当下通用大模型与算力硬件正逐步普及,企业若想在 AI 落地中建立差异化优势,核心已不再是单纯采购算力与通用模型,而是自身长期积累的专有数据。然而大量企业在推进 AI 业务时,海量专有数据仍难以顺畅输送至训练与推理流程,数据资产长期闲置,难以转化为实际业务价值,传统一体化存储架构也难以适配 AI 不同阶段的数据使用特征。
针对专有数据流转中暴露的各类痛点,XSKY 正式推出 AIMesh 2026 全新产品体系。这套一站式 AI 数据基础设施不再沿用传统存储思路,而是按照数据在 AI 业务里承担的实际职责进行分层设计,逐一击破“内存墙”、“IO 墙”、“重力墙”三大技术壁垒,真正盘活企业自有数据资产。
AI 数据分层:从业务视角重新定义存储职责
AI 业务运行过程中,数据会依据生命周期与访问频率分布在不同层级,从近算力的高速缓存到企业长期保存的数据湖,共分为 G1/G2 运行态数据层、G3/G3.5 近端热数据层、G4 共享生产数据层、G5 企业数据资产层。
- G1/G2 运行态数据层:承载 GPU/NPU 内部 HBM 显存与 DRAM 内存中的数据,生命周期最短,属于正在计算中的瞬时状态。
- G3/G3.5 近端热数据层:由服务器本地 NVMe SSD 构成,承载推理场景中的 KV Cache、上下文缓存等热数据。离算力近、延迟低,但通常只能单机调用,容易形成数据孤岛。
- G4 共享生产数据层:承载训练数据集、Checkpoint、模型文件以及推理共享文件,需要多 GPU 节点的高并发共享访问。
- G5 企业数据资产层:承载历史文档、图片视频、日志、RAG 语料等长期积累的专有数据,让企业私有数据能被持续管理与治理,并回流至 AI 链路。
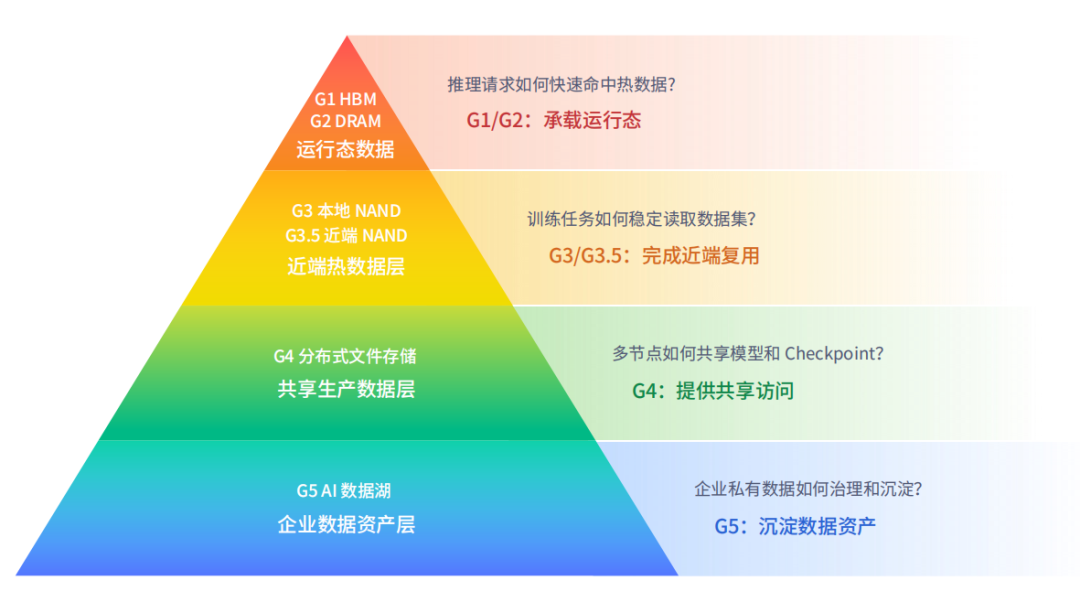
每一层职责不同,对应的产品能力与优化方向也截然不同。XSKY AIMesh 依托三套核心产品分别匹配相应层级,针对性解决各环节痛点,形成一套完整、贯通的数据处理体系。
XSKY AIMesh:面向智算中心的数据基础设施全景
把数据分层与业务流结合起来,就能看清 XSKY AIMesh 的完整定位。AIMesh 并非几个孤立产品的简单组合,而是一套覆盖智算中心不同数据层级的一站式 AI 数据基础设施。
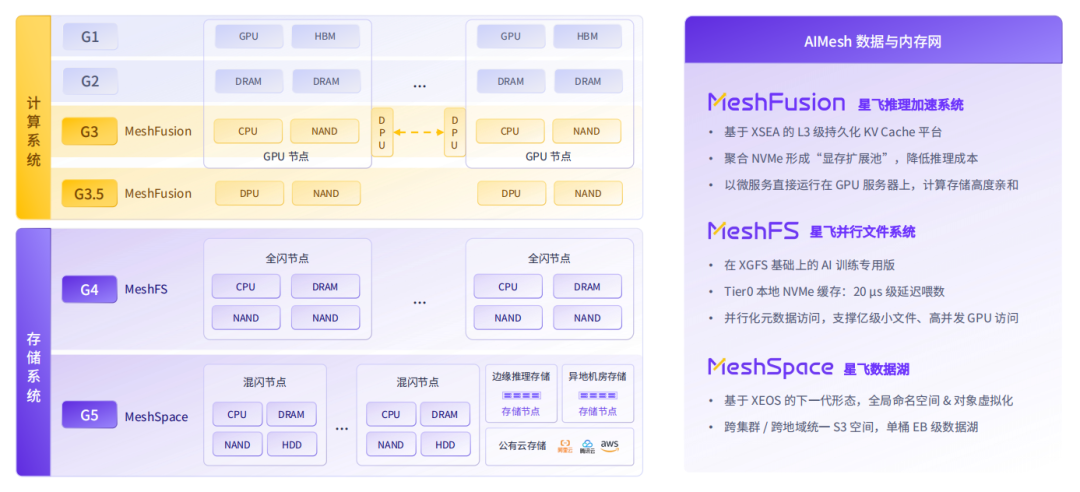
G3/G3.5 近端热数据层:MeshFusion 破解内存墙
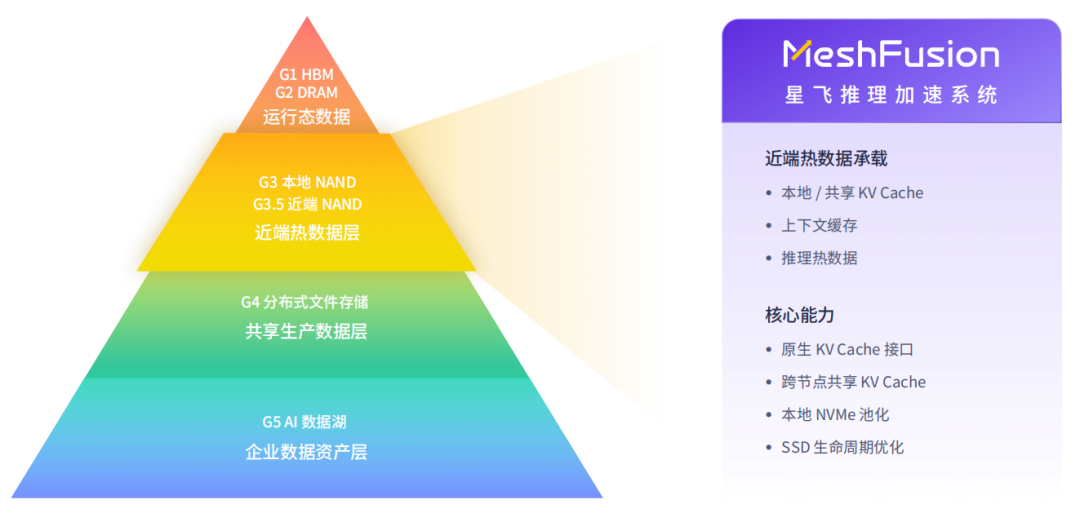
G3/G3.5 是距离 GPU 算力最近的近端缓存层。KV Cache 完全依赖 HBM 承载的成本过高,这里也是内存墙问题的集中爆发区。MeshFusion 将本地 NVMe 池化为共享 KV Cache,用于卸载 HBM 依赖,大幅降低推理成本。
▶ 灵活适配的部署模式
MeshFusion 支持两种部署方式。融合部署可直接复用现有 GPU 服务器本地 NVMe 硬件,无需额外采购存储节点,能够快速落地、控制初期投入;分离部署则实现了计算与存储资源的解耦,可适配超大规模智算集群,贴合 NVIDIA CMX 等架构的落地需求。
▶ 原生 KV Cache 接口与跨节点共享
MeshFusion 将各服务器上的本地 NVMe 聚合为集群内可共享的 KV Cache 资源池,上层应用通过原生 KV Cache 接口访问,无需改造推理框架。缓存数据得以在整个集群内自由流转复用,不再绑定于单机。
▶ 降低显存依赖,提升推理并发
KV Cache 从 HBM 卸载到近端 SSD 池后,对昂贵显存的依赖大幅降低,高并发推理场景的承载能力获得显著提升。推理侧的专有热数据实现高效流转,从根源上解决了内存墙带来的成本与性能矛盾。
MeshFusion 并非简单地将 SSD 连接起来,而是围绕 KV Cache 的访问语义,提供原生接口、低延迟路径与跨节点共享能力,从而支撑起更长上下文、更高并发与更低的推理成本。
G4 共享生产数据层:MeshFS 打通 IO 墙
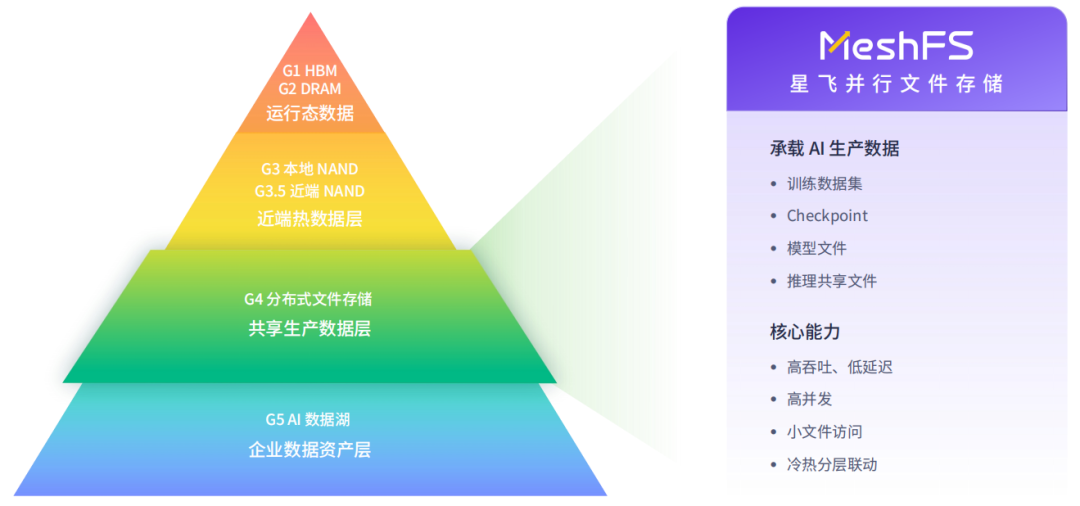
G4 作为集群共享生产数据层,是大模型训练业务的核心支撑。存储并发吞吐一旦跟不上,算力就会被“等数据”死死拖住——这正是 IO 墙的源头。MeshFS 正是面向这一层的高性能并行文件存储系统,并在 7.4 版本中实现全面升级。
▶ POSIX 性能再提升
读带宽保持行业前列,集群写带宽较 7.3 版本增长 24%,使得高并发训练下的数据加载与 Checkpoint 写入更为稳定。
▶ NFS 共享访问大幅增强
引入分布式并行网关,将 NFS 访问压力分散至全集群,多客户端共享读写吞吐提升 3.8 倍,配合智能分层与预取能力,NFS 读性能进一步提升 7.1 倍。
▶ 智能分层双向流动
与 G5 对象存储联动,温冷数据自动下沉至 XEOS 桶中,热数据则可快速拉回 G4 参与计算,无需人工干预搬迁。
▶ 异构硬件全适配
兼容 Intel、AMD、鲲鹏等平台,支持 Infiniband / RoCE 高性能网络,全面覆盖信创环境。
MeshFS 7.4 的核心价值,是把训练读取、Checkpoint 写入、多客户端共享、冷热分层以及存量资源复用,统一沉淀到 G4 层,让 IO 墙不再卡住 AI 训练效率。
G5 企业数据资产层:MeshSpace 消融重力墙
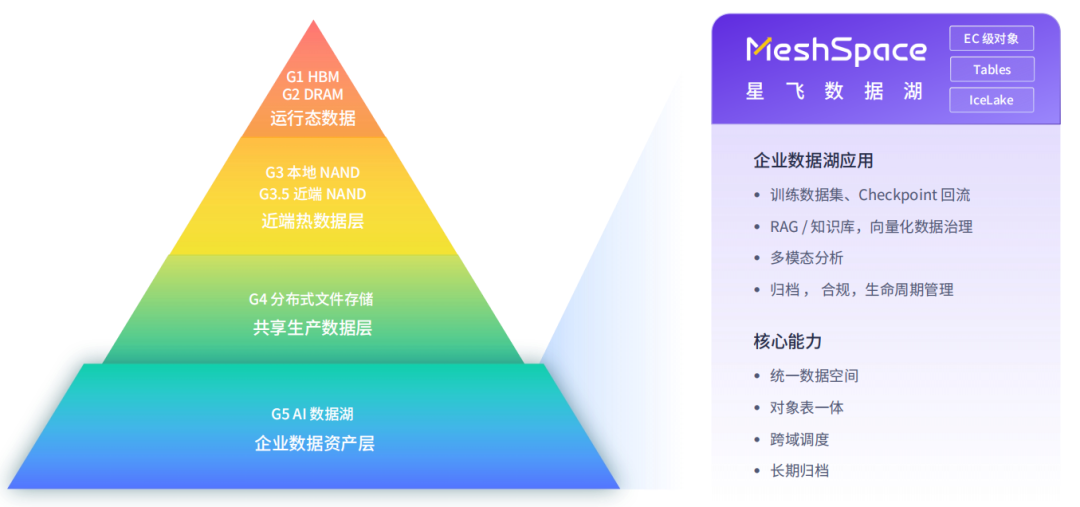
G5 层承载的是企业多年积累的专有数据资产,也是重力墙问题的核心症结。MeshSpace 旨在提供一个统一数据空间,让企业专有数据能从“存得下”走向“管得住、用得好、沉淀得下”。
▶ EB 级统一数据湖命名空间
MeshSpace 将分散在不同桶、不同集群、不同地域的数据,组织成一个统一的逻辑命名空间。底层通过两层元数据横向扩展,单桶即可支撑 EB 级规模。在实际落地案例中,单桶 100PB 可用容量可提供 2.5Tbps 写、3Tbps 读吞吐,4KB 读 OPS 达 400 万对象每秒。数据盘点、权限管理、生命周期策略均可在一个平台上统一执行,管理复杂度大幅降低。
▶ 低成本长期归档(IceLake 联动)
历史数据与低频访问数据若长期滞留在高性能存储层,会造成持续的成本压力。MeshSpace 底层联动 IceLake,通过小文件聚合将海量文件归并后顺序写入低成本介质,闲置数据集自动沉降到低成本归档层,同时保持可检索、可追溯。当需要审计、回溯或重新分析时,支持快速回热调取,做到合规不丢、成本可控。
▶ 湖仓一体数据管理(Tables 能力)
传统对象存储只能按路径管理文件,难以支撑 AI 场景下对数据集的组织要求。MeshSpace 通过 XEOS Tables 能力,在同一个数据湖底座上,同时支持对象和表两种数据形态——原始对象通过 S3 存入,数据集则按 Iceberg 表语义组织。不搬迁、不复制即可被 Spark、Flink、Trino 等引擎直接消费,实现了湖仓一体架构在存储侧的原生落地。
▶ 跨域数据调度
数据不应被锁定在某一个存储层。MeshSpace 支持按策略在训练、分析、沉淀与归档之间调度数据流动。当训练任务需要特定数据集时,数据可自动从归档层回调至高性能层参与计算;任务结束后,结果数据又可按策略下沉到温冷层长期保存。整个过程自动化执行,无需人工介入搬迁。
G5 层的价值,不在于简单地把数据存进去,而是让企业专有数据在统一命名空间里被有序管理、以湖仓一体的方式被组织消费、跨层级自由流动、长期低成本留存——最终形成一条从数据资产到 AI 业务的可循环链路。
三层产品协同联动:搭建企业专有数据完整闭环
MeshFusion、MeshFS、MeshSpace 并非三套彼此独立的存储系统。三者沿着 AI 数据使用链路无缝衔接,形成了一套完整的数据流转闭环。
AI 推理阶段,MeshFusion 负责近端热数据的缓存复用,保障实时业务的响应速度;模型训练时,MeshFS 提供高吞吐共享文件能力,稳定输出训练所需的专有数据集;所有业务产生的历史数据、原始素材,则统一归集至 MeshSpace 完成治理归档,同时根据业务需求向上回流至训练与推理环节。三层各司其职、数据双向流动,构成了“热数据近端复用—生产数据稳定共享—资产数据持续治理”的完整链路。
这套分层架构覆盖了 AI 推理、模型训练、数据治理、长期归档的全流程,兼顾性能、成本、运维便捷性与国产化适配需求。无论是小规模 AI 试点项目,还是大型智算中心集群建设,都能匹配企业不同阶段的数据使用场景。

不同于传统存储产品只解决单一存储场景的问题,XSKY AIMesh 以 AI 业务数据分层逻辑为核心,分层攻克内存墙、IO 墙、重力墙三大行业痛点,充分释放企业专有数据的潜力。在 AI 全面落地的行业趋势下,这套一站式 AI 数据基础设施能够打通数据流转全链路,帮助企业把沉淀多年的专有数据资产,转化为稳定且可持续的 AI 业务竞争力。
 发表于 4 小时前
|
查看: 4|
回复: 0
发表于 4 小时前
|
查看: 4|
回复: 0
