系统的崩溃,往往是由一连串单点的正确选择组成的。
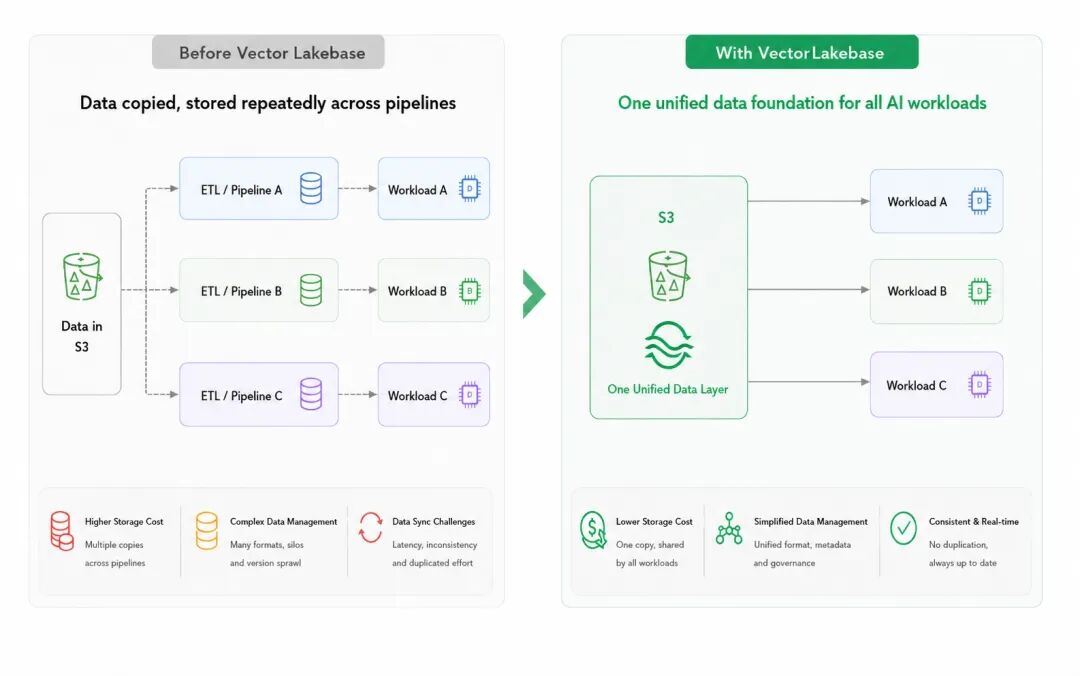
过去几年,企业数据架构大体形成了一个共识:数据湖负责低成本存储,湖仓一体架构负责分析治理,Spark 负责批处理,Delta Lake 或 Iceberg 负责表格式和元数据管理。这套架构处理传统分析任务没有问题。
但如今,非结构化数据占据了企业80%以上的数据占比,我们不仅要能存储它、检索它,还需要发掘数据背后的语义,将它变成AI时代的上下文语料。
于是,所有企业都开始一拥而上建设RAG系统,把企业中的各种文档先 chunk、再生产 embedding、然后再把所有向量数据导入向量数据库。
过了几个月,Agent 火了,它对延迟的要求更高,可接入的数据类型也更丰富,于是,打捞更多数据,相同的流程再走一遍。
再过一段时间,作为一个电商巨头,企业又需要把数十亿张商品图像做训练,然后,为了对这些数据做去重,相同的流程又来一遍。
最后,仅仅半年时间,一个原本清晰的数据湖架构变成了五六套系统拼在一起、数据重复存储的烟囱架构:数据湖一份,向量数据库一份,训练 pipeline 一份,检索服务一份,实验环境再来一份。
这个过程中,数据反复拷贝的存储成本还是次要,更大问题在于,当同一份数据有多个副本,每个副本更新时间不同,如何做统一管理。此外,每次表结构变化,都会牵连到多条 pipeline。Embedding 模型一升级,还要旧向量、新向量、旧索引、新索引全部重新对齐。
团队时间全都用在了数据同步。
在这种情况下,任何单点的优化,都已经无法解决问题,我们需要的,是一个最低代价的架构级解决方案,而这,也是我们推出 Vector Lakebase 的原因之一。
01 向量检索,是如何对抗数据引力的
在 Vector Lakebase 立项之初,我们和全球范围内上百家潜在意向客户的数据团队做了沟通,在此期间,我们频繁听到一个词语:
Data Gravity,数据引力。
这是一个 2010 年云原生普及前后出现的概念,大意是:数据一旦积累到一定规模,就会像有质量的物体一样,吸引计算、应用、服务、治理、安全和业务流程围绕它展开。数据越大,迁移越难;围绕它建立的系统越多,复制它的代价越高。
在此基础上,数据与应用的距离,会直接影响系统性能和成本,形成架构设计的隐性约束。
为了解决这个问题,传统数据架构中,数据仓库、数据湖、湖仓一体等等概念应运而生,也诞生了诸如 Databricks 这样的行业巨头。
但到了 AI 时代,这个问题被放大了。AI 应用不仅要读数据,还要对数据做一整套复杂操作:生成 Embedding、构建向量索引、做语义检索、评估检索质量、压缩上下文、管理 Agent memory、清洗训练语料、做近重复检测、发现异常样本。怎么让这些复杂操作,能基于数据湖直接运行,行业经历了三个阶段的探索。

第一阶段:专用向量数据库解决了在线检索,但没有解决数据引力
第一代方案是专用向量数据库,例如 Milvus。这也是让我们走进广大开发者视线中得意之作,现在它的 GitHub star 数量已经接近 4.5 万,成为开源向量数据库领域的事实标准。
在 2019 年开源 Milvus 时,我们致力于解决的,是如何在 RAG、推荐系统、语义搜索、多模态检索和 Agent 应用的生产环境中,以毫秒级延迟完成高召回的语义检索。
迄今为止,它仍然是所有主流在线业务的核心 infra。
但随着 AI 应用的成熟,越来越多新的变化发生了:我们不止要处理 AI 原生数据,还需要打捞哪些原本已经在对象存储里存放的文档,湖仓里的结构化数据,以及日志、行为数据等分析系统中的数据。
要把它们用于向量检索,往往就需要复制数据、生成 Embedding、导入向量数据库、构建索引、维护同步,再处理源数据和索引之间的一致性。
当 AI 工作负载越来越多,问题就开始爆炸。
同一份数据既要支持在线 RAG,又要支持 Embedding 实验,还要支持离线评估、治理、血缘分析和模型训练数据清洗。每多一个用途,就多一层 pipeline 和状态。
这个不是产品设计的问题,而在于向量数据库的设计本身就是为解决在线检索效率而生的,而要达成极致的效率,就需要我们在数据治理上,付出更多的成本。
很显然,不是所有数据,都值得付出这样的成本的。
第二阶段:Vector Lake 让搜索靠近数据湖,但只走了一半
第二代方案是 Vector Lake。
它的思路是既然数据已经在 Iceberg、Delta Lake 或 Parquet 文件中,那可不可以直接在数据湖上做向量搜索?
这个方向是对的,但在工程上会遇到几个阻力。
第一,Vector Lake 方案不是为低延迟在线服务设计的。它们通常从对象存储按需加载数据或索引,会导致整体延迟飙升,更适合离线探索和批量查询。对于 RAG、Agent、推荐或搜索应用这些常见的向量检索类型,系统需要稳定的亚 100 毫秒 p99 延迟。如果 p99 经常飘到秒级,这套系统可以做分析,但不能做生产级检索服务。
第二,Vector Lake 通常只解决搜的问题,不解决配套的问题。现代 AI 系统需要的不只是近邻搜索,它还需要重新生成 Embedding、评估检索效果、压缩 Agent memory、从视频中抽帧、处理多模态数据、管理元数据、准备微调数据和下游 pipeline。只在湖文件上加一层搜索,覆盖不了 AI 数据的完整生命周期。
第三,数据湖的底层存储格式本来就不是为这类负载设计的。Iceberg 和 Delta Lake 面向的是结构化分析数据。它们没有原生向量类型,没有索引结构,也不擅长高频随机点查(最典型的数据湖文件格式 Parquet 采用的是顺序行组扫描,这才给了后续 Vortex 和 Lance 等格式在 AI 时代大放异彩的机会)。AI 工作负载需要快速点查、与数据一同管理更新的内建索引。图片、音频、视频也不应该作为大块 blob 粗暴塞进表里,而应该通过引用方式管理。
所以,Vector Lake 的动机正确,但能力不完整。它把搜索拉近了湖,却没有把 AI 数据操作真正变成湖的一部分。
第三阶段:Vector Lakebase 把数据湖和向量数据库合成一层
Vector Lakebase 既不是把向量数据库换个名字,也不是在数据湖上外挂一个查询层。
它的核心是:把数据湖和向量数据库看成同一层架构的两种运行模式。
Vector Lakebase 是一种 AI 原生、湖原生的架构。它继承向量数据库的高并发、低延迟检索能力,同时继承多模态数据湖的开放性、可扩展性和成本优势。
传统向量数据库:
[数据湖] --ETL--> [向量数据库]
问题:数据复制、同步延迟、状态不一致
Vector Lake:
[数据湖 + 索引] --> 批量查询
问题:能查,但不擅长在线服务,也缺少完整 AI 数据处理能力
Vector Lakebase:
[数据湖 + 索引 + 计算]
├── 在线模式:缓存 + 高性能索引
│ 支持 ANN 查询,服务 p99 延迟低于 100 毫秒
└── 离线模式:批处理 + 低成本索引构建
支持 Embedding、聚类、去重、特征工程
通过计算与存储分离,Vector Lakebase 可以让在线服务、数据发现、分析和离线处理可以在同一份数据之上独立运行。
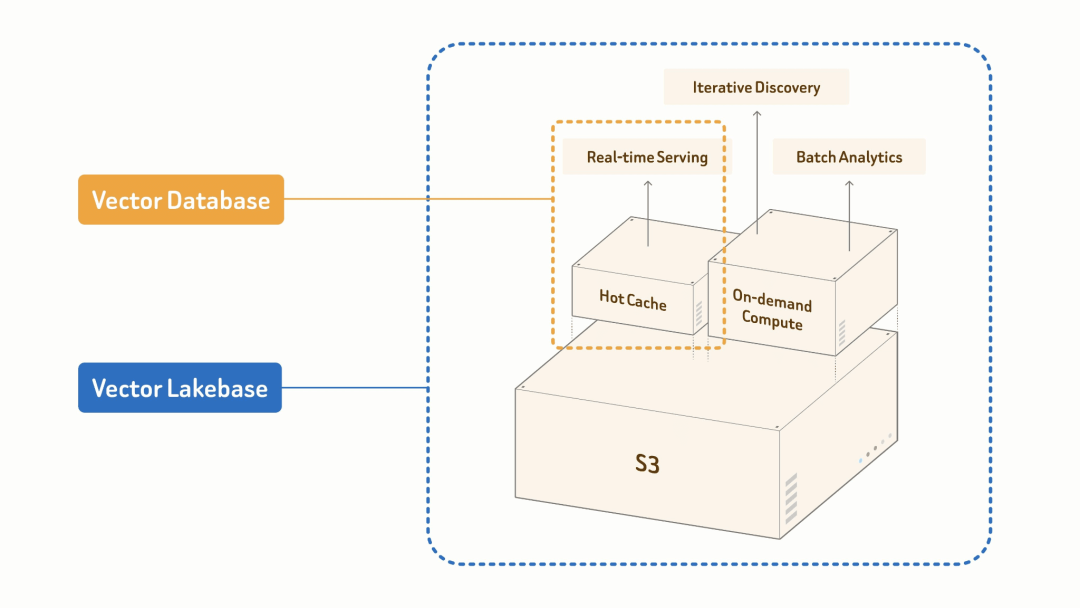
它的核心原则在于所有多模态数据、向量、属性、索引和元数据都可以直接存放在低成本对象存储中,并通过开放格式管理,让在线和离线共享同一份数据、同一套索引、同一个模式。
在此基础上,才是基于在线和离线不同需求而产生的不同计算模式。
在线服务依赖热缓存和高性能内存索引,目标是高并发和低延迟。
离线批处理则追求低成本和大规模处理,通过列式扫描、GPU 加速索引构建,再把结果分阶段写回数据湖进行数据检索。
整个过程,数据相同、索引格式相同,只有计算形态不同。
以一张包含 10 亿向量的 Iceberg 表为例,以下是不同模式对相同工作负载的处理效率差距:
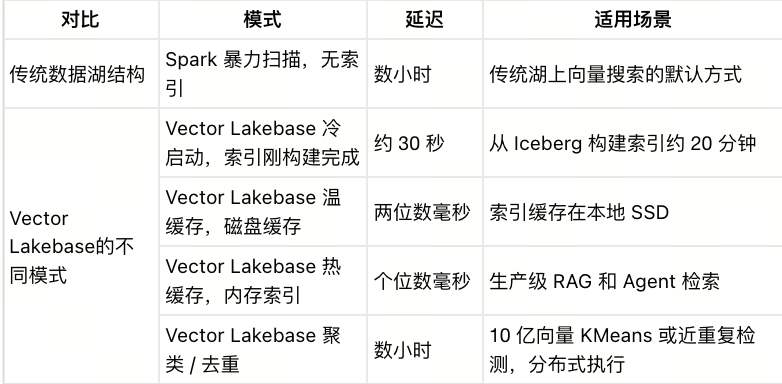
相比传统数据湖,Vector Lakebase 不仅让系统从“几个小时扫一遍”进入“毫秒级服务”,并实现了全程数据没有离开数据湖。
02 哪些企业与负载适合选择 Vector Lakebase
Vector Lakebase 不是所有团队都需要的东西,它更适合三类团队。

第一类:已有数据湖建设,不想做额外的数据迁移
很多企业已经在 S3 上存了 PB 级数据,其中包括 Parquet 文件和大量 Embedding。今天如果要让这些数据服务一个新的 RAG 应用,常规做法是把数据导入向量数据库。整个迁移过程可能需要几天甚至几周,之后还要长期维护同步任务。
Vector Lakebase 的 External Collections 思路正好相反:不搬数据。
你只需要指定 bucket,在现有列上定义模式映射,就能原地构建向量索引。数据仍然留在 S3,索引也写回 S3。源数据更新时,只需要增量刷新发生变化的文件。
# 1. Register your existing lake data as an external collection
client.create_external_collection(
collection_name="enterprise_docs",
src="s3://my-lake/docs/*.parquet", # point at your existing data
schema={"text": String, "embedding": FloatVector(768)},
)
# 2. Build a vector index — data stays in S3, index persists back to S3
client.create_index("enterprise_docs", field="embedding", index_type="HNSW")
# ~20 min for 1B vectors. Data never moves.
# 3. Search — single-digit ms with in-memory cache
results = client.search(
collection_name="enterprise_docs",
data=[query_embedding],
top_k=10,
output_fields=["text"],
)
这意味着,没有迁移,没有额外 pipeline,也没有新的存储副本。
RAG 系统查询的,就是分析团队已经治理过的那份数据。Spark、Ray、LangChain、PyMilvus 或 REST API 都可以访问它。索引不再是表外面的外挂系统,而是表的一等属性。
这是非常重要的变化。因为一旦索引成为表的一部分,数据治理、版本管理、增量更新和权限控制就不再需要跨系统拼接。
第二类:ETL、特征工程和上下文工程
Vector Lakebase 真正重要的地方,不只是性价比。它能把过去分散在多套系统里的 AI 数据,用统一的语义进行管理。
这些工作包括:
- 给现有表增加 Embedding 列。比如对 1 亿行数据做批量推理,然后把结果写回同一张表。
- 为 RAG 切分文档。原始文档和切分后的 chunk 可以一起版本化,而不是散落在不同存储里。
- 升级 Embedding 模型。比如从 text-embedding-3-small 切到新模型时,可以原地回填 5 亿条向量,让旧向量和新向量在切换前并存。
- 构建 Agent 运行时要检索的上下文。包括检索什么、如何组织、如何压缩、如何适配上下文窗口。
这就是 Context Engineering,也可以叫上下文工程。
随着模型能力越来越商品化,应用质量越来越取决于你给模型喂什么上下文。有时候,模型只是彼此差距不大的推理引擎,真正决定效果的是上下文的选择、结构、压缩、更新和版本管理。
而这些工作不应该靠几段脚本、几个 cron job 和几条同步管线拼起来。它们应该发生在数据湖里,靠近数据,和数据一起版本化,并且可以端到端复现。
第三类:模型训练数据的聚类、去重和异常发现
对训练或微调模型的团队来说,向量索引不只是在线检索工具,也是重要的数据治理工具,典型应用有三个:
第一,去重。
如果 LLM 微调数据集中存在大量相似重复样本,它们会增加训练成本之外,也会让模型行为产生偏差。团队需要找出近重复样本,生成规范样本集合,再把去重后的标签写回同一张表。
第二,聚类。
训练前,团队必须知道数据集里到底有什么。对 Embedding 空间做聚类,经常会发现,一个看起来很多样的数据集,可能有 40% 都是少数几个主题的轻微变体。没有聚类分析,所谓数据多样性很容易只是错觉。
第三,异常发现。
在自动驾驶、机器人和其他安全关键场景里,最重要的往往不是平均样本,而是那 0.1% 的罕见样本。它们可能是极端路况、少见障碍物、异常行为或边界场景。数据打标后,如果没有索引,就很难找到它们;不能把结果写回数据湖,就无法把它们送去标注、训练和评估。
03 Databricks Lakebase 和 Vector Lakebase 之间,不需要选型
在与大量客户沟通中,我们会频繁听到这样一个疑问。我们已经有了 Databricks Lakebase,还需要 Vector Lakebase 吗?
要回答这个问题,需要了解 Databricks Lakebase 究竟是什么。
Databricks Lakebase 基于 Neon,把 serverless PostgreSQL 引擎集成进 Databricks 平台。它要解决的是 OLTP 和 OLAP 长期分离的问题:业务交易系统和分析系统能否在同一个平台里更紧密地协作?
但 Vector Lakebase 解决的是另一个新的问题:AI 数据存在哪里,AI 操作在哪里运行。
两者对比如下:
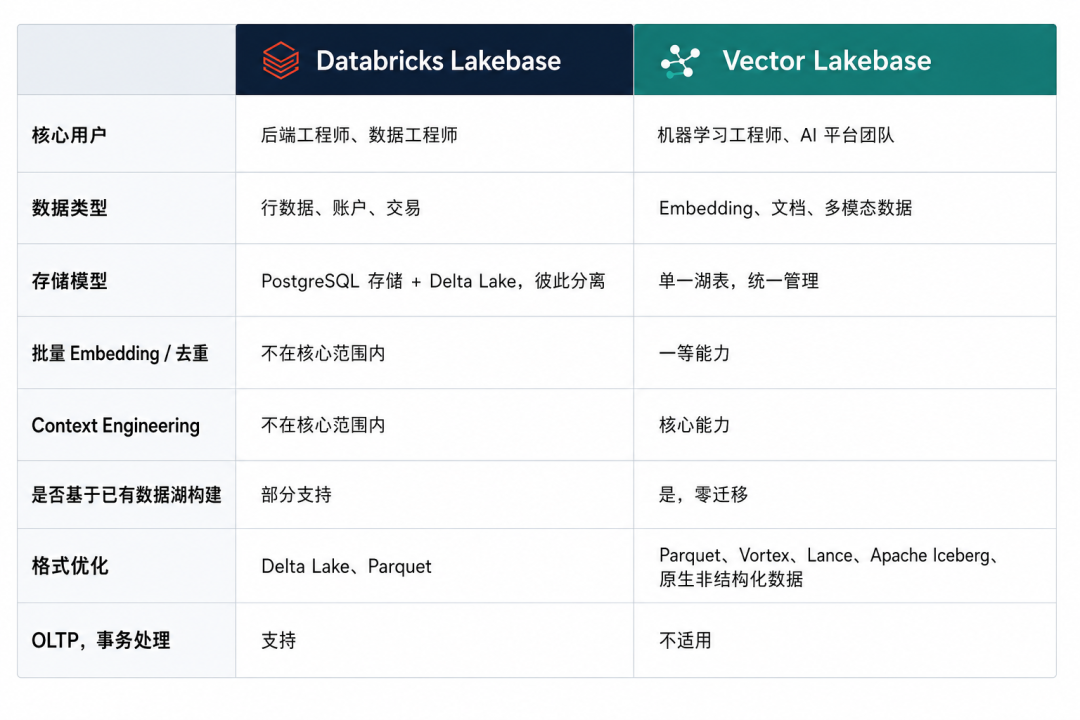
总结来说,就是 Databricks Lakebase 打破的是 OLTP 和 OLAP 的边界。Vector Lakebase 打破的是 AI 数据位置和 AI 操作运行位置之间的边界。
一个面向交易和分析融合。一个面向 AI 数据和 AI 操作融合。未来很多团队可能会同时用两者。
尾声
2013 年,Databricks 提出了一个问题:如果 SQL 分析可以直接运行在数据湖之上,会发生什么?
这个问题后来撑起了一家价值 400 亿美元的公司。
今天,轮到 AI 基础设施回答下一个问题:
如果 RAG 检索、Agent memory、批量 Embedding、模型训练数据治理、Context Engineering 这些 AI 原生数据操作,也能直接运行在数据湖之上,会发生什么?
这是一个更大的话题,也是 Vector Lakebase 的使命。
它不需要你为不同 AI 负载建设重复的 pipeline,也不是一个临时挂在现有数据湖上的查询层。它是建立在你已有数据基础上的统一入口:让你的数据只存一份,索引只建一次,却可以服务所有 AI 工作负载。
从此不必重复副本,没有 ETL 负担,也不用继续和数据引力对抗。
AI 落地拼的是速度,我们每多花一周在数据迁移、pipeline 建设,对手就会多一周发布新功能。
有时候,最终的赢家,往往不一定是模型最强的团队,而是最早降低数据和 AI 之间阻力的团队。
目前 Zilliz Vector Lakebase 的 public preview 已经正式发布。尝鲜链接: https://zilliz.com.cn
附:Zilliz Vector Lakebase 能力一览
当前阶段的 Zilliz Vector Lakebase,主要做了五方面的能力建设:
- 服务能力升级:推出分层服务方案,为极致性能、容量优化和低成本分层存储等不同场景提供对应选择。
- 按需搜索能力升级:推出按需搜索(On-Demand Search),让大规模低频检索、数据探索和离线分析不再需要长期维持闲置计算资源。
- 数据湖搜索能力升级:支持外部数据湖搜索(External Data Lake Search),可直接在已有数据湖上增加高性能索引和大规模搜索能力。
- 检索能力升级:在同一系统内支持向量搜索、全文搜索、JSON 查询、地理空间搜索、多向量搜索、多路径检索和重排序。
- 湖原生存储能力升级:同构统一的 lake-Native Storage,基于 Vortex 开放格式,为在线服务和离线分析提供统一、高效、低成本的数据底座。与 Lance 和 Parquet 相比,它能提供更快、更便宜的随机读取,以及按列格式的灵活性和更广泛的数据建模能力。
如果你也在探索如何用湖原生架构打破 AI 数据孤岛、告别重复建设,欢迎来 云栈社区 与更多开发者交流落地实践。
 发表于 2026-5-29 20:19:17
|
查看: 99|
回复: 0
发表于 2026-5-29 20:19:17
|
查看: 99|
回复: 0
