长度都不一样,即 $len_T \neq len_S$。
这意味着老师在某个位置的下一token分布,和学生在“同一个位置”的下一token分布,根本不是在预测同一段文字。如图2(B)所示,标准OPD在这种位置上是ill-defined。
现有的跨分词器OPD方法大致分三类。最优传输类(如ULD、GOLD)在每个位置算分布间的传输代价,开销不小。
表征迁移类(如DSKD)引入一个额外的可训练投影模块来对齐两边的输出空间,增加了参数量。
绕开token类(如ALM、字节级方法)跳过token直接在更粗的粒度上做监督,简单但损失了细粒度信息。
这三类方法都在“如何让两边可比”上加了不少设计。一个自然的反问是,是否有一个足够简单的监督接口,同时还能把分词器不匹配带来的信号损失捡回来?
为什么“共享词表”不够用
要回答上面那个问题,先得搞清楚最朴素的方案到底丢了什么。我们把“只在两边词表交集 $V_T \cap V_S$ 上做监督”这个朴素方案叫做SimpleOPD,并把它作为最直接的基线。它有两个看似稳健、其实非常保守的设计选择。
(1)只在两边能1:1对齐的token位置上做监督。
(2)在这些位置上,也只看那些同时出现在两边词表中的token。
这两个选择导致了双重信号丢失,我们在§5会做定量验证。在那之前,先看SimCT怎么把丢掉的东西捡回来。
SimCT
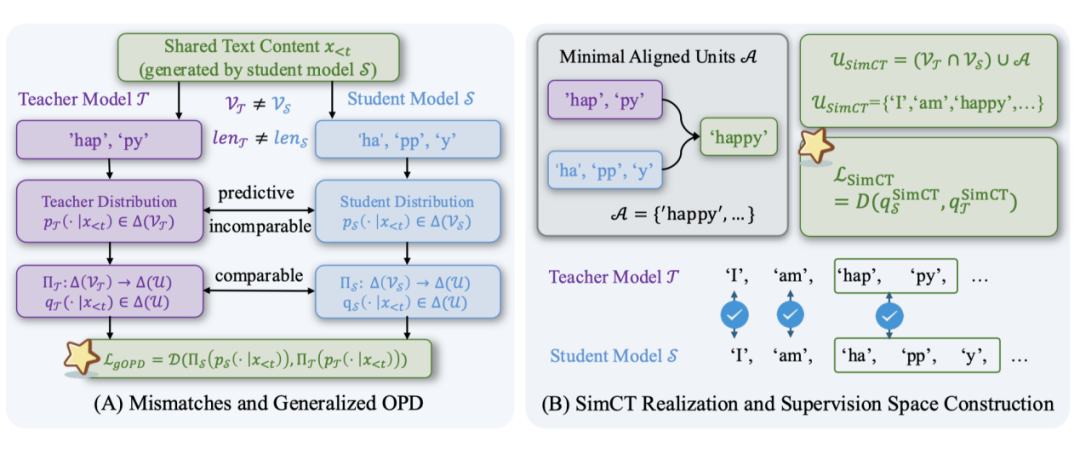
图3:SimCT的框架。(A)跨分词器OPD的核心问题是两个分布落在不同的词表上,需要一个共同的监督空间 $U$ 来桥接。(B)SimCT构造的监督空间是“共享词表 $V_T \cap V_S$ + 最小对齐单元”,然后照搬标准OPD的反向KL损失。
SimCT的核心想法可以用一句话讲完,那就是不改OPD的目标函数,只把监督空间换成一个更大的、两个分词器都能拼出来的单元集合。
形式上,我们引入一个共同监督空间 $U$ 和两个打分映射
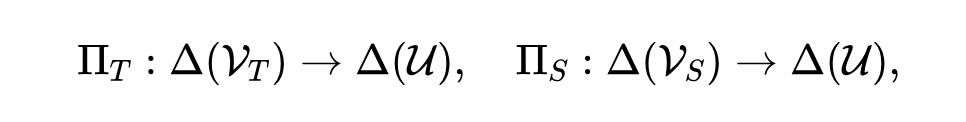
把老师和学生的下一token分布都映到 $U$ 上,得到可比的分布
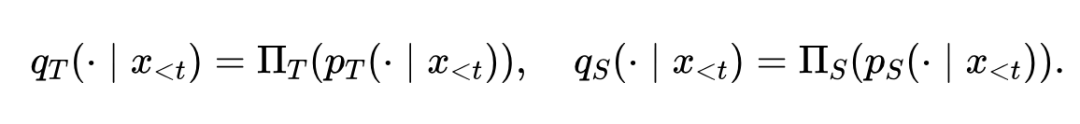
监督空间怎么选,决定了这个框架的下限。对于一段老师切成“hap”+“py”、学生切成“ha”+“pp”+“y”的“happy”,这段文字本身在两边词表里都不存在,但它作为一个连续片段可以被任意一边拼出来。
如图3(B)所示,SimCT把这种“两边都能拼出来的最小连续片段”叫做最小对齐单元(Minimal Aligned Unit),记作 $A$。新的监督空间就是
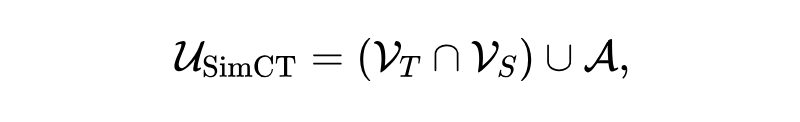
也就是共享token加上最小对齐单元。
在这个空间上,老师和学生的分布都被重新打分。对于共享token,打分就是原本的log概率 $\log p_M(v|x_{<t})$。
对于一个最小对齐单元 $u$,它在某一边可能由 $k$ 个token拼成,记作 $v_1,..,v_k$,那么这一边给 $u$ 的打分是:
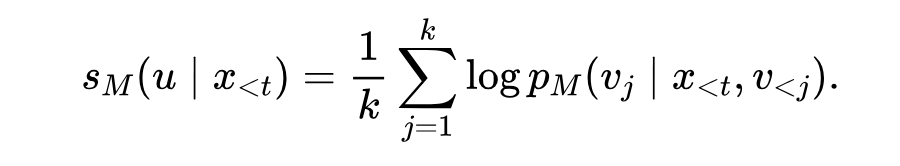
这里 $1/k$ 是一个标准的长度归一化,避免分得更碎的那一边天然吃亏。最后两边在监督空间上各自做一次softmax归一化,得到两个可比的分布:
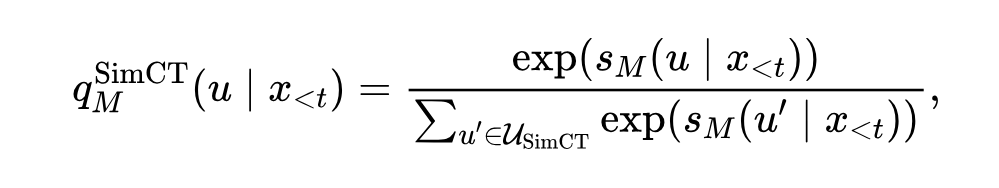
损失函数直接套用标准的反向KL:
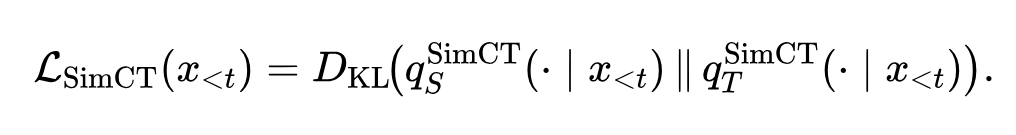
需要强调,整个流程没有引入任何可训练参数,没有最优传输计算,也没有学习投影。
两边的最小对齐单元集合直接由两个分词器在文本边界上的并集决定,是一个纯几何构造。具体推导和算法伪代码可参见原文§3.3和Algorithm 1。
理论性质
为什么要用“最小”对齐单元,而不是更粗或更细?文中给出了两个结果。
定理1(最小性):对任意分词器不匹配的文本片段,SimCT构造出的对齐单元划分是两个分词器联合可表达的最细划分。更细的切分必然会切穿某一边的完整token;更粗的切分则没有必要。
命题1(粗化会抹掉信号):把若干个最小对齐单元按粗化方案 $C$ 合并成更粗的单元,并相应聚合概率质量
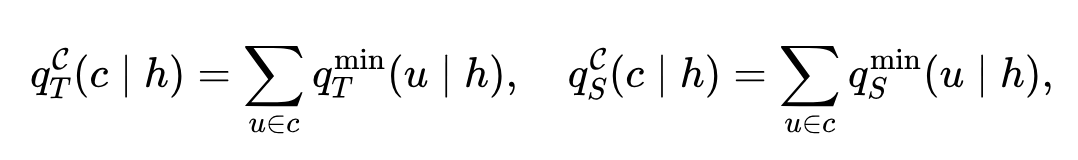
那么粗化后的KL严格不大于最小单元上的KL:
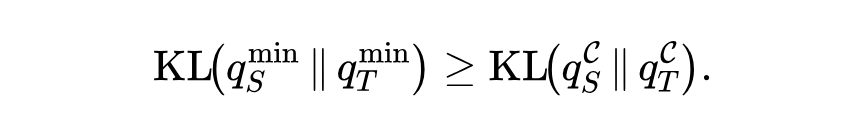
两者之差正好等于“被合并单元内部的师生分布差异”,可以由如下被抹掉的KL信号量来度量:
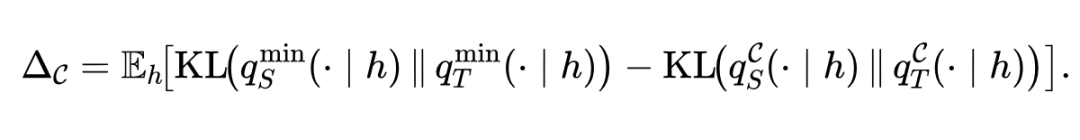
命题1的实际含义是,粗化的代价不是“简化”而是“抹掉”。被合并的几个最小单元内部,老师和学生本来有偏好差异,这正是OPD想学的局部信号,粗化会把它平均掉。这个理论预测在§5.3会被直接验证。
实验
实验部分分三段来讲。第一段比SimCT和现有跨分词器基线的整体表现。第二段把SimpleOPD丢掉的信号拆开,验证SimCT的提升究竟来自哪里。第三段用粗化消融验证“最小”这件事是否真的重要。
5.1 整体效果
我们在三组真实的异构师生对上做评测:Qwen2.5-7B → Gemma-2-2B、Qwen2.5-7B → Phi-4-mini、Phi-4-mini → Gemma-2-2B,覆盖两个老师家族和两个学生家族。
Benchmark包括数学推理(GSM8K、MATH-500)和代码生成(MBPP、LiveCodeBench-v6)。
所有方法从同一个SFT warm-start checkpoint出发,OPD的训练循环、prompt、优化器、调度、算力预算完全一致,唯一的变量就是监督接口的构造方式。
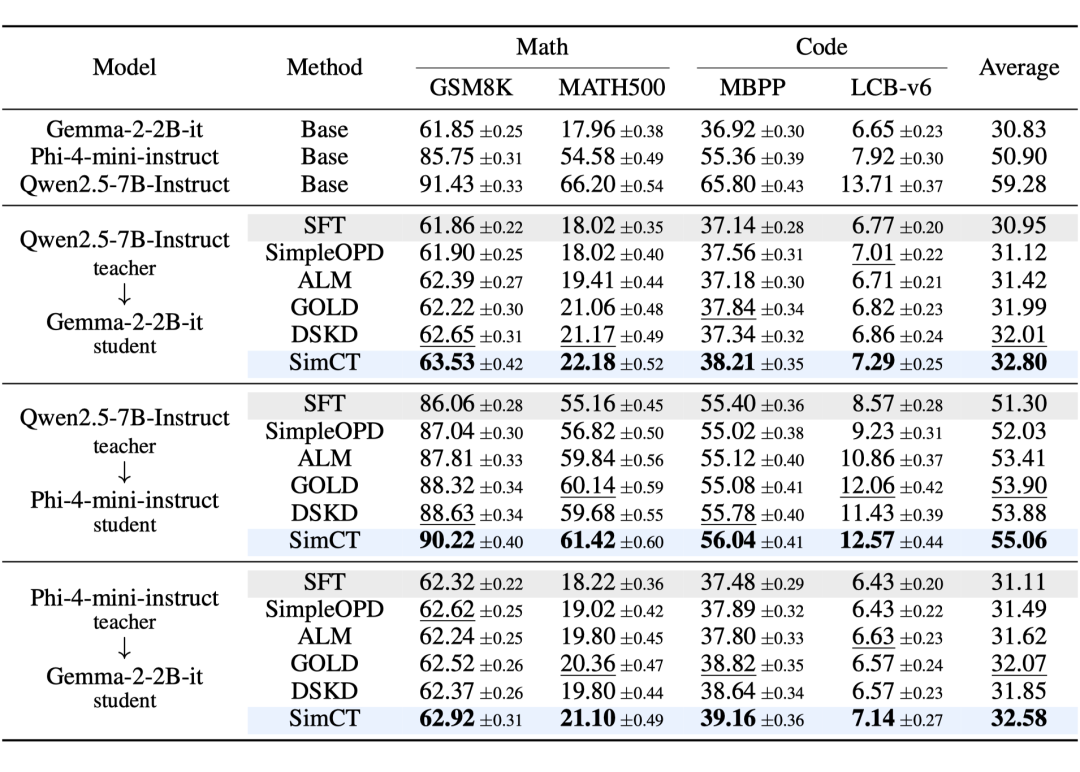
表1:跨分词器OPD主结果。所有蒸馏方法从同一个SFT warm-start checkpoint出发,遵循同一套训练协议。报告5次评测的Pass@1平均值。每组师生对内的最优结果加粗,次优结果下划线。
从表1可以看出三件事。
(1)SimCT在三组师生对的平均分上全部第一,并且在12个“师生对 × benchmark”组合中全部取得最优或并列最优。Qwen → Phi这一组相对SFT平均提升7.3%,是涨幅最大的一组。
(2)SimpleOPD相对SFT几乎没涨(三组平均涨幅0.4%–0.8%),印证了“只用共享词表”是一个非常保守、几乎浪费OPD的选择。
(3)DSKD、GOLD、ALM都比SimpleOPD有提升,但它们之间没有稳定的排序,在不同师生对上互有胜负。这意味着“让两边可比”是必要的,但远远不够,监督接口还得保留OPD真正需要的局部师生差异,而这正是最小对齐单元在做的事。
附录E报告了训练时间。SimCT相对SimpleOPD的额外开销很小(平均每轮2.69h vs 2.53h),并且比ALM、GOLD、DSKD都快。也就是说,它在准确率上最高、在开销上最接近最便宜的基线。
5.2 SimCT到底捡回了什么
第一段证明了SimCT有效,第二段要回答的是它的增益究竟来自哪里。
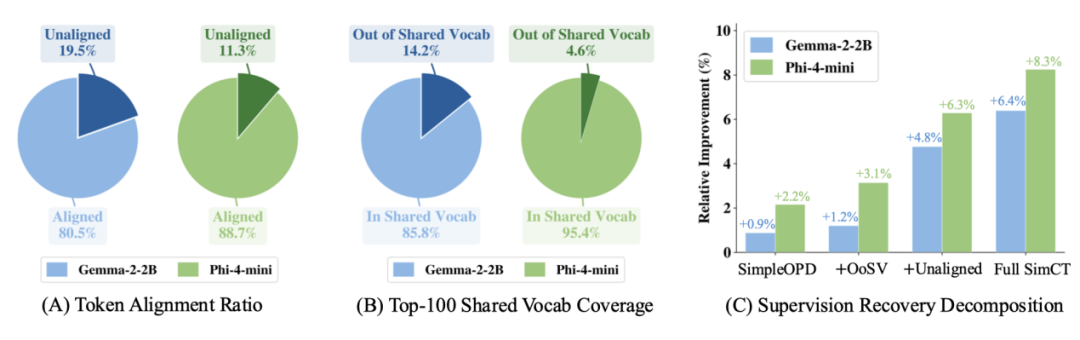
图4:分词器不匹配下的信号回收。(A)大量老师和学生token无法1:1对齐,反映了序列层面的信号损失。(B)即使在能对齐的位置,老师的高概率预测也常常落在共享词表之外。(C)从SimpleOPD出发逐步把丢失的信号加回去,性能逐级提升,完整版SimCT同时覆盖两类损失。
图4(A)显示,在Gemma上有19.5%的token、Phi上有11.3%的token完全无法做1:1对齐,被SimpleOPD直接跳过。
图4(B)进一步显示,即使在1:1对齐的位置上,Gemma也有14.2%的“老师top-100高概率预测”落在共享词表之外,被SimpleOPD一并丢掉。
更关键的是,这些被丢掉的信号不是分词器噪声,而是真正有用的监督。图4(C)做了一个直接验证。
从SimpleOPD出发,单独把“非共享词表的预测”加回去(+OoSV),性能在两个学生上分别涨2.2%和3.1%。单独把“无法1:1对齐的位置”加回去(+Unaligned),分别涨4.8%和6.3%。
把两者都加回去(也就是完整版SimCT),分别涨6.4%和8.3%。两个来源的增益基本可以叠加,说明它们对应的是两类独立的、真实存在的信号损失,而SimCT用一个统一的最小对齐单元空间把它们一起捡了回来。
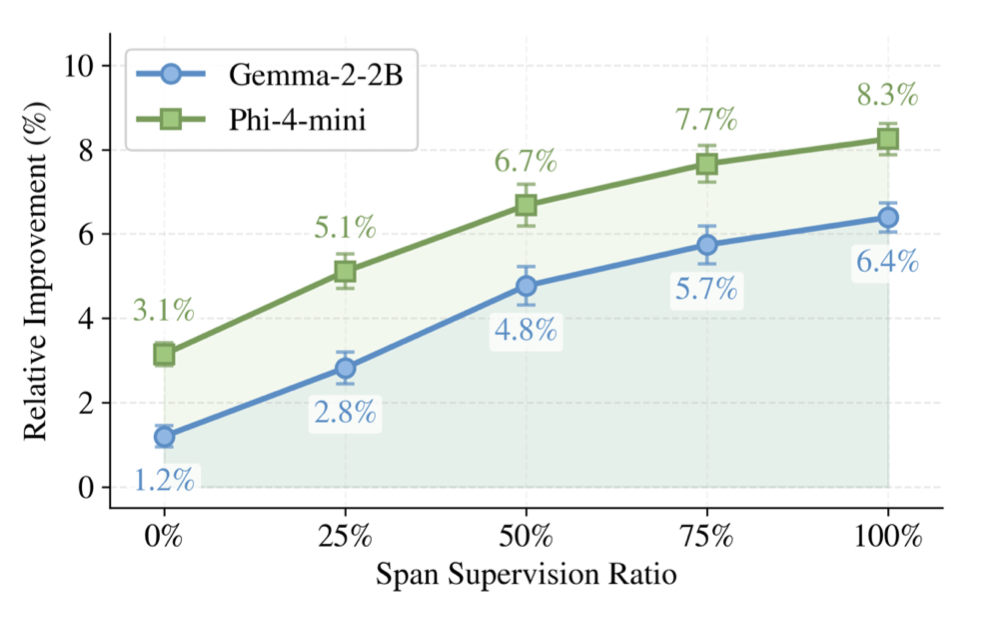
图5:监督单元覆盖率扫描。横轴是被回收的不匹配单元监督占总量的比例,纵轴是相对SFT的提升。两个学生上趋势都是单调向上的。
图5进一步把“回收比例”作为变量扫了一遍。从0%到100%,两个学生的下游提升都是单调向上的,并且没有出现饱和的迹象。这说明被丢掉的信号不是少数几个有用、其余无用,而是整体上稳定有用。
5.3 粗化消融,验证“最小”的必要性
前两段证明了SimCT捡回的信号是有用的。第三段要回答的是,回收的颗粒度是否也重要。如果把最小对齐单元合并成更粗的单元,会怎样?
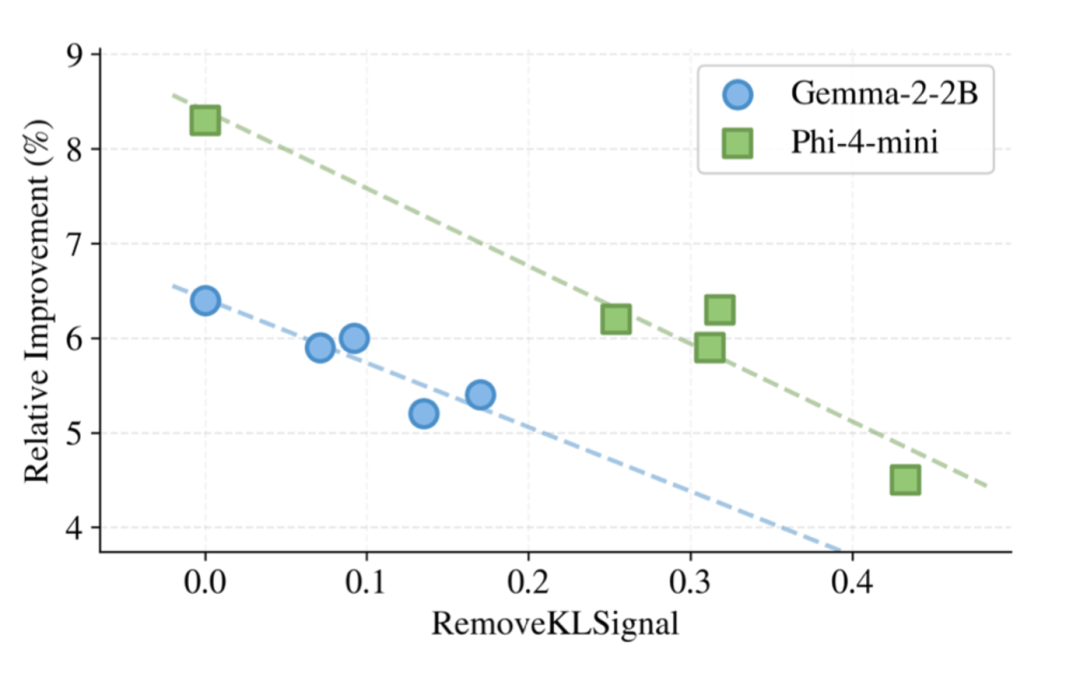
图6:粗化消融。横轴是粗化抹掉的KL信号量 $\Delta_C$(按命题1的公式估计),纵轴是相对SFT的提升。两个学生上都呈现明显的负相关,被抹掉的KL越多,下游增益越少。
我们按§3.4的命题1构造了一组逐步粗化的变体,每一档把若干相邻的最小对齐单元合并成更大的单元,并按$\Delta_C$的公式计算被抹掉的KL信号量。如图6所示,$\Delta_C$越大,下游提升越小,且两个学生上趋势完全一致。
这一结果直接验证了命题1的实际含义,那就是粗化不是“简化”,而是“抹掉”。被合并的几个最小单元内部,老师和学生本来有偏好差异,这正是OPD想要学习的局部信号。
把它们平均成一个粗单元的概率质量,从信号角度等价于把这部分师生差异抹平。这也解释了为什么ALM这类“在更粗的chunk上做监督”的方法虽然简单,但在表1中表现不够稳定。
 发表于 2026-6-4 21:27:29
|
查看: 151|
回复: 0
发表于 2026-6-4 21:27:29
|
查看: 151|
回复: 0
