最近关于Hermes Agent的讨论热度很高,它提出的从历史交互中学习并生成可复用Skill的机制,确实让人眼前一亮。今天,我们就来深入拆解一下,它是如何构建这个Skill闭环系统的,以及它的原生设计存在哪些不足,我们又该如何用现代检索技术为其升级。
与市面上大多数Agent框架相比,Hermes Agent最大的特点在于其“Learning Loop”(学习循环)。它能够从历史任务执行经验中自动提取流程、存储知识,并在后续遇到类似问题时智能检索并复用这些经验,从而让Agent具备自主进化的能力。
这个思路对于处理复杂、重复性的任务而言,无疑是革命性的。它让Agent的记忆不再只是聊天的上下文,而是转化为了实实在在的、可被调用的工具能力。
但实话实说,当前版本Hermes Agent的核心检索机制还比较初级,这严重限制了其“进化”潜力。它自带的基于SQLite FTS5的关键词检索,在面对语义相近但字面不同的查询时,往往无能为力。如果连相关的历史经验都找不到,又何谈从中学习并生成高质量的Skill呢?
因此,本文将手把手带你搭建一套 “Hermes Agent + Milvus 2.6 + 飞书” 的增强方案。我们将用Milvus的混合检索(Hybrid Search)能力,为Hermes Agent装上能理解语义的“大脑”,构建一个真正能跨会话记忆操作、并自主迭代Skill的个人知识库助手。
一、透视Hermes Agent:四层记忆架构与核心机制
要理解Hermes记忆设计的精妙之处,我们得先拆解其架构。它采用了经典的四层记忆设计:
- L1 上下文记忆(Context Window):即当前会话窗口内的实时信息,会话结束后即被清空。这是大多数LLM应用的标配。
- L2 持久化摘要(MEMORY.md/USER.md):以Markdown文件形式,跨会话持久化存储事实性知识、用户偏好等摘要信息。
- L3 原生检索记忆(SQLite Episode History):基于SQLite FTS5实现的关键词全文检索,用于在本地历史记录中定位信息。
- L4 Skill记忆(Skill Documents):以Markdown文档形式存储的可执行操作流程,这是Hermes区别于其他框架的灵魂所在。
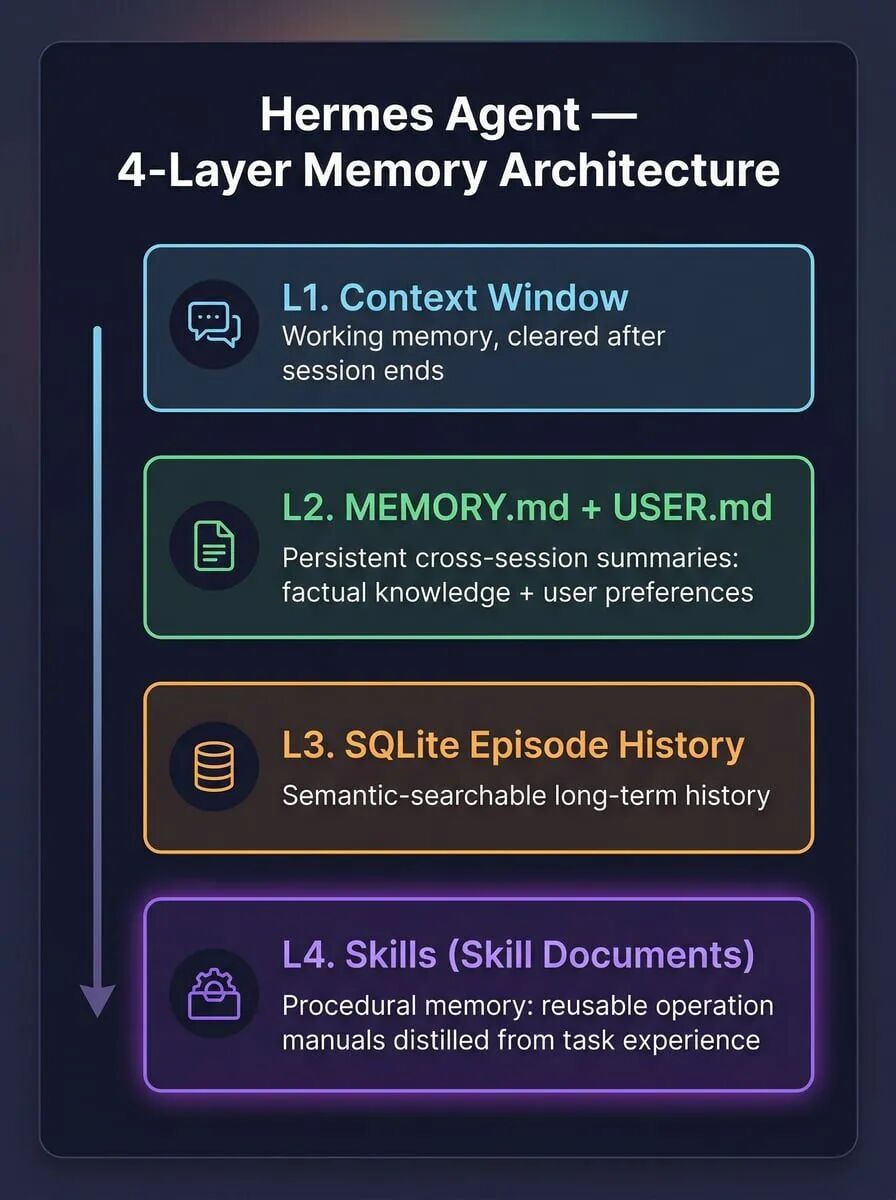
L4 Skills层是Hermes与其他Agent框架最本质的区别。这并不是说其他框架没有Skill或Tool的概念,像LangChain、AutoGPT都有类似设计。关键差异在于Skill的来源。
传统框架的Skill需要开发者在部署前手动定义并编码固化。而Hermes的Skills是从实际的任务执行记录中自动提炼的。例如,当你通过一个Python脚本完成了一次知识库检索后,Hermes的Learning Loop会评估这个工作流。如果判定其有复用价值,就会自动将其固化为一个名为 hybrid-search-doc-qa 的Skill文档。从此,这个流程就成了Agent可复用的“肌肉记忆”,无需任何代码改动。
然而,经过深度实践,我发现一个关键问题:要想让Hermes稳定地学会高质量的Skill,仅靠其原生的L3关键词检索是远远不够的。
二、为什么要引入Milvus?Hermes原生检索的局限性
Hermes实现“跨会话触发相同工作流”的前提,是能通过检索系统精准地找到历史上的相似操作。
但其自带的L3检索基于SQLite FTS5,这是一种关键词倒排索引,擅长精确的字面匹配,在语义检索场景下存在明显短板。
一个典型场景是:你的知识库中记录了“asyncio事件循环”、“异步任务调度”、“非阻塞I/O”等内容。当你询问“Python并发处理有哪些方式?”时,FTS5很可能一条记录都找不到,因为查询语句和文档内容在字面上没有重叠。
因此,当知识库规模增长到数百份文档后,就必须引入向量语义检索来弥补Hermes的这块短板。这就是我们引入 Milvus 的核心原因。
选型Milvus 2.6的两个实际理由
- 原生混合检索(Hybrid Search)能力
Milvus 2.6支持在同一次查询中,并行执行向量检索(捕捉语义)和BM25全文检索(捕捉关键词),并通过RRF(Reciprocal Rank Fusion)算法智能融合两路结果。无论是询问“asyncio的原理”(语义),还是查找“find_similar_task函数在哪”(关键词),或是更复杂的混合查询,都能一次检索得到精准结果,无需手动编写路由逻辑。
- 分层存储,控制部署成本
Milvus 2.6引入了Hot(内存)、Warm(SSD)、Cold(对象存储)三层存储架构,能根据数据访问频率自动进行冷热数据分级。这意味着一个500份文档的向量知识库,无需全部常驻内存,可以将内存消耗控制在2GB以内,在每月5美元的VPS上也能流畅运行。
明确了选型原因,下面我们来看整个增强系统的架构设计。
三、系统整体架构设计
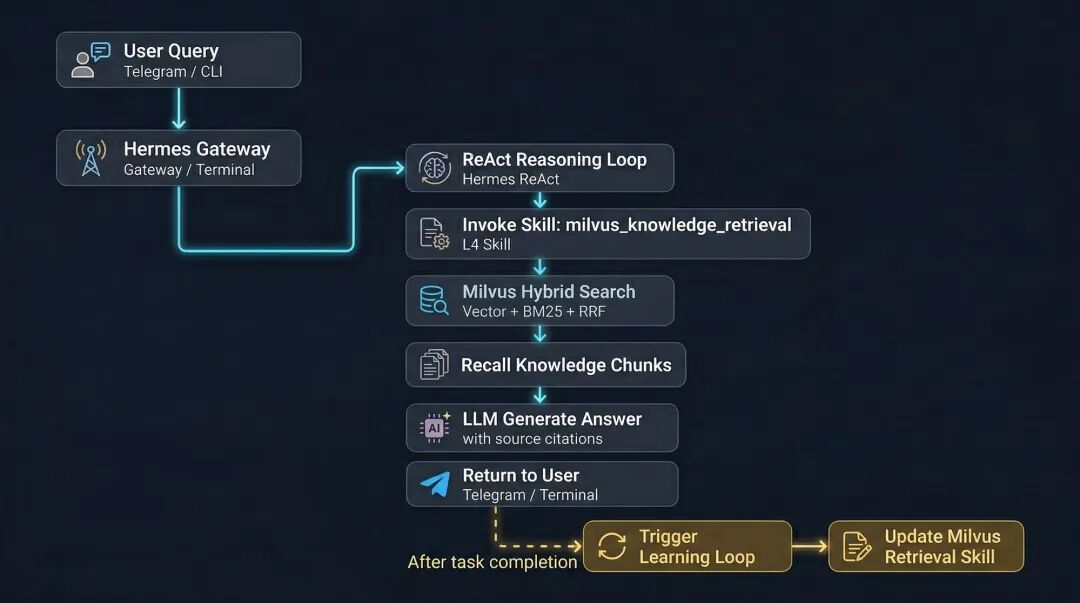
在新的体系下,Hermes Agent与Milvus各司其职:
- Hermes Agent 负责思考与决策(What):理解用户意图,判断该调用哪个Skill来解决问题。
- Milvus 负责知识的精准召回(How):根据问题,通过混合检索找到最相关的知识片段。
两者协同,完成从“提问”到“生成有据可查的回答”的完整闭环。工作流程如下图所示:
四、安装与部署实战
4.1 安装并初始化 Hermes Agent
通过官方脚本安装Hermes Agent:
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
安装后运行 hermes 命令,跟随交互式向导完成初始化,主要配置两项:
- LLM提供商:支持OpenAI、Anthropic、OpenRouter等。
- 消息渠道:本文以飞书机器人为例。
配置成功后,你将能看到如下交互界面:
4.2 部署 Milvus 2.6 Standalone 版
对于个人或轻量级使用,Standalone(单机)模式完全足够。
curl -sfL https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh \
-o standalone_embed.sh
bash standalone_embed.sh start
# 验证服务是否启动
docker ps | grep milvus
4.3 创建支持混合检索的知识库 Collection
Schema设计直接决定了检索能力的上限。以下Python脚本创建一个同时支持稠密向量和BM25稀疏向量检索的Collection。
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(
uri="http://192.168.x.x:19530",
)
schema = client.create_schema(auto_id=True, enable_dynamic_field=True)
schema.add_field("id", DataType.INT64, is_primary=True)
# 原始文本(BM25 全文检索用)
schema.add_field(
"text",
DataType.VARCHAR,
max_length=8192,
enable_analyzer=True,
enable_match=True
)
# 稠密向量(语义检索)
schema.add_field("dense_vector", DataType.FLOAT_VECTOR, dim=1536)
# 稀疏向量(BM25 自动生成,Milvus 2.6 特性)
schema.add_field("sparse_vector", DataType.SPARSE_FLOAT_VECTOR)
schema.add_field("source", DataType.VARCHAR, max_length=512)
schema.add_field("chunk_index", DataType.INT32)
# 告诉 Milvus 用BM25 把text 自动转换为 sparse_vector
bm25_function = Function(
name="text_bm25",
function_type=FunctionType.BM25,
input_field_names=["text"],
output_field_names=["sparse_vector"],
)
schema.add_function(bm25_function)
index_params = client.prepare_index_params()
# HNSW 图索引(稠密向量)
index_params.add_index(
field_name="dense_vector",
index_type="HNSW",
metric_type="COSINE",
params={"M": 16, "efConstruction": 256}
)
# BM25 倒排索引(稀疏向量)
index_params.add_index(
field_name="sparse_vector",
index_type="SPARSE_INVERTED_INDEX",
metric_type="BM25"
)
client.create_collection(
collection_name="hermes_milvus",
schema=schema,
index_params=index_params
)
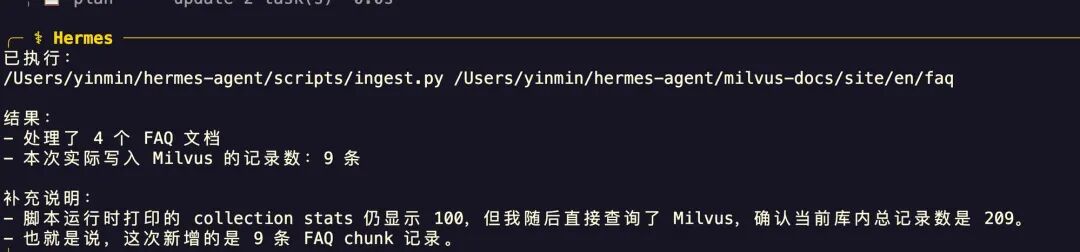
创建Collection后,你可以通过脚本将本地文档(如Markdown、PDF)向量化并摄入到Milvus中。成功摄入后,会有类似下图的输出:
4.4 核心:混合检索(Hybrid Search)脚本
这是连接Hermes与Milvus的桥梁。Hermes将通过调用这个脚本来获取知识。
import sys, json
from openai import OpenAI
from pymilvus import MilvusClient, AnnSearchRequest, RRFRanker
client = MilvusClient("http://192.168.x.x:19530")
oai = OpenAI()
COLLECTION = "hermes_milvus"
def hybrid_search(query: str, top_k: int = 5) -> list[dict]:
# 1. 向量化查询
dense_vec = oai.embeddings.create(
model="text-embedding-3-small",
input=query
).data[0].embedding
# 2. 稠密向量检索(语义相关性)
dense_req = AnnSearchRequest(
data=[dense_vec],
anns_field="dense_vector",
param={"metric_type": "COSINE", "params": {"ef": 128}},
limit=top_k * 2 # 候选集适当放大,交给 RRF 做最终排序
)
# 3. BM25 稀疏向量检索(精确词项匹配)
bm25_req = AnnSearchRequest(
data=[query],
anns_field="sparse_vector",
param={"metric_type": "BM25"},
limit=top_k * 2
)
# 4. RRF 融合排序
results = client.hybrid_search(
collection_name=COLLECTION,
reqs=[dense_req, bm25_req],
ranker=RRFRanker(k=60),
limit=top_k,
output_fields=["text", "source", "doc_type"]
)
return [
{
"text": r.entity.get("text"),
"source": r.entity.get("source"),
"doc_type": r.entity.get("doc_type"),
"score": round(r.distance, 4)
}
for r in results[0]
]
if __name__ == "__main__":
query= sys.argv[1] if len(sys.argv) > 1 else ""
top_k = int(sys.argv[2]) if len(sys.argv) > 2 else 5
output = hybrid_search(query, top_k)
print(json.dumps(output, ensure_ascii=False, indent=2))
一切就绪后,最激动人心的部分来了:见证Hermes Agent的跨会话学习与Skill自动生成。
五、实战演示:Skill的自动生成与进化
Step 1:会话一 - 首次手动执行检索
在飞书中向Hermes发送明确指令,要求其调用特定的混合检索脚本。
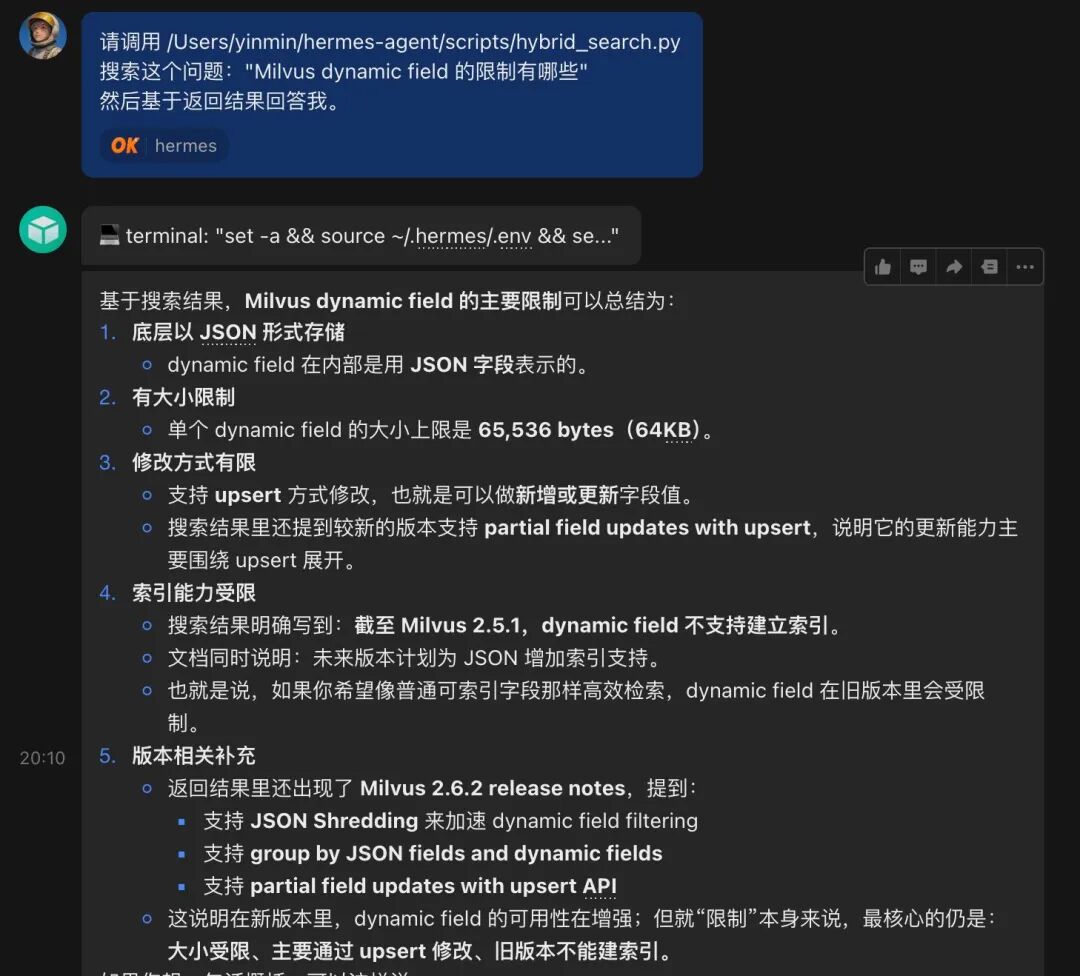
此时,Hermes只是简单地执行了终端命令,Skill尚未创建。
Step 2:开启全新会话 - 直接提问
清空对话,开启一个全新的会话。这次,不提及任何脚本或路径,直接提出一个知识型问题。

Step 3:记忆更新与Skill创建
这时,Hermes的Learning Loop开始运作。它首先会尝试从记忆(Memory)中寻找解决方案。由于我们在会话一有过类似操作,它会识别出当前问题与历史经验的相似性,并自动调用之前的检索流程。
首先,你会看到 Memory updated 的提示,这意味着本次的工作流(调用哪个脚本、参数是什么、返回结构如何)被作为经验记录了下来。
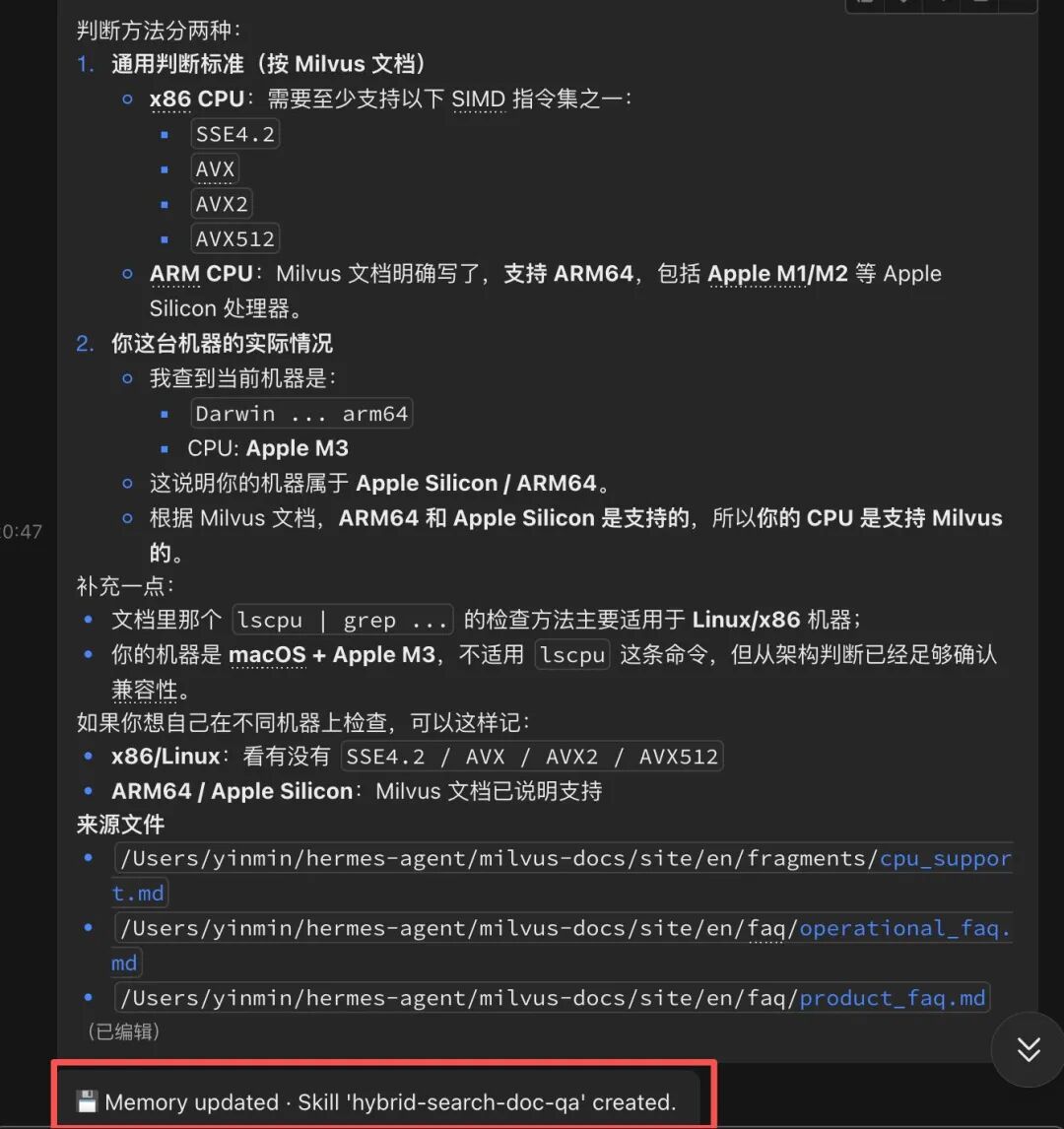
紧接着,在任务完成后,系统判定此工作流具有高复用价值,于是自动将其固化为一个正式的Skill。你会看到最终的提示:Skill ‘hybrid-search-doc-qa’ created.。
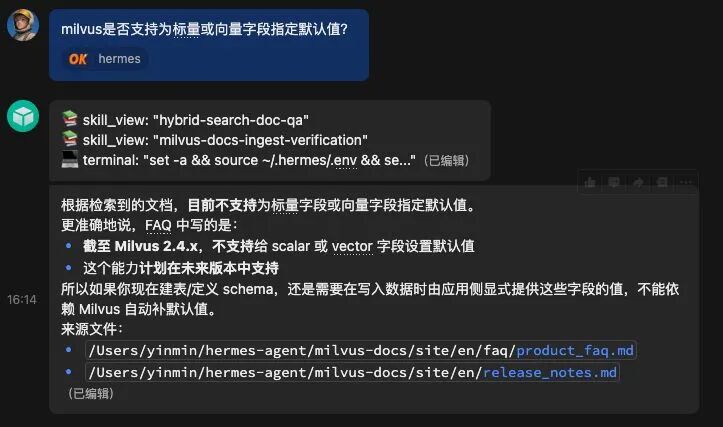
这个过程里,Memory和Skill是两个层级:
- Memory:记录“发生了什么”,是原始的经验日志。
- Skill:定义“下次怎么做”,是规范化、可被反复调用的操作手册。
Hermes完成的是从“积累经验”(Memory)到“封装能力”(Skill)的质变。此后,当用户提出类似问题时,Hermes会自动识别意图、路由到 hybrid-search-doc-qa 这个Skill、从Milvus召回知识并生成回答,全程无需用户干预。
这与传统RAG系统的根本不同在于:检索策略本身(用什么模型、调什么参数、如何融合结果)被沉淀为了一个可持久化、可迭代、有版本记录的Skill对象,而不仅仅是写死在代码里的固定流程。
六、总结与框架对比
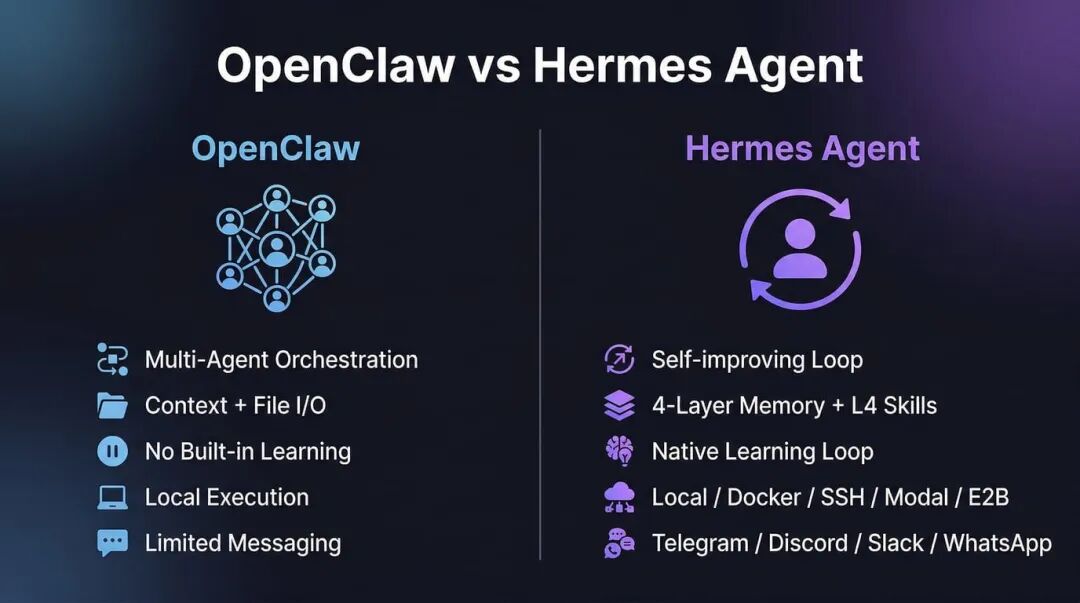
面对目前众多的Agent框架,很多人会好奇Hermes与另一个热门框架OpenClaw有何不同。
在我看来,两者的核心设计取向决定了其适用场景:
- OpenClaw的核心是“编排”:擅长将复杂任务拆解,并分发给多个各司其职的专用Agent去协同完成,强调任务执行的自动化与流水线效率。
- Hermes的核心是“积累”:专注于让单个Agent在长期互动中持续学习,将经验转化为可复用的技能,适合需要深厚领域知识和上下文延续的场景。
简而言之,如果你的核心需求是任务分解与多Agent协作,选OpenClaw;如果是个人或领域知识的长效积累与复用,选Hermes。两者并非对立,Hermes官方甚至提供了从OpenClaw迁移记忆和Skill的工具。
通过本文的实践,我们为Hermes Agent补上了原生检索的短板,用Milvus的混合检索能力让其“记忆”变得真正智能、可用。这套方案不仅解决了语义检索问题,更将检索流程本身变成了Agent可自主管理、迭代的资产,向着真正能“干中学、学中用”的智能体迈进了一大步。
希望这篇深度解析与实践指南能为你构建更强大的AI Agent提供启发。如果你对AI Agent、向量数据库等技术的实战应用感兴趣,欢迎在 云栈社区 交流讨论。
 发表于 2026-4-17 23:04:52
|
查看: 292|
回复: 0
发表于 2026-4-17 23:04:52
|
查看: 292|
回复: 0
